Cassandra开发入门文档第二部分(timeuuid类型、复合主键、静态字段详解)
timeuuid类型
timeuuid具有唯一索引和日期时间的综合特性,可以与日期和时间函数联合使用,常用的关联函数:
- dateOf()
- now()
- minTimeuuid() and maxTimeuuid()
- toDate(timeuuid)
- toTimestamp(timeuuid)
- toUnixTimestamp(timeuuid)
比如
SELECT * FROM myTable
WHERE t > maxTimeuuid('2013-01-01 00:05+0000')
AND t < minTimeuuid('2013-02-02 10:00+0000')
DataStax Enterprise 5.0及更高版本支持一些额外的timeuuid和timestamp函数来操作日期。这些函数可以在INSERT、UPDATE和SELECT语句中使用。
CREATE TABLE sample_times (a int, b timestamp, c timeuuid, d bigint, PRIMARY KEY (a,b,c,d));
INSERT INTO sample_times (a,b,c,d) VALUES (1, toUnixTimestamp(now()), 50554d6e-29bb-11e5-b345-feff819cdc9f, toTimestamp(now()));
SELECT a, b, toDate(c), toDate(d) FROM sample_times

开工!
-- 开始工作:
bin/cqlsh localhost
-- 查看所有的键空间:
DESCRIBE keyspaces
-- 使用创建的键空间:
USE myks;
-- 查看已有表:
describe tables;
-- 查看表结构:
describe table users;
-- 删除已有表:
drop table users;
user_status_updates表有一个id字段,类型是timeuuid。
username是一个分区key。表的分区key的作用是将行分组到特定的逻辑相关。在程序中,每个用户的时间线都是一个独立的数据结构,因此按用户划分表是一个合理的策略。
我们称id列为集群(clustering)列。集群列的任务是确定分区中行的顺序。这就是为什么我们观察到在每个用户的状态更新中,行是按id的时间戳严格按升序返回的。
-- 首先,先建表
CREATE TABLE "user_status_updates" (
"username" text,
"id" timeuuid,
"body" text,
PRIMARY KEY ("username", "id")
); CREATE TABLE "users" (
"username" text,
"email" text,
"encrypted_password" blob,
PRIMARY KEY ("username")
); -- 对主表users进行数据插入
INSERT INTO "users"
("username", "email", "encrypted_password")
VALUES (
'alice',
'alice@gmail.com',
0x8914977ed729792e403da53024c6069a9158b8c4
); INSERT INTO "users"
("username", "encrypted_password")
VALUES (
'bob',
0x10920941a69549d33aaee6116ed1f47e19b8e713
); -- 对从表user_status_updates进行数据插入
INSERT INTO "user_status_updates"
("username", "id", "body")
VALUES (
'alice',
76e7a4d0-e796-11e3-90ce-5f98e903bf02,
'Learning Cassandra!'
); INSERT INTO "user_status_updates"
("username", "id", "body")
VALUES (
'bob',
97719c50-e797-11e3-90ce-5f98e903bf02,
'Eating a tasty sandwich.'
); -- 前面我们加了2条从表记录,现在重点关注下id(即timeuuid)的查询
SELECT * FROM "user_status_updates"; SELECT "username", "id", "body", DATEOF("id")
FROM "user_status_updates"; SELECT "username", "id", "body", UNIXTIMESTAMPOF("id")
FROM "user_status_updates"; SELECT * FROM "user_status_updates"
WHERE "username" = 'alice'
AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02; -- 我们加了2条自制的uuid,那么从时间函数能自动产生uuid吗?会不会产生排序异常?
-- 再插入6条测试数据 INSERT INTO "user_status_updates" ("username", "id", "body")
VALUES ('alice', NOW(), 'Alice Update 1');
INSERT INTO "user_status_updates" ("username", "id", "body")
VALUES ('bob', NOW(), 'Bob Update 1');
INSERT INTO "user_status_updates" ("username", "id", "body")
VALUES ('alice', NOW(), 'Alice Update 2');
INSERT INTO "user_status_updates" ("username", "id", "body")
VALUES ('bob', NOW(), 'Bob Update 2');
INSERT INTO "user_status_updates" ("username", "id", "body")
VALUES ('alice', NOW(), 'Alice Update 3');
INSERT INTO "user_status_updates" ("username", "id", "body")
VALUES ('bob', NOW(), 'Bob Update 3'); -- 看看时间戳就知道了
SELECT "username", "id", "body",toTimestamp("id"), UNIXTIMESTAMPOF("id")
FROM "user_status_updates"; -- 结果:
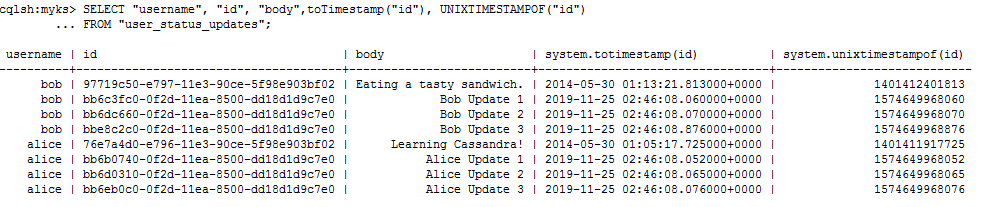
上面的例子看到一个表的主键中有两列:一个分区键(username)和一个集群列(id)。事实证明,这两种都不仅仅限于一个列。可以定义一个或多个分区键列和零个或多个群集列。
多个群集列
群集列不限于前面指定的一个字段。让我们看看多个集群列是如何工作的,并有助于数据排序。为了说明这一点,我们将重新创建状态更新表,以便按用户更新其状态的日期和时间对其进行群集:
"status_date", "status_time"将是下面的演示多个集群列的例子。
复合主键
复合主键是由多个列组成的简单主键。虽然乍一看,这似乎是对Cassandra表的一个小小的补充,但实际上,具有复合主键的表是一个相当丰富的数据结构,它具有新的数据访问模式。
我们构建一个user_status_updates表,该表存储用户状态更新的时间线。
-- 下面来看看复合主键
-- 建表 CREATE TABLE "user_status_updates_by_datetime" (
"username" text,
"status_date" date,
"status_time" time,
"body" text,
PRIMARY KEY ("username", "status_date", "status_time")
); INSERT INTO "user_status_updates_by_datetime" ("username",
"status_date", "status_time", "body")
VALUES ('alice', '2019-11-18', '08:30:55.123', 'Alice Update 1');
INSERT INTO "user_status_updates_by_datetime" ("username",
"status_date", "status_time", "body")
VALUES ('alice', '2019-11-18', '14:40:25.123456789', 'Alice Update 2');
INSERT INTO "user_status_updates_by_datetime" ("username",
"status_date", "status_time", "body")
VALUES ('alice', '2019-11-19', '08:25:25', 'Alice Update 3');
INSERT INTO "user_status_updates_by_datetime" ("username",
"status_date", "status_time", "body")
VALUES ('alice', '2019-11-21', '08:35:55.123456', 'Alice Update 4');
INSERT INTO "user_status_updates_by_datetime" ("username",
"status_date", "status_time", "body")
VALUES ('alice', '2019-11-21', '14:30:15.123', 'Alice Update 5');
INSERT INTO "user_status_updates_by_datetime" ("username",
"status_date", "status_time", "body")
VALUES ('alice', '2019-11-23', '14:50:45.123456', 'Alice Update 6');
-- 试试看插入一些错误数据
INSERT INTO "user_status_updates_by_datetime" ("username",
"status_date", "status_time", "body")
VALUES ('alice', '2019-14-23', '14:50:45.123456', 'Alice Update 7');
INSERT INTO "user_status_updates_by_datetime" ("username",
"status_date", "status_time", "body")
VALUES ('alice', '2019-11-23', '14:65:45.123456', 'Alice Update 8');
一些组合查询和传统数据库不同的地方
SELECT * FROM "user_status_updates_by_datetime";
-- 试试组合查询
SELECT * FROM "user_status_updates_by_datetime"
WHERE "username" = 'alice' AND "status_date" < '2019-11-20'; -- 试试组合日期和时间查询,要查大于某天及大于几点的数据
SELECT * FROM "user_status_updates_by_datetime"
WHERE "username" = 'alice' AND "status_date" > '2019-11-20' AND
"status_time" > '12:00:00';
-- 报了个错:InvalidRequest: Error from server: code=2200 [Invalid query] message="Clustering column "status_time" cannot be restricted (preceding column "status_date" is restricted by a non-EQ relation)"
-- 原因Cassandra 支持的查询语句很严格,首先 partition key 必须精确查询,最后一个查询才能范围查询。
-- 改成下面这样就合规了
SELECT * FROM "user_status_updates_by_datetime"
WHERE "username" = 'alice' AND "status_date" = '2019-11-21' AND
"status_time" > '12:00:00';
Cassandra没有内置的不同表中数据之间关系的概念。SELECT语句中没有外键约束,也没有JOIN子句;
事实上,在同一个查询中没有从多个表中读取的方法,而关系数据库可以考虑不同表中数据之间的关系,无论它们是一对一、一对多还是多对多。
Cassandra没有用于描述或遍历表间关系的内置机制。也就是说,Cassandra的复合主键结构为一种特殊的主从关系提供了充足的保障。
在关系数据库中,我们可以使用外键约束使关系在模式中显式化,但是Cassandra没有提供这样的功能。事实上,如果我们想为用户和用户状态更新使用两个不同的表,我们无法在数据库模式中显式地编码它们的关系。但是,有一种方法可以将用户和状态更新合并到一个表中,同时保持它们之间的一对多关系。为了实现这一合并,我们将使用Cassandra表的一个特性,这是我们以前从未见过的静态列。
其实,归根结缔,用一个词来形容Cassandra的这种Non Join的做法的核心就是:冗余。
而静态列就是保持冗余和一致性的重要技术手段。
STATIC静态字段
-- 创建表
-- 我们将 email 和 encrypted_password 两个字段设置为 STATIC 了,这意味着同一个 username 只会有一个 email 和 encrypted_password CREATE TABLE "users_with_status_updates" (
"username" text,
"id" timeuuid,
"email" text STATIC,
"encrypted_password" blob STATIC,
"body" text,
PRIMARY KEY ("username", "id")
); INSERT INTO "users_with_status_updates"
("username", "id", "email", "encrypted_password", "body")
VALUES (
'alice',
76e7a4d0-e796-11e3-90ce-5f98e903bf02,
'alice@gmail.com',
0x8914977ed729792e403da53024c6069a9158b8c4,
'Learning Cassandra!'
); SELECT * FROM "users_with_status_updates";
-- 验证插入
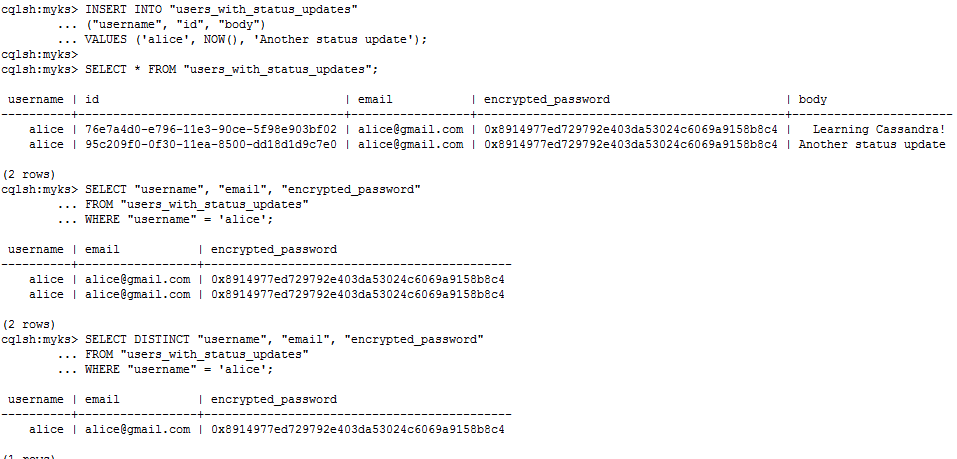
INSERT INTO "users_with_status_updates"
("username", "id", "body")
VALUES ('alice', NOW(), 'Another status update'); SELECT * FROM "users_with_status_updates"; SELECT "username", "email", "encrypted_password"
FROM "users_with_status_updates"
WHERE "username" = 'alice'; SELECT DISTINCT "username", "email", "encrypted_password"
FROM "users_with_status_updates"
WHERE "username" = 'alice'; -- 验证另一个主键bob INSERT INTO "users_with_status_updates"
("username", "email", "encrypted_password")
VALUES (
'bob',
'bob@gmail.com',
0x10920941a69549d33aaee6116ed1f47e19b8e713
); INSERT INTO "users_with_status_updates"
("username", "id", "body")
VALUES ('bob', NOW(), 'Bob status update');
结果:
高级课题
以上是联合主键的一些用法,现在进入高级些的课题
- 如何检索单个分区中的所有行
- 如何检索集群列值范围内的行
- 如何对单个分区中的行进行分页
- 如何更改结果的顺序
- 如何按聚类列的降序存储行
- 如何分页
SELECT * FROM "user_status_updates"
WHERE "username" = 'alice'; -- 以前,我们使用WHERE关键字为一个完整的主键指定一个确切的值。在前面的查询中,我们只指定主键的分区键部分,这允许我们只检索那些我们要求分区的行;
-- 出于唯一性的目的,username列肯定不能保证唯一性;id是一个UUID,我们可以跳过用户名分区键,只通过id clustering列查找行吗?让我们试一试: SELECT * FROM "user_status_updates"
WHERE id = 3f9b5f00-e8f7-11e3-9211-5f98e903bf02; INSERT INTO "status_update_replies"
("status_update_username", "status_update_id", "id", "body")
VALUES(
'alice',
76e7a4d0-e796-11e3-90ce-5f98e903bf02,
NOW(),
'Good luck!'
); SELECT * FROM "status_update_replies"
WHERE "status_update_username" = 'alice'; -- 检索特定时间范围的状态更新 -- 在探究了CQL中WHERE关键字的限制之后,让我们返回到user_status_updates表。假设我们想为MyStatus构建一个存档特性,显示用户在请求的一个月内的所有更新。
-- 在CQL术语中,我们希望选择一系列集群列;例如,让我们返回2014年5月创建的alice的所有状态更新: SELECT "id", DATEOF("id"), "body"
FROM "user_status_updates"
WHERE "username" = 'alice'
AND "id" >= MINTIMEUUID('2014-05-01')
AND "id" <= MAXTIMEUUID('2014-05-31'); -- 在分区中分页,顺序 SELECT "id", DATEOF("id"), "body"
FROM "user_status_updates"
WHERE "username" = 'alice'
LIMIT 3;
-- 在分区中筛选后分页,顺序 SELECT "id", DATEOF("id"), "body"
FROM "user_status_updates"
WHERE "username" = 'alice'
AND id > 3f9df710-e8f7-11e3-9211-5f98e903bf02
LIMIT 3; SELECT COUNT(1) FROM "user_status_updates"
WHERE "username" = 'alice'; -- 在分区中筛选后分页,倒序 SELECT "id", DATEOF("id"), "body"
FROM "user_status_updates"
WHERE "username" = 'alice'
ORDER BY "id" DESC; -- 在分区中不使用簇列进行排序,将会报错 cqlsh:myks> SELECT "id", DATEOF("id"), "body"
... FROM "user_status_updates"
... WHERE "username" = 'alice'
... ORDER BY "body" DESC;
InvalidRequest: Error from server: code=2200 [Invalid query] message="Order by is currently only supported on the clustered columns of the PRIMARY KEY, got body" -- 显式设定特定的倒序排序
CREATE TABLE "reversed_user_status_updates" (
"username" text,
"id" timeuuid,
"body" text,
PRIMARY KEY ("username", "id")
) WITH CLUSTERING ORDER BY ("id" DESC); INSERT INTO "reversed_user_status_updates"
("username", "id", "body")
VALUES ('alice', NOW(), 'Reversed status 1');
INSERT INTO "reversed_user_status_updates"
("username", "id", "body")
VALUES ('alice', NOW(), 'Reversed status 2');
INSERT INTO "reversed_user_status_updates"
("username", "id", "body")
VALUES ('alice', NOW(), 'Reversed status 3');
-- 显式倒序排序测试
SELECT * FROM "reversed_user_status_updates"
WHERE "username" = 'alice'; -- 正确 SELECT * FROM "user_status_updates_by_datetime"; SELECT * FROM "user_status_updates_by_datetime"
WHERE "username" = 'alice'
ORDER BY "status_date" ASC, "status_time" ASC; SELECT * FROM "user_status_updates_by_datetime"
WHERE "username" = 'alice'
ORDER BY "status_date" DESC, "status_time" DESC; --错误 SELECT * FROM "user_status_updates_by_datetime"
WHERE "username" = 'alice'
ORDER BY "status_date" ASC, "status_time" DESC; SELECT * FROM "user_status_updates_by_datetime"
WHERE "username" = 'alice'
ORDER BY "status_date" DESC, "status_time" ASC; -- 显式设定特定的倒序-正序排序组合 CREATE TABLE "reversed_user_status_updates_by_datetime" (
"username" text,
"status_date" date,
"status_time" time,
"body" text,
PRIMARY KEY ("username", "status_date", "status_time")
) WITH CLUSTERING ORDER BY ("status_date" ASC, "status_time" DESC); JSON支持
-- 插入JSON,看起来完全不像传统数据库SQL了 INSERT INTO "user_status_updates_by_datetime"
JSON '{"username": "alice", "status_date": "2016-11-24", "status_time":
"13:35:20.123456", "body": "Alice Update 7"}'; SELECT * FROM "user_status_updates_by_datetime";
-- json查询
SELECT JSON * FROM "user_status_updates_by_datetime"
WHERE "username" = 'alice'
AND status_date > '2016-11-20';
Cassandra开发入门文档第二部分(timeuuid类型、复合主键、静态字段详解)的更多相关文章
- Cassandra开发入门文档第三部分(非规范化关系结构、批处理)
非规范化关系结构 第二部分我们讲了复合主键,这可以灵活的解决主从关系,也即是一对多关系,那么多对多关系呢?多对多关系的数据模型应该回答两个问题: 我跟着谁? 谁跟着我? -- 建表,我们发现这里有个不 ...
- Cassandra开发入门文档第五部分(使用场景)
正确建模 开发人员在构建Cassandra数据库时犯的另一个主要错误是分区键的选择不佳.cassandra是分布式的.这意味着您需要有一种方法来跨节点分布数据.Cassandra通过散列每个表的主键( ...
- Cassandra开发入门文档第一部分
Cassandra的特点 横向可扩展性: Cassandra部署具有几乎无限的存储和处理数据的能力.当需要额外的容量时,可以简单地将更多的机器添加到集群中.当新机器加入集群时,Cassandra需要对 ...
- Cassandra开发入门文档第四部分(集合类型、元组类型、时间序列、计数列)
Cassandra 提供了三种集合类型,分别是Set,List,MapSet: 非重复集,存储了一组类型相同的不重复元素,当被查询时会返回排好序的结果,但是内部构成是无序的值,应该是在查询时对结果进行 ...
- 使用DOM进行xml文档的crud(增删改查)操作<操作详解>
很多朋友对DOM有感冒,这里我花了一些时间写了一个小小的教程,这个能看懂,会操作了,我相信基于DOM的其它API(如JDOM,DOM4J等)一般不会有什么问题. 后附java代码,也可以下载(可点击这 ...
- Hibernate入门之主键生成策略详解
前言 上一节我们讲解了Hibernate命名策略,从本节我们开始陆续讲解属性.关系等映射,本节我们来讲讲主键的生成策略. 主键生成策略 JPA规范支持4种不同的主键生成策略(AUTO.IDENTITY ...
- 【简明翻译】Hibernate 5.4 Getting Started Guide 官方入门文档
前言 最近的精力主要集中在Hibernate上,在意识到Hibernate 5 的中文资料并不多的时候,我不得不把目光转向Hibernate的官方doc,学习之余简要翻一下入门文档. 原文地址:htt ...
- Apache BeanUtils 1.9.2 官方入门文档
为什么需要Apache BeanUtils? Apache BeanUtils 是 Apache开源软件组织下面的一个项目,被广泛使用于Spring.Struts.Hibernate等框架,有数千个j ...
- Duilib入门文档提供下载
版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] Duilib入门文档 基本框架 编写界面xml 响应事件 贴图描述 类html文本描述 动态换肤 Dll插件 资源打包 Duil ...
随机推荐
- 数论篇7——组合数 & 卢卡斯定理(Lucas)
组合数 组合数就是高中排列组合的知识,求解组合数C(n,m),即从n个相同物品中取出m个的方案数. 求解方式 求解通式:$C^{m}_{n}=\dfrac {n!}{m!\left( n-m\righ ...
- python与设计模式--单例模式
https://zhuanlan.zhihu.com/p/31675841 设计模式分类 创建类 单例模式.工厂模式.抽象工厂模式.原型模式.建造者模式 结构类 装饰器模式.适配器模式.门面模式.组合 ...
- Locust性能测试6-命令行参数详解
前言 当我们在linux上使用locust工具压测的时候,会使用no-web模式,然后需要收集运行的日志,方便查找问题. 命令行参数 输入locust --help 查看所有的命令行参数 > l ...
- 【Centos】桌面安装(转)
链接:https://www.bnxb.com/linuxserver/27457.html 正常我们在使用CENTOS时候都是不会去用到它的GUI桌面系统,都是用最基础的命令行形式,这样会比较节省服 ...
- python 二、八、十六进制之间的快速转换
一.进制转换 1.2 十进制转二进制 bin(18)--> '0b10010' 去掉0b就是10010 即为十进制18转二进制是10010 十进制转八进制oct(18) --> ...
- export default 和 export 的主要区别
export default 和 export 的主要区别 在于对应的import的区别:export 对应的 import 需要知道 export抛出的变量名或函数名 import{a,b}expo ...
- Objective-C Classes Are also Objects
https://developer.apple.com/library/content/documentation/Cocoa/Conceptual/ProgrammingWithObjectiveC ...
- redux的知名ppt
https://slides.com/jenyaterpil/redux-from-twitter-hype-to-production#/20
- 在Maven项目中,jsp不解析el表达式
我的这个项目是用Maven-archetype-webapp项目创建的,如下图所示: 有这种方式创建有一个坑,就是它使用的servlet版本是2.3,而servlet2.4以下的版本是不会自动解析el ...
- svn服务器命令(转)
*验证svn安装是否成功 #svnadmin --version *创建svn的数据仓库 #svnadmin create /data/svn/svndata/spms *启动svn服务 #svnse ...