基于Spark2.X系列的累加器和Streaming基础
一、累加器API
关于累加器,前面我也写了一篇博客,顺便粘贴这儿,对比学习,Spark学习之编程进阶总结(一)。Spark 2.0系列引入了一个更加简单和更高性能的累加器API,如在1.X版本中可以这样使用累加器:
val sparkSession = SparkSession.builder().master("local").appName("wordcount").getOrCreate()
val sc = sparkSession.sparkContext
sc.setLogLevel("WARN")
// Spark1.x版本 定义累加器,这里直接使用SparkContext内置的累加器
val accum = sc.accumulator(0, "My Accumulator")
sc.parallelize(Array(1,2,3,4)).foreach(x=>accum+=x)
// 获取累加器的值,Executor上面只能对累加器进行累加操作,只要Driver才能读取累加器的值
// Driver读取值的时候会把各个Executor上存储的本地累加器的值加起来,这里的结果是10
println(accum) // 输出10
在Spark 2.X版本里使用SparkContext里内置的累加器:
// 与Spark1.x不同的是,需要指定累加器的类型,目前SparkContext有Long类型和Double类型
// 可以直接使用,不需要指定初始值
val accum1 = sc.longAccumulator("My Accumulator")
sc.parallelize(Array(1,2,3,4)).foreach(x=>accum1.add(x))
println(accum1.value) // 输出10
只使用SparkContext里内置的累加器功能肯定不能满足略微复杂的业务类型,此时我们就可以自定义累加器。这里给出Spark2.X自定义累加器的参考代码
在Scala中有一种方式来自定义累加器,用户只需要继承Accumulable,就可以把元素和返回值定义为不同的类型,这样我们就可以完成添加操作(如往Int类型的List里添加整数,此时元素为Int类型,而返回类型为List)。
在Spark 2.X中加入一个新的抽象类—AccumulatorV2,继承这个类要实现以下几种方法:
add方法:指定元素相加操作。
copy方法:指定对自定义累加器的复制操作。
isZero方法:返回该累加器的值是否为“零”。
merge方法:合并两个相同类型的累加器。
reset方法:重置累加器。
value方法:返回累加器当前的值。
重写这几种方法之后,只需实例化自定义累加器,并连同累加器名字一起传给sparkContext.register方法。
下面简单实现一个把字符串合并为数组的累加器:
// 首先要继承AccumulatorV2,并指定输入为String类型,输出为ArrayBuffer[String]
class MyAccumulator extends AccumulatorV2[String,ArrayBuffer[String]]{
// 设置累加器的结果,类型为ArrayBuffer[String]
private var result = ArrayBuffer[String]() // 判断累加器当前值是否为零值,这里我们指定如果result的size为0,则累加器当前值是零值
override def isZero:Boolean = this.result.size == 0 // copy方法设置为新建本累加器,并把result赋给新的累加器
override def copy():AccumulatorV2[String,ArrayBuffer[String]] = {
val newAccum = new MyAccumulator
newAccum.result = this.result
newAccum
} // reset 方法设置为把result设置为新的ArrayBuffer
override def reset():Unit = this.result = new ArrayBuffer[String]() // add 方法把传进来的字符串添加到result中
override def add(v:String):Unit = this.result+=v // merge 方法把两个累加器的result合并起来
override def merge(other:AccumulatorV2[String,ArrayBuffer[String]]):Unit={
result.++=:(other.value)
} // value 方法返回result
override def value:ArrayBuffer[String] = this.result
}
// 接着在main方法里使用累加器
val Myaccum = new MyAccumulator()
// 向SparkContext注册累加器
sc.register(Myaccum)
// 把 a b c d添加进累加器的result数组并打印出来
sc.parallelize(Array("a","b","c","d")).foreach(x=>Myaccum.add(x))
println(Myaccum.value) // 输出ArrayBuffer(a, b, c, d)
二、Spark2.X Streaming
关于Streaming我以前也有一篇博客,这里粘贴出来对比学习。Spark学习之Spark Streaming。这里写一个程序来监听网络端口发来的内容,然后进行WordCount。
第一步:创建程序入口SparkSession,并引入spark.implicits来允许Scalaobject隐式转换为DataFrame。
第二步:创建流。配置从socket读取流数据,地址和端口为localhost:9999
第三步:进行单词统计。这里lines是DataFrame,使用as[String]给它定义类型转换为DataSet。之后在DataSet里进行单词统计。
第四步:创建查询句柄,定义打印结果方式并启动程序。这里使用writeStream方法,输出模式为全部输出到控制台。
import org.apache.spark.sql.SparkSession
object StreamingTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("StructuredNetworkCount").getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
// 上面变量一定也得为spark
import spark.implicits._
val lines = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
val words = lines.as[String].flatMap(_.split(" "))
val wordcount = words.groupBy("value").count()
val query = wordcount.writeStream.outputMode("complete").format("console").start()
// 调用awaitTermination方法来防止程序在处理数据时停止
query.awaitTermination()
}
}
运行上面的程序首先nc软件要先运行起来,连接成功后再输入下面的字符串。

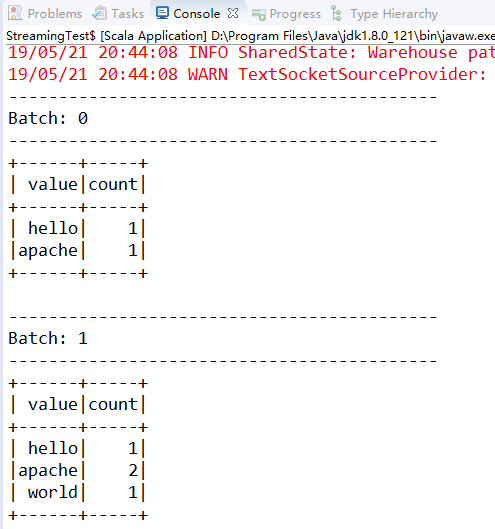
然后控制台打印的结果为:
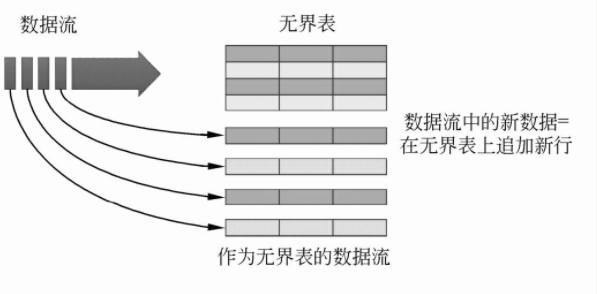
Streaming的关键思想如图所示:把数据流视作一张数据不断增加的表,这样用户就可以基于这张表进行数据处理,就好像使用批处理来处理静态数据一样,但实际上Spark底层是把新数据不断地增量添加到这张无界的表的下一行中。
Structured Streaming共有3种输出模式,这3种模式都只适用于某些类型的查询:
(1)CompleteMode:完整模式。整个更新的结果表将被写入外部存储器。由存储连接器决定如何处理整张表的写入。聚合操作以及聚合之后的排序操作支持这种模式。
(2)AppendMode:附加模式。只有自上次触发执行后在结果表中附加的新行会被写入外部存储器。这仅适用于结果表中的现有行不会更改的查询,如select、where、map、flatMap、filter、join等操作支持这种模式。
(3)UpdateMode:更新模式(这个模式将在以后的版本中实现)。只有自上次触发执行后在结果表中更新的行将被写入外部存储器(不输出未更改的行)。
这篇博文主要来自《Spark大数据商业实战三部曲》这本书里面的第二章,内容有删减,还有本书的一些代码的实验结果。
基于Spark2.X系列的累加器和Streaming基础的更多相关文章
- 基于.NetCore3.1系列 —— 认证授权方案之授权揭秘 (下篇)
一.前言 回顾:基于.NetCore3.1系列 -- 认证授权方案之授权揭秘 (上篇) 在上一篇中,主要讲解了授权在配置方面的源码,从添加授权配置开始,我们引入了需要的授权配置选项,而不同的授权要求构 ...
- 基于.NetCore3.1系列 ——认证授权方案之Swagger加锁
一.前言 在之前的使用Swagger做Api文档中,我们已经使用Swagger进行开发接口文档,以及更加方便的使用.这一转换,让更多的接口可以以通俗易懂的方式展现给开发人员.而在后续的内容中,为了对a ...
- 基于.NetCore3.1系列 —— 日志记录之初识Serilog
一.前言 对内置日志系统的整体实现进行了介绍之后,可以通过使用内置记录器来实现日志的输出路径.而在实际项目开发中,使用第三方日志框架(如: Log4Net.NLog.Loggr.Serilog.Sen ...
- 【Xamarin开发 Android 系列 7】 Android 结构基础(下)
原文:[Xamarin开发 Android 系列 7] Android 结构基础(下) *******前期我们不打算进行太深入的东西,省的吓跑刚进门的,感觉门槛高,so,我们一开始就是跑马灯一样,向前 ...
- 【Xamarin开发 Android 系列 6】 Android 结构基础(上)
原文:[Xamarin开发 Android 系列 6] Android 结构基础(上) 前面大家已经熟悉了什么是Android,而且在 [Xamarin开发 Android 系列 4] Android ...
- C#多线程编程系列(二)- 线程基础
目录 C#多线程编程系列(二)- 线程基础 1.1 简介 1.2 创建线程 1.3 暂停线程 1.4 线程等待 1.5 终止线程 1.6 检测线程状态 1.7 线程优先级 1.8 前台线程和后台线程 ...
- Python学习系列(八)( 面向对象基础)
Python学习系列(八)( 面向对象基础) Python学习系列(七)( 数据库编程) 一,面向对象 1,域:属于一个对象或类的变量.有两种类型,即实例变量—属于每个实例/类的对象:类变量—属于类 ...
- 【MM系列】SAP MM模块-基础配置第一篇
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP MM模块-基础配置第一篇 ...
- SSE图像算法优化系列二十三: 基于value-and-criterion structure 系列滤波器(如Kuwahara,MLV,MCV滤波器)的优化。
基于value-and-criterion structure方式的实现的滤波器在原理上其实比较简单,感觉下面论文中得一段话已经描述的比较清晰了,直接贴英文吧,感觉翻译过来反而失去了原始的韵味了. T ...
随机推荐
- python变量d的说明
[变量] 什么是变量: 变:现实世界中的状态是会发生改变的. 量:记录现实世界中的状态,让计算机能够像人一样去识别世间万物 是变化的量 变量的组成: 变量名:变量名用来引用变量值,但凡需要用变量值,都 ...
- word2vector的tensorflow代码实现
import collections import math import os import random import zipfile import numpy as np import urll ...
- 获取Android包名和activity名
个人主要用2个方法. 方法1:pm list package 方法2: windows:adb shell logcat | findstr START; linux: adb shell logca ...
- Features Track[STL map]
目录 题目地址 题干 代码和解释 参考 题目地址 Features Track(ACM-ICPC 2018 徐州赛区网络预赛 ) 题干 代码和解释 题意:一个动画有许多 n 帧,每帧有 k 个点,点的 ...
- Python3爬取美女妹子图片转载
# -*- coding: utf-8 -*- """ Created on Sun Dec 30 15:38:25 2018 @author: 球球 "&qu ...
- git修改提交作者和邮箱
作用一名程序员,我们会经常混迹与不同的代码仓库,时常不同仓库会有作者信息验证.比如公司内建的gitlab一般会要求统一使用公司内部的域账号签名:github要求使用github账号签名等.因此,很容易 ...
- dashi 成长 > 领导 > 平台 > 钱 人品 态度 能力 价值
https://promotion.aliyun.com/ntms/yunparter/invite.html?userCode=thy3557s https://www.aliyun.com/min ...
- 在idea中打开maven项目pom.xml未识别
在idea中打开maven项目pom.xml没有识别出来,导致idea不能自动下载依赖包, 解决办法是选中pom.xml文件,右键-" add as maven project"
- darkflow测试和训练yolo
转自 https://blog.csdn.net/u011961856/article/details/76582669参考自github:https://github.com/thtrieu/dar ...
- Web API之Web Components
本文参考<你的前端框架要被web组件替代了>. 于2011年面世的Web Components是一套功能组件,让开发者可以使用 HTML.CSS 和 JavaScript 创建可复用的组件 ...