Redis 常用五种数据类型编码
转载请注明出处:
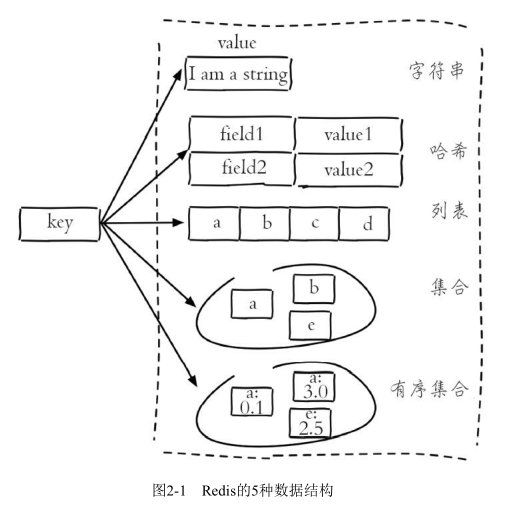
Redis 的五种数据结构
Redis 数据结构的内部编码
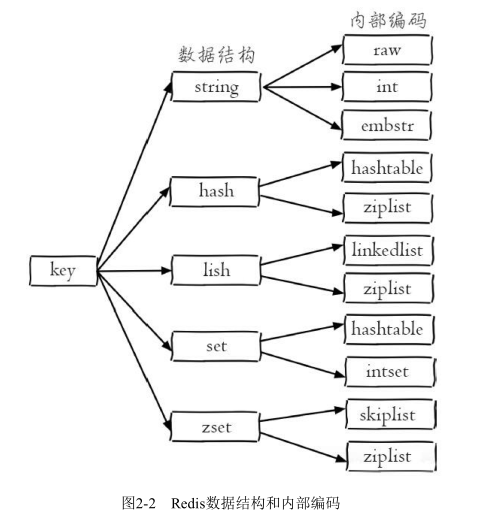
Redis这样设计有两个好处:
第一,可以改进内部编码,而对外的数据结构和命令没有影响,这样一旦开发出更优秀的内部编码,无需改动外部数据结构和命令。
第二,多种内部编码实现可以在不同场景下发挥各自的优势,例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会有所下降,这时候Redis会根据配置选项将列表类型的内部实现转换为linkedlist。
1.String
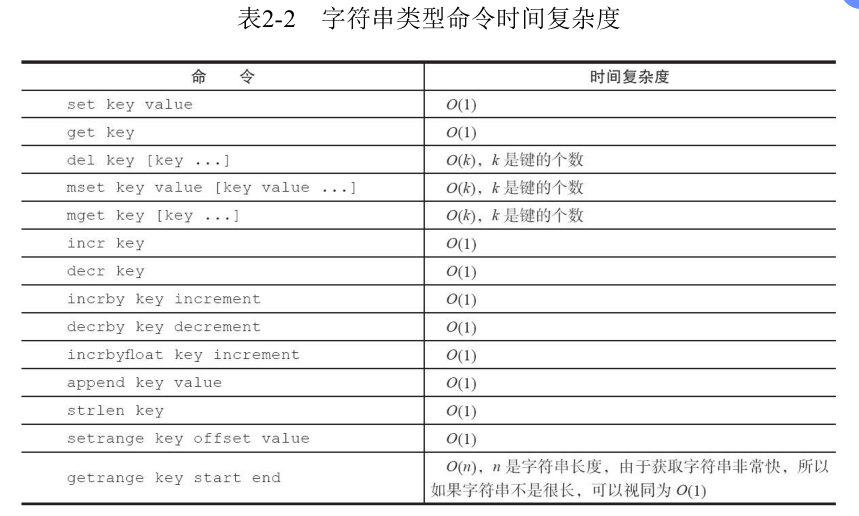
1.1 常用命令
(1)设置值
set key value [ex seconds] [px milliseconds] [nx|xx]
set命令有几个选项:
ex seconds:为键设置秒级过期时间。
px milliseconds:为键设置毫秒级过期时间。
nx:键必须不存在,才可以设置成功,用于添加。
xx:与nx相反,键必须存在,才可以设置成功,用于更新。
除了set选项,Redis还提供了setex和setnx两个命令
(2)获取值
get key
(3)批量设置值
mset key value [key value ...]
(4)批量获取值
mget key [key ...]
(5)计数
incr key
incr命令用于对值做自增操作,返回结果分为三种情况:
值不是整数,返回错误。
值是整数,返回自增后的结果。
键不存在,按照值为0自增,返回结果为1。
除了incr命令,Redis提供了decr(自减)、incrby(自增指定数字)、decrby(自减指定数字)、incrbyfloat(自增浮点数);
(6)字符串长度
strlen key
1.2 内部编码
字符串类型的内部编码有3种:
int:8个字节的长整型。
embstr:小于等于39个字节的字符串。
raw:大于39个字节的字符串。
Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
# 小于等于39个字节的字符串:embstr
127.0.0.1:6379> set key "hello,world"
OK
127.0.0.1:6379> object encoding key
"embstr"
1.3 典型使用场景
1.缓存功能
Redis作为缓存层,MySQL作为存储层,绝大部分请求的数据都是从Redis中获取。由于Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用
2.计数
3.共享Session
用Redis将用户的Session进行集中管理,只要保证Redis是高可用和扩展性的,每次用户更新或者查询登录信息都直接从Redis中集中获取。
4.限速
限制接口不被频繁访问
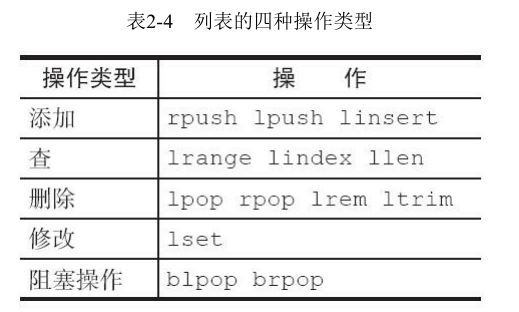
2. Hash
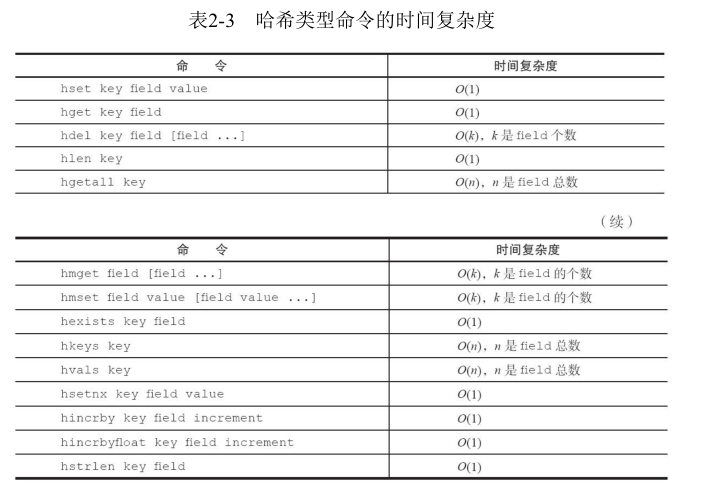
2.1 常用命令及时间复杂度
2.2 内部编码
哈希类型的内部编码有两种:
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2
OK
127.0.0.1:6379> object encoding hashkey
"ziplist"
3.列表
3.1 常用命令及时间复杂度

3.2 内部编码
列表类型的内部编码有两种。
ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时(默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使用。
linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
127.0.0.1:6379> rpush listkey e1 e2 e3
(integer) 3
127.0.0.1:6379> object encoding listkey
"ziplist"
3.3 使用场景
1.消息队列
Redis的lpush+brpop命令组合即可实现阻塞队列,生产者客户端使用lrpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。

2.文章列表
每个用户有属于自己的文章列表,现需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。
4.集合
4.1 常用命令及时间复杂度
集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。
Redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多实际问题。
SADD key member [member ...] //往集合key中存入元素,元素存在则忽略,若key不存在则新建
SREM key member [member ...] //从集合key中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数,scard的时间复杂度为O(1),它不会遍历集合所有元素,而是直接用Redis内部的变量
SISMEMBER key member //判断member元素是否存在于集合key中
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除
SPOP key [count] //从集合key中选出count个元素,元素从key中删除
Set 运算命令
SINTER key [key ...] //交集运算
SINTERSTORE destination key [key ..] //将交集结果存入新集合destination中
SUNION key [key ..] //并集运算
SUNIONSTORE destination key [key ...] //将并集结果存入新集合destination中
SDIFF key [key ...] //差集运算
SDIFFSTORE destination key [key ...] //将差集结果存入新集合destination中

4.2 内部编码
集合类型的内部编码有两种:
intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用。
hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
127.0.0.1:6379> sadd setkey 1 2 3 4
(integer) 4
127.0.0.1:6379> object encoding setkey
"intset"
4.3 使用场景
1. 微博点赞,收藏,标签(给用户添加标签,给标签添加用户),计算用户共同感兴趣的标签
2. 微博或微信中可能认识的人,共同好友,共同关注的话题等。
5.有序集合
5.1 常用命令
它保留了集合不能有重复成员的特性,但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下标作为 排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据。有序集合中的元素不能重复,但是score可以重复;有序集合提供了获取指定分数和元素范围查询、计算成员排名等功能
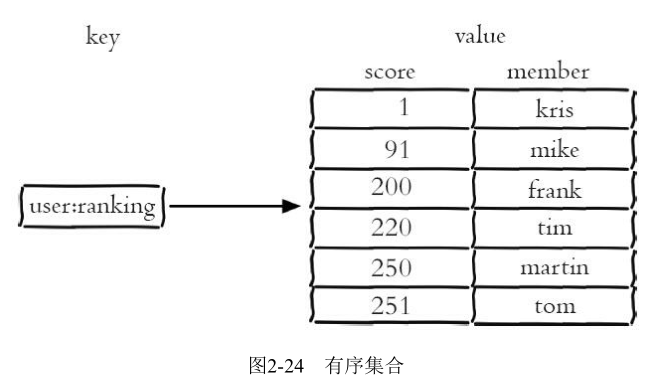
ZADD key score member [[score member]…] //往有序集合key中加入带分值元素
ZREM key member [member …] //从有序集合key中删除元素
ZSCORE key member //返回有序集合key中元素member的分值
ZINCRBY key increment member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素 ZUNIONSTORE destkey numkeys key [key ...] //并集计算
ZINTERSTORE destkey numkeys key [key …] //交集计算
5.2 内部编码
有序集合类型的内部编码有两种:
ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,ziplist 可以有效减少内存的使用。
skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时ziplist的读写效率会下降。
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3
(integer) 3
127.0.0.1:6379> object encoding zsetkey
"ziplist"
5.3 使用场景
榜单排名,热点排名
Redis 常用五种数据类型编码的更多相关文章
- Redis: Redis支持五种数据类型
ylbtech-Redis: Redis支持五种数据类型 Redis支持五种数据类型:string(字符串) ,hash(哈希),list(列表),set(集合)及zset(sorted set:有序 ...
- 【快速掌握】Redis 的五种数据类型
不同于MySQL的表结构所带来的复杂语句,Redis只需要维护好它的[key-value]结构就可以,因此相比于MySQL,语句非常简单. 今天介绍一下Redis 五种常用的数据类型: 这五种数据类型 ...
- redis的五种数据类型及应用场景
前言 redis是用键值对的形式来保存数据,键类型只能是String,但是值类型可以有String.List.Hash.Set.Sorted Set五种,来满足不同场景的特定需求. 本博客中的示例不是 ...
- Redis的五种数据类型的简单介绍和使用
1.准备工作: 1.1在Linux下安装Redis https://www.cnblogs.com/dddyyy/p/9763098.html 1.2启动Redis 先把root/redis的red ...
- [Redis]Redis的五种数据类型与键值/服务器相关命令
-------------------------------------------------------------------------------------- String(字符串):最 ...
- StackExchange.Redis学习笔记(二) Redis查询 五种数据类型的应用
ConnectionMultiplexer ConnectionMultiplexer 是StackExchange.Redis的核心对象,用这个类的实例来进行Redis的一系列操作,对于一个整个应用 ...
- Redis的五种数据类型及方法
字符串string: 字符串类型是Redis中最为基础的数据存储类型,是一个由字节组成的序列,他在Redis中是二进制安全的,这便意味着该类型可以接受任何格式的数据,如JPEG图像数据货Json对象描 ...
- Redis的五种数据类型
官方的几篇很好的文章: https://redis.io/topics/data-types https://redis.io/topics/data-types-intro https://redi ...
- Redis:五种数据类型的简单增删改查
Redis简单增删改查例子 例一:字符串的增删改查 #增加一个key为ay_key的值 127.0.0.1:6379> set ay_key "ay" OK #查询ay_ke ...
- Redis探索之路(四):Redis的五种数据类型Set和ZSet
一:Set无需集合 Set是个集合,string类型的无需集合,通过hash table实现,添加删除查找复杂度都是0(1).对集合我们可以取并集,交集和差集.通过这些操作我们可以实现sns中的好友推 ...
随机推荐
- 【笔记整理】[案例]爱词霸翻译post请求
import json if __name__ == '__main__': import requests resp = requests.post( url="http://ifanyi ...
- 数字孪生结合GIS会给矿业带来怎样的改变
数字孪生技术和GIS的结合为矿业带来了革命性的改变.矿业作为重要的经济支柱,其发展与资源的开采.生产过程的管理密切相关.通过数字孪生和GIS的融合,矿业行业可以实现更高效.可持续的运营和管理,带来许多 ...
- Meta3D -- 开源的Web3D低代码平台
大家好,Meta3D是开源的Web3D低代码平台,快速搭建Web3D编辑器,共建开放互助的web3d生态 Github 进入平台 功能演示 加入UI Control 加入Action脚本 运行&quo ...
- @Value是个什么东西
对注解不了解的可以看一下: Java注解,看完就会用 首先我们要明确: @Value 是 Spring 框架的注解. 它有什么作用呢? 作用 @Value 通过注解将常量.配置文件中的值.其他bean ...
- 设置CentOS7使用代理服务器上网
用三种方法设置CentOS7使用代理服务器上网 https://zhangyujia.cn/?p=1206 https://www.cnblogs.com/a-du/p/8964048.html 一. ...
- fence的使用
一.创建一个集群及pcs安装 1.真机切换root用户下 2.打开PC管理器视图 1.安装pcs,关掉防火墙,重启pcs和下次开机自动启动pcs 1.创建一个集群,用户:hacluster:密码:re ...
- Ynoi
P4688 [Ynoi2016] 掉进兔子洞 序列,静态,求三个区间的可重集的交的大小,离线,\(n,Q\le 10^5\),3s,500MB 缺乏性质 \(\rightarrow\) bitset ...
- linux中创建用户组
1.打开终端并以 root 用户身份登录到 Linux 系统. 2.运行以下命令以创建一个用户组: sudo groupadd group_name 将 "group_name" ...
- 在线编辑Word——插入内容控件
内容控件是可添加和自定义的以在模板.窗体和文档中使用的单个控件.Word中支持添加多种类型的控件用于不同文档的设计需求.本文,将通过在线编辑的方式展示如何在Word中插入内容控件,这里使用的在线编辑器 ...
- 第四部分_Shell脚本数组和其他变量
数组定义 ㈠ 数组分类 普通数组:只能使用整数作为数组索引(元素的下标) 关联数组:可以使用字符串作为数组索引(元素的下标) ㈡ 普通数组定义 可以切片 一次赋予一个值 #数组名[索引下标]=值 ar ...