Stable Diffusion(三)Dreambooth finetune模型
1. Dreambooth
Dreambooth可以把你任何喜欢的东西放入Stable Diffusion模型。
1.1. 什么是Dreambooth
最初由谷歌在2022年发布,是对SD模型的fine-tune技术。可以把自己喜欢的东西注入到SD模型中。
为什么称为Dreambooth?根据谷歌团队的解释:它就像一个照相馆,在对这个东西拍照后,就可以合成到你梦想中的任何地方。
下面是论文中给的一个例子,仅使用这条狗的3张图片(这里为其取名为Devora),dreambooth调优后的模型即可生成这条狗在不同风格下的图片:

1.2. Dreambooth工作原理
为什么不能直接使用这些新图片以及额外的训练step来训练模型呢?因为这样会造成过拟合以及语言漂移language drift,从而导致无法达到目的。
(什么是语言漂移:一个例子是社交媒体上的文本数据。社交媒体的语言使用和风格会随着时间的推移而发生变化,例如,一个词汇在某个时期可能是流行的,但在另一个时期可能已经过时了。如果使用旧数据来训练自然语言处理模型,并在处理新数据时使用该模型,由于语言漂移的影响,模型可能无法正确处理新的社交媒体文本数据。例如,一个过时的模型可能无法正确处理最新的俚语或缩写词。因此,为了解决语言漂移问题,需要定期更新模型以适应新的语言使用和风格。)
Dreambooth解决这两个问题的方式:
- 使用一个很罕见的词来表示新的对象,这样它在模型中一开始就没有太多意义
- 保留先前的类别:为了保留类别的含义,例如,为了保留原始模型中“dog”的含义,模型被微调以在保留类别(狗)的图像生成的同时注入主题(Devora)。
除了Dreambooth外,还有另一种类似的技术叫textual inversion。它们之间的区别是:Dreambooth会微调整个模型,而textual inversion是注入一个新的单词(而不是重复使用一个罕见的单词),并且只微调模型的text embedding部分。
2. 训练Dreambooth准备
训练Dreambooth需要准备:
- 几张训练图片
- 一个特定的标识(unique identifier)
- 一个类别名(class name)
在上面那个例子中,标识是“Devora”,类别是“dog”。
然后构建我们的提示词:
a photo of [unique identifier] [class name]
(例如a photo of Devora dog)
以及类别提示词:
a photo of [class name]
(例如a photo of a dog)
2.1. 为webUI安装Dreambooth插件
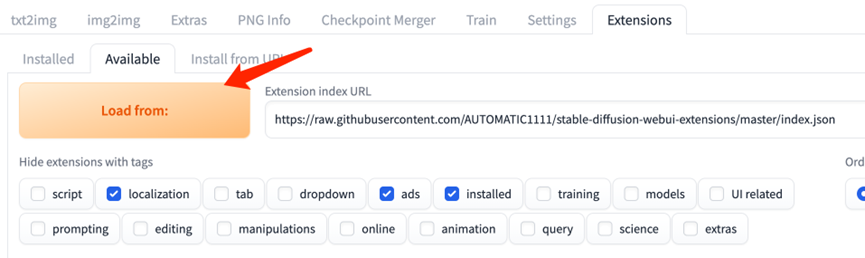
可能会遇到下面的问题:
assert not shared.cmd_opts.disable_extension_access, "extension access disabled because of command line flags"
在启动命令里加上--enable-insecure-extension-access 即可解决。
2.2. 准备图片与模型
首先准备一个物品的几张图片,使用不同的角度拍摄。最好是不同背景,让模型可以区分背景。
我们使用3张兔子图片:



首先将它们裁剪为512 x 512 大小,可以使用工具BIRME
然后把图片上传到web UI所在机器。
2.3. 创建模型
在Dreambooth tab里,先创建一个模型,输入模型的名称,并选择要从哪个checkpoint开始进行训练。
(如果是要从Hagging Face加载模型,也可以指定模型的url与token。URL的格式应为‘runwayml/stable-diffusion-v1-5’这种。原始checkpoint会提取到models/dreambooth/MODELNAME/working目录)
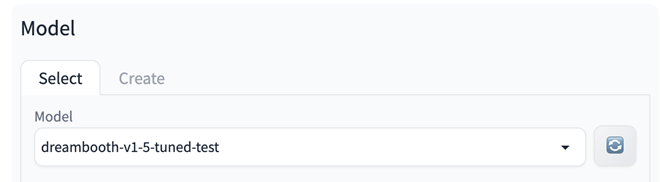
然后点击Create,耗时1-2分钟左右。创建完毕后,UI会显示新模型目录已经设置好。

选择刚创建好的模型:
3. Class概念解释
在对图片与其描述(对图片内容的描述)进行训练时,模型会将每个输入的图片 与 图片对应的描述(描述里的每个单词)进行关联。而如果我们是要训练一个特定的对象(例如人),则这种方式是达不到我们预期效果的。
举个例子,假设我们要训练一个“施瓦辛格”的模型。我们有他3张instance图片,并分别使用下面的描述:
- Arnold Schwarzenegger, man, sunglasses, black coat, muscular, scene from Terminator
- Arnold Schwarzenegger, man, suit, red tie, smiling
- Arnold Schwarzenegger, muscular, smiling, man, flexing, black and white
如果我们训练这些图片时,不使用类别图片(Class Images)。模型最终可能可以生成很好的施瓦辛格图片。但是,描述里的其他单词也会被影响。例如,如果在结果模型中使用提示词man,则会输出像施瓦辛格的男人。一个单词在描述里出现的频率越高,则受影响的程度越大。不常见的单词同样在训练中也越容易受到影响,所以单词“man”相对于单词“Governator”则需要更多的训练进行影响。
这里就是类别图片作用的地方。假设我们使用同样的描述,但是使用以下配置:
- Instance Token = Arnold Schwarzenegger
- Class Token = man
- Instance Prompt = [filewords]
- Class Prompt = [filewords]
- # Class Images = 1
对图片的描述会处理为下面的类别描述:
- man, sunglasses, black coat, muscular, scene from Terminator
- man, suit, red tie, smiling
- muscular, smiling, man, flexing, black and white
这个插件会为每张Instance图片生成1个类别图片(Class Image)。这些类别图片以及描述,会组成一对,然后与Instance图片一起送入dreambooth。现在单词“man”就会在施瓦辛格以及其他的(假设为随机)3张 man 的类别图片上进行训练。这样就可以保留原始模型对单词“man”的概念。
如果我们有一个小的数据集,或者是要做一个大规模的训练。则为每个图片生成1张类别图可能是不够的。在施瓦辛格的例子中,“man”可能会生成看起来像施瓦辛格或是类别图片中的男人。如果所有的类别图片中,男人都是秃头,则“man”可能就会偏向为生成秃头的男人。通过调整Class Images的倍数#,我们可以引入更多的随机生成的“man”图片,也就会引入更多模型对与“man”的概念,从而减少训练模型时的bias。
最后提一下关于实现类图片的重要事项。每个Instance 图片以及1张关联的类别图片,会在每个epoch中一起送入dreambooth。(这里在使用多个images buckets时,会增加一些复杂度,但是我们可以忽略)。
增加类别图片数量不会增加输入到dreambooth中instance图片的类别比率。类别图片的权重由Prior Weight Loss决定:
- Prior Weight Loss = 1.0:可能太高,生成的对象会非常像类别图像
- Prior Weight Loss = 0.01:太低,类别图像会被忽略
- Prior Weight Loss = 0.15 – 0.4之间:一般是合理的区域
4. 配置参数
各个部分的配置下面具体解释。
4.1. Setting部分
可以按照Performance Wizard作为starting point(可能不是最优的)。
General
可以选择训练的方法,例如LoRa。其他方法可以让训练运行在性能一般的机器上,但是会损失生成图片的质量。这些方法包括(生成质量高到低排序):
- Dreambooth(默认,需要VRAM >= 10GB)
- LoRa Extended(需要 VRAM >= 8GB)
- LoRa(需要VRAM >= 6GB)
- Imagic(???)
Intervals
每个图片训练的步数(epochs),也就是每张图片被用于训练的次数。默认100是推荐值。
Save Preview(s) Frequency(Epochs) 是指定在训练过程中,生成sample图片的频率。
Batching
使用默认推荐即可
Learning Rate
2e-6是一个推荐的初始值
LoRa使用另一组Learning Rate字段,因为LR的值在LoRa里会比较高(相对于dreambooth)。对LoRa来说,LR的默认值为1e-4 for UNET,以及5e-5 for Text。
LR scheduler可以让我们控制LR在训练过程中如何变化。默认为constant_with_warmup(指定为0 warmup step)。对初学者来说,推荐warmup设置为500。资深玩家可以尝试微调此值。
Image Processing
初学者建议保留默认配置
Tuning
对初学者来说,Performance Wizard已经够用了(除了Text Encoder)。不过也可以尝试调整:
- Memory Attention:default(如果使用Torch2,且VRAM >= 16GB)
- Cache Latents:基本上always选择
- Step Ratio of Text Encoder Training:0(text encoder有些奇怪的点,参考advanced guide)
Prior Loss Weight:如果使用class images的话,这个参数很重要。如果没用class images,则Prior Loss Weight就无意义。它决定给class images多少权重(更高的值=更多的class weight)。如果我们没有得到足够的训练,则减少Prior Loss Weight。If your concept is "bleeding" beyond the desired tokens, increase Prior Loss Weight。
Advanced
新用户建议这部分保留默认值。
4.2. Concepts部分
Directories
设置Dataset Directory为训练图片的目录。如果需要重用之前的class images,则Classification Dataset Directory可以为空。
如果训练目标是训练一个风格,则可以跳过下面的tab。
Training Prompts
Instance Prompt:对实例图片的描述(也就是你训练图片的描述)。如果使用了描述(captions),可以填写 [filewords],此时instance prompt就会替代描述。例如,假设我们训练一张猫的图片,称为Rufus。我们可能会填写 photo of Rufus。或者更好的是,给Instance Prompt填写 [filewords],然后使用例如close up photo of Rufus 或 Rufus wearing a cowboy hat的描述(captions)。
Class Prompt是排除concept后,对图片的描述。
我们可以给Class Prompt填写 [filewords],然后我们对图片的描述就会用于生成类别图片。在上面猫的例子中,Rufus是一只猫,所以我们的类别提示词可能是:photo of a cat。越贴近类别含义越好。
Classification Image Negative Prompt仅用于类别图片的生成(也就是不会送入dreambooth的图片)。工作原理与txt2img negatives prompts类似,例如可以输入worst quality,low quality。
Filewords
如果没在Instance Prompt(对对象的描述,例如photo of zwxrabbit toy)或Class Prompt(对类别的描述,例如photo of a toy)中使用filewords,则可以跳过这部分。
Instance 与 Class Token,它们是和我们的prompts混用的。从传统意义上来说,Instance Token是我们在训练完成后,用来唤起训练后对象的token。而Class Token是对这个对象类别的1-2个单词的描述。
在前面的例子中,Instance Token可以是Rufu,而Class Token可以是cat。这些token会与我们的Instance Prompt以及Class Prompt混在一起。参考下面的例子:
假设我有3张Rufus的图片,使用下面3个描述:
- A photo of Rufus dancing
- Close up,bedroom background
- Rufus the cat
则配置项可以是:
- Instance Token:Rufus
- Class Token:cat
- Instance Prompt:[filewords]
- Class Prompt:[filewords]
从而被送入dreambooth的instance images的描述为:
- A photo of Rufus cat dancing
- Rufus cat, Close up, bedroom background
- Rufus the cat
以及生成的类别图片时会使用:
- A photo of cat dancing
- cat, Close up, bedroom background
- the cat
注意:我们的Instance Token(与其他所有tokens一样)会从source model继承它的value。出于这个原因,Instance Token最好是一个全新的词。
4.3. Sample Prompts
Sample Image Prompt以及Sample Negative prompt是用于生成sample图片的提示词。生成的过程在训练过程中以及结束后。这里也可以使用 [filewords],例如,我们可能会设置:
l Save Preview(s) Frequency (Epochs) = 10
l Sample Image Prompt = [filewords]
l Sample Negative Prompt = worst quality, low quality
l Number of Samples to Generate = 5
每10秒生成5张sample图片。
4.4. Saving tab
General and Checkpoints and Diffusion Weights
这是保存的行为,默认对大部分人是适用的。
在训练过程中生成 .ckpt 文件并保存,需要同时与Save Model Frequency (Epochs) 选项一起使用。
Lora
LoRa UNET以及Text Encoder Rank基本上是Lora输出的质量控制参数。更高的ranks = 更高的质量 = 更大的输出文件。我们建议初始值设置为 32,会产生约 100MB 左右的输出文件。
当LoRa启用时,Checkpoints设置会用于生成LoRa引入的checkpoints。但是,我们推荐关闭这个功能,并使用LoRa Weights设置(在LoRa设置的底部)。LoRa Weights设置控制了输出到models/Lora 目录的内容。若是要使用更小的LoRa模型,可以安装a1111-sd-webui-locon 插件。
5. 开始训练
5.1. 直接使用Dreambooth
图片路径为:
/home/ubuntu/stable-diffusion-webui/dreambooth-train/myimg
使用Training Prompt为:

photo of tangrabbittoy
photo of a toy
然后开始训练。可能遇到报错,建议启动命令改为:
nohup ./webui.sh --listen --enable-insecure-extension-access --no-gradio-queue &
遇到报错:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 14.61 GiB total capacity; 12.68 GiB already allocated; 271.12 MiB free; 13.11 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
说明显存不够直接训练dreambooth。
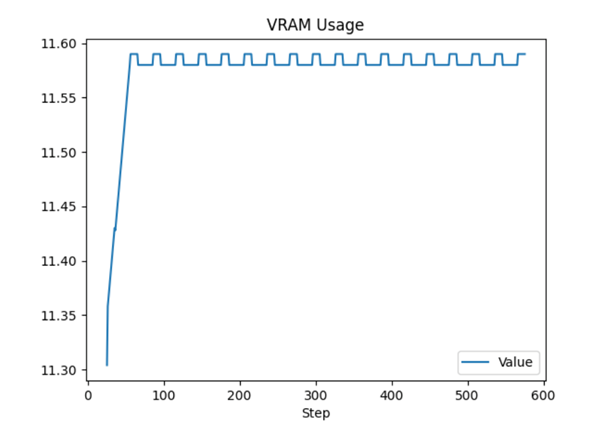
然后换了 pytorch 的deep learning AMI,可以正常完成训练。显存使用量为:
5.1. 使用LoRa Extended
如果机器显存不够直接训练dreambooth,我们也可以使用Lora Extended进行训练:

训练结束:

可以看到显存使用明显减少,在7.8GB左右:

6. 使用新模型
然后即可使用新模型

测试用提示词:
oil painting of tangrabbittoy in style of van gogh
6.1. 直接使用Dreambooth生成的模型

6.2. 使用Lora训练的模型
使用Lora训练的模型,生成的图片为:

可以看到保留了我们之前的兔子玩具的特征。
使用更高的CFG的话,会更接近:

7. LoRA模型
LoRA模型是小型的Stable Diffusion模型,对标准的checkpoint应用了微小的变化。一般来说比标准模型的checkpoint要小10-100倍。
7.1. 什么是LoRA模型
LoRA(Low-Rank Adaptation)是对Stable Diffusion模型的一种训练技术。那为什么已经有了dreambooth和textual inversion,还要用LoRA呢?因为它对文件大小以及训练资源提供了一个很好的权衡。Dreambooth的能力非常强大,但是由于它训练的是整个模型,所以最终生成的chekcpoint文件非常大(一般在2-7GB左右)。而Textual inversion虽然生成的文件较小(100KB左右),但是它的能力有限,能做的事情不多。
LoRA的定位就在它俩之间。它生成的文件不大(2-200 MB),并且使用的训练资源也相对Dreambooth更少。
与textual inversion一样,LoRA模型也不能单独使用。它必须要与一个模型的checkpoint文件共同使用。LoRA通过修改伴生模型的文件来实现风格的修改。
7.2. LoRA的工作原理
LoRA会将小部分变更应用到SD模型里最关键的部位:cross attention 层。这部分是图片和prompt组合到一起的层。
研究人员发现,仅需要对模型的这部分进行fine-tune,即足够达到一个很好的训练结果。下图中黄色部分即为cross- attention层:

cross-attention层里的权重保存在矩阵中,而LoRA模型做fine-tune时,便是将其自身的权重加到这些矩阵上。
既然LoRA要存储同样数量的权重,为什么LoRA的文件要更小呢?这是因为LoRA是将1个矩阵分解为了2个小的低阶(low-rank)矩阵。这样使用的存储空间更小。下面具体解释其原理。
假设模型有一个1000行 x 2000列的矩阵,则需要存储 2,000,000(1,000 x 2,000)个数值来保存模型。LoRA会将这个矩阵分解为1个 1,000 x 2 的矩阵 和 1个2 x 2,000的矩阵。这样存储的数值就仅为 6,000个,减少了333倍。这也就是为什么LoRA文件小的多。

在这个例子中,矩阵的阶(rank)为2,最低可以为1。由于它比原始维度要小得多,所以叫low-rank矩阵。研究人员发现,在使用了这种降维方式后,不会影响对cross-attention层的fine-tune,所以可以放心用来微调模型。
7.3. 使用LoRA模型
可以在Civitai与HuggingFace上找到各种公开的LoRA模型。
在使用时,需要将下载后的LoRA模型放入stable-diffusion-webui/models/Lora/下。
例如,我们下载名为“墨心”(中国古风风格)的LoRA模型,并放在目标目录下:
https://civitai.com/models/12597/moxin
然后即可在web-ui找到对应LoRA模型:
“墨心”推荐的base模型为ChilloutMix、国风3.2等,可以去下载对应的模型。但下面我们仍使用stable-diffusion v1.5进行演示。
在使用LoRA模型时,prompt有固定的格式:<lora:filename:multiplier>
其中filename为加载的LoRA模型名称,multiplier表示应用LoRA模型的权重(值为0-1之间,0表示不使用LoRA模型)。点击上图的Moxin_10即可自动填写prompt。
需要注意:
- 有些LoRA模型是用Dreambooth训练得来,可能需要特定关键词出发,对此需参考模型说明
- 可以同时使用多个LoRA模型
使用positive prompt:
<lora:Moxin_10:1>, chinese painting, half body, female, perfect symmetric face, detailed chinese dress, mountains, flowers, 1girl, tiger
Negative prompt:
disfigured, ugly, bad, immature
生成的图片如:

Stable Diffusion(三)Dreambooth finetune模型的更多相关文章
- 使用 LoRA 进行 Stable Diffusion 的高效参数微调
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题.目前超过数十亿以上参数的具有强能力的大 ...
- AI绘画提示词创作指南:DALL·E 2、Midjourney和 Stable Diffusion最全大比拼 ⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 自然语言处理实战系列:https://www.showmeai.tech ...
- 从 GPT2 到 Stable Diffusion:Elixir 社区迎来了 Hugging Face
上周,Elixir 社区向大家宣布,Elixir 语言社区新增从 GPT2 到 Stable Diffusion 的一系列神经网络模型.这些模型得以实现归功于刚刚发布的 Bumblebee 库.Bum ...
- Diffusers中基于Stable Diffusion的哪些图像操作
目录 辅助函数 Text-To-Image Image-To-Image In-painting Upscale Instruct-Pix2Pix 基于Stable Diffusion的哪些图像操作们 ...
- AI 绘画咒语入门 - Stable Diffusion Prompt 语法指南 【成为初级魔导士吧!】
要用好 Stable Diffusion,最最重要的就是掌握 Prompt(提示词).由于提示词对于生成图的影响甚大,所以被称为魔法,用得好惊天动地,用不好魂飞魄散 . 因此本篇整理下提示词的语法(魔 ...
- 基于Docker安装的Stable Diffusion使用CPU进行AI绘画
基于Docker安装的Stable Diffusion使用CPU进行AI绘画 由于博主的电脑是为了敲代码考虑买的,所以专门买的高U低显,i9配核显,用Stable Diffusion进行AI绘画的话倒 ...
- Stable Diffusion魔法入门
写在前面 本文为资料整合,没有原创内容,方便自己查找和学习, 花费了一晚上把sd安装好,又花了大半天了解sd周边的知识,终于体会到为啥这些生成式AI被称为魔法了,魔法使用前要吟唱类比到AI上不就是那些 ...
- Stable Diffusion 关键词tag语法教程
提示词 Prompt Prompt 是输入到文生图模型的文字,不同的 Prompt 对于生成的图像质量有较大的影响 支持的语言Stable Diffusion, NovelAI等模型支持的输入语言为英 ...
- 最新版本 Stable Diffusion 开源AI绘画工具之部署篇
目录 AI绘画 本地环境要求 下载 Stable Diffusion 运行启动 AI绘画 关于 AI 绘画最近有多火,既然你有缘能看到这篇文章,那么相信也不需要我过多赘述了吧? 随着 AI 绘画技术的 ...
- 最新版本 Stable Diffusion 开源 AI 绘画工具之汉化篇
目录 汉化预览 下载汉化插件一 下载汉化插件二 下载汉化插件三 开启汉化 汉化预览 在上一篇文章中,我们安装好了 Stable Diffusion 开源 AI 绘画工具 但是整个页面都是英文版的,对于 ...
随机推荐
- docker-compose安装EFK
一.环境 IP 系统 配置 版本 192.168.10.100 Centos7.9 2核4G Docker Compose version v2.19.1.EFK-7.17.11 EFK版本是试用版本 ...
- Jetpack Compose(6)——动画
目录 一.低级别动画 API 1.1 animate*AsState 1.2 Animatable 1.3 Transition 动画 1.3.1 updateTransition 1.3.2 cre ...
- linux文本三剑客之awk详解
linux文本三剑客之awk详解 目录 linux文本三剑客之awk详解 1.awk命令详解 1.1 awk的处理流程 1.2 awk中的变量 1.2.1 内置变量 1.2.2 自定义变量 1.3 a ...
- GPS坐标、火星坐标、百度坐标之间的转换--提供java版本转换代码
参考文章:https://www.jianshu.com/p/c39a2c72dc65?from=singlemessage 1.国内几种常用坐标系说明 (1)名词解释 坐标系统:用于定位的系统,就跟 ...
- 适用于任何设备的屏幕共享应用程序 – Mirroring360
Mirroring360 适用于 Windows.Mac.iOS.Android 和 Chromebook 设备的屏幕镜像和屏幕共享,非常适合商务和教育! 屏幕共享应用程序可以帮助增强业务专业人员,讲 ...
- Spring6 的JdbcTemplate的JDBC模板类的详细使用说明
1. Spring6 的JdbcTemplate的JDBC模板类的详细使用说明 @ 目录 1. Spring6 的JdbcTemplate的JDBC模板类的详细使用说明 每博一文案 2. 环境准备 3 ...
- 网络安全—模拟ARP欺骗
文章目录 网络拓扑 安装 使用 编辑数据包 客户机 攻击机 验证 仅做实验用途,禁止做违法犯罪的事情,后果自负.当然现在的计算机多无法被欺骗了,开了防火墙ARP欺骗根本无效. 网络拓扑 均使用Wind ...
- 2022年官网下安装ActiveMQ最全版与官网查阅方法
目录 一.环境整合 构建工具(参考工具部署方式) 二.下载安装 1.百度搜索ActiveMQ,双击进入.或访问官网https://activemq.apache.org/ 2.进入下载界面,两种方式, ...
- kubernetes 之二进制方式部署
我的资料链接:https://pan.baidu.com/s/18g0sar1N-FMhzY-FCMqOog 两种集群架构图 多master需要在集群上面加个lb,所有的node都需要连接lb,lb帮 ...
- Swoole 实践篇之结合 WebSocket 实现心跳检测机制
原文首发链接:Swoole 实践篇之结合 WebSocket 实现心跳检测机制 大家好,我是码农先森. 引言 前段时间在 Swoole 的交流群里,有群友提问:"如何判断用户端是否在线&qu ...