【转载】 SLI导致双显卡被TensorFlow同时占用问题(Windows下) ---------- (windows环境下如何为tensorflow安装多个独立的消费级显卡)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/qq_21368481/article/details/81907244
————————————————
转载 注明:
突然想给自己的电脑上tensorflow环境下安装多独立显卡,网上搜索发现这篇文章,该篇文章主要是在windows环境下为tensorflow安装多个独立显卡。
本文逻辑:
windows环境下安装多个独立显卡,如果不使用sli技术,则Windows不识别多个独立显卡,但是使用sli技术,则不能指定单独显卡为tensorflow进行计算,因为指定单独显卡后slave显卡的显存占用会和master显卡的显存占用进行同步,也就是即使指定了一个显卡参与运算但是另一个显卡的显存会随之同步变化,本文作者提出一个方法解决这个问题:Windows环境下两显卡进行物理桥接后在软件上关闭桥接功能,便可实现Windows环境下双显卡识别及单显卡指定运算。
原文如下:
---------------------------------------
最近学习TensorFlow,被一些不是bug的问题折腾的头晕脑胀,借此写一下解决方法。本人是在win10下使用TensorFlow的,所以ubuntu下的绕行吧,不会出现这些问题。(此文有些地方我重新整理了一遍,放在了相约机器人公众号上,大家可以参见链接)
众所周知,TensorFlow在运行时,会抢占所有检测到的GPU的显存,这种做法褒贬不一吧,只能说,但怎么单独设置使用哪几块显卡呢,唯一的方法就是利用CUDA本身隐藏掉某些显卡(除此之外就是拔掉多余显卡了,大家应该不会傻到这么去做),有些教辅书或网上教程中写的以下方法都是治标不治本的:
(1)使用with.....device语句
例如
with tf.device("/gpu:1"):
这只是指定下面的程序在哪块GPU上执行,程序本身还是会占用所有GPU的资源(信不信由你)
(2)使用allow_growth=True或per_process_gpu_memory_fraction
例如
import tensorflow as tf
g = tf.placeholder(tf.int16)
h = tf.placeholder(tf.int16)
mul = tf.multiply(g,h)
gpu_options = tf.GPUOptions(allow_growth = True)
# gpu_options = tf.GPUOptions ( per_process_gpu_memory_fraction = 0.7 )
config = tf.ConfigProto(log_device_placement = True,allow_soft_placement = True,gpu_options = gpu_options)
with tf.Session(config=config) as sess:
print("相乘:%d" % sess.run(mul, feed_dict = {g:3,h:4}))
前者能够实现随着程序本身慢慢增加所占用的GPU的显存,但仍旧会占用所有GPU,如下:

上图为程序运行前,下图为程序运行后,可见程序运行后,两块GPU均被占用了,但实际上只有GPU0执行了上述程序:

C:\Users\B622>python
Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
>>>
>>> g = tf.placeholder(tf.int16)
>>> h = tf.placeholder(tf.int16)
>>> mul = tf.multiply(g,h)
>>>
>>> gpu_options = tf.GPUOptions(allow_growth = True)
>>> #gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.7)
... config = tf.ConfigProto(log_device_placement = True,allow_soft_placement = True,gpu_options = gpu_options)
>>> with tf.Session(config=config) as sess:
... print("相乘:%d" % sess.run(mul, feed_dict = {g:3,h:4}))
...
2018-08-21 07:00:01.651592: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2018-08-21 07:00:01.927932: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1356] Found device 0 with properties:
name: GeForce GTX 1080 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.721
pciBusID: 0000:17:00.0
totalMemory: 11.00GiB freeMemory: 9.10GiB
2018-08-21 07:00:02.025456: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1356] Found device 1 with properties:
name: GeForce GTX 1080 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.721
pciBusID: 0000:65:00.0
totalMemory: 11.00GiB freeMemory: 9.10GiB
2018-08-21 07:00:02.030441: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1435] Adding visible gpu devices: 0, 1
2018-08-21 07:00:03.036953: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-08-21 07:00:03.040347: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:929] 0 1
2018-08-21 07:00:03.042564: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:942] 0: N N
2018-08-21 07:00:03.044994: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:942] 1: N N
2018-08-21 07:00:03.047419: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 8806 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:17:00.0, compute capability: 6.1)
2018-08-21 07:00:03.054450: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:1 with 8806 MB memory) -> physical GPU (device: 1, name: GeForce GTX 1080 Ti, pci bus id: 0000:65:00.0, compute capability: 6.1)
Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:17:00.0, compute capability: 6.1
/job:localhost/replica:0/task:0/device:GPU:1 -> device: 1, name: GeForce GTX 1080 Ti, pci bus id: 0000:65:00.0, compute capability: 6.1
2018-08-21 07:00:03.064623: I T:\src\github\tensorflow\tensorflow\core\common_runtime\direct_session.cc:284] Device mapping:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:17:00.0, compute capability: 6.1
/job:localhost/replica:0/task:0/device:GPU:1 -> device: 1, name: GeForce GTX 1080 Ti, pci bus id: 0000:65:00.0, compute capability: 6.1 Mul: (Mul): /job:localhost/replica:0/task:0/device:GPU:0
2018-08-21 07:00:03.074668: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] Mul: (Mul)/job:localhost/replica:0/task:0/device:GPU:0
Placeholder_1: (Placeholder): /job:localhost/replica:0/task:0/device:GPU:0
2018-08-21 07:00:03.078028: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] Placeholder_1: (Placeholder)/job:localhost/replica:0/task:0/device:GPU:0
Placeholder: (Placeholder): /job:localhost/replica:0/task:0/device:GPU:0
2018-08-21 07:00:03.081462: I T:\src\github\tensorflow\tensorflow\core\common_runtime\placer.cc:886] Placeholder: (Placeholder)/job:localhost/replica:0/task:0/device:GPU:0
相乘:12
而后者设置固定大小资源的per_process_gpu_memory_fraction,也只是均匀抢占每块GPU这么多资源而已,仍旧占用了所有GPU,如下:

正确的做法是利用CUDA来隐藏某些GPU,方法如下:
(1)直接在代码中利用python语句实现
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
(2)直接在终端写入
windows下(test.py改成自己的py文件):
- set CUDA_VISIBLE_DEVICES=1
- python tset.py
linux下:
CUDA_VISIBLE_DEVICES=1 python test.py但是如果程序中出现with tf.device():等语句,可能会因为不小心的索引而发生错误,为什么这么说呢?
CUDA_VISIBLE_DEVICES=1 Only device 1 will be seen
CUDA_VISIBLE_DEVICES=0,1 Devices 0 and 1 will be visible
CUDA_VISIBLE_DEVICES="0,1" Same as above, quotation marks are optional
CUDA_VISIBLE_DEVICES=0,2,3 Devices 0, 2, 3 will be visible; device 1 is masked
CUDA_VISIBLE_DEVICES="" No GPU will be visible
举个例子,当运行如下代码时,程序会提示错误:
import tensorflow as tf
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "1" with tf.device("/gpu:1"):
g = tf.placeholder(tf.int16)
h = tf.placeholder(tf.int16)
mul = tf.multiply(g,h)
gpu_options = tf.GPUOptions(allow_growth = True)
config = tf.ConfigProto(log_device_placement = True,gpu_options = gpu_options)
#config = tf.ConfigProto(log_device_placement = True,allow_soft_placement = True)
with tf.Session(config=config) as sess:
print("相乘:%d" % sess.run(mul, feed_dict = {g:3,h:4}))
因为当设置os.environ["CUDA_VISIBLE_DEVICES"] = "1"时,如果你又使用了with tf.device("/gpu:1"):(注:with tf.device("/gpu:0"):是正确的),则程序会提示你没有可用的GPU1,只有可用的CPU0和GPU0,如下(原因是因为设置了CUDA_VISIBLE_DEVICES后,CUDA本身会重新按你设置的顺序从0开始排列可见的GPU,这里只设置了一块GPU,所以只能索引到第0号GPU,超出索引会报错,虽然物理PCI总线上调用的还是GPU1这块显卡,但程序本身认为该块显卡的索引号是0而不是1):
InvalidArgumentError: Cannot assign a device for operation 'Mul': Operation was explicitly assigned to /device:GPU:1 but available devices are [ /job:localhost/replica:0/task:0/device:CPU:0, /job:localhost/replica:0/task:0/device:GPU:0 ]. Make sure the device specification refers to a valid device.
[[Node: Mul = Mul[T=DT_INT16, _device="/device:GPU:1"](Placeholder, Placeholder_1)]] Caused by op 'Mul', defined at:
File "E:\Anaconda3\lib\site-packages\spyder\utils\ipython\start_kernel.py", line 269, in <module>
main()
File "E:\Anaconda3\lib\site-packages\spyder\utils\ipython\start_kernel.py", line 265, in main
kernel.start()
File "E:\Anaconda3\lib\site-packages\ipykernel\kernelapp.py", line 486, in start
self.io_loop.start()
File "E:\Anaconda3\lib\site-packages\tornado\platform\asyncio.py", line 127, in start
self.asyncio_loop.run_forever()
File "E:\Anaconda3\lib\asyncio\base_events.py", line 422, in run_forever
self._run_once()
File "E:\Anaconda3\lib\asyncio\base_events.py", line 1432, in _run_once
handle._run()
File "E:\Anaconda3\lib\asyncio\events.py", line 145, in _run
self._callback(*self._args)
File "E:\Anaconda3\lib\site-packages\tornado\platform\asyncio.py", line 117, in _handle_events
handler_func(fileobj, events)
File "E:\Anaconda3\lib\site-packages\tornado\stack_context.py", line 276, in null_wrapper
return fn(*args, **kwargs)
File "E:\Anaconda3\lib\site-packages\zmq\eventloop\zmqstream.py", line 450, in _handle_events
self._handle_recv()
File "E:\Anaconda3\lib\site-packages\zmq\eventloop\zmqstream.py", line 480, in _handle_recv
self._run_callback(callback, msg)
File "E:\Anaconda3\lib\site-packages\zmq\eventloop\zmqstream.py", line 432, in _run_callback
callback(*args, **kwargs)
File "E:\Anaconda3\lib\site-packages\tornado\stack_context.py", line 276, in null_wrapper
return fn(*args, **kwargs)
File "E:\Anaconda3\lib\site-packages\ipykernel\kernelbase.py", line 283, in dispatcher
return self.dispatch_shell(stream, msg)
File "E:\Anaconda3\lib\site-packages\ipykernel\kernelbase.py", line 233, in dispatch_shell
handler(stream, idents, msg)
File "E:\Anaconda3\lib\site-packages\ipykernel\kernelbase.py", line 399, in execute_request
user_expressions, allow_stdin)
File "E:\Anaconda3\lib\site-packages\ipykernel\ipkernel.py", line 208, in do_execute
res = shell.run_cell(code, store_history=store_history, silent=silent)
File "E:\Anaconda3\lib\site-packages\ipykernel\zmqshell.py", line 537, in run_cell
return super(ZMQInteractiveShell, self).run_cell(*args, **kwargs)
File "E:\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2662, in run_cell
raw_cell, store_history, silent, shell_futures)
File "E:\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2785, in _run_cell
interactivity=interactivity, compiler=compiler, result=result)
File "E:\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2909, in run_ast_nodes
if self.run_code(code, result):
File "E:\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2963, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-1-f92d6fb2b710>", line 1, in <module>
runfile('C:/Users/B622/.spyder-py3/temp.py', wdir='C:/Users/B622/.spyder-py3')
File "E:\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py", line 705, in runfile
execfile(filename, namespace)
File "E:\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py", line 102, in execfile
exec(compile(f.read(), filename, 'exec'), namespace)
File "C:/Users/B622/.spyder-py3/temp.py", line 22, in <module>
add2 = tf.multiply(g,h)
File "E:\Anaconda3\lib\site-packages\tensorflow\python\ops\math_ops.py", line 337, in multiply
return gen_math_ops.mul(x, y, name)
File "E:\Anaconda3\lib\site-packages\tensorflow\python\ops\gen_math_ops.py", line 5066, in mul
"Mul", x=x, y=y, name=name)
File "E:\Anaconda3\lib\site-packages\tensorflow\python\framework\op_def_library.py", line 787, in _apply_op_helper
op_def=op_def)
File "E:\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py", line 3392, in create_op
op_def=op_def)
File "E:\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py", line 1718, in __init__
self._traceback = self._graph._extract_stack() # pylint: disable=protected-access InvalidArgumentError (see above for traceback): Cannot assign a device for operation 'Mul': Operation was explicitly assigned to /device:GPU:1 but available devices are [ /job:localhost/replica:0/task:0/device:CPU:0, /job:localhost/replica:0/task:0/device:GPU:0 ]. Make sure the device specification refers to a valid device.
[[Node: Mul = Mul[T=DT_INT16, _device="/device:GPU:1"](Placeholder, Placeholder_1)]]
同理,如果你设置了os.environ["CUDA_VISIBLE_DEVICES"] = "3,0,1"(假设你有4块GPU),则这时物理上的GPU3在程序看来是GPU0,物理上的GPU0在程序看来是GPU1,物理上的GPU1在程序看来是GPU2,物理上的GPU2不可见(被隐藏掉了)。
当然为了防止不小心的索引,可以在tf.ConfigProto中设置allow_soft_placement = True(表示指定的设备不存在时,允许tf自动分配设备),但这其实和我们所要将某些代码指配给某块GPU相违背,所以在写tf.device时要想清楚现在的GPU索引号。
除上述之外,在windows下还有很坑的一点是,当你的机子上有两块GPU设置了交火后,即使用了SLI桥后,无论你怎么设置os.environ["CUDA_VISIBLE_DEVICES"] = "1"或在终端写入对应指定某块GPU的指令,TensorFlow还是会占用所有GPU,虽然真的只有设定的GPU可见。
是不是感觉隐藏的GPU不可用,但还是被占了显存,有点赔了夫人又折兵啊。就是这么荒唐,这个问题,排查了我一宿加一早上,百度又百度都找不到任何答案。尝试过拆除SLI桥(如下图):

但拆除后,发现windows检测不到任何一块显卡,如下图(两块显卡都处于感叹号状态,这时你在终端使用nvidia-smi会报错,表示不存在任何GPU):

装上后又显示正常了,真是很醉的操作,于是折腾了很久很久都没有解决,一开始以为是驱动坏了,重装了无数遍驱动,还是感叹号,哇得一声哭了出来(注:ubuntu下不会出现这样的问题)。
最终,是禁用了SLI才解决的,即直接在NAVIDIA设置(NAVIDIA控制面板)中禁用掉就行了,如下图:


禁用的时候会显示需要关闭一些程序,直接在任务管理器里结束即可。
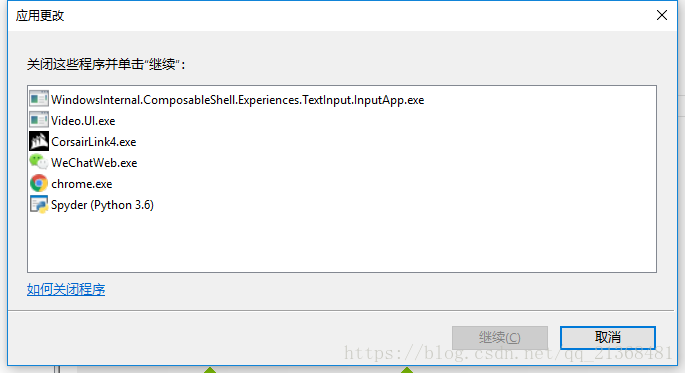
注意:在结束上图中的第一个进程(WindowsInternal...)时,该进程会在一两秒内自动重启用,所以速度要快,多尝试几次就行。
禁用SLI后,就不会出现两块GPU同时被tf占用了,真正实现指定哪块就占用哪块。
---------------------------------------------------------------------------------
转载者注:
本篇文章虽然写的还是蛮有借鉴意义的,但是我还是有一些观点, 首先Windows下面安装两个独立显卡后系统对这两个显卡显示都是未能正确识别还是有可能是驱动版本问题或者是驱动的管理界面中的具体设置问题,还不能直接就说Windows不支持没有SLI桥接的双独立显卡。
我想之所以能出现文中的多卡不识别问题还是有可能在设置上的不正确,毕竟Windows系统无法智能识别出应该用哪块显卡作为显示输出(个人感觉这个是要看屏幕的输出接口具体接在那个显卡上,文中现象可能是屏幕的显示输入接在了集成显卡上,当然只是猜想)
个人观点,如果Windows环境下如果驱动版本及设置正确,屏幕的输入接口插队,应该可以正确识别多个独立N显卡的。
当然还有一点主要就是不建议在Windows环境下做多显卡的科学计算,因为毕竟Windows不是很适合做科学计算的,做多显卡的科学计算还是在Linux上要好些。
【转载】 SLI导致双显卡被TensorFlow同时占用问题(Windows下) ---------- (windows环境下如何为tensorflow安装多个独立的消费级显卡)的更多相关文章
- python在windows(双版本)及linux(源码编译)环境下安装
python下载 下载地址:https://www.python.org/downloads/ 可以下载需要的版本,这里选择2.7.12和3.6.2 下面第一个是linux版本,第二个是windows ...
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案. 请注意, ...
- TensorFlow Python3.7环境下的源码编译(三)编译
这里要为仅支持 CPU 的 TensorFlow 构建一个 pip 软件包,需要调用以下命令: $ bazel build --cxxopt="-D_GLIBCXX_USE_CXX11_AB ...
- 【转载】 CUDA_DEVICE_ORDER 环境变量说明 ( ---------- tensorflow环境下的应用 )
原文地址: https://www.jianshu.com/p/d10bfee104cc ------------------------------------------------------- ...
- 常用增强学习实验环境 II (ViZDoom, Roboschool, TensorFlow Agents, ELF, Coach等) (转载)
原文链接:http://blog.csdn.net/jinzhuojun/article/details/78508203 前段时间Nature上发表的升级版Alpha Go - AlphaGo Ze ...
- Win10 Anaconda下TensorFlow-GPU环境搭建详细教程(包含CUDA+cuDNN安装过程)(转载)
win7(win10也适用)系统安装GPU/CPU版tensorflow Win10 Anaconda下TensorFlow-GPU环境搭建详细教程(包含CUDA+cuDNN安装过程) 目录 2.配置 ...
- 【转】windows环境下安装win8.1+Mac OS X 10.10双系统教程
先要感谢远景论坛里的各位大神们的帖子 没有他们的分享我也不能顺利的装上Mac OS X 10.10! 写这篇随笔主要是为了防止自己遗忘,同时给大家分享下我的经验. 本教程适用于BIOS+MBR分区的 ...
- RedHat 6.7 Enterprise x64环境下使用RHCS部署Oracle 11g R2双机双实例HA
环境 软硬件环境 硬件环境: 浪潮英信服务器NF570M3两台,华为OceanStor 18500存储一台,以太网交换机两台,光纤交换机两台. 软件环境: 操作系统:Redhat Enterpris ...
- tensorflow安装过程-(windows环境下)---详解(摆平了很多坑!)
一, 前言:本次安装tensorflow是基于Python的,安装Python的过程不做说明(既然决定按,Python肯定要先了解啊):本次教程是windows下Anaconda安装Tensorflo ...
- Ubuntu环境下Anaconda安装TensorFlow并配置Jupyter远程访问
本文主要讲解在Ubuntu系统中,如何在Anaconda下安装TensorFlow以及配置Jupyter Notebook远程访问的过程. 在官方文档中提到,TensorFlow的安装主要有以下五种形 ...
随机推荐
- kettle从入门到精通 第二十四课 kettle 部署生产常用命令
一.设置KETTLE_HOME环境变量 假设kettle软件目录为/xxx/data-integration vi ~/.bash_profile export KETTLE_HOME=/xxx/da ...
- java 中 pop 和 peek 方法区别
相同点:都返回栈顶的值. 不同点:peek 不改变栈的值(不删除栈顶的值),pop会把栈顶的值删除. 下面通过代码展现 /* * 文 件 名: TestPeekAndPopDiff.java */ i ...
- vue动态页签
效果图 前端 1 <template> 2 <!-- 总体情况 - 总览echarts --> 3 4 <div v-loading="loading" ...
- Jetpack Compose(7)——触摸反馈
目录 一.点按手势 1.1 Modifier.clickable 1.2 Modifier.combinedClickable 二.滚动手势 2.1 滚动修饰符 Modifier.verticalSc ...
- C#/.NET这些实用的技巧和知识点你都知道吗?
前言 今天大姚给大家分享一些C#/.NET中的实用的技巧和知识点,它们可以帮助我们提升代码质量和编程效率,希望可以帮助到有需要的同学. .NET使用CsvHelper快速读取和写入CSV文件 本文主要 ...
- selenium无头浏览器
from selenium.webdriver import Edge # 在这里导入浏览器设置相关的类 from selenium.webdriver.edge.options import Opt ...
- 专用M4F+四核A53,异构多核AM62x让工业控制“更实时、更安全” Tronlong创龙科技5 秒前 1 德州仪器 TI芯片
Cortex-M4F + Cortex-A53异构多核给工业控制带来何种意义? 创龙科技SOM-TL62x工业核心板搭载TI AM62x最新处理器,因其Cortex-M4F + Cortex-A53异 ...
- 浏览器中JS的执行
JS是在浏览器中运行的,浏览器为了运行JS, 必须要编译或解释JS,因为JS是高级语言,计算机不认识,必须把它编译或解释成机器语言,其次,在运行JS的过程,浏览器还要创建堆栈,因为程序是在栈中执行,执 ...
- 外部网关协议BGP
不能全部使用RIP与OSPF的原因有二:互联网规模太大,自治系统间路由选择困难:自治系统间路由选择必须考虑有关策略. 在每一个自治系统中有两种不同功能的路由器,边界路由器和内部路由器. BGP四种报文 ...
- WebGL实践之半透阴影
楔子 相信很多人都知道,通过ShadowMap可以产生阴影,通过渲染阴影可以增加场景渲染的对比度,增加渲染的真实效果. 如下图所示: 但是对于透明或者半透明的对象,WebGL在处理阴影效果的时候,会把 ...