解密Prompt系列33. LLM之图表理解任务-多模态篇
上一章我们介绍了纯文本模态的表格理解任务,这一章我们聚焦多模态图表数据。先讨论下单纯使用prompt的情况下,图片和文字模态哪种表格模型理解的效果更好更好,再说下和表格相关的图表理解任务的微调方案。
Prompt:表格模态哪家强
使用prompt对比SOTA的文本模型和多模态模型,哪个在表格理解任务上效果更好,可以借鉴以下两篇论文,前者使用了已有的TableQA Benchmark,后者新构建的TableVQA Benchmark。
Table as Text or Image
- TableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains
这是一篇实验性论文,有如下几个实验变量
- 不同的开源(llama2)闭源(GPT3.5,GPT4,Gmini)模型
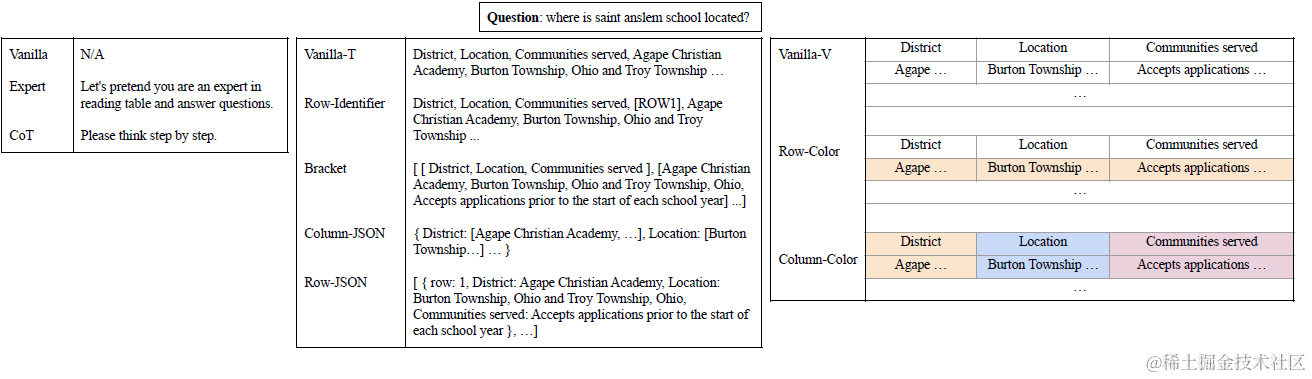
- 不同格式的文本表格数据:纯文字逗号分割(vanilla)类,行号标注类,括号数组类,行json,列json等5种
- 不同格式的图片表格数据:纯表格图片(Vanilla),每列一种颜色,每行一种颜色等3种
- 不同的prompt方案:vanilla,COT,和专家prompt(假设你是一个XX专家)
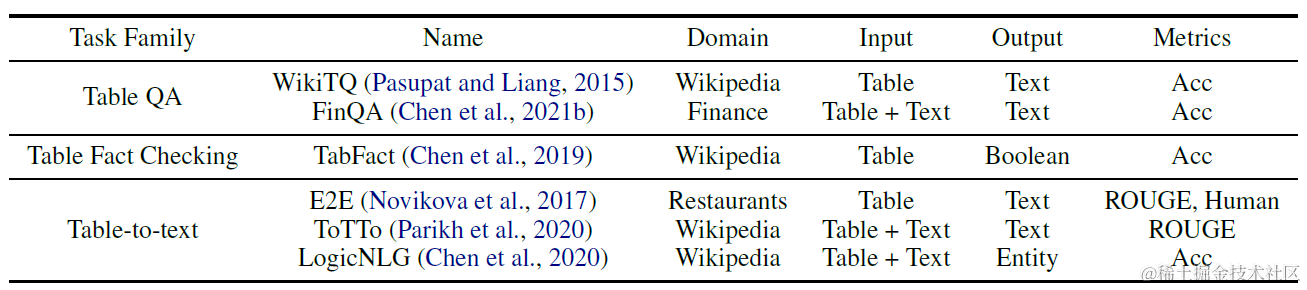
论文使用了以下6个数据集的混合,分别对TableQA,Table Fact-check,Table-to-text等任务进行评估。
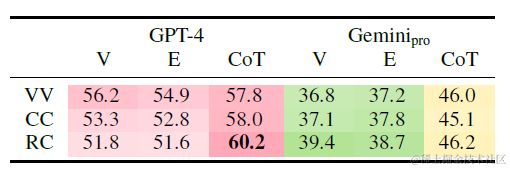
直接来看实验结论吧
- 图片和文字的效果在不同数据集上存在差异,Gmini和GPT4,当使用Vanilla的表格文本和表格图片时,在FinQA上图片显著更好,而在TabFact和WikiTQ上文本显著更好。论文猜测的点是FinQA的上文更长,导致文本表征模型容易混淆信息,而WikiTQ和TabFact是维基百科的数据,文本模型可能在预训练时见过才导致的效果更好。对比并不太充分,这么看感觉图片和文字的效果还是要在实际使用的场景上去做测试。

- 不论是图片和文字模态,COT都能带来显著的效果提升,文字prompt上一章微软的另一篇论文中已经说过了,这里只看图片的实验结果,下图列(V,E,COT)分别是vanilla,ExPert和COT,行(VV,CC,RC)分别是图片无颜色,列高亮,和行高亮
更多文本模态的结论和前一章微软的论文有所重合这里了就不多说了,图片和文本的对比感觉不太充分,我们再看下下面的另一篇论文
TableVQA-Bench
- TableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains
- https://github.com/naver-ai/tablevqabench?tab=readme-ov-file
第二篇论文我们说下新出炉不久的TableVQA评估集,论文提出了新的多模态表格评估数据集。和以上论文的数据集存在重合,不过更细致地给出了数据集构建的细节,以及论文的结论也和前文存在差异。
评估集由以下三个数据集构成(点击链接可以看到数据)
- VWTQ:从维基百科表格问答的数据集WTQ,通过wiki网页链接获取原始表格的HTML截图得到图片,并通过Table Renderer对表格属性进行修改,降低维基百科在预训练中的数据泄露问题再通过截图获取图片数据(VWTQ-Syn)
- VTabFact: 表格事实检查的另类QA问题,这里未提供原始html,因此使用csv数据转换成伪html,再使用Table Renderer进行属性修改和截图
- FinTabNetQA: 本身是TSR任务,因此论文使用GPT4和HTML作为输入构建了QA对
上面提到的Table Renderer其实就是随机修改表格的HTML样式,例如加入cell color,调整文字对齐,修改边界样式,给表格加背景色等等。
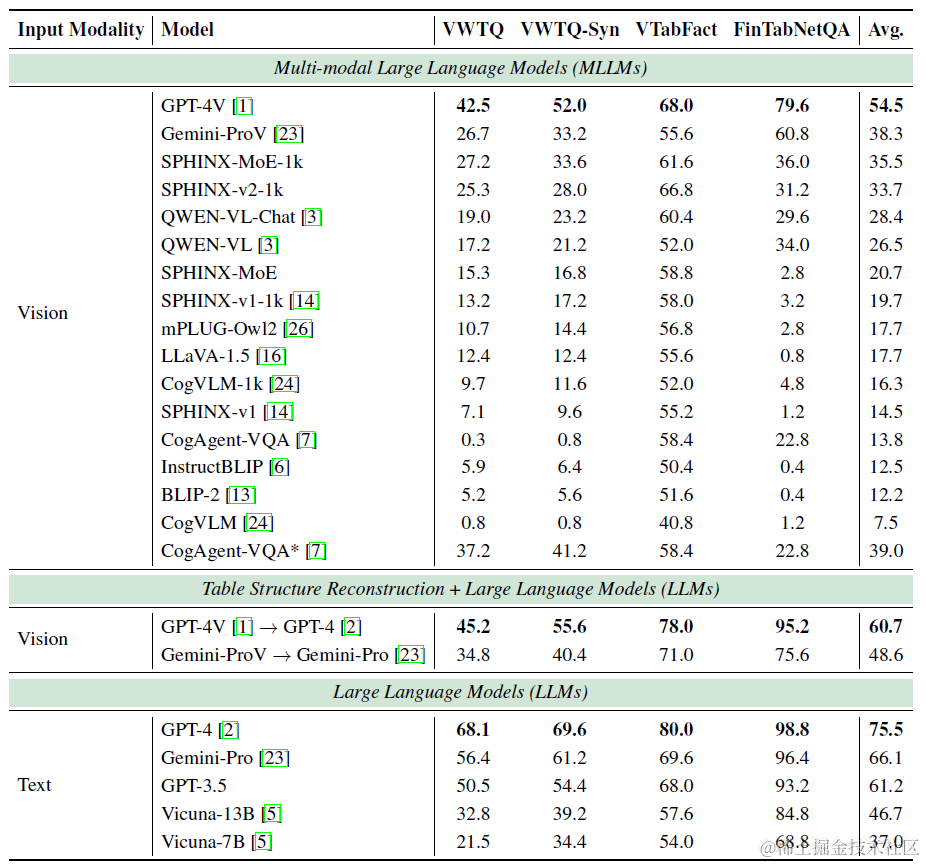
基于以上评估集,论文对众多开源和商用MLLM进行了整体评估,结果如下
- 在3个数据集上:文本模态>图转文>图片模态:这里的TabFact和WTQ数据集和上面一篇的论文重合,上面论文这两个数据集也是文本>图片,但并未测试前面论文中图片模态表现更好的FinQA数据集。
- 当图片模态效果不好时不妨试试先进行TSR模态转换: 论文还测试了用GPT-4V把图片模态转换成文本模态再用GPT-4进行回答的折中模式,效果比图片模态有提升
我们结合两篇论文来看,在当前的prompt水平上,整体上还是文本模态的表格要更好些,但确实可能存在不同上下文和表格类型上表现不同的差异性~
说完纯prompt的方案,我们再来看下图表理解相关的微调方案,这里的微调方案更多是针对图表数据中的图,例如饼图,时序图,直方图等等分别介绍ChartLlama和TinyChart两篇论文,还有一些相关的论文像ChartInstruct,ChartX,ChartAssistant会列在最后感兴趣的大家自己去看吧~
Chart SFT
ChartLlama
- https://tingxueronghua.github.io/ChartLlama/
- ChartLlama: A Multimodal LLM for Chart Understanding and Generation
ChartLlam的核心其实是给了一套构建多模态图表指令理解数据集的方案。然后基于构建的数据集在Llava-1.5上进行了微调训练。Llava-1.5是由VIT-L/14@336px作为图像编码器,两层MLP作为投影层,Llama作为LLM。这里ChartLlama只对Projection层和Llama层进行了微调。
既然以构建大规模,多样性的图表理解数据为主,那我们就重点说下数据构建的细节。分成以下三个步骤

- step1: Chart Data生成
这里包含从头让GPT4直接构建和从已有数据中合成。以下prompt用于GPT直接生成数据,论文通过随机采样主题(预先生成了100+主题短语),数据趋势,表格的行数和列数,以及图片类型。这部分除了生成数据,还会生成数据的描述在最后的推理部分帮助模型理解数据。第一部分的核心其实是如何避免模型生成毫无意义的低质量数据

- Step2: 基于ChartData绘制图片
基于以上获得的数据,论文使用GPT4的代码能力,生成matplotlib的绘图代码从而生成图片。为了代码生成的准确率,论文会随机采样可以成功执行的代码作为In-Context上文,并加入相关函数的documentation作为上文。这里除了生成代码同时还会生成图片描述,在最后的推理部分帮助模型理解图片。但整体上感觉只使用matplotlib比较容易导致这一步构建的图片本身的样式相对单一。

- step3:QA对样本生成
获得图片后,就可以进行QA对的样本生成了。这里模型的输入会包括原始数据,前两部分生成的数据和图片的描述,以及问题类型。这里论文涵盖了TableQA,Summarization,数据抽取,图标描述,代码生成和图片编辑等丰富的问题类型。最终构建了总共160K的指令样本

微调和效果部分就不细说了在后面的TinyChart里面会有ChartLlama的效果数据。
TinyChart
- TinyChart: Efficient Chart Understanding with Visual Token Merging and Program-of-Thoughts Learning
除了ChartLlama后面还有过很多篇论文但多数也是构建不同的数据,在不同的模型上去训练,这里我们再看一篇针对效率提升的论文。
TinyChart使用了更高效的像素合并和Program-of-Thoguhts让3B的MLLM一举超越了13B的ChartLLama。TinyChart的整体模型结构也是传统的MMLM,由Vision Transformer Encoder,Connector和LLM构成,下面我们主要说下提升效率的图像元素合并,以及提升效果的PoT
Visual Token Merging
图片编码器的输入会先把图片压缩到固定像素(N),然后裁剪成多个大小为(P)的区域作为视觉模型的token输入。因此视觉模型的token数=(N//p)^2。考虑到Chart图表理解往往需要用到图片中的文字等信息,因此必须使用高像素的图片。而像素N的提升会带来输入token平方级的增长。这里论文提出可以通过相似token合并来降低每一层的token量级。
这里其实用到了chart图表本身的图片特征,例如饼图和直方图等图片会在局部存在大量的同色色块,以及空白,因此在裁剪的区域上可以再做一层相似合并。
这里合并使用了token的self-attention的cosine similar来作为相似度度量,然后使用了二分图匹配算法,有点好奇为啥是用这个方案而不直接用矩阵。就是把所有token分两堆,然后男嘉宾(左边一堆)去找最喜欢(相似)的女嘉宾(右边一堆),保留最有眼缘(最相似)的r对嘉宾(token)进行合并。这里token合并并不一定是相邻token。
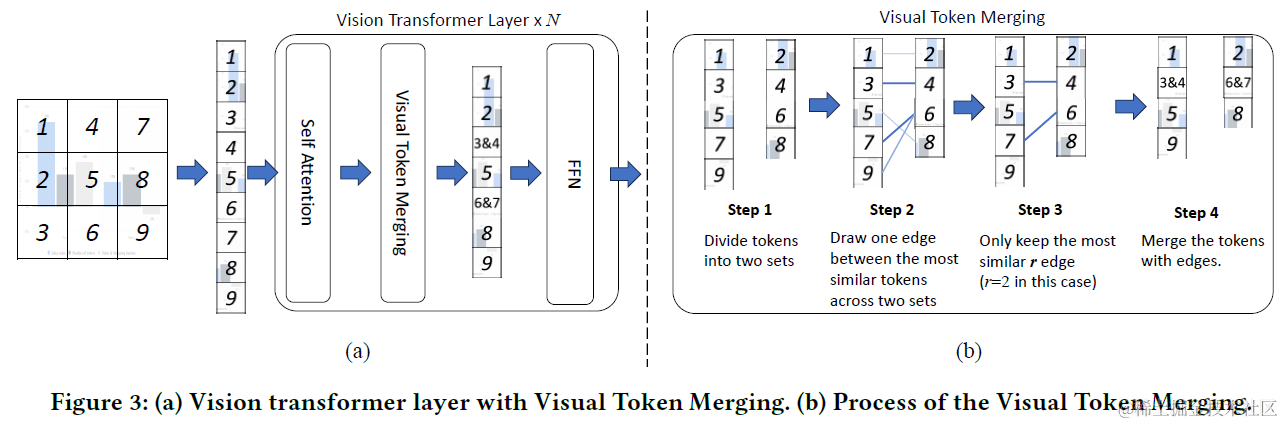
同时考虑到合并后参与attention计算的元素会减少,因此论文加入了被合并的元素数来调整scale。
\]
直观来看下Token Merge的效果,这里论文展示了Transformer最后一层中最大的十组Merged Token,基本上都是白色背景,或者纯色的色块。

Program-of-Thought
为了提升模型在解决图表问题中数学计算等逻辑推理问题的效果,论文在训练时加入了让模型推理生成多步python代码的Program-of-Thought样本。而在推理时论文,会通过简单的关键词判断,如果涉及计算类问题,就选择让模型进行代码推理的prompt,否则使用文字推理的prompt。
这里论文分别通过模板和GPT进行了Chart-POT数据集的构建,总共构建了140,584条样本(question,POT Answer),每个answer包含完整带comment的python代码。包含chartQA,chart-to-text,chart-to-table,chart指令理解等几种任务,其中
- Template-Base
这里论文从PlotQA中选了40个问题,然后手工编写了对应的Python代码模版,之后从每个data-table中随机采样字段和数值填入模版。总共构建了119,281个样本对 - GPT-Base
尽管以上模版的样本对量级很大,但多样性非常有限,因此论文还使用以上template生成的q+code样本对作为In-Context上文,让GPT3.5基于文本化的表格数据进行回答构建。因为生成的python numpy代码,因此可以直接intrepreter运行检测输出是否正确。总共构建了21303个样本。
样本demo如下
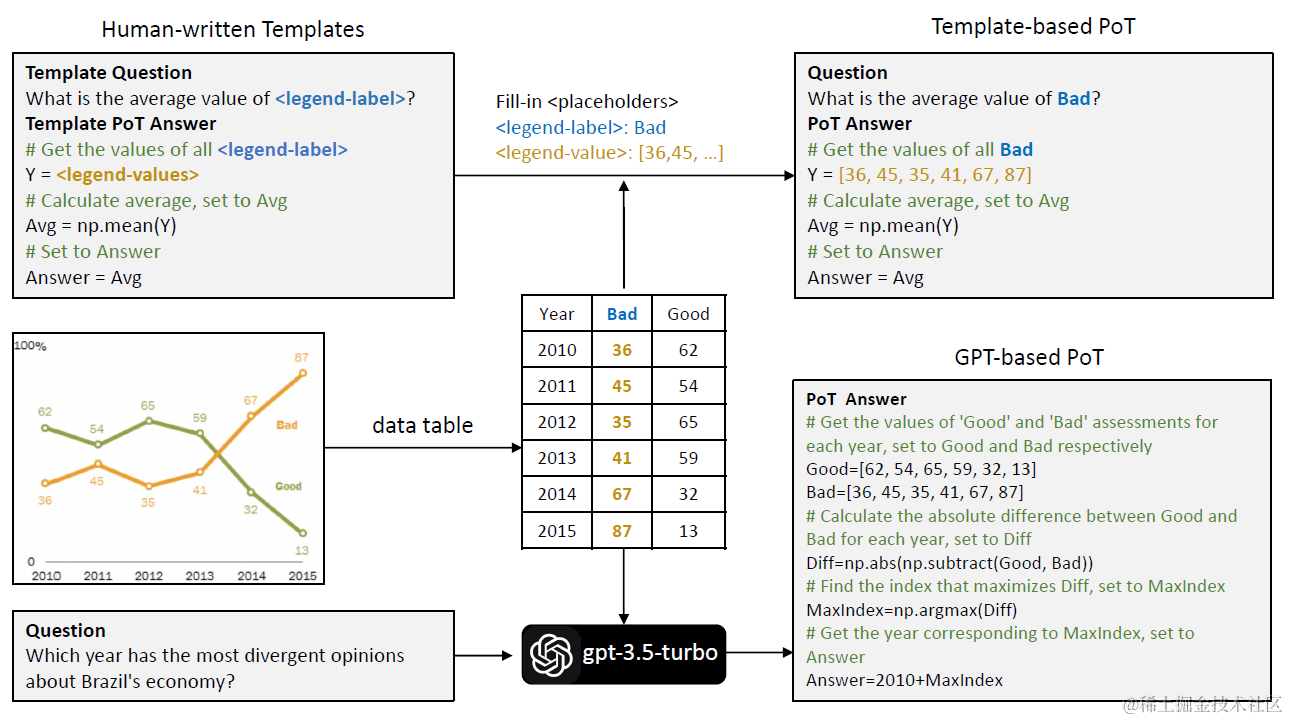
之后基于以上的样本,TinyChart是基于TinyLlava,包含SIGCLIP作为图像Encoder,Phi-2作为作为LLM,然后分别在512*512,以及768*768的像素上进行全模型的微调。
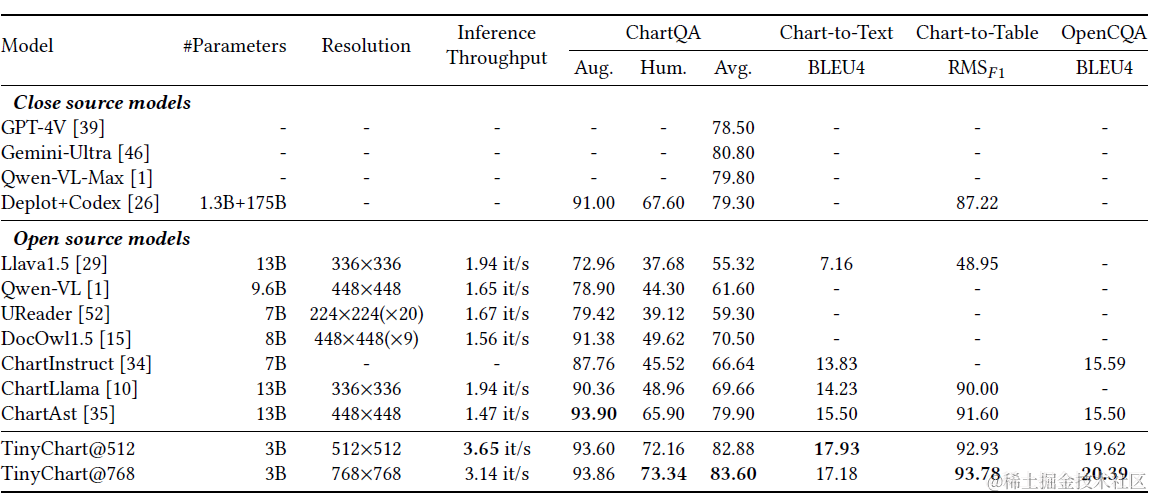
效果如下,因为表格理解类任务的样本丰富度相对有限,所以在同领域的效果提升会比较明显,所以这个结果嘛看看就好~
论文还做了消融实验,对比了POT的加入,确实能有效提升模型在计算类问题上的效果,以及更高的分辨率配合TokenMerge可以推理效率持平的情况下提升模型效果。
其他相关论文
- ChartAssisstant: A Universal Chart Multimodal Language Model via Chart-to-Table Pre-training and Multitask Instruction Tuning
- ChartInstruct: Instruction Tuning for Chart Comprehension and Reasoning
- ChartX & ChartVLM: A Versatile Benchmark and Foundation Model for Complicated Chart Reasoning
- MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt
解密Prompt系列33. LLM之图表理解任务-多模态篇的更多相关文章
- 解密Prompt系列6. lora指令微调扣细节-请冷静,1个小时真不够~
上一章介绍了如何基于APE+SELF自动化构建指令微调样本.这一章咱就把微调跑起来,主要介绍以Lora为首的低参数微调原理,环境配置,微调代码,以及大模型训练中显存和耗时优化的相关技术细节 标题这样写 ...
- 解密prompt系列5. APE+SELF=自动化指令集构建代码实现
上一章我们介绍了不同的指令微调方案, 这一章我们介绍如何降低指令数据集的人工标注成本!这样每个人都可以构建自己的专属指令集, 哈哈当然我也在造数据集进行时~ 介绍两种方案SELF Instruct和A ...
- 解密Prompt系列3. 冻结LM微调Prompt: Prefix-Tuning & Prompt-Tuning & P-Tuning
这一章我们介绍在下游任务微调中固定LM参数,只微调Prompt的相关模型.这类模型的优势很直观就是微调的参数量小,能大幅降低LLM的微调参数量,是轻量级的微调替代品.和前两章微调LM和全部冻结的pro ...
- 解密Prompt系列4. 升级Instruction Tuning:Flan/T0/InstructGPT/TKInstruct
这一章我们聊聊指令微调,指令微调和前3章介绍的prompt有什么关系呢?哈哈只要你细品,你就会发现大家对prompt和instruction的定义存在些出入,部分认为instruction是promp ...
- 解密Prompt系列2. 冻结Prompt微调LM: T5 & PET & LM-BFF
这一章我们介绍固定prompt微调LM的相关模型,他们的特点都是针对不同的下游任务设计不同的prompt模板,在微调过程中固定模板对预训练模型进行微调.以下按时间顺序介绍,支持任意NLP任务的T5,针 ...
- 11.Java 加解密技术系列之 总结
Java 加解密技术系列之 总结 序 背景 分类 常用算法 原理 关于代码 结束语 序 上一篇文章中简单的介绍了第二种非对称加密算法 — — DH,这种算法也经常被叫做密钥交换协议,它主要是针对密钥的 ...
- 9.Java 加解密技术系列之 RSA
Java 加解密技术系列之 RSA 序 概念 工作流程 RSA 代码实现 加解密结果 结束语 序 距 离上一次写博客感觉已经很长时间了,先吐槽一下,这个月以来,公司一直在加班,又是发版.上线,又是新项 ...
- 6. Java 加解密技术系列之 3DES
Java 加解密技术系列之 3DES 序 背景 概念 原理 代码实现 结束语 序 上一篇文章讲的是对称加密算法 — — DES,这篇文章打算在 DES 的基础上,继续多讲一点,也就是 3 重 DES ...
- 4.Java 加解密技术系列之 HMAC
Java 加解密技术系列之 HMAC 序 背景 正文 代码 结束语 序 上一篇文章中简单的介绍了第二种单向加密算法 — —SHA,同时也给出了 SHA-1 的 Java 代码.有这方面需求的童鞋可以去 ...
- 3.Java 加解密技术系列之 SHA
Java 加解密技术系列之 SHA 序 背景 正文 SHA-1 与 MD5 的比较 代码实现 结束语 序 上一篇文章中介绍了基本的单向加密算法 — — MD5,也大致的说了说它实现的原理.这篇文章继续 ...
随机推荐
- 03. Ruby入门理解
Ruby入门学习: 视频教程 https://www.bilibili.com/video/BV1QW411F7rh?t=401&p=1 笔记 https://github.com/haima ...
- SQL如何删除所有字段都相同的重复数据?
SQL Server数据库:有时候在处理数据时会遇到不加主键的表,导致数据表内出现了一模一样的数据,刚开始第一时间想到的方式是,把两条数据全部删除,然后再插入一条,但是这种可能数据量比较少的话,还可以 ...
- 计算机网络基础 — Linux 虚拟路由器
目录 文章目录 目录 前文列表 前言 Neutron L3 agent 概述 L3 agent的配置 虚拟路由器实现原理 总结 前文列表 <计算机网络基础 - 以太网> <计算机网络 ...
- 5GC 关键技术之 SBA(基于服务的软件架构)
目录 文章目录 目录 前文列表 5GC 的关键技术 SBA(基于服务的软件架构) 微服务架构 NF 的模块化 NF Service 的服务化 前文列表 <简述移动通信网络的演进之路> &l ...
- 使用systemctl管理服务(nginx)
首先调整好路径信息,修改配置文件vim /usr/lib/systemd/system/nginx.service [Unit]Description=The nginx HTTP and rever ...
- Python 潮流周刊#52:Python 处理 Excel 的资源
本周刊由 Python猫 出品,精心筛选国内外的 250+ 信息源,为你挑选最值得分享的文章.教程.开源项目.软件工具.播客和视频.热门话题等内容.愿景:帮助所有读者精进 Python 技术,并增长职 ...
- wpf 自定义轮播图组件
轮播图组件代码: [Localizability(LocalizationCategory.None, Readability = Readability.Unreadable)][TemplateP ...
- C++笔记(3)引用
引用是变量的别名.也就是说,它是某个已存在变量的另一个名字.一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量. 1.创建引用 int i = 0; int& r = i;/ ...
- 第一次线上 OOM 事故,竟和 where 1 = 1 有关
这篇文章,聊聊一个大家经常使用的编程模式 :Mybatis +「where 1 = 1 」. 笔者人生第一次重大的线上事故 ,就是和使用了类似的编程模式 相关,所以印象极其深刻. 这几天在调试一段业务 ...
- mescroll.js 使用
mescroll.js 使用 附:点击查看中文文档 第一步:引入css和js // unpkg的CDN: <link rel="stylesheet" href=" ...