Python爬虫知识点四--scrapy框架
一。scrapy结构数据
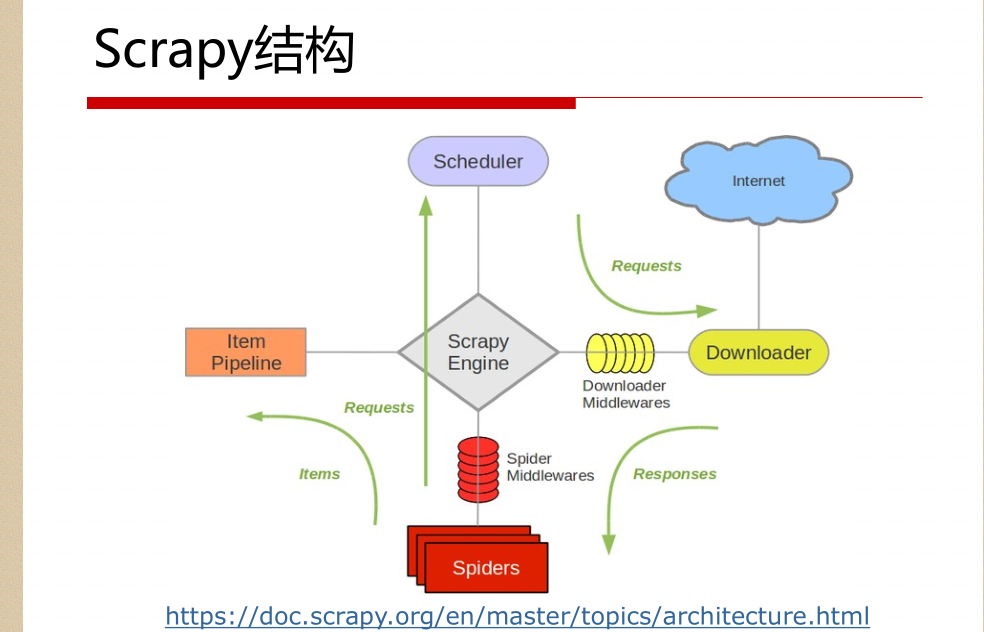
解释:
1.名词解析:
o 引擎(Scrapy Engine)
o 调度器(Scheduler)
o 下载器(Downloader)
o 蜘蛛(Spiders)
o 项目管道(Item Pipeline)
o 下载器中间件(Downloader Middlewares)
o 蜘蛛中间件(Spider Middlewares)
o 调度中间件(Scheduler Middlewares)
2.具体解析
绿线是数据流向
从初始URL开始,Scheduler会将其交给Downloader进
行下载
下载之后会交给Spider进行分析
Spider分析出来的结果有两种
一种是需要进一步抓取的链接,如 “下一页”的链接,它们
会被传回Scheduler;另一种是需要保存的数据,它们被送到Item Pipeline里,进行
后期处理(详细分析、过滤、存储等)。
在数据流动的通道里还可以安装各种中间件,进行必
要的处理。
二。初始化爬虫框架 Scrapy
命令: scrapy startproject qqnews
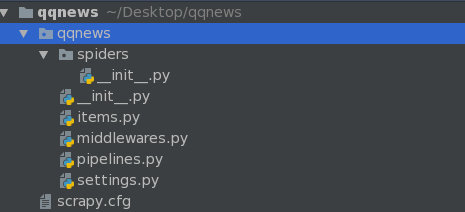
ps:真正的项目是在spiders里面写入的
三。scrapy组件spider
爬取流程
1. 先初始化请求URL列表,并指定下载后处
理response的回调函数。
2. 在parse回调中解析response并返回字典,Item
对象,Request对象或它们的迭代对象。
3 .在回调函数里面,使用选择器解析页面内容
,并生成解析后的结果Item。
4. 最后返回的这些Item通常会被持久化到数据库
中(使用Item Pipeline)或者使用Feed exports将
其保存到文件中。
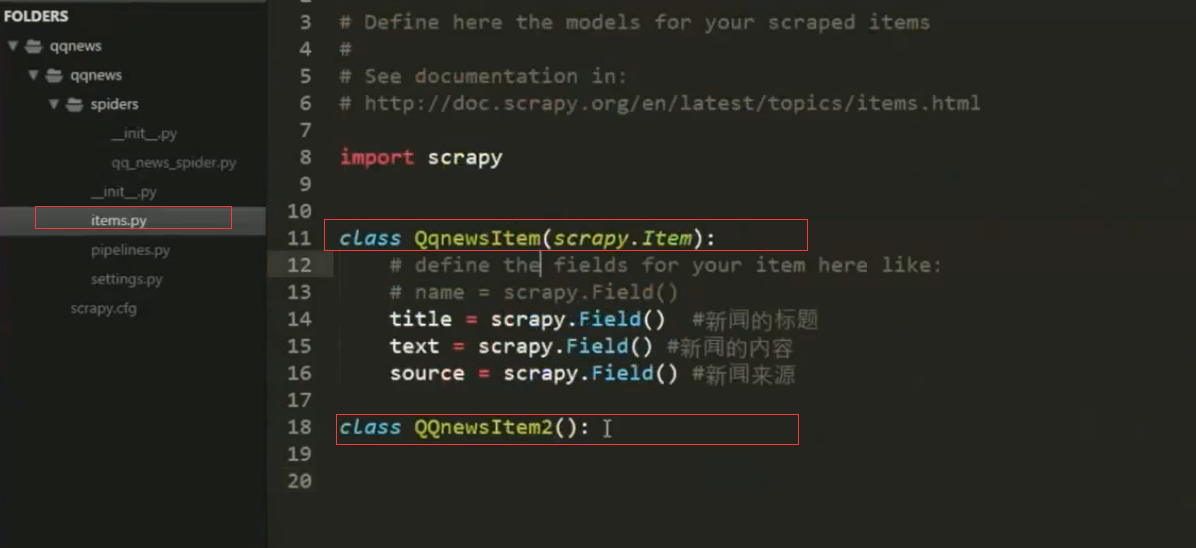
标准项目结构实例:
1.items结构:定义变量,根据不同种数据结构定义
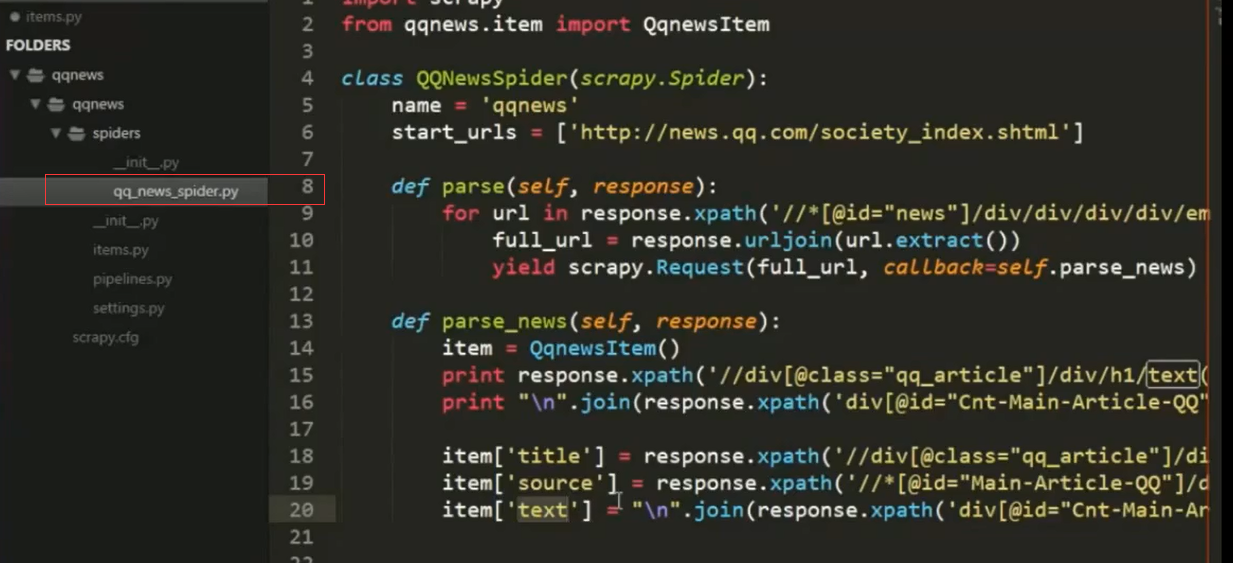
2.spider结构中引入item里面,并作填充item
3。pipline去清洗,验证,存入数据库,过滤等等 后续处理
Item Pipeline常用场景
清理HTML数据
验证被抓取的数据(检查item是否包含某些字段)
重复性检查(然后丢弃)
将抓取的数据存储到数据库中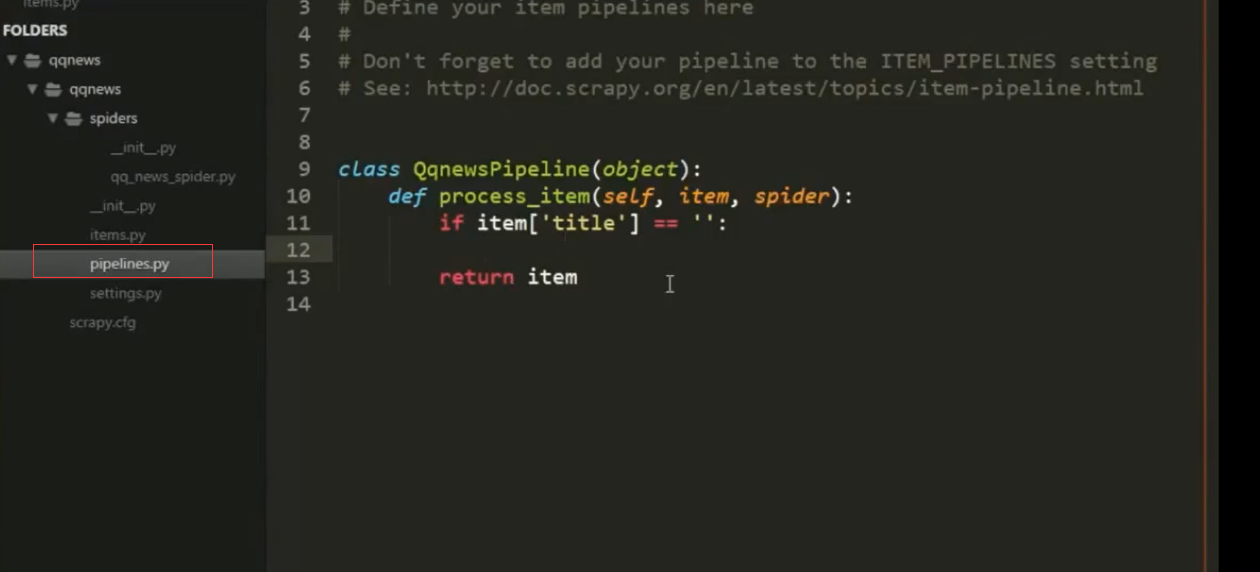
4.Scrapy组件Item Pipeline
经常会实现以下的方法:
open_spider(self, spider) 蜘蛛打开的时执行
close_spider(self, spider) 蜘蛛关闭时执行
from_crawler(cls, crawler) 可访问核心组件比如配置和
信号,并注册钩子函数到Scrapy中
pipeline真正处理逻辑
定义一个Python类,实现方法process_item(self, item,
spider)即可,返回一个字典或Item,或者抛出DropItem
异常丢弃这个Item。
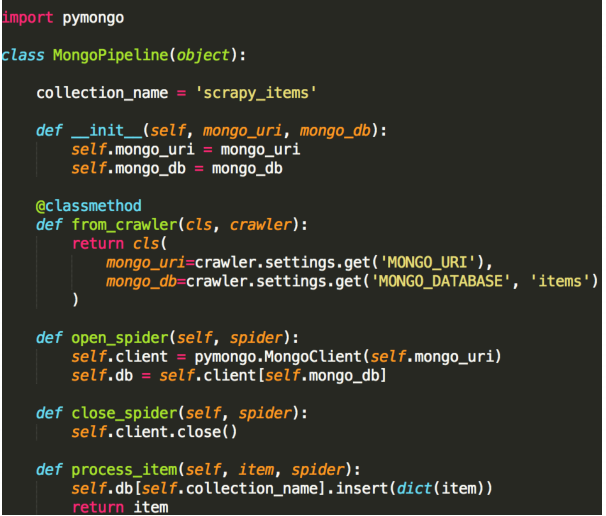
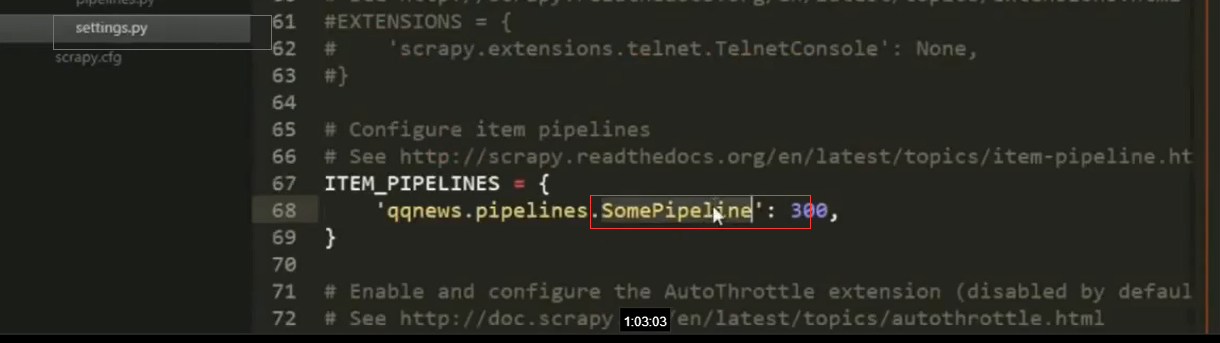
5.settings中定义哪种类型的pipeline
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

Python爬虫知识点四--scrapy框架的更多相关文章
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python 爬虫相关含Scrapy框架
1.从酷狗网站爬取 新歌首发的新歌名字.播放时长.链接等 from bs4 import BeautifulSoup as BS import requests import re import js ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 【Python爬虫实战】Scrapy框架的安装 搬运工亲测有效
windows下亲测有效 http://blog.csdn.net/liuweiyuxiang/article/details/68929999这个我们只是正确操作步骤详解的搬运工
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- JAVA常用API(Date、DateFormat、Calendar、System、Math、基本数据类型包装类)
注:本文所有内容均属个人见解,如有错误望各位大佬好心指点批评,不胜感激 本章重点单词: parse:解析 format:格式化 pattern:模式 amount:数量 filed :领域 1.Dat ...
- win10 UWP 隐式转换
implicit operator string <script type="text/javascript"> $(function () { $('pre.pret ...
- ASP.NET Web API 2中的错误处理
前几天在webapi项目中遇到一个问题:Controller构造函数中抛出异常时全局过滤器捕获不到,于是网搜一把写下这篇博客作为总结. HttpResponseException 通常在WebAPI的 ...
- Python 初学者 入门 应该学习 python 2 还是 python 3?
许多刚入门 Python 的朋友都在纠结的的问题是:我应该选择学习 python2 还是 python3? 对此,咪博士的回答是:果断 Python3 ! 可是,还有许多小白朋友仍然犹豫:那为什么还是 ...
- HTML5-前端开发很火且工资很高?
前言 晚上逛论坛看到一篇对从事HTML5前端开发的文章写的非常不错,和目前的市场形势差不多,然后我在其基础上给大家进行加工总结一下分享给大家.今天我们谈论的话题是<<为什么从事HTML5前 ...
- PLSQL Developer oracle导入导出表及数据
1.进入PLSQL Developer 2.创建新用户(如需要新表空间则需先创建新表空间再创建用户) 3.打开菜单Tools->Export User Objects 导出表及视图等创建SQL ...
- 总结HTML5
都说项目页面是HTML5写的,但是HTML5的特别之处用了多少? 1.是不是页面布局都是统一的div,然后class写样式?可是HTML5提供了好多新标签 ,css中直接用标签名即可定义样式,不用费力 ...
- java swing中Timer类的学习
最近在完成学校课程的java平时作业,要实现一个计时器,包含开始.暂停以及重置三个功能.由于老师规定要用这个timer类,也就去学习了一下,顺便记录一下. 首先呢去查了一下java手册上的东西,发现t ...
- 『实践』Yalmip建模+Cplex类求解
Yalmip建模+Cplex类求解 一.缘由 Yalmip只能设置部分Cplex的参数,所以需要调用Cplex类.而且optimize是Yalmip提供的常用函数,但此函数的返回结果参数有限. 图1 ...
- Leetcode题解(24)
73. Set Matrix Zeroes 分析:如果没有空间限制,这道题就很简单,但是要求空间复杂度为O(1),因此需要一些技巧.代码如下(copy网上的代码) class Solution { p ...