【Spark2.0源码学习】-2.一切从脚本说起
- %SPARK_HOME%/sbin/start-master.sh
- %SPARK_HOME%/sbin/start-slaves.sh
- %SPARK_HOME%/sbin/start-all.sh
- %SPARK_HOME%/bin/spark-submit
| spark-config.sh | 初始化环境变量 SPARK_CONF_DIR, PYTHONPATH |
| bin/load-spark-env.sh |
初始化环境变量SPARK_SCALA_VERSION,
调用%SPARK_HOME%/conf/spark-env.sh加载用户自定义环境变量
|
| conf/spark-env.sh | 用户自定义配置 |
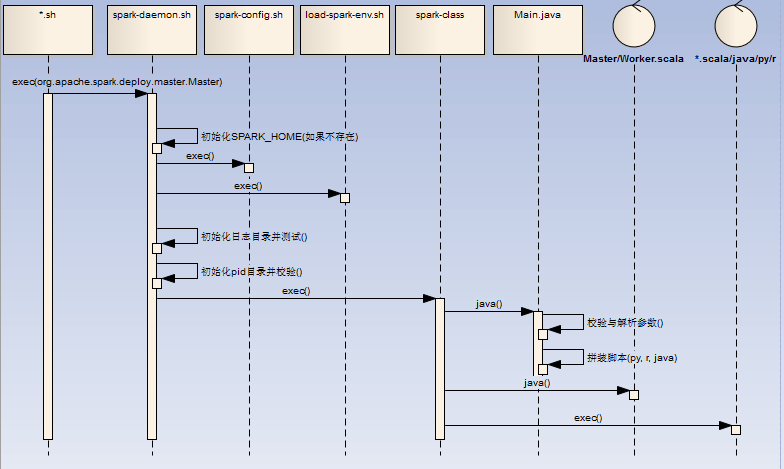
- 初始化 SPRK_HOME,SPARK_CONF_DIR,SPARK_IDENT_STRING,SPARK_LOG_DIR环境变量(如果不存在)
- 初始化日志并测试日志文件夹读写权限,初始化PID目录并校验PID信息
- 调用/bin/spark-class脚本,/bin/spark-class见下
- master调用举例:bin/spark-class --class org.apache.spark.deploy.master.Master --host $SPARK_MASTER_HOST --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT $ORIGINAL_ARGS
- 初始化 RUNNER(java),SPARK_JARS_DIR(%SPARK_HOME%/jars),LAUNCH_CLASSPATH信息
- 调用( "$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@")获取最终执行的shell语句
- 执行最终的shell语句(比如:/opt/jdk1.7.0_79/bin/java -cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/ -Xmx1g -XX:MaxPermSize=256m org.apache.spark.deploy.master.Master --host zqh --port 7077 --webui-port 8080),如果是Client,那么可能为r,或者python脚本
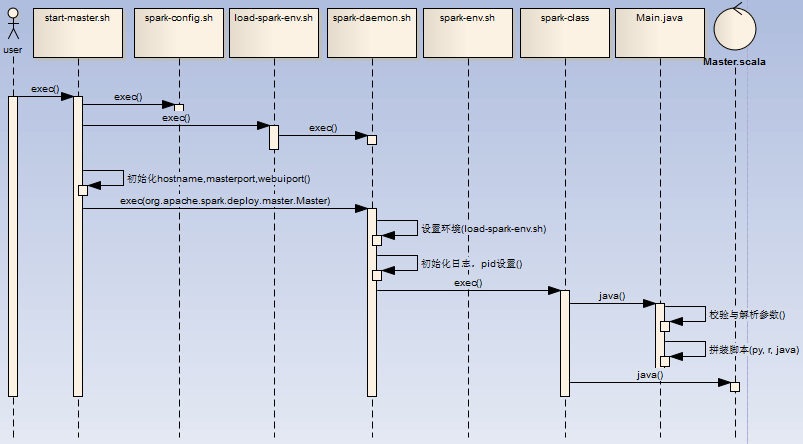
- 用户执行start-master.sh脚本,初始化环境变量SPARK_HOME (如果PATH不存在SPARK_HOME,初始化脚本的上级目录为SPARK_HOME),调用spark-config.sh,调用load-spark-env.sh
- 如果环境变量SPARK_MASTER_HOST, SPARK_MASTER_PORT,SPARK_MASTER_WEBUI_PORT不存在,进行初始化7077,hostname -f,8080
- 调用spark-daemon.sh脚本启动master进程(spark-daemon.sh start org.apache.spark.deploy.master.Master 1 --host $SPARK_MASTER_HOST --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT $ORIGINAL_ARGS)
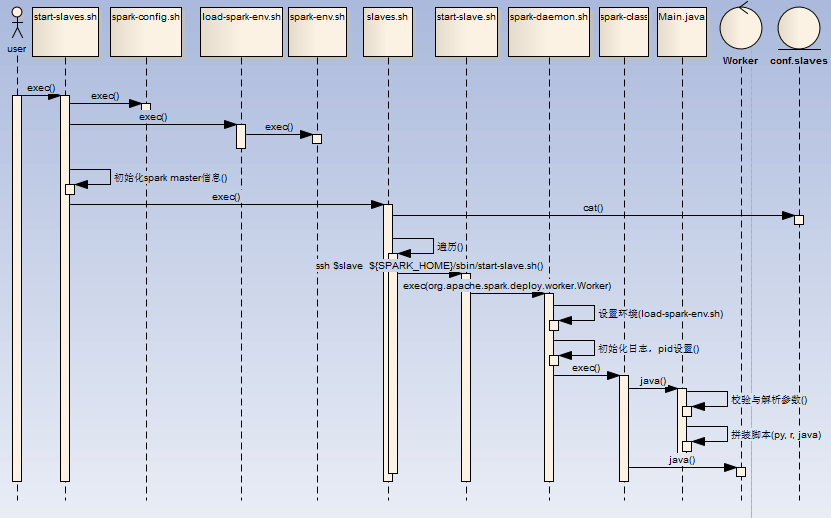
- 用户执行start-slaves.sh脚本,初始化环境变量SPARK_HOME,调用spark-config.sh,调用load-spark-env.sh,初始化Master host/port信息,
- 调用slaves.sh脚本,读取conf/slaves文件并遍历,通过ssh连接到对应slave节点,启动 ${SPARK_HOME}/sbin/start-slave.sh spark://$SPARK_MASTER_HOST:$SPARK_MASTER_PORT
- start-slave.sh在各个节点中,初始化环境变量SPARK_HOME,调用spark-config.sh,调用load-spark-env.sh,根据$SPARK_WORKER_INSTANCES计算WEBUI_PORT端口(worker端口号依次递增 )并启动Worker进程(${SPARK_HOME}/sbin /spark-daemon.sh start org.apache.spark.deploy.worker.Worker $WORKER_NUM --webui-port "$WEBUI_PORT" $PORT_FLAG $PORT_NUM $MASTER "$@")
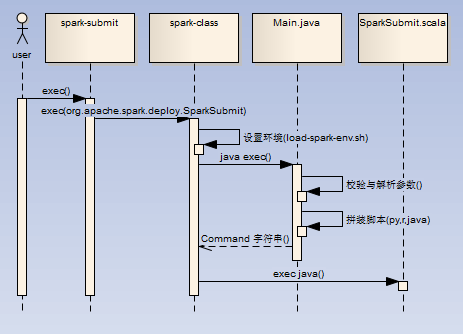
- 直接调用spark-class脚本进行进程创建(./spark-submit --class org.apache.spark.examples.SparkPi --master spark://zqh:7077 ../examples/jars/spark-examples_2.11-2.1.0.jar 10)
- 如果是java/scala任务,那么最终调用SparkSubmit.scala进行任务处理(/opt/jdk1.7.0_79/bin/java -cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/ -Xmx1g -XX:MaxPermSize=256m org.apache.spark.deploy.SparkSubmit --master spark://zqh:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.1.0.jar 10)
- 公共的环境变量由spark-config.sh,bin/load-spark-env.sh进行统一的处理
- 扩在由conf/spark-env.sh进行配置读取实现
- 守护进程由spark-daemon.sh进行创建,进行相关的log,pid前置处理
- spark-class.sh是公共的处理入口脚本
- Main.java负责对参数的解析组装
- 最后执行组装好的command,其中支持scala/java/python/r
【Spark2.0源码学习】-2.一切从脚本说起的更多相关文章
- 【Spark2.0源码学习】-1.概述
Spark作为当前主流的分布式计算框架,其高效性.通用性.易用性使其得到广泛的关注,本系列博客不会介绍其原理.安装与使用相关知识,将会从源码角度进行深度分析,理解其背后的设计精髓,以便后续 ...
- spark2.0源码学习
[Spark2.0源码学习]-1.概述 [Spark2.0源码学习]-2.一切从脚本说起 [Spark2.0源码学习]-3.Endpoint模型介绍 [Spark2.0源码学习]-4.Master启动 ...
- 【Spark2.0源码学习】-3.Endpoint模型介绍
Spark作为分布式计算框架,多个节点的设计与相互通信模式是其重要的组成部分. 一.组件概览 对源码分析,对于设计思路理解如下: RpcEndpoint: ...
- 【Spark2.0源码学习】-6.Client启动
Client作为Endpoint的具体实例,下面我们介绍一下Client启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/bin/jav ...
- 【Spark2.0源码学习】-4.Master启动
Master作为Endpoint的具体实例,下面我们介绍一下Master启动以及OnStart指令后的相关工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-5.Worker启动
Worker作为Endpoint的具体实例,下面我们介绍一下Worker启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-9.Job提交与Task的拆分
在前面的章节Client的加载中,Spark的DriverRunner已开始执行用户任务类(比如:org.apache.spark.examples.SparkPi),下面我们开始针对于用 ...
- 【Spark2.0源码学习】-10.Task执行与回馈
通过上一节内容,DriverEndpoint最终生成多个可执行的TaskDescription对象,并向各个ExecutorEndpoint发送LaunchTask指令,本节内容将关注Exe ...
- 【Spark2.0源码学习】-7.Driver与DriverRunner
承接上一节内容,Client向Master发起RequestSubmitDriver请求,Master将DriverInfo添加待调度列表中(waitingDrivers),下面针对于Dri ...
随机推荐
- Git基础教程(二)
继续上篇Git基础教程(一),在开篇之前,先回顾一下上篇中的基本命令. 配置命令:git config --global * 版本库初始化:git init 向版本库添加文件:git add * 提交 ...
- Json数据解析在Unity3d中的应用
最近做项目过程中因为Json文件名写错了一个字母Unity报错,找错误找到半夜,当时为了验错,写了一个小Demo,正好借此总结一下Json. 1.什么是Json JSON(JavaScript Obj ...
- PHP解耦的三重境界(浅谈服务容器)
阅读本文之前你需要掌握:PHP语法,面向对象 在完成整个软件项目开发的过程中,有时需要多人合作,有时也可以自己独立完成,不管是哪一种,随着代码量上升,写着写着就"失控"了,渐渐&q ...
- (读书笔记)第2章 TCP-IP的工作方式
第2章 TCP-IP的工作方式 TCP/IP协议系统 为了实现TCP的功能,TCP/IP的创建者使用了模块化的设计.TCP/IP协议系统被分为不同的组件,每个组件分别负责通信过程的一个步骤.这种模块化 ...
- 当前最上层的视图控制器vc 和 当前最上层的导航控制器nav
在处理 URL Router 跳转的时候,我们经常需要得到 当前最上层的视图控制器 和 当前最上层的导航控制器 来进行视图跳转或者方法调用.- (UIViewController *)currentV ...
- Java容器源码解析之——ArrayList
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess ...
- 一个web应用的诞生(8)--博文发布
这个系统一直号称轻博客,但貌似博客的功能还没有实现,这一章将简单的实现一个博客功能,首先,当然是为数据库创建一个博文表(models\post.py): from .. import db from ...
- 帝国CMS万能标签的使用
标签名称: 带模板的信息调用标签[万能标签] [ecmsinfo]栏目ID/专题ID,显示条数,标题截取数,是否显示栏目名,操作类型,标签模板ID,只显示有标题图片[/ecmsinfo] 说明:e ...
- 技术方案:在外部网址调试本地js(基于fiddler)
1 解决的问题 1) 场景1:生产环境报错 对前台开发来说,业务逻辑都在js中,所以报错90%以上都是js问题. 如果生产环境出现报错,但是测试环境正常.这时修改了代码没有环境验证效果, ...
- ubuntu16.10下安装erlang和RabbitMQ
Ubuntu系统下安装RabbitMQ(我选择的是Ubuntu Server 16.10) 1.首先必须要有Erlang环境支持 --安装之前要装一些必要的库(Erlang开发环境同样)(参考:duq ...