【操作教程】利用YCSB测试巨杉数据库性能
一、前言
巨杉数据库(SequoiaDB)是国内第一款新一代文档型分布式数据库,巨杉数据库由巨杉软件完全自主研发,拥有完全自主知识产权,不基于任何其它的开源项目。SequoiaDB数据库是为分布式存储、并行计算模型、云计算资源条件下搭建和运行应用程序而设计的。
作为一款操作性数据库,巨杉数据库在海量数据实时读写场景具有得天独厚的优势,拥有较高的读写性能。
为便于跟其他同类数据库进行比较,在本篇文章中,我们介绍一个专门用于对NoSQL数据库产品进行性能测试的工具——YCSB。
二、YCSB介绍
YCSB全称为Yahoo! Cloud Serving Benchmark,是雅虎开源的一款通用的性能测试框架。YCSB不仅安转简单,还可以自由扩展测试数据类型和支持的数据库产品。通过对其进行扩展,YCSB可以支持对多个不同的NOSQL产品进行性能测试,通过测试结果可以了解数据库在并发写入、读取、更新时的一些指标,比如吞吐量、操作延迟等。
YCSB是由Java语言实现的性能测试工具,其架构如图一所示:

图一 YCSB架构图
Workload Executor是产生应用负载的,DB Interface Layer是将特定数据库的API转为YCSB的API,用户可以自定义负载和数据库。
YCSB包括两个组件:
YCSB客户端,一个可扩展的工作负载生成器;
核心工作负载,一组由YCSB客户端执行的工作负载场景。
YCSB包括一组核心工作负载,其中定义了基本的性能测试场景。利用这些工具负载得到的性能数据,可以对大多数不同系统的性能做出权衡。
目前,YCSB的核心工作负载包括6种,其中的5种如表一所示:

表一 YCSB核心工作负载
用户可以自定义不同操作(read、update、scan、insert)的比例,选择操作目标记录的分布:Zipfian(随机选择记录,存在热记录)、Uniform(等概率随机选择记录)和Latest(近期写入的记录是热记录)。
三、SequoiaDB测试步骤
利用YCSB对SequoiaDB进行测试时,可以按照本章的步骤进行。这里的测试步骤假定只需要运行一个YCSB客户端,因为对于一个9-12台机器的集群规模来说,一个YCSB客户端已经足够。对于更大规模的集群,为了产生足够大的测试压力,可能需要同时运行多个YCSB客户端。但是,在运行一个YCSB客户端不能得到理想的测试结果时,可以尝试并行地运行多个YCSB客户端来提升测试性能。
3.1 安装数据库集群
在测试的硬件环境上安装SequoiaDB,并部署好集群。在运行YCSB客户端之前,需要先建立表来存放数据,对应到SequoiaDB中就是集合,默认情况下,完整的集合名称为ycsb.usertable,ycsb为集合空间,usertable为集合。
为了充分发挥SequoiaDB的分布式处理能力,测试数据需要尽可能打散到多个数据分区组里面。因此,在建立集合的时候需要注意指定Domain参数,Domain值为包含SequoiaDB集群中所有数据节点的数据域。假如集群中包含三个数据分区组:datagroup1、datagroup2、datagroup3,创建集合的语句为:
> var global_domain = db.createDomain("global_domain ", ['datagroup1',' datagroup 2',' datagroup 3'], {AutoSplit:true})
> db.createCS("ycsb", {Domain:" global_domain "})
> db.ycsb.createCL("usertable", {ShardingKey:{_id:1}, ShardingType:"hash"})
3.2 实现DB接口层
目前版本的YCSB默认不支持SequoiaDB,不能直接用于SequoiaDB的测试,但是YCSB作为通用的测试框架,提供了一套方法对其本身进行扩展。所以,在开始测试前,我们需要按照YCSB的扩展要求实现其对SequoiaDB的支持。
DB接口层是一个java类,当YCSB客户端发起读、写、更新、删除请求时,DB接口层负责将这些查询转化为对应数据的API。当运行YCSB客户端时,需要在命令行指定DB接口层的类名,客户端会动态地加载数据库的接口类。命令行或者负载文件中指定的参数值也会传递给DB接口类实例。
DB接口层隐藏了特定数据库的实现细节,当实现了DB接口层后,可以通过YCSB客户端对数据库进行性能测试而不用关心数据库的具体实现,且不需要改变。
DB接口层是一个提供了数据库read、insert、update、delete、scan接口的虚类。因此,需要使用SequoiaDB的java驱动实现这几个方法。创建一个工程,新建一个名为SequoiaDBClient的类,并让其继承com.yahoo.ycsb.DB。
首先,实现init方法。init方法主要用于对数据库对象进行初始化。由于我们使用了SequoiaDB连接池的技术,因此,需要在init方法中进行初始化。连接池初始化的代码示例如下:
try {
SequoiadbOption sdbOption = new SequoiadbOption();
sdbOption.setMaxConnectionNum(maxConnectionnum);
sdbOption.setMaxIdeNum(maxidleconnnum);
sdbOption.setRecheckCyclePeriod(period * );
ConfigOptions connectOpt = new ConfigOptions();
connectOpt.setConnectTimeout();
connectOpt.setMaxAutoConnectRetryTime();
ArrayList<String> urls = new ArrayList<String>();
if (hosts != null){
for (int i= ;i< hosts.length;++i){
urls.add(hosts[i]+":"+port);
System.out.println(i+ "url" + urls.get(i));
}
}else{
String[] urlset = surl.split(",");
for (int i= ;i< urlset.length;++i){
urls.add(urlset[i]);
System.out.println(i+ "url" + urls.get(i));
}
}
sdbpools = new SequoiadbDatasource(urls,"","", connectOpt,sdbOption);
} catch (Exception e) {
System.err.println("Could not initialize Sequoiadb connection pool for Loader: "
+ e.toString());
e.printStackTrace();
throw new DBException(e.toString());
}
然后,实现查询和更新方法。需要实现的方法为:
//Read a single record
public int read(String table, String key, Set<String> fields, HashMap<String,String> result); //Perform a range scan
public int scan(String table, String startkey, int recordcount, Set<String> fields, Vector<HashMap<String,String>> result); //Update a single record
public int update(String table, String key, HashMap<String,String> values); //Insert a single record
public int insert(String table, String key, HashMap<String,String> values); //Delete a single record
public int delete(String table, String key);
每个方法都包括一个集合名称和一个记录键值的参数,对于读操作(read、scan)还有读操作的返回字段值及返回结果。update和insert还包括字段名和字段值得HashMap。
SequoiaDB的read、update、insert、delete使用方法请参考官网Java驱动开发文档。
最后,将以上的实现打成jar包sequoiadb-binding-0.1.4.jar,并放到ycsb-0.1.4目录下。修改bin/ycsb源文件,在dict DATABASES中新增产品SequoiaDB,如图二所示:

图二 ycsb源文件修改
也可以从SequoiaDB获取YCSB测试工具包,我们已经依据YCSB的结构实现了DB Interface Layer,而且我们根据需要对开源YCSB测试工具包进行了整理。我们将与YCSB自身实现相关的文件放在ycsb目录下,将产品实现相关包放在product目录下,在测试相关产品时,先执行ycsb-0.1.4目录下的copy.sh将相关产品的包拷入ycsb目录下。
3.3 配置工作负载
工作负载定义了loading阶段将要装载到数据库中的数据和transaction阶段针对初始化测试数据将要执行的操作。工作负载可以通过参数文件进行定义,也可以在命令行指定。当同时指定时,命令行参数会生效。如果使用参数文件,它在测试的两个阶段都会用到。
参数文件可配置项如表二所示:
|
参数名 |
说明 |
|
fieldcount |
单条记录字段数(默认值:10) |
|
fieldlength |
每个字段大小(默认值:100字节) |
|
readallfields |
是否读取所有记录(默认值:true) |
|
readproportion |
读比例(默认值:0.95) |
|
updateproportion |
更新比例(默认值:0.05) |
|
insertproportion |
插入比例(默认值:0) |
|
scanproportion |
扫描比例(默认值:0) |
|
readmodifywriteproportion |
同一记录读、修改、回写比例(默认值:0) |
|
requestdistribution |
记录选择策略:uniform,zipfian,latest(默认值:uniform) |
|
maxscanlength |
最大scan记录数(默认值:100) |
|
scanlengthdistribution |
scan记录选择策略(默认值:uniform) |
|
insertorder |
记录插入策略:ordered,hashed(默认值:hashed) |
|
operationcount |
操作执行数 |
|
maxexecutiontime |
最大执行时间,单位:秒 |
|
table |
表名(默认值值usertable) |
|
recordcount |
初始化记录条数(默认值:0) |
表二 参数说明
另外,与SequoiaDB实现相关的参数包括:
|
参数名 |
说明 |
|
sequoiadb.host |
SequoiaDB协调节点所在主机(默认值:localhost) |
|
sequoiadb.port |
SequoiaDB协调节点端口号(默认值:11810) |
|
sequoiadb.insertmode |
数据装载方式,支持bulk,single |
|
sequoiadb.bulknumber |
批量插入记录数,insertmode为bulk时生效 |
表三 SequoiaDB相关参数
实践中建议将重要参数放置在参数文件中,而不是通过命令行的方式指定,便于复用。
3.4 选择合适的运行参数
通过参数文件,我们可以定义一个特定的工作负载,除此之外,还有其他的参数可以在执行性能测试时指定,即运行参数。运行参数在运行YCSB客户端时通过命令行指定。运行参数包括:
-threads:客户端线程数。默认情况下,YCSB客户端只运行一个线程,可以通过增加线程数提高整体吞吐量。
-target:每秒操作数目标值。
-s:状态(status)。YCSB客户端定期打印状态,默认情况下,每10s会将运行状态打印出来。
3.5 初始化测试数据
工作负载有两个可执行阶段:初始化测试数据(loading phase)和测试执行(transaction phase)。初始化测试数据使用如下命令:
./bin/ycsb load sequoiadb workloads/sequoia1 -s
数据插入过程需要关注YCSB客户端定期打印的状态信息,如果需要保存状态信息,可以将输出结果重定向到文件。以95%update5%read为例,数据装载过程的状态信息如图三所示:

图三 数据装载过程状态信息
数据装载性能也是数据库性能的一个参考指标,我们需要关注的是INSERT AverageLatency,代表的是插入操作的平均时延,最后的结果会以Excel表的形式导出,方便后续进行结果的统计分析。
3.6 执行测试
数据装载完成后,可以通过如下命令执行测试:
./bin/ycsb run sequoiadb workloads/sequoia1 -s
测试过程也会定期打印状态信息,以95%update5%read为例,测试过程的状态信息如图四所示:

图四 测试执行过程状态信息
测试执行完后,测试结果也会以Excel的形式导出,导出文件路径和导出文件名通过参数exportfile进行配置。测试结果内容如图五所示:

图五 YCSB测试结果内容
从测试结果可以得到总的吞吐量(Throughput)、总耗时(RunTime)以及每一类操作的操作数(Operations)、平台时延(AverageLatency)、最大时延(MaxLatency)、最小时延(MinLatency)等,也可以查看指标随时间序列的变化情况。
四、测试案例
YCSB测试结果中包含多个测试指标值,这些指标值用于评估NoSQL数据库性能时能从各个不同方面对所测试产品进行评估。因此,在用YCSB对SequoiaDB进行测试时,应根据测试目的进行测试规划,并针对性地进行测试结果分析。
若需要跟其他同类产品进行比较,可以使用YCSB默认支持的6种核心工作负载;若要评估SequoiaDB的水平扩展能力,可以以某一个工作负载(比如只读场景)为基础,通过水平增加物理服务器数量,分析性能随物理服务器的变化情况。本文中我们以YCSB常见的几个工作负载为例,说明利用YCSB对SequoiaDB的整体性能进行评估。
4.1 测试环境
数据库服务
|
6台服务器 |
|
|
组件 |
配置 |
|
CPU |
4 core |
|
内存 |
16 GB |
|
磁盘 |
300GB * 1 |
|
OS |
SUSE Linux Enterprise Server (SLES) 12 SP1 |
测试客户端
|
服务器类型 |
机器配置 |
节点数 |
|
测试客户端 |
4C,16G,100G存储,Suse Linux 12 SP1 |
1 |
软件及版本
|
软件项 |
版本 |
说明 |
|
SequoiaDB数据库 |
2.0 |
广州巨杉软件开发有限公司发行的分布式数据库 |
4.2 物理部署
每台测试机器上部署一个数据节点,每个数据节点构成单独的数据节点组。每个机器上都部署有协调节点,可以连接到任意一台物理机上进行数据访问。
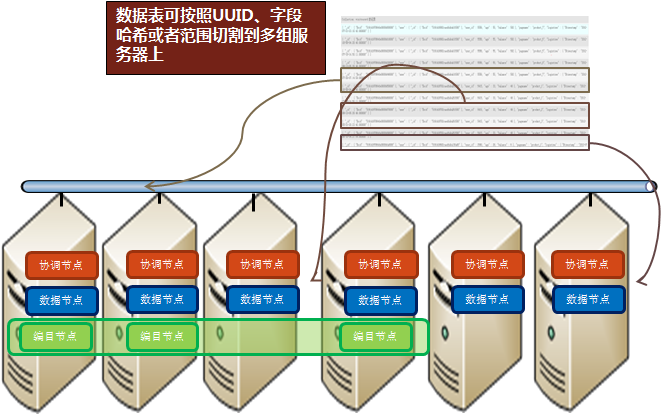
图六 SequoiaDB物理部署
4.3 测试结果
测试场景包括插入、单纯查询、查询为主、查询更新平衡、更新为主、单纯更新六个场景,结果如表四、图七所示:
|
场景 |
场景说明 |
测试结果 |
|
插入 |
批量插入 |
122249 |
|
单纯查询 |
100%查询 |
30650 |
|
查询为主 |
95%查询+5%更新 |
30030 |
|
查询更新平衡 |
50%查询+50%更新 |
20033 |
|
更新为主 |
5%查询+95%更新 |
18909 |
|
单纯更新 |
100%更新 |
18131 |
表四 YCSB测试结果
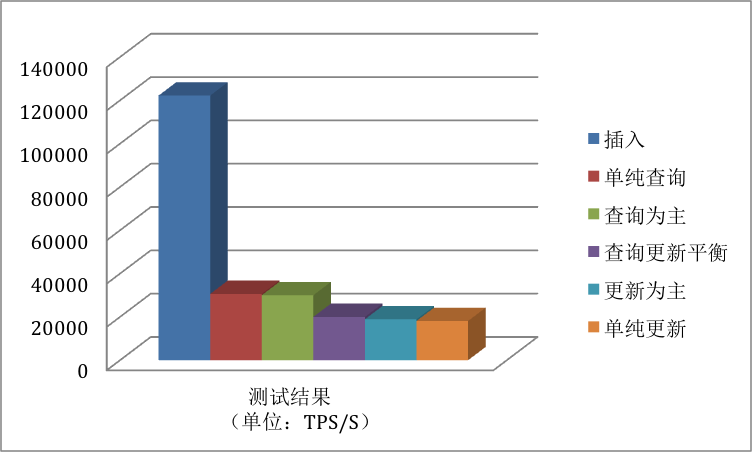
图七 YCSB测试结果
从结果中可以看到,在当前硬件环境条件下,SequoiaDB的插入性能达到122249TPS/S,单纯查询和以查询为主的性能都超过30000TPS/S,单纯更新性能达到18131TPS/S。整体性能非常优秀。
YCSB测试过程中YCSB测试客户端的资源利用情况为:

图八 YCSB测试客户端资源利用情况
SequoiaDB集群服务器资源利用情况为:

图九 SequoiaDB集群服务器资源利用情况
可以看到,由于YCSB测试客户端的CPU利用率几乎跑满,成为性能测试的瓶颈。因此,在改善现有硬件测试环境的情况下,可以提升现有性能测试结果。
五、结论
SequoiaDB完善的功能和良好的可扩展性不仅使其可以使用通用的性能测试工具进行性能评估,也为SequoiaDB的应用开发提供了极大便利。从整体上来看,SequoiaDB性能表现出色,并且还根据国内实际的应用场景做了非常多的本地化优化工作,使得用户在使用SequoiaDB来构建大数据平台时,能在性能和功能上都得到一个比较好的体验。
SequoiaDB巨杉数据库2.6最新版下载
SequoiaDB巨杉数据库技术博客
SequoiaDB巨杉数据库社区

【操作教程】利用YCSB测试巨杉数据库性能的更多相关文章
- 利用http_load测试Web引擎性能
http_load是基于linux平台的性能测试工具,它体积非常小,仅100KB.它以并行复用的方式运行,可以测试web服务器的吞吐量与负载. 一.获得http_load httpd_load的官方站 ...
- python测试mysql数据库性能(二)
一,普通写入数据库 二,批量写入数据库 三,普通写入数据库添加事务 config = { 'host': 'localhost', 'port': 3306, 'database': 'test', ...
- 巨杉Tech|SequoiaDB 巨杉数据库高可用容灾测试
数据库的高可用是指最大程度地为用户提供服务,避免服务器宕机等故障带来的服务中断.数据库的高可用性不仅仅体现在数据库能否持续提供服务,而且也体现在能否保证数据的一致性. SequoiaDB 巨杉数据库作 ...
- jmeter测试 常用数据库的性能
在线程组中设置线程属性,执行次数=线程数*循环次数 本次JOB共插入了5W条记录,从14:56:46开始到15:01:29结束共耗时343s,平均145.8条/s. 同理sql sever:从15:2 ...
- 入门级----黑盒测试、白盒测试、手工测试、自动化测试、探索性测试、单元测试、性能测试、数据库性能、压力测试、安全性测试、SQL注入、缓冲区溢出、环境测试
黑盒测试 黑盒测试把产品软件当成是一个黑箱子,只有出口和入口,测试过程中只要知道往黑盒中输入什么东西,知道黑盒会出来什么结果就可以了,不需要了解黑箱子里面是如果做的. 即测试人员不用费神去理解软件里面 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 分布式数据库Sysbench测试最佳实践
引言 作为一名DBA,时常需要对某些数据库进行一些基准测试,进而掌握数据库的性能情况.本文就针对sysbench展开介绍,帮助大家了解sysbench的一般使用方法. sysbench简介 什么是 ...
- 【SQL server初级】数据库性能优化三:程序操作优化
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第三部分 数据库性能优化三:程序操作优化 概述:程序访问优化也可以认为是访问SQL语句的优化,一个好的SQL语句是可以减少 ...
- 【转】dd命令详解及利用dd测试磁盘性能
dd命令详解及利用dd测试磁盘性能 linux下dd命令详解 名称: dd 使用权限: 所有使用者 manpage 定义: convert and copy a file 使用方式: dd [op ...
- SequoiaDB 巨杉数据库Docker镜像使用教程
为方便用户快速体验,SequoiaDB 巨杉数据库提供基于 Docker 的镜像.本文介绍如何在 Docker 环境下部署 SequoiaDB 分布式集群环境. 集群规划 我们准备在五个容器中部署 ...
随机推荐
- jquery之效果操作
jQuery操作之效果 效果一共分五大类 一.基本 二.滑动 三.淡入淡出 四.自定义 五.设置 咱们先来看一下基本类 一.基本又分为 show() hide() toggle() html代码 &l ...
- Java线程安全性中的对象发布和逸出
发布(Publish)和逸出(Escape)这两个概念倒是第一次听说,不过它在实际当中却十分常见,这和Java并发编程的线程安全性就很大的关系. 什么是发布?简单来说就是提供一个对象的引用给作用域之外 ...
- Spring Boot 整合 Elasticsearch,实现 function score query 权重分查询
摘要: 原创出处 www.bysocket.com 「泥瓦匠BYSocket 」欢迎转载,保留摘要,谢谢! 『 预见未来最好的方式就是亲手创造未来 – <史蒂夫·乔布斯传> 』 运行环境: ...
- mysql一库多表查询主键
mysql> show databases; mysql> use information_schema; mysql> show tables; mysql> select ...
- iOSImagesExtractor for mac 快速拿到iOS应用中所有的图片资源
iOS应用在开发中有很多图片资源被放在了Images.xcassets,在这个文件中的图片在app打包后会被加密成Assets.car文件 这里通过一个工具iOSImagesExtractor可以快速 ...
- 简易-五星评分-jQuery纯手写
超级简单的评分功能,分为四个步骤轻松搞定: 第一步: 引入jquery文件:这里我用百度CDN的jquery: <script src="http://apps.bdimg.com/l ...
- 游戏UI框架设计(五): 配置管理与应用
游戏UI框架设计(五) --配置管理与应用 在开发企业级游戏/VR/AR产品时候,我们总是希望可以总结出一些通用的技术体系,框架结构等,为简化我们的开发起到"四两拨千金"的作用.所 ...
- 一天搞定HTML----列表标签03
1.细说列表标签 2.代码演示 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"&g ...
- Java线程间通信
1.由来 当需要实现有顺序的执行多个线程的时候,就需要进行线程通信来保证 2.实现线程通信的方法 wait()方法: wait()方法:挂起当前线程,并释放共享资源的锁 notify()方法: not ...
- Python 的枚举 Enum
枚举是常用的功能,看看Python的枚举. from enum import Enum Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May' ...