python网络爬虫之LXML与HTMLParser
Python lxml包用于解析html和XML文件,个人觉得比beautifulsoup要更灵活些
Lxml中的路径表达式如下:
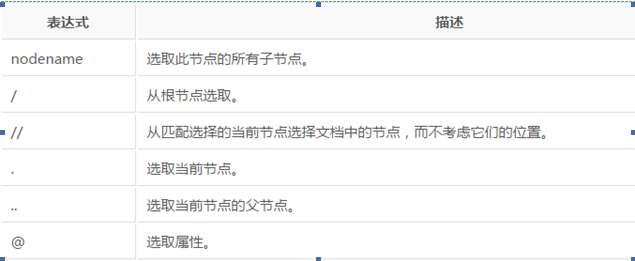
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:


路径表示中还可以选取多个路径,使用’|’运算符,比如下面的样子:
//book/title | //book/price 选取 book 元素的所有 title 和 price 元素。
下面就来看下lxml的用法:还是用我们之前用过的网站,代码如下:
from lxml import etree
def parse_url_xml():
try:
req=urllib2.Request('http://www.xunsee.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/index.shtml')
fd=urllib2.urlopen(req)
html=etree.HTML(fd.read())
result=html.xpath('//*[@id="content_1"]/span[7]/a')
print type(result)
for r in result:
print r.text except BaseException,e:
print e
首先使用etree,然后利用etree.HTML()初始化。然后用xpath进行查找。其中xpath中的//*[@id="content_1"]/span[7]/a就是网页元素的xpath地址
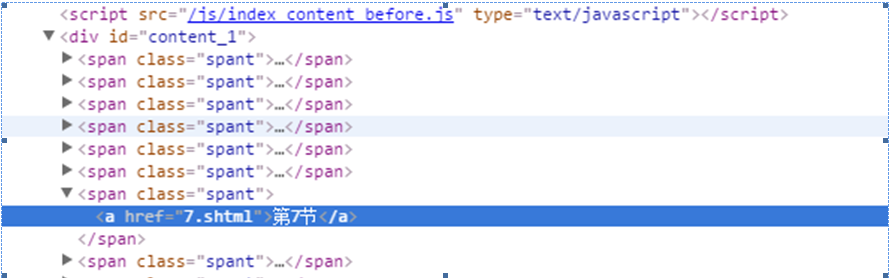
从表达式中可以看到首先找到id属性为content_1的任意标签。//*表示不管位置,只管后面的属性满足即可。然后往下查找第7个span标签,找到下面a的标签。然后的result是一个列表。代表找到的所有的元素。通过遍历列表打印出内容。运行结果如下:
E:\python2.7.11\python.exe E:/py_prj/test.py
<type 'list'>
第7节
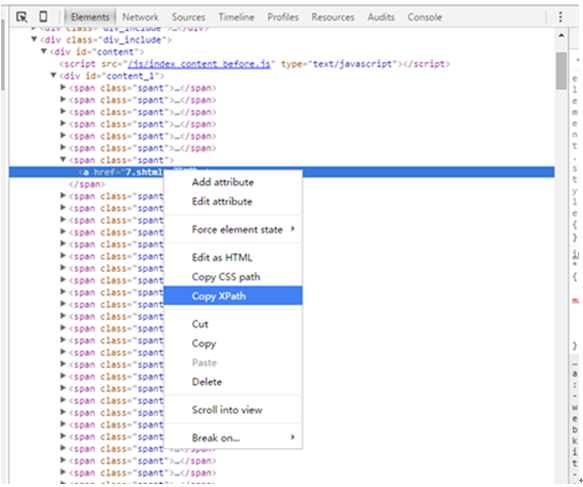
从上面可以看出,其实xpath还是很好写,相对beautifulsoup对元素的定位更加准确。其实如果嫌麻烦,不想写xpath,还有一个更简单的方法。在浏览器中按F12,在网页源代码中找到想定位的元素,然后鼠标右键,点击Copy Xpath就可以得到xpath路径
下面再多举几个例子:比如获取到最后一个span元素,可以用到下面的例子
result=html.xpath('//*[@id="content_1"]/span[last()]/a')
结果如下:
E:\python2.7.11\python.exe E:/py_prj/test.py
第657节
我们还可以精简刚才用到的//*[@id="content_1"]/span[7]/a
精简为://*[@href="7.shtml"]表示直接查找属性为7.shtml的元素
如果想返回多个元素,则可以用下面的方式,表示反悔第7节和第8节
result=html.xpath('//*[@href="7.shtml"] | //*[@href="8.shtml"]')
如果想得到所找节点的属性值:可以用get的方法
result=html.xpath('//*[@href="7.shtml"] | //*[@href="8.shtml"]')
print type(result)
for r in result:
print r.get('href')
结果就会显示节点href属性的值
E:\python2.7.11\python.exe E:/py_prj/test.py
<type 'list'>
7.shtml
8.shtml
下面介绍下HTMLParser的用法:
HTMLParser是python自带的网页解析工具,使用很简单。便于HTML文件的解析
下面我们来看相关代码:
class Newparser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.flag=False
self.text=[]
def handle_starttag(self,tag,attrs):
if tag == 'span':
self.flag=True
def handle_data(self, data):
if self.flag == True:
print data
self.text.append(data)
def handle_endtag(self, tag):
if tag == 'span':
self.flag=False if __name__=="__main__":
parser=Newparser()
try:
req=urllib2.Request('http://www.xunsee.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/index.shtml')
fd=urllib2.urlopen(req)
parser.feed(fd.read())
print parser.text except BaseException,e:
print e
首先定义一个类继承自HTMLParser.在__init__函数中定义一些自己的参数。
parser.feed(fd.read()) 其中feed函数是类自带的函数。参数就是网页的HTML代码。其中feed相当于一个驱动函数。我们来看下feed函数的原型。下面是feed的实现。可以看到实现了2个功能。其中就是将传入的网页代码赋值给rawdata。然后运行goahead开始进行处理
def feed(self, data):
r"""Feed data to the parser. Call this as often as you want, with as little or as much text
as you want (may include '\n').
"""
self.rawdata = self.rawdata + data
self.goahead(0)
goahead函数代码过多,这里就不全部贴出来,具体功能就是遍历rawdata每行数据。然后根据的不同标识调用不同的函数。关键函数如下。可以看到当遇到’<’开始的时候。调用parse_startag,当遇到’</’调用parse_endtag

parse_startag里面实现handle_starttag,parse_endtag里面实现handle_endtag。
代码中的handle_starttag和handle_endtag是个空函数。只是传入了当前的tag以及attrs.这就给了我们重写此函数的机会
def handle_starttag(self, tag, attrs):
pass
def handle_endtag(self, tag):
pass
def handle_data(self, data):
pass
其中hanle_data是处理网页代码中的具体数据
说了这么多,应该对HTMLParser的实现很清楚了。对每行网页代码进行处理。依次判断是否进入handle_starttag,handle_endtag,handle_data。HTMLParser为我们解析出了每行的tag,attrs以及data。我们通过重写这些函数提取我们需要的信息。那么回到我们的之前的代码,这个代码我们要实现的功能是将<span></span>的字段提取出来。
首先__init__定义了2个参数,flag以及text,flag初始值为False
def __init__(self):
HTMLParser.__init__(self)
self.flag=False
self.text=[]
handle_starttag中实现只要tag=span,那么设置flag为True
def handle_starttag(self,tag,attrs):
if tag == 'span':
self.flag=True
handle_data中实现只要flag=True则提取出data数据并保存在text列表里面
def handle_data(self, data):
if self.flag == True:
print data
self.text.append(data)
那么这个提取数据的动作在什么时候结束呢:这就要看handle_endtag了。同样的在遇到tag=span的时候,则设置flag=False。这样就不会提取data数据了,直到遇到下一个tag=span的时候。
def handle_endtag(self, tag):
if tag == 'span':
self.flag=False
这就是HTMLParser的全部功能。是不是比之前的Beautifulsoup以及lxml都感觉要简洁明了很多呢。对于不规范的网页,HTMLParser就比Beautifulsoup和lxml好使。下面列出所有的函数功能:
handle_startendtag 处理开始标签和结束标签
handle_starttag 处理开始标签,比如<xx>
handle_endtag 处理结束标签,比如</xx>
handle_charref 处理特殊字符串,就是以&#开头的,一般是内码表示的字符
handle_entityref 处理一些特殊字符,以&开头的,比如
handle_data 处理数据,就是<xx>data</xx>中间的那些数据
handle_comment 处理注释
handle_decl 处理<!开头的,比如<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
handle_pi 处理形如<?instruction>的东西
其他的实现都大同小异。从下一章开始将介绍scrapy的用法
python网络爬虫之LXML与HTMLParser的更多相关文章
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 从零开始学Python网络爬虫PDF高清完整版免费下载|百度网盘
百度网盘:从零开始学Python网络爬虫PDF高清完整版免费下载 提取码:wy36 目录 前言第1章 Python零基础语法入门 11.1 Python与PyCharm安装 11.1.1 Python ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件)
python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件) requests是一个Python第三方库,用于向URL地址发起请求 bs4 全名 BeautifulSoup4, ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
随机推荐
- angularjs jsonp跨域
<script> (function(angular){ "use strict" var app= angular.module('appController',[] ...
- Firefox实用插件记录
之前总结过一个软件推荐的小文,用来记录一直以来在软件开发过程中遇到的各种实用的软件.后来发现里面越来越多的记录了Firefox的插件,所以今天决定单独抽出一个页面来记录Firefox的插件.因为平时大 ...
- Azure Event Bus 技术研究系列1-Event Hub入门篇
前两个系列研究了Azure IoT Hub和Azure Messaging.最近准备继续研究Azure Event Bus,即Azure的事件中心.首先, Azure Event Hub的官方介绍: ...
- Linux环境g++编译TinyXML动态库
除了CMarkup,tinyxml也是C/C++下解析XML很好的工具.在linux下用g++编译tinyxml的步骤如下(tinyxml版本2.6.2): 进入tinyxml解压目录,用文本编辑器打 ...
- 微信小程序开发之获取openid及用户信息
1. 获取openid 1.1 获取code 调用接口获取登录凭证(code)进而换取用户登录态信息,包括用户的唯一标识(openid) 及本次登录的会话密钥(session_key).用户数据的加解 ...
- ArrayList源码解析(二)自动扩容机制与add操作
本篇主要分析ArrayList的自动扩容机制,add和remove的相关方法. 作为一个list,add和remove操作自然是必须的. 前面说过,ArrayList底层是使用Object数组实现的. ...
- 无锁atomicInteger
AtomicInteger可以保证硬件上的原子操作 1.主要原理 CAS操作 在进行数据更新的时候,会进行与内存中的地址进行比较,若预期值与内存中的值相同,则进行数据上的更新,若值不同,则更新失败, ...
- ArrayList源码解析(三)
1.isEmpty() 如果此列表中没有元素,则返回 true /** * Returns <tt>true</tt> if this list contains no el ...
- 009一对一 主键关联映射_单向(one-to-one)
009一对一 主键关联映射_单向(one-to-one) ² 两个对象之间是一对一的关系,如Person-IdCard(人—身份证号) ² 有两种策略可以实现一对一的关联映射 主键关联:即让两个 ...
- struts2.1.6教程十二、总结
本教程对struts2的基本知识进行了一些说明,关于struts2的更多详细内容应参看struts2的官方文档及提供的app实例. 下面对struts2的基本执行流程作一简要说明,此流程说明可以结合官 ...