[saiku] 使用 Apache Phoenix and HBase 结合 saiku 做大数据查询分析
saiku不仅可以对传统的RDBMS里面的数据做OLAP分析,还可以对Nosql数据库如Hbase做统计分析。
本文简单介绍下一个使用saiku去查询分析hbase数据的例子。
1、phoenix和hbase的关系
我们知道:hbase虽然好用,但是想用jdbc方式来查询数据单纯的hbase是办不到的,这里需要借助一个JDBC中间件名叫phoenix(英文:凤凰)来实现对HBASE的JDBC查询。在phoenix中可以用简单的sql语句来访问hbase的数据。中间的转换对用户是透明的。 安装只需3步:
、下载phoenix并解压到用户家目录
、将phoenix/lib下的core包和client包拷贝到hbase的lib目录下
、将hbase的hbase-site.xml拷贝到phoenix的bin目录下
注意,集群的每个节点都要如此配置哦 启动phoenix:
进入phoenix/bin,输入命令:./sqlline.py master: master 是zookeeper节点的ip,通过hosts文件映射
2181是zookeeper客户端的默认端口号 进入这个shell之后,可以通过phoenix的命令来操作hbase
比如:
!tables 查看所有表
!columns 表名称 查看某个表的列结构
!quit 退出shell
其他的命令可以输入help查看
普通sql语句直接执行sql操作 如果不用linux shell 客户端,可以使用squirrel sql clinet 这个工具(类似于查询mysql用navicat for mysql) phoenix 安装使用教程:
http://www.cnblogs.com/laov/p/4137136.html phoenix官网语法:
http://phoenix.apache.org/language/index.html squirrel sql clinet 安装使用教程:
http://blog.sina.com.cn/s/blog_79346ff80102v6hm.html
2、在项目中集成phoenix
准备工作:用phoenix创建表Company和Order4 ,为查询列创建索引(耗磁盘资源) 批量导入测试数据
Company(ID-BIGINT,CODE-VARCHAR,NAME-VARCHAR)
ORDER4
| | | ORDER4 | ID | -5 | BIGINT |
| | | ORDER4 | CODE | 12 | VARCHAR |
| | | ORDER4 | NAME | 12 | VARCHAR |
| | | ORDER4 | STATUS | 12 | VARCHAR |
| | | ORDER4 | QUANTITY | 6 | FLOAT |
| | | ORDER4 | ORDERTYPE | 12 | VARCHAR |
| | | ORDER4 | DETAILSIZE | 6 | FLOAT |
| | | ORDER4 | COMPANYID | -5 | BIGINT |
| | | ORDER4 | CREATER | 12 | VARCHAR |
| | | ORDER4 | CREATE_TIME | 91 | DATE |
| | | ORDER4 | UPDATER | 12 | VARCHAR |
| | | ORDER4 | UPDATE_TIME | 91 | DATE |
建表sql例子
DROP TABLE IF EXISTS P_1000;
CREATE TABLE IF NOT EXISTS P_1000 (
HOST CHAR(2) NOT NULL, DOMAIN VARCHAR NOT NULL,
FEATURE VARCHAR NOT NULL,
USAGE.DATE VARCHAR, STATS.ACTIVE_VISITOR INTEGER
CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE)
) SPLIT ON ('CSGoogle','CSSalesforce','EUApple','EUGoogle',
'EUSalesforce', 'NAApple','NAGoogle','NASalesforce');
逐条插入数据
UPSERT INTO p_1000 VALUES('11','localhost1','localhost1','2015-10-11',3);
UPSERT INTO p_1000 VALUES('12','localhost2','localhost2','2015-10-12',31);
UPSERT INTO p_1000 VALUES('13','localhost3','localhost3','2015-10-13',67);
批量导入数据步骤
编写建表sql保存到表名.sql
使用excel生成数据并保存为csv格式 名称必须是表名.csv
编写查询测试sql保存为表名_test.sql
使用phoenix/bin下面的脚本psql.py来执行批量导入
#建表p_1000并导入数据并查询出导入数据
./psql.py master,node1,node2 p_1000_table.sql p_1000.csv p_1000_select.sql
参数分别是:zookeeper节点、建表sql、数据文件、查询sql
其他例子:
psql localhost my_ddl.sql
psql localhost my_ddl.sql my_table.csv
psql -t MY_TABLE my_cluster:1825 my_table2012-Q3.csv
psql -t MY_TABLE -h COL1,COL2,COL3 my_cluster:1825 my_table2012-Q3.csv
psql -t MY_TABLE -h COL1,COL2,COL3 -d : my_cluster:1825 my_table2012-Q3.csv
(1)导入jar
phoenix-4.6.0-HBase-1.0-client-without-hbase.jar
phoenix-4.6.0-HBase-1.0-server.jar
/usr/lib/hbase/hbase.jar
/usr/lib/hadoop/hadoop-common.jar
/usr/lib/hadoop/hadoop-auth.jar
特别注意:如果出现类冲突,将phoenix的jar包优先置顶(Java Build Path)
(2)配置 datasource - order.txt
type=OLAP
name=ORDER_COMPANY
driver=mondrian.olap4j.MondrianOlap4jDriver
Locale=zh_CN
DynamicSchemaProcessor=mondrian.i18n.LocalizingDynamicSchemaProcessor
location=jdbc:mondrian:Jdbc=jdbc:phoenix:master,node1,node2;Catalog=res:saiku-schemas/order.xml;JdbcDrivers=org.apache.phoenix.jdbc.PhoenixDriver
username=name
password=pwd
(3)配置 schema - order.xml
注意表名不管定义时是什么样,在schema文件中都必须大写,否则会报错 table undefined
公司表作为基础信息表,和订单表进行关联。
<?xml version="1.0"?>
<Schema name="ORDER_COMPANY">
<Dimension type="StandardDimension" name="COMPANY_DIMENSION">
<Hierarchy hasAll="true" allMemberName="All Types">
<Table name="COMPANY"></Table>
<Level name="COMPANY_CODE" column="CODE" uniqueMembers="false"/>
<Level name="COMPANY_NAME" visible="true" column="ID" nameColumn="NAME" table="COMPANY" type="String" uniqueMembers="false"/>
</Hierarchy>
</Dimension>
<Cube name="ORDER_COMPANY_CUBE">
<Table name="ORDER4"/>
<DimensionUsage source="COMPANY_DIMENSION" name="USE_COMPANY_DIMENSION" visible="true" foreignKey="COMPANYID" highCardinality="false"></DimensionUsage>
<Dimension name="ORDER_DIMENSION">
<Hierarchy hasAll="true" allMemberName="All Types">
<Level name="Date" column="CREATE_TIME" uniqueMembers="false"/>
</Hierarchy>
</Dimension>
<Measure name="QUANTITY" column="QUANTITY" aggregator="sum" formatString="Standard"/>
</Cube>
</Schema>
(4)修改Mondrina的源代码,重编译到项目中
在查询的时候,需要将大数据表放在所有表之前,不然查询会报错
比如:ORDER4 100多万 company 4条
select * from ORDER4 as o,COMPANY as c where o.companyid = c.id //可以正常查询
select * from COMPANY as c,ORDER4 as o where o.companyid = c.id //报错
Error: Encountered exception in sub plan [0] execution.
SQLState: null
ErrorCode: 0
RolapStar.addToFrom -》 将mdx查询语句转换为传统sql查询语句
query.addFrom(relation, alias, failIfExists);
//将这一句挪到方法最后,这样就调换了事实表(order4大数据表-在前)和 维度表(company小表-在后)
public void addToFrom(
SqlQuery query,
boolean failIfExists,
boolean joinToParent)
{
Util.assertTrue((parent == null) == (joinCondition == null));
if (joinToParent) {
if (parent != null) {
parent.addToFrom(query, failIfExists, joinToParent);
}
if (joinCondition != null) {
query.addWhere(joinCondition.toString(query));
}
}
query.addFrom(relation, alias, failIfExists);//将这一句挪到方法最后
}
翻译的sql语句(能良好执行的)
select
"COMPANY"."CODE" as "c0",
"COMPANY"."ID" as "c1",
"ORDER4"."CREATE_TIME" as "c2",
sum("ORDER4"."QUANTITY") as "m0"
from
"ORDER4" as "ORDER4",//大数据表在前
"COMPANY" as "COMPANY"//小数据表在后
where
"ORDER4"."COMPANYID" = "COMPANY"."ID"
group by
"COMPANY"."CODE",
"COMPANY"."ID",
"ORDER4"."CREATE_TIME"
测试结果
多表联合单维度(10s左右)

多表联合多维度(据情况而定)
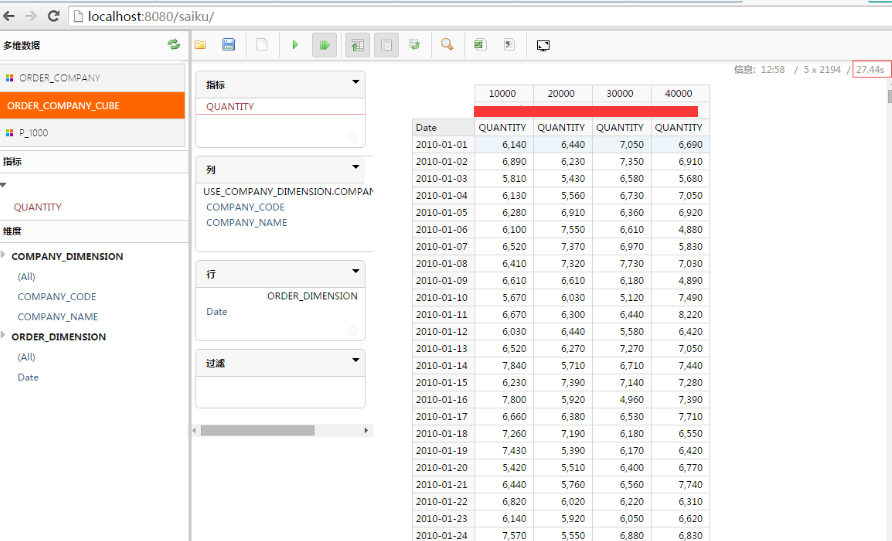
备注:mondrian 和 phoenix 集成支持表join ,但是只能是事实表关联维度表,查询速度才正常,查询效率与mysql 比较,无明显提升,可能还有点慢,但是至少解决了数据仓库在hbase中,使用saiku做分析是没问题,经测试数据量在102w事实表和4条维度表关联查询 ,基本保持在7-10秒之间。总之:大数据表在前就对了!
参考资料:
https://blogs.apache.org/phoenix/entry/olap_with_apache_phoenix_and
phoenix-jdbc测试类
package org.saiku.database; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map; import org.apache.phoenix.jdbc.Jdbc7Shim.Statement; /**
* 连接数据库的工具类,被定义成不可继承且是私有访问
*/
public final class PhoenixDBUtils {
// private static String url = "jdbc:mysql://localhost:3306/testdb";
// private static String user = "user";
// private static String psw = "pwd"; private static String url = "jdbc:phoenix:master,node1,node2";
private static String user = "hadoop";
private static String psw = "hadoop"; private static Connection conn;
private static Statement statement; static {
try {
// Class.forName("com.mysql.jdbc.Driver");
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
} public static void main(String args[]) throws SQLException {
conn = DriverManager.getConnection(url, user, psw);
statement = (Statement)conn.createStatement();
System.out.println("HI,The connection is:" + conn);
System.out.println("HI,The statement is:" + statement); String sql = "select * from student";
sql = "select \"data\".\"xxid\",\"data\".\"xsrs\" from student";
PreparedStatement ps1 = conn.prepareStatement(sql);
ResultSet rs1 = ps1.executeQuery();
System.out.println("ResultSet is : " +rs1);
List list = resultSetToList(rs1);
System.out.println("LIST is : "+ list);
} private PhoenixDBUtils() {
} /**
* 获取数据库的连接
*
* @return conn
*/
public static Connection getConnection() {
if (null == conn) {
try {
conn = DriverManager.getConnection(url, user, psw);
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
return conn;
} public static Statement getStatement() {
if (null == statement) {
try {
statement = (Statement) PhoenixDBUtils.getConnection().createStatement();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
return statement;
} /**
* 释放资源
*
* @param conn
* @param pstmt
* @param rs
*/
public static void closeResources(Connection conn, PreparedStatement pstmt,
ResultSet rs) {
if (null != rs) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
} finally {
if (null != pstmt) {
try {
pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
} finally {
if (null != conn) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
}
}
} /**
*
* @Method: com.wdcloud.sql.DBUtils.java
* @Description: TODO 将ResultSet转成list
* @author: luoshoulei
* @date: 2015年11月19日 下午2:08:25
* @version: 1.0
* @param rs
* @return
* @throws java.sql.SQLException
* @List
* @update [日期YYYY-MM-DD] [更改人姓名][变更描述]
*/
public static List resultSetToList(ResultSet rs)
throws java.sql.SQLException {
if (rs == null)
return Collections.EMPTY_LIST;
ResultSetMetaData md = rs.getMetaData(); // 得到结果集(rs)的结构信息,比如字段数、字段名等
int columnCount = md.getColumnCount(); // 返回此 ResultSet 对象中的列数
List list = new ArrayList();
Map rowData = new HashMap();
while (rs.next()) {
rowData = new HashMap(columnCount);
for (int i = 1; i <= columnCount; i++) {
rowData.put(md.getColumnName(i), rs.getObject(i));
}
list.add(rowData);
}
return list;
} }
[saiku] 使用 Apache Phoenix and HBase 结合 saiku 做大数据查询分析的更多相关文章
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
- 大数据查询——HBase读写设计与实践--转
背景介绍 本项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的不断 ...
- Apache Hudi表自动同步至阿里云数据湖分析DLA
1. 引入 Hudi 0.6.0版本之前只支持将Hudi表同步到Hive或者兼容Hive的MetaStore中,对于云上其他使用与Hive不同SQL语法MetaStore则无法支持,为解决这个问题,近 ...
- 新闻实时分析系统Hive与HBase集成进行数据分析 Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- apache phoenix 安装试用
备注: 本次安装是在hbase docker 镜像的基础上配置的,主要是为了方便学习,而hbase搭建有觉得 有点费事,用镜像简单. 1. hbase 镜像 docker pull har ...
- Phoenix on HBase
(一)概要 Apache Phoenix是基于BSD许可开源的一个Java中间层,可以让开发者在Apache HBase上执行SQL查询.Apache Phoenix主要特性: 嵌入式的JDBC驱动, ...
- 免费报名 | 汇聚HBase&大数据最前沿 Apache HBaseConAsia2019盛会火热来袭
Apache HBase介绍 Apache HBase是基于Apache Hadoop构建的一个高可靠性.高性能.可伸缩的分布式存储系统,它提供了大数据背景下的高性能的随机读写能力,HBase是Goo ...
- 大数据技术之HBase原理与实战归纳分享-上
@ 目录 概述 定义 特点 数据模型 概述 逻辑结构 物理存储结构 数据模型 应用场景 基础架构 安装 前置条件 部署 启动服务 高可用 Shell操作 基础操作 命令空间 DDL DML 概述 定义 ...
随机推荐
- 一维条码打印的C#实现(Code128)
1.CODE128基础知识 CODE128有三个版本: CODE128A: 标准数字和字母, 控制符, 特殊字符 CODE128B: 标准数字和字母, 小写字母, 特殊字符 CODE128C: [00 ...
- 首先,定义描述学生的类——Student,包括学号(int)、 姓名(String)、年龄(int)等属性;二个方法:Student(int stuNo,String name,int age) 用于对对象的初始化,outPut()用于输出学生信息。其次,再定义一个主类—— TestClass,在主类的main方法中创建多个Student类的对象,使用这些对象来测 试Student类的功能。
package lianxi; public class Student { String Name; int XveHao,Age; Student(String Name,int XveHao,i ...
- php中一个"异类"语法: $a && $b = $c;
php中一个"异类"语法: $a && $b = $c; $a = 1;$b = 2;$c = 3;$a && $b = $c;echo & ...
- CUBRID学习笔记 13 日志文件
欢迎转载 ,转载时请保留作者信息.本文版权归本人所有,如有任何问题,请与我联系wang2650@sohu.com . 过错 CUBRID Broker Log Files 可以理解为数据库中间件日志 ...
- tilemap坐标转换
像素点跟tile的索引之间的转换//从cocos2d-x坐标转换为Tilemap坐标CCPoint GameMap::tileCoordForPosition(CCPoint position){ i ...
- linux软件下载及安装
1.jdk安装以及下载地址 rpm.tar.gz格式下载 | bin格式下载 官方bin格式下载 | 安装 2.centos安装phpstorm 戳我
- eclispse 中集成多个tomcat
1.背景 在本地需要运行两个项目进行测试时,需要同时启动两个服务器,所以集成多个Tomcat到eclipse就成为一个必要的知识点. 2.准备知识 2.1 因为同时在一台主机上运行,所以多个服务器共用 ...
- C++——输入、输出和文件
一.C++输入和输出概述 1.1.流和缓冲区 C++程序把输入和输出看作字节流.输入时,程序从输入流中抽取字节:输出时,程序将字节插入到输出流中.对于面相文本的程序,每个字节代表一个字符,更通俗地说, ...
- java语法糖3 深入剖析Java中的装箱和拆箱
装箱 在Java SE5之前,如果要生成一个数值为10的Integer对象,必须这样进行: Integer i = new Integer(10); 而在从Java SE5开始就提供了自动装箱的特性, ...
- virtualbox中centos系统配置nat+host only上网(zhuan)
http://www.cnblogs.com/leezhxing/p/4482659.html **************************************************** ...