(译) 强化学习 第一部分:Q-Learning 以及相关探索
(译) 强化学习 第一部分:Q-Learning 以及相关探索
Q-Learning review:
Q-Learning 的基础要点是:有一个关于环境状态S的表达式,这些状态中可能的动作 a,然后你学习这些状态下他们action的值。直观的讲,这个值,Q,是 状态-动作值(state-action value.) 所以,在Q-Leaning中,你设置初始 状态-动作值为0,然后你去附近溜溜并且探索 状态-动作空间。在你试了一个状态下的某一动作之后,你会评价将会转向哪一个状态。如果该动作将导致一个不想要的输出,你减小在那个状态下,那个动作的Q值,才能使得其他动作将会得到一个较大的值,这样在下一次你处于当前状态下时,才可能被选中,从而替换掉这次所执行的那个动作。同样的,如果你执行的那个动作得到了奖励,那么在那个状态下,该动作的权重将会被增加,所以当你在那个状态下时,你可能会再一次的选择该行动。重要的是,当你更新Q的时候,你也在更新之前的 状态-动作组合。只有你看到结果的时候,你才能更新Q。
让我们首先看一个 “猫抓耗子” (cat vs mouse) 的例子,当然了,你是老鼠。一只猫就在你的眼前,你选择直走,就会碰到猫,然后被吃掉,身为耗子,当前不希望自己就这样JJ了,所以,你必须减小在那个情况下,选择那个动作的权重,所以,当你再一次的出现在猫眼前时,你就会选择从一侧闪过或者往后倒退(除非你有重生技能,那就不用担心被吃的问题了)。注意到,当没有猫在你面前时,你并不会减小前进的权重,我们要前进搜索食物啊,所以,除非有猫站在你面前,否则都不会影响你前进的步伐。相反的情况下,当你面前有奶酪的时候,你选择了前进,那么你就会得到奖励。当下一次,有奶酪出现在你眼前,你就会很有可能选择“Move Forward”,因为你上次执行该操作得到了奖励。
假设我们又是老鼠了,我们当前的状态是:奶酪就在我们面前一步,但是我们还没有学习任何事情,(action box 中的空白代表 0)。所以我们随机的选择一个动作,并且假设我们恰巧选择了“Move Forward”。如下图所示:
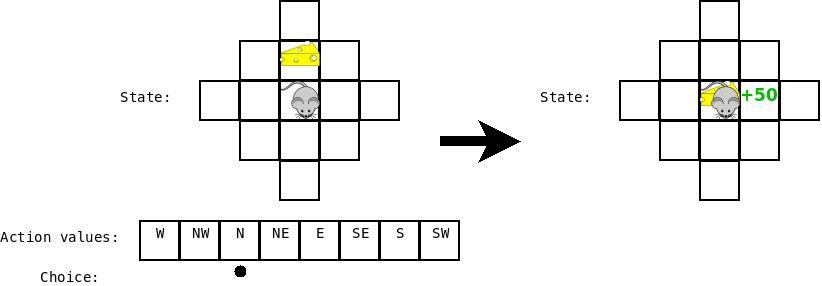
那么,在这种情况下,我们就得到了奖励,所以我们就可以返回来更新对应“Cheese is one step ahead”以及动作“Move Forward”的Q值,然后增加那个状态下对应“Move Forward”的值。
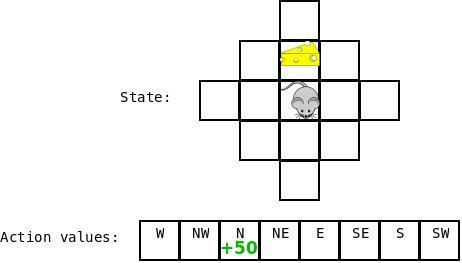
然后假设现在奶酪被移动了,然后我们又要四处移动了,现在我们的状态是:“cheese is two steps ahead”,然后我们做出移动,达到的目的是:“cheese is one step ahead”。
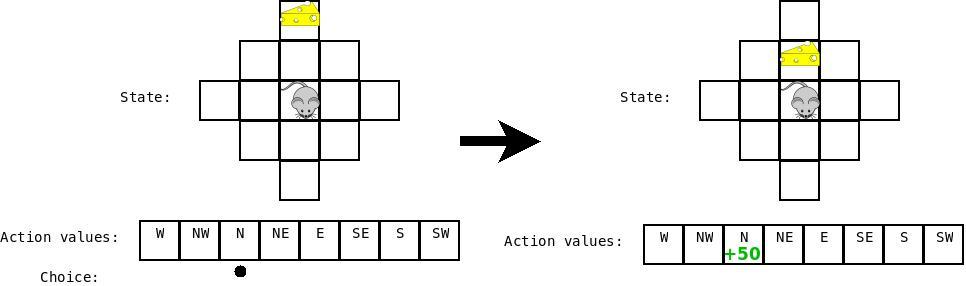
当我们要更新上一次 state-action combination 的Q值时,我们考虑状态“cheese is one step ahead”的所有Q值。我们看到他们这些值中有一个是非常高的(对应于动作“Move Forward”) 并且该值结合到上一次 state-action combination 的更新之中去。

特别地,我们更新利用公式:$Q(s, a) = \alpha * (reward(s, a) + max(Q(s')) - Q(s, a))$ 其中,s是之前的状态,a是之前的行动,$s'$ 是当前的状态,$\alpha$ 是衰减因子(此处设置为 0.5)。
直观上来看,为了执行状态s下的动作s而改变Q值 和 实际的奖励 $(reward(s, a) + max(Q(s'))$与期望的奖励 $Q(s, a)$乘以一个学习率 $\alpha$ 不同的。你可以将此想象成一种PD control(我想问,什么是PD control ?),驱使你的系统朝向目标,也就是这种情况下的正确的Q值。
此处,我们评价向前移动的奖励,当奶酪在前方两步的时候,由于移动到那个状态(0)的奖励,加上从那个状态得来的最好的行动带来的奖励(moving into the cheese +50),减去 那个状态下(0)期望的值,乘以我们的学习率(0.5) = +25.
Exploration:
最直观的运行Q-Learning,state-action values 被存贮在一个查找表当中。所以,我们有一个巨大的表格,大小为:$N*M$,其中N是不同可能状态的个数,M是不同可能动作的个数。所以,当做决定的时候,我们简单的浏览下表格,寻找那个状态的对应的动作值,选择最大的:
- def choose_action(self, state)
- q = [self.getQ(state, a) for a in self.actions]
- maxQ = max(q)
- action = self.actions[maxQ]
- return action
还有一些额外的东西需要添加。
首先,我们需要处理存在多个动作具有相同值的情况。为了处理这种情况,我们随机的挑选一个值进行处理:
- def choose_action(self, state):
- q = [self.getQ(state, a) for a in self.actions]
- maxQ = max(q)
- count = q.count(maxQ)
- if count > 1:
- best = [i for i in range(len(self.actions)) if q[i] == maxQ]
- i = random.choice(best)
- else:
- i = q.index(maxQ)
- action = self.actions[i]
- return action
这就可以让我们摆脱那种情况的影响,但是如果我们曾经恰巧碰到一个不错的选择,我们将总是选择这个,即使存在一个更好的选择。为了克服这种问题,我们将引入一个额外的项目,$\epsilon$。我们接着随机的产生一个值,如果那个值小于 $\epsilon$,然后就随机的选择一个动作,而不是跟随我们选择最大Q值的常规策略:
- def choose_action(self, state):
- if random.random() < self.epsilon: # exploration action = random.choice
- best = [i for i in range(len(self.actions)) if q[i] == maxQ]
- i = random.choice(best)
- else:
- i = q.index(maxQ)
- action = self.actions[i]
- return action
a
(译) 强化学习 第一部分:Q-Learning 以及相关探索的更多相关文章
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- 机器学习之强化学习概览(Machine Learning for Humans: Reinforcement Learning)
声明:本文翻译自Vishal Maini在Medium平台上发布的<Machine Learning for Humans>的教程的<Part 5: Reinforcement Le ...
- 【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083 DQN(Deep Q-Learning)是将深度学习deeplearni ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
原文地址: https://arxiv.org/pdf/1811.07871.pdf ======================================================== ...
随机推荐
- IBM RSA 的语言设置
右键 IBM Rational software Architect for websphere software 快捷方式 ----> 打开文件位置 在 eclipse.ini 文件中添加参数 ...
- 第一课 Hello
using System; using Android.App; using Android.Content; using Android.Runtime; using Android.Views; ...
- poj2429 大数分解+dfs
//Accepted 172 KB 172 ms //该程序为随机性算法,运行时间不定 #include <cstdio> #include <cstring> #includ ...
- iOS开发经验总结(转)
在iOS开发中经常需要使用的或不常用的知识点的总结,几年的收藏和积累(踩过的坑). 一. iPhone Size 手机型号 屏幕尺寸 iPhone 4 4s 320 * 480 iPhone 5 5s ...
- Ubuntu 14.10 下设置静态IP
修改 /etc/network/interfaces 文件 sudo nano /etc/network/interfaces 修改为 # 前面的不变auto eth0 iface eth0 inet ...
- 第一个PHP程序
<html> <head> <title><?php echo"这是第一个php程序"?></title> <st ...
- Android库Volley的使用介绍
Android Volley 是Google开发的一个网络lib,可以让你更加简单并且快速的访问网络数据.Volley库的网络请求都是异步的,你不必担心异步处理问题. Volley的优点: 请求队列和 ...
- Smart210学习-----lcd驱动
帧缓冲设备 1.1帧缓冲设备:帧缓冲(framebuffer)是 Linux 系统为显示设备提供的一个接口,它将显示缓冲区抽象,屏蔽图像硬件的底层差异,允许上层应用程序在图形模式下直接对显示缓冲区进行 ...
- 转:Repeater嵌套绑定Repeater以及内层调用外层数据
<table border=" style="margin-bottom: 5px" width="100%"> <asp:Repe ...
- OpenFlow Switch学习笔记(四)——Matching
这次我们着重详述来自于网络中的数据包在OpenFlow Switch中与Flow Entries的具体匹配过程,以及当出现Table Miss时的处理方式,下面就将从这两方面说起. 1.Matchin ...