python基础set
1、set
set是一个无序的不重复的集合
li=[11,22,33,11]
s=set(li)
print(s)
{11,22,33}
set提供的方法
1、add(self, *args, **kwargs): 添加
li={11,22,33}
s=li.add(44)
print(li)
{11,22,33,44}
2、clear(self, *args, **kwargs): 清除内容
li={11,22,33,44}
s=li.clear()
print(li)
str()
3、difference(self, *args, **kwargs): 寻找不同 s=A.different(B) A中存在的B中不存在的元素赋值给s
li={11,22,33,44,11}
l2={22,44,55,11}
s=li.difference(l2)
print(s)
{33}
4、difference_update(self, *args, **kwargs): 把不同找到并更新原有的 s=A.difference_update(B) A中存在的B中不存在的元素找到并更新A
li={11,22,33,44}
l2={11,22,33,55}
li.different_upper(l2)
print(li)
{44}

5、discard(self, *args, **kwargs): 移除指定元素 不存在不报错
li={11,22,33,44}
s=li.discard(11)
print(li)
{22,33,44}
6、intersection(self, *args, **kwargs): 寻找相同 s=A.intersection(B) A、B中都存在的元素赋值给s
li={11,22,33,44}
l2={11,22,44}
s=li.intersection(l2)
print(s)
{11,22,44}
7、intersection_update(self, *args, **kwargs): 把相同的找到并更新原有的 s=A.intersection_update(B) AB中都存在的元素找到并更新A
li={11,22,33,44}
l2={11,22,44}
s=li.intersection_update(l2)
print(li)
{11,22,44}
8、isdisjoint(self, *args, **kwargs): 查看俩个集合有没有交集 如果有则返回False 没有返回True
li={11,22,33,44}
l2={00,77}
s=li.isdisjoint(l2)
print(s)
True
9、issubset(self, *args, **kwargs): 是否是子序列
li={11,22,33,44}
l2={00,77}
s=li.issubset(l2)
print(s)
False
10、 issuperset(self, *args, **kwargs): 是否是父序列
li={11,22,33,44}
l2={00,77}
s=li.issuperset(l2)
print(s)
False
11、pop(self, *args, **kwargs): 随机移除并赋值
li={11,22,33,44}
s=li.pop()
print(s)
{33}
12、remove(self, *args, **kwargs): 移除指定元素 不存在则报错
li={11,22,33,44}
s=li.remove(11)
print(li)
{22,33,44}
13、symmetric_difference(self, *args, **kwargs): s=A.symmetric_difference(B)把A中有B中无得元素和B中有A中无得元素放到s中
li={11,22,33,44}
l2={11,55,66,77}
s=li.symmetric_difference(l2)
print(s)
{33, 66, 44, 77, 22, 55}

14、symmetric_difference_update(self, *args, **kwargs): s=A.symmetric_difference_update(B)把A中有B中无得元素和B中有A中无得元素赋值给s
li={11,22,33,44}
l2={11,55,66,77}
s=li.symmetric_difference_update(l2)
print(li)
{22,33,44,55,66,77}
15、union(self, *args, **kwargs): 并集
li={11,22,33,44}
l2={11,55,66,77}
s=li.union(l2)
print(s)
{11,22,33,44,55,66,77}
16、update(self, *args, **kwargs): 更新 不会生成新的集合
li={11,22,33,44}
l2={11,55,66,77}
s=li.update(l2)
print(li)
{11,22,33,44,55,66,77}
练习题
# 数据库中原有
old_dict = {
"#1":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 },
"#2":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 }
"#3":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 }
} # cmdb 新汇报的数据
new_dict = {
"#1":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 800 },
"#3":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 }
"#4":{ 'hostname':c2, 'cpu_count': 2, 'mem_capicity': 80 }
}
m=set(old_dict.keys())
print(m)
n=set(new_dict.keys())
print(n)
需要添加的 a=n.different(m)
需要删除的 b=m.different(n)
需要更新的 c=m.intersection(n)
old_dict.update(a)
print(old_dict)
old_dict.pop(b)
print(old_dict)
6、三元运算(三目运算),是对简单的条件语句的缩写
书写格式: a= 值1 if 条件 else 值2 如果条件成立则把值1赋值给a 条件不成立把值2赋值给a
a="lu" if 1>2 else "xiao"
print(a)
xiao
7、深浅拷贝
字符串(str)一次性创建,不能被修改。只要修改则再创建生成新的
列表(list)链表 可以记录上及下的位置
数值和字符串
只要是赋值,拷贝(无论深浅)地址都一样
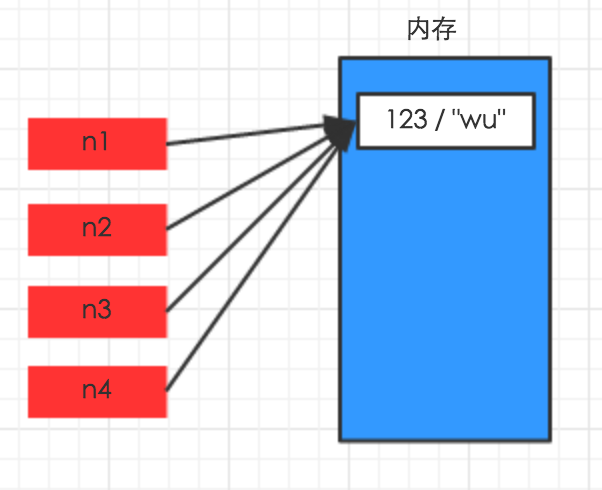
其他数据类型
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的
赋值,只是创建一个变量,该变量指向原来内存地址(对于赋值,其内存地址相同),如:
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n2 = n1
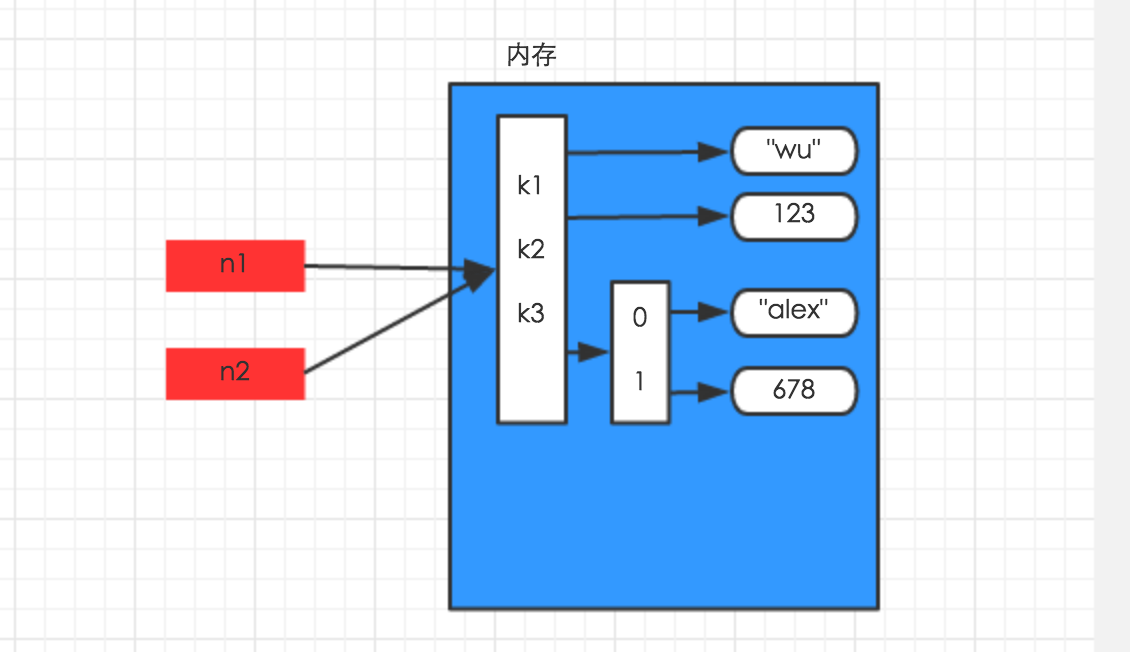
浅拷贝(只是拷贝了最外面的一层)
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n3 = copy.copy(n1)
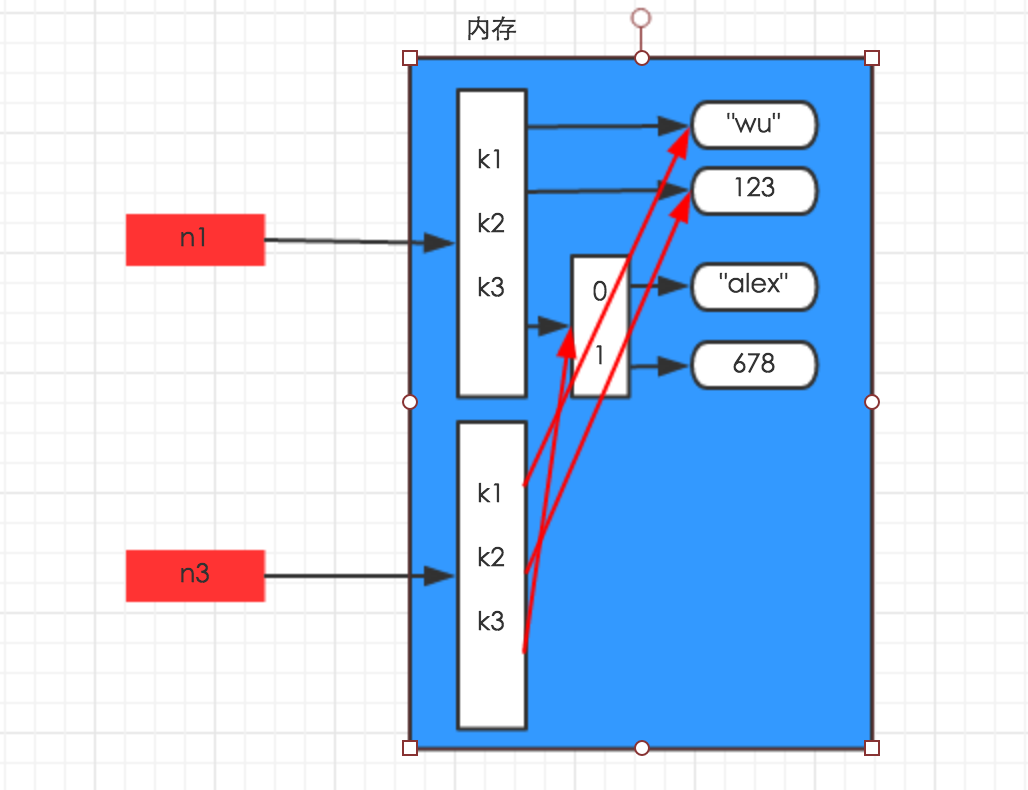
深拷贝在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)(拷贝全部,除了最底层)
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n3 = copy.copy(n1)

总结:
对一个对象进行浅拷贝其实是新创建了一个类型跟原对象一样,其内容是原来对象元素的引用,换句话说,这个拷贝的对象本身是新的,但是它的内容不是,如下:
1、进行浅拷贝,得到一个新对象,但是其内容还是原来的内容,
import copy a = [1,2,[3,4],5]
b = copy.copy(a)
print id(a)
print id(b)
print [id(i) for i in a]
print [id(i) for i in b] 38118216
38187528
[31947048L, 31947024L, 39364616L, 31946952L]
[31947048L, 31947024L, 39364616L, 31946952L]
2、浅拷贝只能做顶层复制,但是不能复制其嵌套的数据结构
import copy a = [1,2,[3,4],5]
b = copy.copy(a)
a[2][0] = 100
print a
print b [1, 2, [100, 4], 5]
[1, 2, [100, 4], 5]
8、函数
(函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可)
定义和使用:
def 函数名(参数):
...
函数体
...
返回值
特点
* def: 表示函数的关键字
* 函数名:根据函数名调用函数
* 参数: 为函数提供数据
* 函数体:函数中进行一系列的逻辑运算
* 返回值: 函数执行完毕后,可以给调用者返回一个值,遇到返回值时下面的程序不执行
参数(形式参数x和实际参数(具体的数))
#发送邮件实例
def email():
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr msg = MIMEText('邮件内容', 'plain', 'utf-8')
msg['From'] = formataddr(["武沛齐",'wptawy@126.com'])
msg['To'] = formataddr(["走人",'424662508@qq.com'])
msg['Subject'] = "主题" server = smtplib.SMTP("smtp.126.com", 25)
server.login("wptawy@126.com", "邮箱密码")
server.sendmail('wptawy@126.com', ['424662508@qq.com',], msg.as_string())
server.quit()
email()
传入参数的顺序
def name(k1,k2,k3,k4):
name(1,2,3,4) 形参,实参(默认,按照顺序) 一 一对应的关系 k1-1, k2-2, k3-3, k4-4
def name (k1, k2, k3, k4)
name(k1=2,k2=1,k3=4,k4=3) 指定形参传入实参,可以不按照顺序 也可以指定
默认参数
def a(p,name="卢晓军"): #假如函数中既有有默认值的参数,又有没有默认值的参数,一定要把没有默认值的参数放到前面
b=name + "开车去新疆"
return b
a()
print(a()) # a里面不传参数的话默认name="卢晓军"
卢晓军开车去新疆
动态参数(一)
def a(*b):
print(b)
a(11,22,33,)
(11,22,33) #传入*b直接把传入的转化为元祖
动态参数(二)
def a(**b):
print(b)
a(k1=123,k2=456)
{'k2': 456, 'k1': 123} #传入**b直接把传入的转化为字典
动态参数结合(一和二)
def a(p,*b,**c):
print(p)
print(b)
print(c)
a(11,22,33,k1=123,k2=456)
11
(22, 33)
{'k1': 123, 'k2': 456}
参数的一般写法: *args **kwargs
def a(*b):
print(b)
li=[11,22,33]
a(li)
([11, 22, 33],) #把li当成一个元素进行循环
列表
def a(*b):
print(b)
li=[11,22,33]
a(*li)
(11, 22, 33) # *li:循环li里面的每一个元素
字典
def a(*b):
print(b)
li={"k1":"v1","k2":"v2"}
a(li)
a(*li)
({'k1': 'v1', 'k2': 'v2'},)
('k1', 'k2')
字典(二)
def a(**b):
print(b)
li={"k1":"v1","k2":"v2"}
a(k1=li)
a(**li)
{'k1': {'k2': 'v2', 'k1': 'v1'}}
{'k2': 'v2', 'k1': 'v1'}
9、全局变量,局部变量(全局变量都大写,局部变量都小写)
a=456 #这里a是全局变量
def dict():
a=123 #这里的a是局部变量 下面的print(a)不能执行
print(a)
print(a)
dict()
修改全局变量用global +全局变量
a=123
def dict():
global a
a=456
dict()
def tim():
print(a)
tim()
456
练习题
1、简述普通参数、指定参数、默认参数、动态参数的区别
普通参数就是用户输入的元素按照顺序一一对应输入
指定参数就是用户可以指定某一元素传入某一参数中,可以不按顺序
默认参数就是提前给参数指定一个数值,如果用户没有输入数值。那么就默认指定的数值是参数
动态参数就是可以接收用户输入的多个元素,元祖,列表通常用*args表示,字典通常用*kwargs
2、写函数,计算传入字符串中【数字】、【字母】、【空格] 以及 【其他】的个数
def m(p):
a=0
b=0
c=0
for i in p:
if i.isdigit():
a=a+1
for i in p:
if i.isalpha():
b=b+1
for i in p:
if i.isspace():
c=c+1
d=len(p)-(a+b+c)
return a,b,c,d q=m(p)
print(q)
3、写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5。
def z(p):
if len(p)>5:
return True
else:
return False
a =z(p)
print(a)
4、写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空格。
def m(p):
for i in p:
if i.isspace():
return True
else:
return False
z=m(p)
print(z)
5、写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
def z(p):
if len(p)>2:
s=p[0:2]
return s
else:
return False
m=z(p)
print(m)
6、写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。
def z(p):
d=[]
for i in range(len(p)):
if i%2==1:
d.append(p[i])
return d
m=z(p)
print(m)
7、写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者
def z(p):
for i in p.values():
if len(i)>2:
m=i[0:2]
return m
c=z(p)
print(c)
python基础set的更多相关文章
- python之最强王者(2)——python基础语法
背景介绍:由于本人一直做java开发,也是从txt开始写hello,world,使用javac命令编译,一直到使用myeclipse,其中的道理和辛酸都懂(请容许我擦干眼角的泪水),所以对于pytho ...
- Python开发【第二篇】:Python基础知识
Python基础知识 一.初识基本数据类型 类型: int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位 ...
- Python小白的发展之路之Python基础(一)
Python基础部分1: 1.Python简介 2.Python 2 or 3,两者的主要区别 3.Python解释器 4.安装Python 5.第一个Python程序 Hello World 6.P ...
- Python之路3【第一篇】Python基础
本节内容 Python简介 Python安装 第一个Python程序 编程语言的分类 Python简介 1.Python的由来 python的创始人为吉多·范罗苏姆(Guido van Rossum) ...
- 进击的Python【第三章】:Python基础(三)
Python基础(三) 本章内容 集合的概念与操作 文件的操作 函数的特点与用法 参数与局部变量 return返回值的概念 递归的基本含义 函数式编程介绍 高阶函数的概念 一.集合的概念与操作 集合( ...
- 进击的Python【第二章】:Python基础(二)
Python基础(二) 本章内容 数据类型 数据运算 列表与元组的基本操作 字典的基本操作 字符编码与转码 模块初探 练习:购物车程序 一.数据类型 Python有五个标准的数据类型: Numbers ...
- Python之路【第一篇】python基础
一.python开发 1.开发: 1)高级语言:python .Java .PHP. C# Go ruby c++ ===>字节码 2)低级语言:c .汇编 2.语言之间的对比: 1)py ...
- python基础之day1
Python 简介 Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言. Python为我们提供了非常完善的基础代码库,覆盖了 ...
- python基础之文件读写
python基础之文件读写 本节内容 os模块中文件以及目录的一些方法 文件的操作 目录的操作 1.os模块中文件以及目录的一些方法 python操作文件以及目录可以使用os模块的一些方法如下: 得到 ...
- python基础之编码问题
python基础之编码问题 本节内容 字符串编码问题由来 字符串编码解决方案 1.字符串编码问题由来 由于字符串编码是从ascii--->unicode--->utf-8(utf-16和u ...
随机推荐
- zend studio 12汉化和破解
首先提供一个 zend studio 12汉化的百度连接地址(我的网盘里有) http://pan.baidu.com/s/1dD5x1cd 下载后解压 安装方法 Help–> Install ...
- 无法找到类:java.lang.ClassNotFoundException: com.tt.javaweb.HttpServletRequest问题解决
问题如下:找不到Httpservlet对应的Class,进入build目录下发现确实没有对应的class文件. 严重: Allocate exception for HttpServletReques ...
- (四)java程序基本组成
一个基本的java程序一般包括几个部分,分别是程序所在的包名.程序中用到的其他包的路径.程序的类.类中的方法.变量和字面量. package demo; import java.util.Date; ...
- GR&R
ANOVA gauge R&R (or ANOVA gauge repeatability and reproducibility) is a measurement systems anal ...
- SecureCRT控制台显示中文字符的设置
- hdu 3068 最长回文 manacher算法(视频)
感悟: 首先我要Orz一下qsc,我在网上很难找到关于acm的教学视频,但偶然发现了这个,感觉做的很好,链接:戳戳戳 感觉这种花费自己时间去教别人的人真的很伟大. manacher算法把所有的回文都变 ...
- hdu 5438 Ponds dfs
Time Limit: 1500/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others) Problem Descr ...
- Java爬虫搜索原理实现
permike 原文 Java爬虫搜索原理实现 没事做,又研究了一下爬虫搜索,两三天时间总算是把原理闹的差不多了,基本实现了爬虫搜索的原理,本次实现还是俩程序,分别是按广度优先和深度优先完成的,广度优 ...
- windows service的作成
http://jingyan.baidu.com/article/fa4125acb71a8628ac709226.html
- 对 HTTP 304 的理解(转-并增加自己的测试)
作者:吴俊杰 性别:男 邮箱:sshroot@126.com 文章类型:原创 博客:http://www.cnblogs.com/voiphudong/ 转自: http://www.cnblogs. ...