Linux内核同步机制
http://blog.csdn.net/bullbat/article/details/7376424
Linux内核同步控制方法有很多,信号量、锁、原子量、RCU等等,不同的实现方法应用于不同的环境来提高操作系统效率。首先,看看我们最熟悉的两种机制——信号量、锁。
一、信号量
首先还是看看内核中是怎么实现的,内核中用struct semaphore数据结构表示信号量(<linux/semphone.h>中):
- struct semaphore {
- spinlock_t lock;
- unsigned int count;
- struct list_head wait_list;
- };
其中lock为自旋锁,放到这里是为了保护count的原子增减,无符号数count为我们竞争的信号量(PV操作的核心),wait_list为等待此信号量的进程链表。
初始化:
对于这一类工具类使用较多的机制,包括用于同步互斥的信号量、锁、completion,用于进程等待的等待队列、用于Per-CPU的变量等等,内核都提供了两种初始化方法,静态与动态方式。
1) 静态初始化,实现代码如下:
- #define __SEMAPHORE_INITIALIZER(name, n) \
- { \
- .lock = __SPIN_LOCK_UNLOCKED((name).lock), \
- .count = n, \
- .wait_list = LIST_HEAD_INIT((name).wait_list), \
- }
- #define DECLARE_MUTEX(name) \
- struct semaphore name = __SEMAPHORE_INITIALIZER(name, 1)
可以看到,这种初始化使我们在编程的时候直接用一条语句DECLARE_MUTEX(name);就可以完成申明与初始化,另一种下面要说的动态初始化方式申请与初始化分离。
2) 我们看到,静态初始化时信号量的count值初始化为1,当我们需要初始化为0时需要用动态初始化方法。
- #define init_MUTEX(sem) sema_init(sem, 1)
- #define init_MUTEX_LOCKED(sem) sema_init(sem, 0)
- static inline void sema_init(struct semaphore *sem, int val)
- {
- static struct lock_class_key __key;
- *sem = (struct semaphore) __SEMAPHORE_INITIALIZER(*sem, val);
- lockdep_init_map(&sem->lock.dep_map, "semaphore->lock", &__key, 0);
- }
操作:
获取信号量
- /*获取信号量*/
- void down(struct semaphore *sem)
- {
- unsigned long flags;
- spin_lock_irqsave(&sem->lock, flags);
- if (likely(sem->count > 0))
- sem->count--;
- else
- __down(sem);
- spin_unlock_irqrestore(&sem->lock, flags);
- }
__down(sem)最终由下面函数实现
- static inline int __sched __down_common(struct semaphore *sem, long state,
- long timeout)
- {
- struct task_struct *task = current;
- struct semaphore_waiter waiter;
- list_add_tail(&waiter.list, &sem->wait_list);
- waiter.task = task;
- waiter.up = 0;
- for (;;) {
- if (signal_pending_state(state, task))
- goto interrupted;
- if (timeout <= 0)
- goto timed_out;
- __set_task_state(task, state);
- spin_unlock_irq(&sem->lock);
- timeout = schedule_timeout(timeout);
- spin_lock_irq(&sem->lock);
- if (waiter.up)
- return 0;
- }
- timed_out:
- list_del(&waiter.list);
- return -ETIME;
- interrupted:
- list_del(&waiter.list);
- return -EINTR;
- }
释放信号量
- void up(struct semaphore *sem)
- {
- unsigned long flags;
- spin_lock_irqsave(&sem->lock, flags);
- if (likely(list_empty(&sem->wait_list)))
- sem->count++;
- else
- __up(sem);
- spin_unlock_irqrestore(&sem->lock, flags);
- }
- static noinline void __sched __up(struct semaphore *sem)
- {
- struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
- struct semaphore_waiter, list);
- list_del(&waiter->list);
- waiter->up = 1;
- wake_up_process(waiter->task);
- }
从上面代码可以看出,信号量的获取和释放很简单,不外乎修改count值、加入或移除等待队列元素,其中count值的修改需要自旋锁的支持。还有几个down和up类函数,实现类似,使用时可以看看源码不同之处。
运用:
用信号量我们实现两个线程的同步,我们用kernel_thread创建两个线程,对变量num的值进行同步访问,代码如下,文件为semaphore.c
- #include <linux/init.h>
- #include <linux/kernel.h>
- #include <linux/module.h>
- #include <linux/sched.h>
- #include <linux/semaphore.h>
- #define N 15
- MODULE_LICENSE("GPL");
- static unsigned count=0,num=0;
- struct semaphore sem_2;
- DECLARE_MUTEX(sem_1);/*init 1*/
- int ThreadFunc1(void *context)
- {
- char *tmp=(char*)context;
- while(num<N){
- down(&sem_1);
- printk("<2>" "%s\tcount:%d\n",tmp,count++);
- num++;
- up(&sem_2);
- }
- return 0;
- }
- int ThreadFunc2(void *context)
- {
- char *tmp=(char*)context;
- while(num<N){
- down(&sem_2);
- printk("<2>" "%s\tcount:%d\n",tmp,count--);
- num++;
- up(&sem_1);
- }
- return 0;
- }
- static __init int semaphore_init(void)
- {
- char *ch1="this is first thread!";
- char *ch2="this is second thread!";
- init_MUTEX_LOCKED(&sem_2);/*init 0*/
- kernel_thread(ThreadFunc1,ch1,CLONE_KERNEL);
- kernel_thread(ThreadFunc2,ch2,CLONE_KERNEL);
- return 0;
- }
- static void semaphore_exit(void)
- {
- }
- module_init(semaphore_init);
- module_exit(semaphore_exit);
- MODULE_AUTHOR("Mike Feng");
实现结果如下。
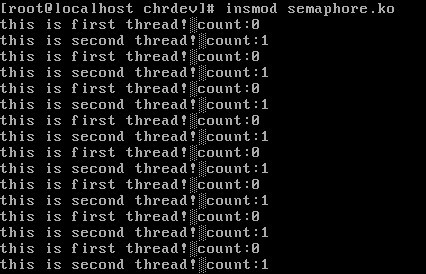
可以看到线程1和线程2交替运行,实现了同步。
读、写信号量:
类似操作系统中学习的读者、写者问题,内核中,许多任务可以划分为两种不同的工作类型:一些任务只需要读取受保护的数据结构,而其他的则必须做出修改。循序多个并发的读者是可能的,只要他们之中没有哪个要做出修改。Linux内核为这种情形提供了一种特殊的信号量类型——读、写信号量。struct rw_semaphore作为其数据结构,初始化和信号量类似,down_read、up_read等类函数实现信号量控制,这些函数实现比较复杂,用到了读写锁(将在后面分析),有兴趣可以看看,。我们运用读、写信号实现哪个古老的读者、写者同步问题:
文件down_read.c
- #include <linux/init.h>
- #include <linux/module.h>
- #include <linux/kernel.h>
- #include <linux/sched.h>
- #include <linux/rwsem.h>
- #include <linux/semaphore.h>
- MODULE_LICENSE("GPL");
- static int count=0,num=0,readcount=0,writer=0;
- struct rw_semaphore rw_write;
- struct rw_semaphore rw_read;
- struct semaphore sm_1;
- int ThreadRead(void *context)
- {
- down_read(&rw_write);
- down(&sm_1);
- count++;
- readcount++;
- up(&sm_1);
- printk("<2>" "Read Thread %d\tcount:%d\n",readcount,count);
- msleep(10);
- printk("<2>" "Read Thread Over!\n",readcount);
- up_read(&rw_write);
- return 0;
- }
- int ThreadWrite(void *context)
- {
- down_write(&rw_write);
- writer++;
- printk("<2>" "Write Thread %d\tcount:%d\n",writer,--count);
- msleep(10);
- printk("<2>" "Write Thread %d Over!\n",writer);
- up_write(&rw_write);
- return count;
- }
- static __init int rwsem_init(void)
- {
- static int i,iread=0,iwrite=0;
- init_rwsem(&rw_read);
- init_rwsem(&rw_write);
- init_MUTEX(&sm_1);
- for(i=0;i<2;i++){
- kernel_thread(ThreadWrite,&i,CLONE_KERNEL);
- iwrite++;
- }
- for(i=0;i<2;i++){
- kernel_thread(ThreadRead,&i,CLONE_KERNEL);
- iread++;
- }
- for(i=2;i<5;i++){
- kernel_thread(ThreadRead,&i,CLONE_KERNEL);
- iread++;
- }
- for(i=2;i<5;i++){
- kernel_thread(ThreadWrite,&i,CLONE_KERNEL);
- iwrite++;
- }
- return 0;
- }
- static void rwsem_exit(void)
- {
- }
- module_init(rwsem_init);
- module_exit(rwsem_exit);
- MODULE_AUTHOR("Mike Feng");
实验结果:
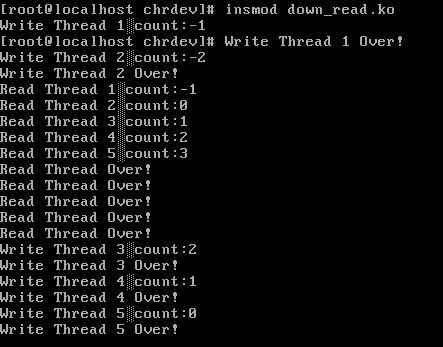
从代码上看,实现起来很简单。
二、自旋锁
读写信号量基于自旋锁实现。内核中为如下结构:
- typedef struct {
- raw_spinlock_t raw_lock;
- #ifdef CONFIG_GENERIC_LOCKBREAK
- unsigned int break_lock;
- #endif
- #ifdef CONFIG_DEBUG_SPINLOCK
- unsigned int magic, owner_cpu;
- void *owner;
- #endif
- #ifdef CONFIG_DEBUG_LOCK_ALLOC
- struct lockdep_map dep_map;
- #endif
- } spinlock_t;
其中raw_lock为实现的原子量控制。下面我们就信号量和自旋锁实现我们上面用读写信号量实现的读者、写者问题:spinlock.c文件
- #include <linux/init.h>
- #include <linux/module.h>
- #include <linux/kernel.h>
- #include <linux/sched.h>
- #include <linux/semaphore.h>
- #include <linux/spinlock.h>
- MODULE_LICENSE("GPL");
- static int count=0,num=0,readcount=0,writer=0,writecount=0;
- struct semaphore sem_w,sem_r;
- spinlock_t lock1=SPIN_LOCK_UNLOCKED;
- int ThreadRead(void *context)
- {
- down(&sem_r);
- spin_lock(&lock1);
- readcount++;
- if(readcount==1)
- down(&sem_w);
- spin_unlock(&lock1);
- up(&sem_r);
- printk("<2>" "Reader %d is reading!\n",readcount);
- msleep(10);
- printk("<2>" "Reader is over!\n");
- spin_lock(&lock1);
- readcount--;
- if(readcount==0)
- up(&sem_w);
- spin_unlock(&lock1);
- return count;
- }
- int ThreadWrite(void *context)
- {
- spin_lock(&lock1);
- writecount++;
- if(writecount==1)
- down(&sem_r);
- spin_unlock(&lock1);
- down(&sem_w);
- writer++;
- printk("<2>" "Writer %d is writting!\n",writer);
- msleep(10);
- printk("<2>" "Writer %d is over!\n",writer);
- up(&sem_w);
- spin_lock(&lock1);
- writecount--;
- if(writecount==0)
- up(&sem_r);
- spin_unlock(&lock1);
- return count;
- }
- static __init int rwsem_init(void)
- {
- static int i;
- init_MUTEX(&sem_r);
- init_MUTEX(&sem_w);
- for(i=0;i<2;i++){
- kernel_thread(ThreadWrite,&i,CLONE_VM);
- }
- for(i=0;i<2;i++){
- kernel_thread(ThreadRead,&i,CLONE_KERNEL);
- }
- for(i=2;i<5;i++){
- kernel_thread(ThreadRead,&i,CLONE_KERNEL);
- }
- for(i=2;i<5;i++){
- kernel_thread(ThreadWrite,&i,CLONE_KERNEL);
- }
- return 0;
- }
- static void rwsem_exit(void)
- {
- }
- module_init(rwsem_init);
- module_exit(rwsem_exit);
- MODULE_AUTHOR("Mike Feng");
运行结果:

从结果上看,和我们上面的结果略有差别,因为我们这里实现的是写者优先算法。
读写锁:
读写信号量的实现是基于读写锁的。可以想到他们的应用都差不多。自旋锁、读写锁中不能有睡眠,我们就不做实验验证了,当你在锁之间添加msleep函数时,会造成系统崩溃。
顺序锁:
顺序锁和读写锁非常相似,只是他为写者赋予了较高的优先级:事实上,即使在读者正在读的时候也允许写者继续运行。这种策略的好处是写者永远不会等待(除非另外一个写者正在写),缺点是有些时候读者不得不反复读相同数据直到他获得有效的副本。
最后,为完整起见,附上代码的Makefile文件:
- obj-m+=semaphore.o down_read.o spinlock.o
- CURRENT:=$(shell pwd)
- KERNEL_PATH:=/usr/src/kernels/$(shell uname -r)
- all:
- make -C $(KERNEL_PATH) M=$(CURRENT) modules
- clean:
- make -C $(KERNEL_PATH) M=$(CURRENT) clean
Linux内核同步机制之completion
http://blog.csdn.net/bullbat/article/details/7401688
内核编程中常见的一种模式是,在当前线程之外初始化某个活动,然后等待该活动的结束。这个活动可能是,创建一个新的内核线程或者新的用户空间进程、对一个已有进程的某个请求,或者某种类型的硬件动作,等等。在这种情况下,我们可以使用信号量来同步这两个任务。然而,内核中提供了另外一种机制——completion接口。Completion是一种轻量级的机制,他允许一个线程告诉另一个线程某个工作已经完成。
结构与初始化
Completion在内核中的实现基于等待队列(关于等待队列理论知识在前面的文章中有介绍),completion结构很简单:
- struct completion {
- unsigned int done;/*用于同步的原子量*/
- wait_queue_head_t wait;/*等待事件队列*/
- };
和信号量一样,初始化分为静态初始化和动态初始化两种情况:
静态初始化:
- #define COMPLETION_INITIALIZER(work) \
- { 0, __WAIT_QUEUE_HEAD_INITIALIZER((work).wait) }
- #define DECLARE_COMPLETION(work) \
- struct completion work = COMPLETION_INITIALIZER(work)
动态初始化:
- static inline void init_completion(struct completion *x)
- {
- x->done = 0;
- init_waitqueue_head(&x->wait);
- }
可见,两种初始化都将用于同步的done原子量置位了0,后面我们会看到,该变量在wait相关函数中减一,在complete系列函数中加一。
实现
同步函数一般都成对出现,completion也不例外,我们看看最基本的两个complete和wait_for_completion函数的实现。
wait_for_completion最终由下面函数实现:
- static inline long __sched
- do_wait_for_common(struct completion *x, long timeout, int state)
- {
- if (!x->done) {
- DECLARE_WAITQUEUE(wait, current);
- wait.flags |= WQ_FLAG_EXCLUSIVE;
- __add_wait_queue_tail(&x->wait, &wait);
- do {
- if (signal_pending_state(state, current)) {
- timeout = -ERESTARTSYS;
- break;
- }
- __set_current_state(state);
- spin_unlock_irq(&x->wait.lock);
- timeout = schedule_timeout(timeout);
- spin_lock_irq(&x->wait.lock);
- } while (!x->done && timeout);
- __remove_wait_queue(&x->wait, &wait);
- if (!x->done)
- return timeout;
- }
- x->done--;
- return timeout ?: 1;
- }
而complete实现如下:
- void complete(struct completion *x)
- {
- unsigned long flags;
- spin_lock_irqsave(&x->wait.lock, flags);
- x->done++;
- __wake_up_common(&x->wait, TASK_NORMAL, 1, 0, NULL);
- spin_unlock_irqrestore(&x->wait.lock, flags);
- }
不看内核实现的源代码我们也能想到他的实现,不外乎在wait函数中循环等待done变为可用(正),而另一边的complete函数为唤醒函数,当然是将done加一,唤醒待处理的函数。是的,从上面的代码看到,和我们想的一样。内核也是这样做的。
运用
运用LDD3中的例子:
- #include <linux/module.h>
- #include <linux/init.h>
- #include <linux/sched.h>
- #include <linux/kernel.h>
- #include <linux/fs.h>
- #include <linux/types.h>
- #include <linux/completion.h>
- MODULE_LICENSE("GPL");
- static int complete_major=250;
- DECLARE_COMPLETION(comp);
- ssize_t complete_read(struct file *filp,char __user *buf,size_t count,loff_t *pos)
- {
- printk(KERN_ERR "process %i (%s) going to sleep\n",current->pid,current->comm);
- wait_for_completion(&comp);
- printk(KERN_ERR "awoken %i (%s)\n",current->pid,current->comm);
- return 0;
- }
- ssize_t complete_write(struct file *filp,const char __user *buf,size_t count,loff_t *pos)
- {
- printk(KERN_ERR "process %i (%s) awakening the readers...\n",current->pid,current->comm);
- complete(&comp);
- return count;
- }
- struct file_operations complete_fops={
- .owner=THIS_MODULE,
- .read=complete_read,
- .write=complete_write,
- };
- int complete_init(void)
- {
- int result;
- result=register_chrdev(complete_major,"complete",&complete_fops);
- if(result<0)
- return result;
- if(complete_major==0)
- complete_major=result;
- return 0;
- }
- void complete_cleanup(void)
- {
- unregister_chrdev(complete_major,"complete");
- }
- module_init(complete_init);
- module_exit(complete_cleanup);
测试步骤:
1, mknod /dev/complete创建complete节点,在linux上驱动程序需要手动创建文件节点。
2, insmod complete.ko 插入驱动模块,这里要注意的是,因为我们的代码中是手动分配的设备号,很可能被系统已经使用了,所以如果出现这种情况,查看/proc/devices文件。找一个没有被使用的设备号。
3, cat /dev/complete 用于读该设备,调用设备的读函数
4, 打开另一个终端输入 echo “hello” > /dev/complete 该命令用于写入该设备
Linux内核的同步机制
http://soft.yesky.com/os/lin/10/2303010all.shtml#p2303010
本文详细的介绍了Linux内核中的同步机制:原子操作、信号量、读写信号量和自旋锁的API,使用要求以及一些典型示例
一、引言
在现代操作系统里,同一时间可能有多个内核执行流在执行,因此内核其实象多进程多线程编程一样也需要一些同步机制来同步各执行单元对共享数据的访问。尤其是在多处理器系统上,更需要一些同步机制来同步不同处理器上的执行单元对共享的数据的访问。
在主流的Linux内核中包含了几乎所有现代的操作系统具有的同步机制,这些同步机制包括:原子操作、信号量(semaphore)、读写信号量(rw_semaphore)、spinlock、BKL(Big Kernel Lock)、rwlock、brlock(只包含在2.4内核中)、RCU(只包含在2.6内核中)和seqlock(只包含在2.6内核中)。
本文详细的介绍了Linux内核中的同步机制:原子操作、信号量、读写信号量和自旋锁的API,使用要求以及一些典型示例
一、引言
在现代操作系统里,同一时间可能有多个内核执行流在执行,因此内核其实象多进程多线程编程一样也需要一些同步机制来同步各执行单元对共享数据的访问。尤其是在多处理器系统上,更需要一些同步机制来同步不同处理器上的执行单元对共享的数据的访问。
在主流的Linux内核中包含了几乎所有现代的操作系统具有的同步机制,这些同步机制包括:原子操作、信号量(semaphore)、读写信号量(rw_semaphore)、spinlock、BKL(Big Kernel Lock)、rwlock、brlock(只包含在2.4内核中)、RCU(只包含在2.6内核中)和seqlock(只包含在2.6内核中)。
二、原子操作
所谓原子操作,就是该操作绝不会在执行完毕前被任何其他任务或事件打断,也就说,它的最小的执行单位,不可能有比它更小的执行单位,因此这里的原子实际是使用了物理学里的物质微粒的概念。
原子操作需要硬件的支持,因此是架构相关的,其API和原子类型的定义都定义在内核源码树的include/asm/atomic.h文件中,它们都使用汇编语言实现,因为C语言并不能实现这样的操作。
原子操作主要用于实现资源计数,很多引用计数(refcnt)就是通过原子操作实现的。原子类型定义如下:
<ccid_nobr>
<ccid_code>typedef struct |
volatile修饰字段告诉gcc不要对该类型的数据做优化处理,对它的访问都是对内存的访问,而不是对寄存器的访问。
原子操作API包括:
<ccid_nobr>
<ccid_code>atomic_read(atomic_t * v); |
该函数对原子类型的变量进行原子读操作,它返回原子类型的变量v的值。
<ccid_nobr>
<ccid_code>atomic_set(atomic_t * v, int i); |
该函数设置原子类型的变量v的值为i。
<ccid_nobr>
<ccid_code>void atomic_add(int i, atomic_t *v); |
该函数给原子类型的变量v增加值i。
<ccid_nobr>
<ccid_code>atomic_sub(int i, atomic_t *v); |
该函数从原子类型的变量v中减去i。
<ccid_nobr>
<ccid_code>int atomic_sub_and_test(int i, atomic_t *v); |
该函数从原子类型的变量v中减去i,并判断结果是否为0,如果为0,返回真,否则返回假。
<ccid_nobr>
<ccid_code>void atomic_inc(atomic_t *v); |
该函数对原子类型变量v原子地增加1。
<ccid_nobr>
<ccid_code>void atomic_dec(atomic_t *v); |
该函数对原子类型的变量v原子地减1。
<ccid_nobr>
<ccid_code>int atomic_dec_and_test(atomic_t *v); |
该函数对原子类型的变量v原子地减1,并判断结果是否为0,如果为0,返回真,否则返回假。
<ccid_nobr>
<ccid_code>int atomic_inc_and_test(atomic_t *v); |
该函数对原子类型的变量v原子地增加1,并判断结果是否为0,如果为0,返回真,否则返回假。
<ccid_nobr>
<ccid_code>int atomic_add_negative(int i, atomic_t *v); |
该函数对原子类型的变量v原子地增加I,并判断结果是否为负数,如果是,返回真,否则返回假。
<ccid_nobr>
<ccid_code>int atomic_add_return(int i, atomic_t *v); |
该函数对原子类型的变量v原子地增加i,并且返回指向v的指针。
<ccid_nobr>
<ccid_code>int atomic_sub_return(int i, atomic_t *v); |
该函数从原子类型的变量v中减去i,并且返回指向v的指针。
<ccid_nobr>
<ccid_code>int atomic_inc_return(atomic_t * v); |
该函数对原子类型的变量v原子地增加1并且返回指向v的指针。
<ccid_nobr>
<ccid_code>int atomic_dec_return(atomic_t * v); |
该函数对原子类型的变量v原子地减1并且返回指向v的指针。
原子操作通常用于实现资源的引用计数,在TCP/IP协议栈的IP碎片处理中,就使用了引用计数,碎片队列结构struct ipq描述了一个IP碎片,字段refcnt就是引用计数器,它的类型为atomic_t,当创建IP碎片时(在函数ip_frag_create中),使用atomic_set函数把它设置为1,当引用该IP碎片时,就使用函数atomic_inc把引用计数加1。
当不需要引用该IP碎片时,就使用函数ipq_put来释放该IP碎片,ipq_put使用函数atomic_dec_and_test把引用计数减1并判断引用计数是否为0,如果是就释放IP碎片。函数ipq_kill把IP碎片从ipq队列中删除,并把该删除的IP碎片的引用计数减1(通过使用函数atomic_dec实现)。
三、信号量(semaphore)
Linux内核的信号量在概念和原理上与用户态的System V的IPC机制信号量是一样的,但是它绝不可能在内核之外使用,因此它与System V的IPC机制信号量毫不相干。
信号量在创建时需要设置一个初始值,表示同时可以有几个任务可以访问该信号量保护的共享资源,初始值为1就变成互斥锁(Mutex),即同时只能有一个任务可以访问信号量保护的共享资源。
一个任务要想访问共享资源,首先必须得到信号量,获取信号量的操作将把信号量的值减1,若当前信号量的值为负数,表明无法获得信号量,该任务必须挂起在该信号量的等待队列等待该信号量可用;若当前信号量的值为非负数,表示可以获得信号量,因而可以立刻访问被该信号量保护的共享资源。
当任务访问完被信号量保护的共享资源后,必须释放信号量,释放信号量通过把信号量的值加1实现,如果信号量的值为非正数,表明有任务等待当前信号量,因此它也唤醒所有等待该信号量的任务。
信号量的API有:
<ccid_nobr>
<ccid_code>DECLARE_MUTEX(name) |
该宏声明一个信号量name并初始化它的值为0,即声明一个互斥锁。
<ccid_nobr>
<ccid_code>DECLARE_MUTEX_LOCKED(name) |
该宏声明一个互斥锁name,但把它的初始值设置为0,即锁在创建时就处在已锁状态。因此对于这种锁,一般是先释放后获得。
<ccid_nobr>
<ccid_code>void sema_init (struct semaphore *sem, int val); |
该函用于数初始化设置信号量的初值,它设置信号量sem的值为val。
<ccid_nobr>
<ccid_code>void init_MUTEX (struct semaphore *sem); |
该函数用于初始化一个互斥锁,即它把信号量sem的值设置为1。
<ccid_nobr>
<ccid_code>void init_MUTEX_LOCKED (struct semaphore *sem); |
该函数也用于初始化一个互斥锁,但它把信号量sem的值设置为0,即一开始就处在已锁状态。
<ccid_nobr>
<ccid_code>void down(struct semaphore * sem); |
该函数用于获得信号量sem,它会导致睡眠,因此不能在中断上下文(包括IRQ上下文和softirq上下文)使用该函数。该函数将把sem的值减1,如果信号量sem的值非负,就直接返回,否则调用者将被挂起,直到别的任务释放该信号量才能继续运行。
<ccid_nobr>
<ccid_code>int down_interruptible(struct semaphore * sem); |
该函数功能与down类似,不同之处为,down不会被信号(signal)打断,但down_interruptible能被信号打断,因此该函数有返回值来区分是正常返回还是被信号中断,如果返回0,表示获得信号量正常返回,如果被信号打断,返回-EINTR。
<ccid_nobr>
<ccid_code>int down_trylock(struct semaphore * sem); |
该函数试着获得信号量sem,如果能够立刻获得,它就获得该信号量并返回0,否则,表示不能获得信号量sem,返回值为非0值。因此,它不会导致调用者睡眠,可以在中断上下文使用。
<ccid_nobr>
<ccid_code>void up(struct semaphore * sem); |
该函数释放信号量sem,即把sem的值加1,如果sem的值为非正数,表明有任务等待该信号量,因此唤醒这些等待者。
信号量在绝大部分情况下作为互斥锁使用,下面以console驱动系统为例说明信号量的使用。
在内核源码树的kernel/printk.c中,使用宏DECLARE_MUTEX声明了一个互斥锁console_sem,它用于保护console驱动列表console_drivers以及同步对整个console驱动系统的访问。
其中定义了函数acquire_console_sem来获得互斥锁console_sem,定义了release_console_sem来释放互斥锁console_sem,定义了函数try_acquire_console_sem来尽力得到互斥锁console_sem。这三个函数实际上是分别对函数down,up和down_trylock的简单包装。
需要访问console_drivers驱动列表时就需要使用acquire_console_sem来保护console_drivers列表,当访问完该列表后,就调用release_console_sem释放信号量console_sem。
函数console_unblank,console_device,console_stop,console_start,register_console和unregister_console都需要访问console_drivers,因此它们都使用函数对acquire_console_sem和release_console_sem来对console_drivers进行保护。
四、读写信号量(rw_semaphore)
读写信号量对访问者进行了细分,或者为读者,或者为写者,读者在保持读写信号量期间只能对该读写信号量保护的共享资源进行读访问,如果一个任务除了需要读,可能还需要写,那么它必须被归类为写者,它在对共享资源访问之前必须先获得写者身份,写者在发现自己不需要写访问的情况下可以降级为读者。读写信号量同时拥有的读者数不受限制,也就说可以有任意多个读者同时拥有一个读写信号量。
如果一个读写信号量当前没有被写者拥有并且也没有写者等待读者释放信号量,那么任何读者都可以成功获得该读写信号量;否则,读者必须被挂起直到写者释放该信号量。如果一个读写信号量当前没有被读者或写者拥有并且也没有写者等待该信号量,那么一个写者可以成功获得该读写信号量,否则写者将被挂起,直到没有任何访问者。因此,写者是排他性的,独占性的。
读写信号量有两种实现,一种是通用的,不依赖于硬件架构,因此,增加新的架构不需要重新实现它,但缺点是性能低,获得和释放读写信号量的开销大;另一种是架构相关的,因此性能高,获取和释放读写信号量的开销小,但增加新的架构需要重新实现。在内核配置时,可以通过选项去控制使用哪一种实现。
读写信号量的相关API有:
<ccid_nobr>
<ccid_code>DECLARE_RWSEM(name) |
该宏声明一个读写信号量name并对其进行初始化。
<ccid_nobr>
<ccid_code>void init_rwsem(struct rw_semaphore *sem); |
该函数对读写信号量sem进行初始化。
<ccid_nobr>
<ccid_code>void down_read(struct rw_semaphore *sem); |
读者调用该函数来得到读写信号量sem。该函数会导致调用者睡眠,因此只能在进程上下文使用。
<ccid_nobr>
<ccid_code>int down_read_trylock(struct rw_semaphore *sem); |
该函数类似于down_read,只是它不会导致调用者睡眠。它尽力得到读写信号量sem,如果能够立即得到,它就得到该读写信号量,并且返回1,否则表示不能立刻得到该信号量,返回0。因此,它也可以在中断上下文使用。
<ccid_nobr>
<ccid_code>void down_write(struct rw_semaphore *sem); |
写者使用该函数来得到读写信号量sem,它也会导致调用者睡眠,因此只能在进程上下文使用。
<ccid_nobr>
<ccid_code>int down_write_trylock(struct rw_semaphore *sem); |
该函数类似于down_write,只是它不会导致调用者睡眠。该函数尽力得到读写信号量,如果能够立刻获得,就获得该读写信号量并且返回1,否则表示无法立刻获得,返回0。它可以在中断上下文使用。
<ccid_nobr>
<ccid_code>void up_read(struct rw_semaphore *sem); |
读者使用该函数释放读写信号量sem。它与down_read或down_read_trylock配对使用。如果down_read_trylock返回0,不需要调用up_read来释放读写信号量,因为根本就没有获得信号量。
<ccid_nobr>
<ccid_code>void up_write(struct rw_semaphore *sem); |
写者调用该函数释放信号量sem。它与down_write或down_write_trylock配对使用。如果down_write_trylock返回0,不需要调用up_write,因为返回0表示没有获得该读写信号量。
<ccid_nobr>
<ccid_code>void downgrade_write(struct rw_semaphore *sem); |
该函数用于把写者降级为读者,这有时是必要的。因为写者是排他性的,因此在写者保持读写信号量期间,任何读者或写者都将无法访问该读写信号量保护的共享资源,对于那些当前条件下不需要写访问的写者,降级为读者将,使得等待访问的读者能够立刻访问,从而增加了并发性,提高了效率。
读写信号量适于在读多写少的情况下使用,在linux内核中对进程的内存映像描述结构的访问就使用了读写信号量进行保护。
在Linux中,每一个进程都用一个类型为task_t或struct task_struct的结构来描述,该结构的类型为struct mm_struct的字段mm描述了进程的内存映像,特别是mm_struct结构的mmap字段维护了整个进程的内存块列表,该列表将在进程生存期间被大量地遍利或修改。
因此mm_struct结构就有一个字段mmap_sem来对mmap的访问进行保护,mmap_sem就是一个读写信号量,在proc文件系统里有很多进程内存使用情况的接口,通过它们能够查看某一进程的内存使用情况,命令free、ps和top都是通过proc来得到内存使用信息的,proc接口就使用down_read和up_read来读取进程的mmap信息。
当进程动态地分配或释放内存时,需要修改mmap来反映分配或释放后的内存映像,因此动态内存分配或释放操作需要以写者身份获得读写信号量mmap_sem来对mmap进行更新。系统调用brk和munmap就使用了down_write和up_write来保护对mmap的访问。
五、自旋锁(spinlock)
自旋锁与互斥锁有点类似,只是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,"自旋"一词就是因此而得名。
由于自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是睡眠是非常必要的,自旋锁的效率远高于互斥锁。
信号量和读写信号量适合于保持时间较长的情况,它们会导致调用者睡眠,因此只能在进程上下文使用(_trylock的变种能够在中断上下文使用),而自旋锁适合于保持时间非常短的情况,它可以在任何上下文使用。
如果被保护的共享资源只在进程上下文访问,使用信号量保护该共享资源非常合适,如果对共巷资源的访问时间非常短,自旋锁也可以。但是如果被保护的共享资源需要在中断上下文访问(包括底半部即中断处理句柄和顶半部即软中断),就必须使用自旋锁。
自旋锁保持期间是抢占失效的,而信号量和读写信号量保持期间是可以被抢占的。自旋锁只有在内核可抢占或SMP的情况下才真正需要,在单CPU且不可抢占的内核下,自旋锁的所有操作都是空操作。
跟互斥锁一样,一个执行单元要想访问被自旋锁保护的共享资源,必须先得到锁,在访问完共享资源后,必须释放锁。如果在获取自旋锁时,没有任何执行单元保持该锁,那么将立即得到锁;如果在获取自旋锁时锁已经有保持者,那么获取锁操作将自旋在那里,直到该自旋锁的保持者释放了锁。
无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。
自旋锁的API有:
<ccid_nobr>
<ccid_code>spin_lock_init(x) |
该宏用于初始化自旋锁x。自旋锁在真正使用前必须先初始化。该宏用于动态初始化。
<ccid_nobr>
<ccid_code>DEFINE_SPINLOCK(x) |
该宏声明一个自旋锁x并初始化它。该宏在2.6.11中第一次被定义,在先前的内核中并没有该宏。
<ccid_nobr>
<ccid_code>SPIN_LOCK_UNLOCKED |
该宏用于静态初始化一个自旋锁。
<ccid_code>DEFINE_SPINLOCK(x)等同于spinlock_t x = SPIN_LOCK_UNLOCKED |
该宏用于判断自旋锁x是否已经被某执行单元保持(即被锁),如果是,返回真,否则返回假。
<ccid_nobr>
<ccid_code>spin_unlock_wait(x) |
该宏用于等待自旋锁x变得没有被任何执行单元保持,如果没有任何执行单元保持该自旋锁,该宏立即返回,否则将循环在那里,直到该自旋锁被保持者释放。
<ccid_nobr>
<ccid_code>spin_trylock(lock) |
该宏尽力获得自旋锁lock,如果能立即获得锁,它获得锁并返回真,否则不能立即获得锁,立即返回假。它不会自旋等待lock被释放。
<ccid_nobr>
<ccid_code>spin_lock(lock) |
该宏用于获得自旋锁lock,如果能够立即获得锁,它就马上返回,否则,它将自旋在那里,直到该自旋锁的保持者释放,这时,它获得锁并返回。总之,只有它获得锁才返回。
<ccid_nobr>
<ccid_code>spin_lock_irqsave(lock, flags) |
该宏获得自旋锁的同时把标志寄存器的值保存到变量flags中并失效本地中断。
<ccid_nobr>
<ccid_code>spin_lock_irq(lock) |
该宏类似于spin_lock_irqsave,只是该宏不保存标志寄存器的值。
<ccid_nobr>
<ccid_code>spin_lock_bh(lock) |
该宏在得到自旋锁的同时失效本地软中断。
<ccid_code>spin_unlock(lock) |
该宏释放自旋锁lock,它与spin_trylock或spin_lock配对使用。如果spin_trylock返回假,表明没有获得自旋锁,因此不必使用spin_unlock释放。
<ccid_nobr>
<ccid_code>spin_unlock_irqrestore(lock, flags) |
该宏释放自旋锁lock的同时,也恢复标志寄存器的值为变量flags保存的值。它与spin_lock_irqsave配对使用。
<ccid_nobr>
<ccid_code>spin_unlock_irq(lock) |
该宏释放自旋锁lock的同时,也使能本地中断。它与spin_lock_irq配对应用。
<ccid_code>spin_unlock_bh(lock) |
该宏释放自旋锁lock的同时,也使能本地的软中断。它与spin_lock_bh配对使用。
<ccid_code>spin_trylock_irqsave(lock, flags) |
该宏如果获得自旋锁lock,它也将保存标志寄存器的值到变量flags中,并且失效本地中断,如果没有获得锁,它什么也不做。
因此如果能够立即获得锁,它等同于spin_lock_irqsave,如果不能获得锁,它等同于spin_trylock。如果该宏获得自旋锁lock,那需要使用spin_unlock_irqrestore来释放。
<ccid_nobr>
<ccid_code>spin_trylock_irq(lock) |
该宏类似于spin_trylock_irqsave,只是该宏不保存标志寄存器。如果该宏获得自旋锁lock,需要使用spin_unlock_irq来释放。
<ccid_nobr>
<ccid_code>spin_trylock_bh(lock) |
该宏如果获得了自旋锁,它也将失效本地软中断。如果得不到锁,它什么也不做。因此,如果得到了锁,它等同于spin_lock_bh,如果得不到锁,它等同于spin_trylock。如果该宏得到了自旋锁,需要使用spin_unlock_bh来释放。
<ccid_nobr>
<ccid_code>spin_can_lock(lock) |
该宏用于判断自旋锁lock是否能够被锁,它实际是spin_is_locked取反。如果lock没有被锁,它返回真,否则,返回假。该宏在2.6.11中第一次被定义,在先前的内核中并没有该宏。
获得自旋锁和释放自旋锁有好几个版本,因此让读者知道在什么样的情况下使用什么版本的获得和释放锁的宏是非常必要的。
如果被保护的共享资源只在进程上下文访问和软中断上下文访问,那么当在进程上下文访问共享资源时,可能被软中断打断,从而可能进入软中断上下文来对被保护的共享资源访问,因此对于这种情况,对共享资源的访问必须使用spin_lock_bh和spin_unlock_bh来保护。
当然使用spin_lock_irq和spin_unlock_irq以及spin_lock_irqsave和spin_unlock_irqrestore也可以,它们失效了本地硬中断,失效硬中断隐式地也失效了软中断。但是使用spin_lock_bh和spin_unlock_bh是最恰当的,它比其他两个快。
如果被保护的共享资源只在进程上下文和tasklet或timer上下文访问,那么应该使用与上面情况相同的获得和释放锁的宏,因为tasklet和timer是用软中断实现的。
如果被保护的共享资源只在一个tasklet或timer上下文访问,那么不需要任何自旋锁保护,因为同一个tasklet或timer只能在一个CPU上运行,即使是在SMP环境下也是如此。实际上tasklet在调用tasklet_schedule标记其需要被调度时已经把该tasklet绑定到当前CPU,因此同一个tasklet决不可能同时在其他CPU上运行。
timer也是在其被使用add_timer添加到timer队列中时已经被帮定到当前CPU,所以同一个timer绝不可能运行在其他CPU上。当然同一个tasklet有两个实例同时运行在同一个CPU就更不可能了。
如果被保护的共享资源只在两个或多个tasklet或timer上下文访问,那么对共享资源的访问仅需要用spin_lock和spin_unlock来保护,不必使用_bh版本,因为当tasklet或timer运行时,不可能有其他tasklet或timer在当前CPU上运行。
如果被保护的共享资源只在一个软中断(tasklet和timer除外)上下文访问,那么这个共享资源需要用spin_lock和spin_unlock来保护,因为同样的软中断可以同时在不同的CPU上运行。
如果被保护的共享资源在两个或多个软中断上下文访问,那么这个共享资源当然更需要用spin_lock和spin_unlock来保护,不同的软中断能够同时在不同的CPU上运行。
如果被保护的共享资源在软中断(包括tasklet和timer)或进程上下文和硬中断上下文访问,那么在软中断或进程上下文访问期间,可能被硬中断打断,从而进入硬中断上下文对共享资源进行访问,因此,在进程或软中断上下文需要使用spin_lock_irq和spin_unlock_irq来保护对共享资源的访问。
而在中断处理句柄中使用什么版本,需依情况而定,如果只有一个中断处理句柄访问该共享资源,那么在中断处理句柄中仅需要spin_lock和spin_unlock来保护对共享资源的访问就可以了。
因为在执行中断处理句柄期间,不可能被同一CPU上的软中断或进程打断。但是如果有不同的中断处理句柄访问该共享资源,那么需要在中断处理句柄中使用spin_lock_irq和spin_unlock_irq来保护对共享资源的访问。
在使用spin_lock_irq和spin_unlock_irq的情况下,完全可以用spin_lock_irqsave和spin_unlock_irqrestore取代,那具体应该使用哪一个也需要依情况而定,如果可以确信在对共享资源访问前中断是使能的,那么使用spin_lock_irq更好一些。
因为它比spin_lock_irqsave要快一些,但是如果你不能确定是否中断使能,那么使用spin_lock_irqsave和spin_unlock_irqrestore更好,因为它将恢复访问共享资源前的中断标志而不是直接使能中断。
当然,有些情况下需要在访问共享资源时必须中断失效,而访问完后必须中断使能,这样的情形使用spin_lock_irq和spin_unlock_irq最好。
需要特别提醒读者,spin_lock用于阻止在不同CPU上的执行单元对共享资源的同时访问以及不同进程上下文互相抢占导致的对共享资源的非同步访问,而中断失效和软中断失效却是为了阻止在同一CPU上软中断或中断对共享资源的非同步访问。
参考资料
Kernel Locking Techniques,http://www.linuxjournal.com/article/5833
Redhat 9.0 kernel source tree
kernel.org 2.6.12 source tree
Linux 2.6内核中新的锁机制--RCU(Read-Copy Update),
http://www.ibm.com/developerworks/cn/linux/l-rcu/
Unreliable Guide To Locking.
Linux内核同步机制的更多相关文章
- [内核同步]浅析Linux内核同步机制
转自:http://blog.csdn.net/fzubbsc/article/details/37736683?utm_source=tuicool&utm_medium=referral ...
- Linux内核同步机制--转发自蜗窝科技
Linux内核同步机制之(一):原子操作 http://www.wowotech.net/linux_kenrel/atomic.html 一.源由 我们的程序逻辑经常遇到这样的操作序列: 1.读一个 ...
- Linux内核同步机制之(五):Read Write spin lock【转】
一.为何会有rw spin lock? 在有了强大的spin lock之后,为何还会有rw spin lock呢?无他,仅仅是为了增加内核的并发,从而增加性能而已.spin lock严格的限制只有一个 ...
- Linux内核同步机制之completion【转】
Linux内核同步机制之completion 内核编程中常见的一种模式是,在当前线程之外初始化某个活动,然后等待该活动的结束.这个活动可能是,创建一个新的内核线程或者新的用户空间进程.对一个已有进程的 ...
- 浅析Linux内核同步机制
非常早之前就接触过同步这个概念了,可是一直都非常模糊.没有深入地学习了解过,最近有时间了,就花时间研习了一下<linux内核标准教程>和<深入linux设备驱动程序内核机制>这 ...
- Linux内核同步机制之(四):spin lock【转】
转自:http://www.wowotech.net/kernel_synchronization/spinlock.html 一.前言 在linux kernel的实现中,经常会遇到这样的场景:共享 ...
- Linux 内核同步机制
本文将就自己对内核同步机制的一些简要理解,做出一份自己的总结文档. Linux内部,为了提供对共享资源的互斥访问,提供了一系列的方法,下面简要的一一介绍. Technorati 标签: ...
- Linux内核同步机制之(二):Per-CPU变量
转自:http://www.wowotech.net/linux_kenrel/per-cpu.html 一.源由:为何引入Per-CPU变量? 1.lock bus带来的性能问题 在ARM平台上,A ...
- Linux内核同步机制之原子操作
1.前言 原子操作指的是该操作不会在执行完毕之前被任何其它任务或事件打断,它是最小的执行单位,不会有比它更小的执行单位,原子实际上使用了物理学中物质微粒的概念,在Linux内核中,原子操作需要硬件的支 ...
随机推荐
- composer很慢修改镜像
有两种方式启用本镜像服务: 系统全局配置: 即将配置信息添加到 Composer 的全局配置文件 config.json 中.见“例1” 单个项目配置: 将配置信息添加到某个项目的 composer. ...
- java一般要点
1.String是引用类型. 2.char, short, byte在进行运算的时候会自动转换成int类型数据., 3.数据A 异或同一个数两次,得到的还是A 4.java的for循环,可以在前面加一 ...
- log4net 使用教程
1.下载log4net (Google log4net) //已有 2.unzip log4net 3.运行VS,新建 c# Windows应用程序. 4.添加引用Log4NET 5.新建一个应用程序 ...
- paper 78:sniff抓包程序片段
#define INTERFACE "eth0"#define MAX_SIZE 65535 int init_raw_socket();int open_promisc(char ...
- 【RoR win32】提高rails new时bundle install运行速度
在新建rails项目时,rails new老是卡在bundle install那里,少则五分钟,多则几十分.这是因为rails new时自动会运行bundle install,而bundle inst ...
- 《OpenGL游戏编程》第9章-PlanarShadow关键代码注释
阴影这块确实是难点.说到阴影就必须提到投影矩阵.模板值为1和2时分别渲染.说来话长,仅仅放上代码,供日后查阅. /** 渲染墙面和阴影 */ void CPlanarShadow::Render() ...
- sql server中index的REBUILD和REORGANIZE
参考文献: http://technet.microsoft.com/en-us/library/ms188388.aspx 正文 本文主要讲解如何使用alter index来rebuild和reor ...
- Spring+SpringMVC+MyBatis)
用SSM(Spring.SpringMVC和Mybatis)已经有三个多月了,项目在技术上已经没有什么难点了,基于现有的技术就可以实现想要的功能,当然肯定有很多可以改进的地方.之前没有记录SSM整合的 ...
- 160918、BigDecimal运算
java.math.BigDecimal.BigDecimal一共有4个够造方法,让我先来看看其中的两种用法: 第一种:BigDecimal(double val)Translates a doubl ...
- h3c 交换机配置VLAN和远程管理
一.基本设置 1. console线连接成功 2. 进入系统模式 <H3C>system-view //提示符由<H3C> 变为 [H3C] 3. 更改设备名称 [H3C]sy ...