机器学习 Support Vector Machines 1
引言
这一讲及接下来的几讲,我们要介绍supervised learning 算法中最好的算法之一:Support Vector Machines (SVM,支持向量机)。为了介绍支持向量机,我们先讨论“边界”的概念,接下来,我们将讨论优化的边界分类器,并将引出拉格朗日数乘法。我们还会给出 kernel function 的概念,利用 kernel function,可以有效地处理高维(甚至无限维数)的特征向量,最后,我们会介绍SMO算法,该算法说明了如何高效地实现SVM。
Margin 边界
我们的SVM之旅,从边界的讨论开始,我们要讨论边界的概念以及预测的置信度等概念。
考虑 logistic regression, 其概率 p(y=1|x;θ) 由函数 hθ(x)=g(θTx) 估计,我们预测一个输入向量的输出为 “1” 当且仅当其概率 hθ(x)⩾0.5,或者 θTx⩾0, 考虑一个正样本(y=1)。如果 θTx 越大,意味着其概率 hθ(x)=p(y=1|x;w,b) 也越大,因此我们有更高的置信度将该样本判定为正样本(y=1)。一般情况下,当 θTx≫0, 我们非常确信该样本的输出为 1, 同样地,当 θTx≪0,我们非常确信该样本为负样本,y=0。给定一组训练样本,我们希望可以找到这样一组参数 θ,使得对于任何的正样本 y(i)=1,满足 θTx(i)≫0;而对于任何的负样本y(i)=0, 满足θTx(i)≪0,如果能找到这样一组参数,那对于分类器来说,它可以有很高的置信度区分正负样本,这是分类问题的非常理想的结果。我们将在后面用 function margin (函数边界)的概念描述这个想法。
我们先来考虑如下一张图,其中 × 表示正样本,∘ 表示负样本。决策边界 (在图中就是那条直线,由 θTx=0 定义,这条线也称为分界面。图上三个点分别标为:A,B,C.
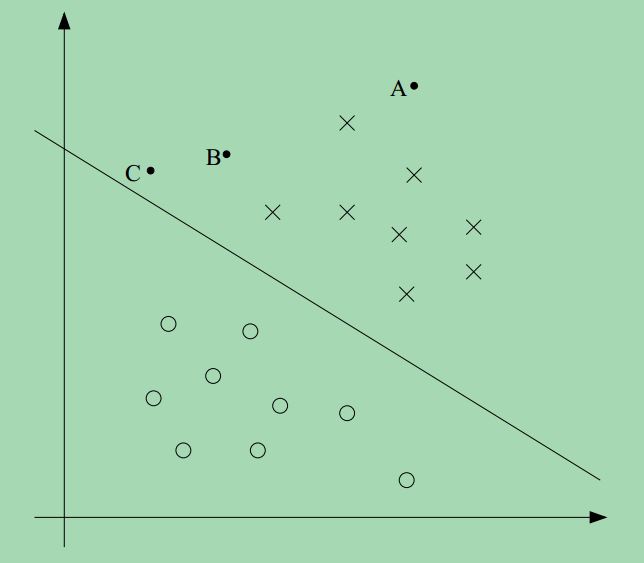
我们注意到点A离决策边界非常远,如果要我们判断点A,我们有很高的置信度判断点A为正样本,其y=1。但是对于点C,我们发现它离决策边界很近,在图上所示的情况下,我们知道点C是正样本,我们预测其输出y=1,但是我们也注意到,如果决策边界稍微有点改变,则点C有可能被判断为负样本,预测的输出为y=0。因此,从图上各点的分布以及决策边界的位置,我们可以说我们对于点A的预测比对点C的预测更加自信,换句话说,点A的置信度比点C高。我们看到,如果一个点离决策边界越远,那么分类器判断的时候置信度也会更高。因此,给定一组训练样本,我们试着找到这样一个决策边界,使得分类器对所有训练样本的判断都有一个很高的置信度(意味着所有的点都要尽可能地远离决策边界),我们稍后将用 geometric margin (几何边界)的概念去实现这个想法。
在介绍函数边界和几何边界之前,我们要先定义一些符号。我们考虑用线性分类器解决二分类问题,其输出为y,输入的特征向量为x,现在我们要用{−1,1}而不是{0,1}来表示样本的输出。我们不再用向量θ来表示我们需要求的参数,现在换成了参数w,b,而线性分类器的表达式为:
其中,函数g满足,g(z)=1 当 z>0,反之 g(z)=−1当,z<0。w 还是一个向量,而b相当于截距。
从分类器的函数表达式可以看出,我们将直接预测样本的输出为1或者-1,而不再像logistic regression那样,先判断其概率,然后再判断样本的输出。
函数边界和几何边界
接下来,我们探讨函数边界和几何边界,给定一组训练样本(x(i),y(i)),我们定义某个样本的函数边界为:
如果y(i)=1,那么为了使得函数边界尽可能地大,我们需要wTx+b是一个很大的正数,相反得,如果y(i)=−1,我们希望wTx+b是一个绝对值很大的负数。
进一步的,如果 y(i)(wTx+b)>0,那么我们的预测就是对的(这个应该很容易验证)。因此,一个大的函数边界意味着一个可靠的,正确的预测。
对于线性分类器,其函数为g,我们发现如果函数g的参数w,b变成2w,2b,由于g(wTx+b)=g(2wTx+2b),因此hw,b(x)不会有任何改变,因为hw,b(x) 取决于 wTx+b的符号而不是大小。虽然如此,但是(w,b)变成(2w,2b)还是使得函数边界乘以了2. 从中可以看出,我们可以通过任意改变w,b的尺度,使得函数边界取任意的值而不会使hw,b(x)有任何变化。直观上,我们可以引入如下的归一化,即∥w∥2=1,我们可以将w,b替换成(w/∥w∥2,b/∥w∥2),我们考虑参数(w/∥w∥2,b/∥w∥2) 所表示的函数边界。我们稍后将会回到这个问题。
给定一组训练样本,S={(x(i),y(i));i=1,2...m},我们定义参数w,b关于训练集S的函数边界为所有样本的函数边界的最小值,称为γ^,可以定义为:
因此,一个训练集的\textbf{函数边界},就是该训练集中所有样本的函数边界的最小值。
接下来,我们讨论几何边界,考虑如下的一张图:
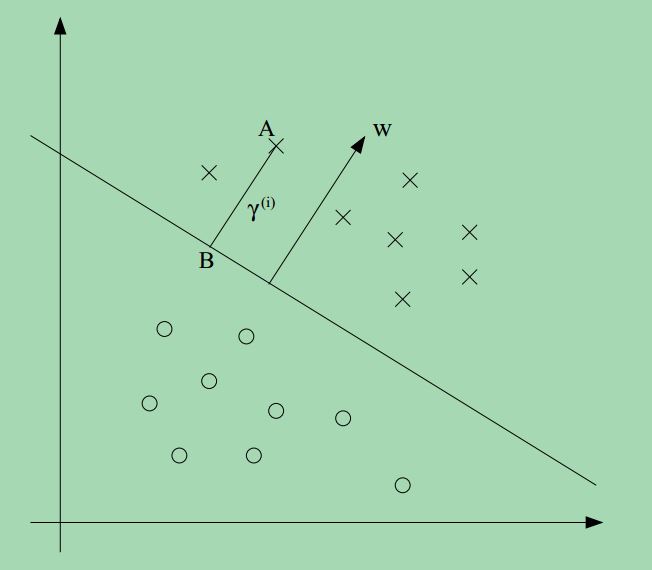
w,b对应的决策边界已经给出,沿着w的方向,请注意,w是垂直于分界面的(这一点应该容易证明)。考虑点A,表示某个正样本,点A到决策边界的距离 γ(i),由线段AB表示。
如何确定γ(i)的值?w/∥w∥是一个与w方向相同的单位长度的向量,点A表示特征向量x(i),点B可以表示为:x(i)−γ(i)⋅w/∥w∥, 我们知道这点在决策边界上,所有在决策边界上的点满足wTx+b=0. 因此:
进而可以求得γ(i)为:
上式给出的是正样本的情况,更一般地,我们定义一个样本关于参数w,b的几何边界为:
我们可以发现如果 ∥w∥=1,那么函数边界和几何边界相等,这个表达式提供了一种将两种边界联系起来的渠道。同样可以看到几何边界具有尺度不变性,如果将w,b 替换成2w,2b,可以看到几何边界不会改变。稍后我们将会看到,正是这种尺度不变性,让我们在拟合训练样本的时候,可以任意寻找参数w,b,而不会对函数性质产生多大的变化。
最后,我们给出几何边界的定义, 与函数边界的定义类似,给定一组训练样本,S={(x(i),y(i));i=1,2...m},我们定义参数w,b关于训练集S的几何边界为所有样本的几何边界的最小值,称为γ^,可以定义为:
因此,一个训练集的几何边界,就是该训练集中所有样本的几何边界的最小值。
参考文献
Andrew Ng, “Machine Learning”, Stanford University.
机器学习 Support Vector Machines 1的更多相关文章
- 机器学习 Support Vector Machines 3
Optimal margin classifiers 前面我们讲过,对如下的原始的优化问题我们希望找到一个优化的边界分类器. minγ,w,bs.t.12∥w∥2y(i)(wTx(i)+b)⩾1,i= ...
- 机器学习 Support Vector Machines 2
优化的边界分类器 上一讲里我们介绍了函数边界和几何边界的概念,给定一组训练样本,如果能够找到一条决策边界,能够使得几何边界尽可能地大,这将使分类器可以很可靠地预测训练样本,特别地,这可以让分类器用一个 ...
- Coursera 机器学习 第7章 Support Vector Machines 学习笔记
7 Support Vector Machines7.1 Large Margin Classification7.1.1 Optimization Objective支持向量机(SVM)代价函数在数 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 12—Support Vector Machines 支持向量机
Lecture 12 支持向量机 Support Vector Machines 12.1 优化目标 Optimization Objective 支持向量机(Support Vector Machi ...
- Andrew Ng机器学习编程作业:Support Vector Machines
作业: machine-learning-ex6 1. 支持向量机(Support Vector Machines) 在这节,我们将使用支持向量机来处理二维数据.通过实验将会帮助我们获得一个直观感受S ...
- Machine Learning - 第7周(Support Vector Machines)
SVMs are considered by many to be the most powerful 'black box' learning algorithm, and by posing构建 ...
- 【Supervised Learning】支持向量机SVM (to explain Support Vector Machines (SVM) like I am a 5 year old )
Support Vector Machines 引言 内核方法是模式分析中非常有用的算法,其中最著名的一个是支持向量机SVM 工程师在于合理使用你所拥有的toolkit 相关代码 sklearn-SV ...
- [C7] 支持向量机(Support Vector Machines) (待整理)
支持向量机(Support Vector Machines) 优化目标(Optimization Objective) 到目前为止,你已经见过一系列不同的学习算法.在监督学习中,许多学习算法的性能都非 ...
- Support Vector Machines for classification
Support Vector Machines for classification To whet your appetite for support vector machines, here’s ...
随机推荐
- Linux进程间通信(二) - 消息队列
消息队列 消息队列是Linux IPC中很常用的一种通信方式,它通常用来在不同进程间发送特定格式的消息数据. 消息队列和之前讨论过的管道和FIFO有很大的区别,主要有以下两点(管道请查阅我的另一篇文章 ...
- php闭包简单实例
<?php function getClosure($i) { $i = $i.'-'.date('H:i:s'); return function ($param) use ($i) { ec ...
- yii2.0 console执行php守护进程
//该方法只需执行一次public function actionIndex(){ $pid =pcntl_fork();//在当前进程中生成一个新的子进程 //$pid会有三种形式 $pid==-1 ...
- jquery获取页面iframe内容
//取得整个HTML格式 var f = $(window.frames["ReportIFrame"].document).contents().html(); 或者 $(&qu ...
- 合唱队形(LIS)
合唱队形 OpenJ_Bailian - 2711 N位同学站成一排,音乐老师要请其中的(N-K)位同学出列,使得剩下的K位同学不交换位置就能排成合唱队形. 合唱队形是指这样的一种队形:设K位同 ...
- spring bean标签常用属性
一.id属性 其名称,可以是任意名称,但不能包含特殊符号. 根据id得到配置对象. 二.class属性 创建对象所在的类名称 三.name属性 功能和id属性一样,但name属性值可以包含特殊属性 四 ...
- TextView属性
TextView及其子类,当字符内容太长显示不下时可以省略号代替未显示的字符:省略号可以在显示区域的起始,中间,结束位置,或者以跑马灯的方式显示文字(textview的状态为被选中). 其实现只需在x ...
- Iptalbes练习题(一)
实验环境: KVM 虚拟机 centos6.7 test1:192.168.124.87 test2:192.168.124.94 场景一: 要求:1.对所有地址开放本机的tcp(80.22.10- ...
- sql把字符数组转换成表
需求:把字符串1,2,3变成表里的行数据 方法:用自定义函数实现 /* 获取字符串数组的 Table */ from sysobjects where id = object_id('Get_StrA ...
- deviceToken的获取(一)
1.获得deviceToken的过程 1>客户端向苹果服务APNS,发送设备的UDID和英语的Bundle Identifier.2>经苹果服务器加密生成一个deviceToken ...