MCP|MZL|Accurate Estimation of Context- Dependent False Discovery Rates in Top- Down Proteomics 在自顶向下蛋白组学中精确设定评估条件估计假阳性
一、 概述:
自顶向下的蛋白质组学技术近年来也发展成为高通量蛋白定性定量手段。该技术可以在一次的实验中定性上千种蛋白,然而缺乏一个可靠的假阳性控制方法阻碍了该技术的发展。在大规模流程化的假阳性控制手段中,假阳性的判断取决于蛋白鉴定的检索条件,包括谱图的质量,检索的数据库的大小,检索引擎,检索参数等。本文提出了一个一种依据蛋白鉴定条件设定假阳性的方法。该方法的可靠性在一个人工确认的包含546个蛋白的数据集中进行了验证。目前该方法已被封装成一个开源工具,TDCD_FDR_CALCULATOR,可以整合到任何的鉴定搜索引擎中。
二、 研究背景:(简要介绍研究进展动态、研究目的和意义)
对于大规模高通量的自顶向下的蛋白质组学研究,自动高效的假阳性校正是必不可少的。在之前的自顶向下的蛋白质组学研究中,通过人工核验鉴定到的谱图与目标蛋白的理论谱图来确认鉴定结果的过程是不适用于高通量的研究的。目前自下而上向上的蛋白质组研究已经建立了丰富的假阳性控制的方法和工具,而在自顶向下的蛋白组学研究中尚缺乏这样的假阳性控制工具。本文建立了一套适用于自顶向下蛋白质组的假阳性分析工具,并评估了其可靠性。
三、实验设计:
本文开发了一种基于鉴定条件/鉴定的上下文来评估FDR的方法,并整合成为一个工具TDCD_FDR_CALCULATOR。该方法在鉴定时首先计算非参数的FDR值。同时在鉴定到的不同分子水平上依据鉴定的条件,构建该鉴定条件下的反库,并计算在反库中的匹配得分。再使用参数检验计算不同分子水平上的鉴定得分是否高于最好的反库匹配得分,更高的才认为是阳性。这个方法在PROSIGHT Absolute Mass, PROSIGHT Biomarker, 和INFORMED PROTEOMICS MSPathFinder上进行了测试。TDCD_FDR_CALCULATOR的适用性较广,可以适用于所有的自顶向下的搜索引擎。其输入文件为CSV格式,每个run一个CSV文件。TDCD_FDR_CALCULATOR的可靠性在一个546个人工验证的蛋白的数据集上进行了测试评估。这个数据集以及TDCD_FDR_CALCULATOR软件都是公开的。
四、研究成果:
在细胞中,基因被转录、剪切、翻译和修饰,成为一个蛋白群组。因此基于谱图的鉴定报道的是一个蛋白群组。在报道一个蛋白群组的假阳性的时候,所有的支持该蛋白群组的谱图都需要被考虑,来计算可信度与假阳性。同样的道理,在计算isoform的假阳性的时候也要考虑与其相关的谱图。

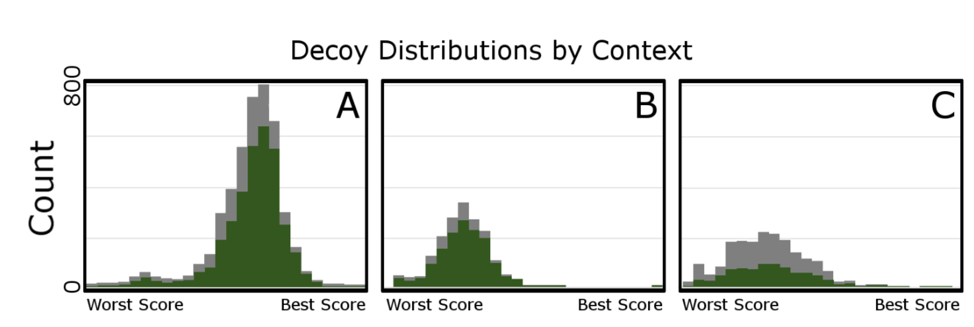
在自顶向下的蛋白质组学中,因为每个分子的鉴定都是有特定的谱图支持、搜索的数据库和搜索的参数,可以依据这些条件得到每个分子的反库,因此,每个分子水平的鉴定都有其自身的反库的搜索得分分布。下图展示了蛋白水平和蛋白群组水平的反库搜索得分的分布。绿色表示蛋白水平,灰色表示蛋白组水平,A,B,C分别表示对于同一个蛋白在不同的数据库、搜索引擎下,得到的不同的反库的得分分布。
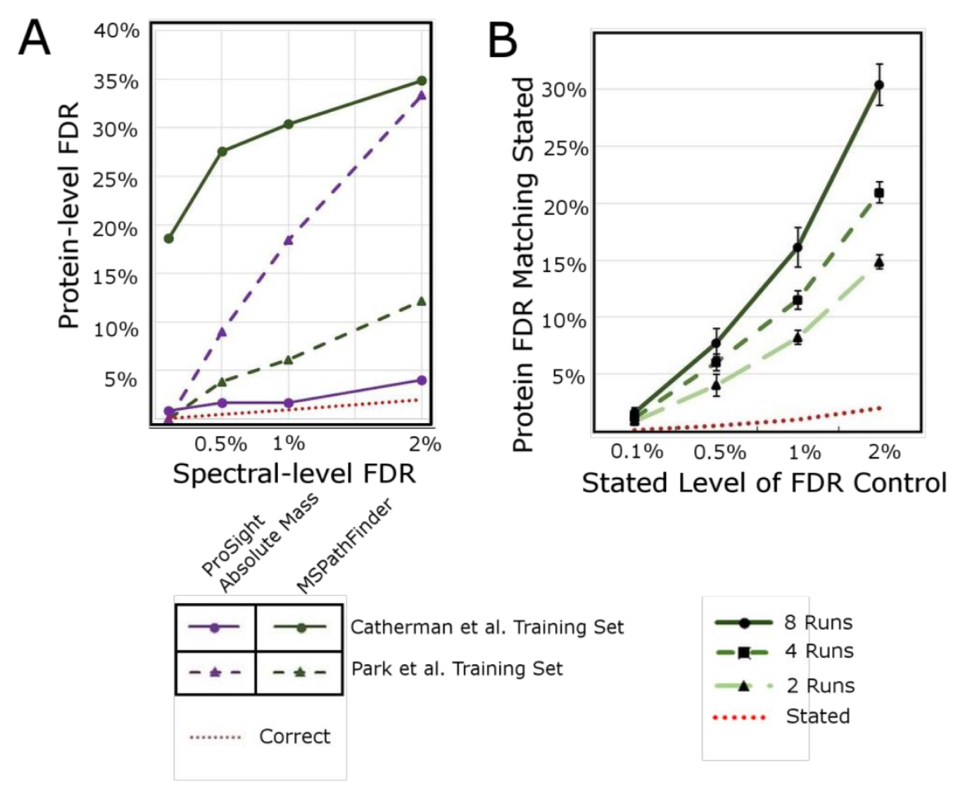
依赖PrSM水平的FDR校正得到的蛋白水平的假阳性率会很高,如下图所示:在两个数据集上,使用PROSIGHT Absolute Mass search (AM)和and MSPATHFINDER (PF)来做谱图水平的FDR为x轴,由此得到的蛋白水平的FDR为y轴,红线表示真实值。可见谱图水平的1%的FDR,得到的蛋白鉴定结果有约30%是假阳性的。因此,需要更为精确的的FDR控制。
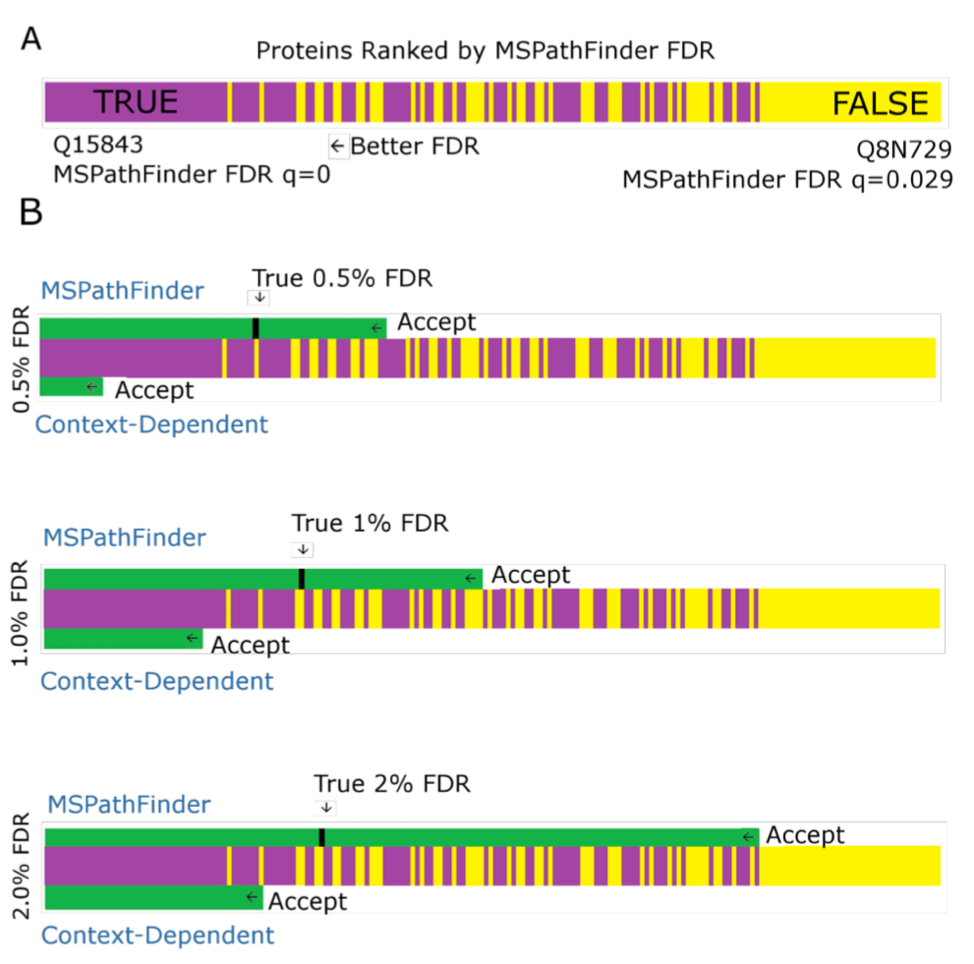
那么考虑鉴定条件的FDR究竟比常规的FDR的效果好在何处,作者通过可视化比较不同的FDR效果:A表示460个蛋白的q值得分,从最左边最低0到最右边的最高,0.029。从左到右q值逐渐增加。紫色表示人工验证的真阳性,黄色表示假阳性。B表示在不同的的FDR水平下,常规的FDR与基于上下文的FDR的效果。上面绿色表示常规FDR的水平下接受的蛋白的情况。如0.5%FDR接受的蛋白用绿色表示,黑色短竖线表示真实的0.5%所应当接受的蛋白。比较两种FDR计算策略在不同FDR水平下接受的蛋白的正确性来看,基于上下文的FDR校正方法更加保守,更加精确。
五、结论
蛋白或者蛋白组的鉴定的假阳性估计是与搜库的条件相关的。需要考虑搜库过程中设定的条件。我们提出了一种方便快捷的假阳性校正的方法。这个方法是可以根据蛋白鉴定的条件来设定不同的假阳性校正条件的,即每个蛋白组的假阳性校正都取决于其鉴定的参数。正式考虑了这些条件,该方法在假阳性校正方面更加的可靠与准确。该方法适合在大规模的自顶向下蛋白质组学中应用。为了提高这类方法的普适性,适当的包含一些假阳性结果比去除正阳性结果更为恰当。
MCP|MZL|Accurate Estimation of Context- Dependent False Discovery Rates in Top- Down Proteomics 在自顶向下蛋白组学中精确设定评估条件估计假阳性的更多相关文章
- 解读人:谭亦凡,Macrophage phosphoproteome analysis reveals MINCLE-dependent and -independent mycobacterial cord factor signaling(巨噬细胞磷酸化蛋白组学分析揭示MINCLE依赖和非依赖的分支杆菌索状因子信号通路)(MCP换)
发表时间:2019年4月 IF:5.232 一. 概述: 分支杆菌索状因子TDM(trehalose-6,6’-dimycolate)能够与巨噬细胞C-型凝集素受体(CLR)MINCLE结合引起下游通 ...
- 文献名:Repeat-Preserving Decoy Database for False Discovery Rate Estimation in Peptide Identication (用于肽段鉴定中错误发生率估计的能体现重复性的诱饵数据库)
文献名:Repeat-Preserving Decoy Database for False Discovery Rate Estimation in Peptide Identication (用于 ...
- False Discovery Rate, a intuitive explanation
[转载请注明出处]http://www.cnblogs.com/mashiqi Today let's talk about a intuitive explanation of Benjamini- ...
- [PAMI 2018] Differential Geometry in Edge Detection: accurate estimation of position, orientation and curvature
铛铛铛,我的第一篇文章终于上线了,过程曲折,太不容易了--欢迎访问--- https://ieeexplore.ieee.org/document/8382271/ 后面有需要的话可以更新一下介绍,毕 ...
- MCP|ZWT|Precision de novo peptide sequencing using mirror proteases of Ac-LysargiNase and trypsin for large-scale proteomics(基于Ac-LysargiNase和胰蛋白酶的蛋白组镜像de novo测序)
一.概述 由于难以获得100%的蛋白氨基酸序列覆盖率,蛋白组de novo测序成为了蛋白测序的难点,由Ac-LysargiNase(N端蛋白酶)和胰蛋白酶构成的镜像酶组合可以解决这个问题并具有稳定性, ...
- MCP|LQ|DIAlignR provides precise retention time alignment across distant runs in DIA and targeted proteomics
文献名: DIAlignR provides precise retention time alignment across distant runs in DIA and targeted prot ...
- Simulation of empirical Bayesian methods (using baseball statistics)
Previously in this series: The beta distribution Empirical Bayes estimation Credible intervals The B ...
- Tomcat 部署
<CATALINA_HOME>/webapps: Tomcat的主要Web发布目录,默认情况下把Web应用文件放于此目录. 1.war包部署: 将需要发布的web应用打成war文件, ( ...
- C# PropertyGrid控件应用心得
何处使用 PropertyGrid 控件 在应用程序中的很多地方,您都可以使用户与 PropertyGrid 进行交互,从而获得更丰富的编辑体验.例如,某个应用程序包含多个用户可以设置的“设置”或选项 ...
随机推荐
- Unity3D之Mesh(六)绘制扇形、扇面、环形
前言: 绘制了圆,就想到绘制与之相关的几何图形,以便更灵活的掌握Mesh动态创建模型的机制与方法. 一.分析: 首先,结合绘制圆的过程绘制环形: 圆形是由segments个等腰三角形组成的(上一篇中, ...
- 如何在MySQL中查询当前数据上一条和下一条的记录
如果ID是主键或者有索引,可以直接查找: 方法一: 查询上一条记录的SQL语句(如果有其他的查询条件记得加上other_conditions以免出现不必要的错误): select * from tab ...
- JavaWEB - 静态include指令、动态Include指令
(一)使用静态include指令 <%@ page language="java" contentType="text/html; charset=gb2312&q ...
- xcopy语法
xcopy语法 2007-02-09 13:29:45| 分类: 服务器 | 标签:xcopy语法 |字号 订阅复制文件和目录,包括子目录. 语法 xcopySource [Destination] ...
- linux 下查看某个进程中线程运行在哪个CPU上
运行程序,使用命令top查看指定的进程的PID: 然后使用命令: top -H -p PID 按f键,并使用上下切换,利用空格键选中nTH,P: 按esc键,P所在的列就是线程运行的CPU号:
- 点击Button调用另一个Dialog
资源视图--Dialog--右键--添加资源--新建--对话框--然后在已经生成的对话框中(解决资源视图中的dialog下的新生成的那个)右键--添加类.例如:添加CMyNewDlg类,在所要调的代码 ...
- 【java并发编程艺术学习】(二)第一章 java并发编程的挑战
章节介绍 主要介绍并发编程时间中可能遇到的问题,以及如何解决. 主要问题 1.上下文切换问题 时间片是cpu分配给每个线程的时间,时间片非常短. cpu通过时间片分配算法来循环执行任务,当前任务执行一 ...
- shell解决DOS攻击生产案例
解决DOS攻击生产案例企业实战题5:请用至少两种方法实现!写一个脚本解决DOS攻击生产案例.提示:根据web日志或者或者网络连接数,监控当某个IP并发连接数或者短时内PV达到100,即调用防火墙命令封 ...
- 并发设计模式和锁优化以及jdk8并发新特性
1 设计模式 (1) 单例模式 保证一个类只能一个对象实现.正常的单例模式分为懒汉式和饿汉式,饿汉式就是把单例声明称static a=new A(),系统第一次调用的时候生成(包括调用该类的其他静态资 ...
- ASP.NET 调试出现<%@ Application Codebehind="Global.asax.cs" Inherits="XXX.XXX.Global" Language="C#" %>
ASP.NET 调试出现<%@ Application Codebehind="Global.asax.cs" Inherits="XXX.XXX.Global&q ...