海量日志收集利器 —— Flume
Flume 是什么?
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume 特点
1、可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。
2、可扩展性
Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
3、可管理性
所有agent和colletor由master统一管理,这使得系统便于维护。多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shellscript command两种形式对数据流进行管理。
4、功能可扩展性
用户可以根据需要添加自己的agent,collector或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
5、文档丰富,社区活跃
Flume 已经成为 Hadoop 生态系统的标配,它的文档比较丰富,社区比较活跃,方便我们学习。
Flume OG 与 Flume NG 的对比
1、Flume OG
Flume OG:Flume original generation 即Flume 0.9.x版本,它由agent、collector、master等组件构成。
2、Flume NG
Flume NG:Flume next generation ,即Flume 1.x版本,它由Agent、Client等组件构成。
3、Flume NG版本的优点
1)相对于Flume OG版本,Flume NG版本代码比较简单。
2)相对于Flume OG版本,Flume NG版本架构简洁。
接下来我们重点讲解 Flume NG。
Flume NG基本架构
Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。由原来的Flume OG到现在的Flume NG,进行了架构重构,并且现在NG版本完全不兼容原来的OG版本。经过架构重构后,Flume NG更像是一个轻量的小工具,非常简单,容易适应各种方式日志收集,并支持failover和负载均衡。
Flume NG 的架构图如下所示。

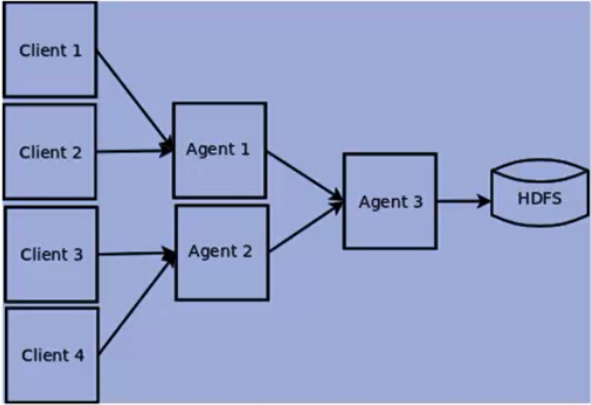
Flume NG核心概念
Flume的架构主要有一下几个核心概念:
1、Event:一个数据单元,带有一个可选的消息头。
2、Flow:Event从源点到达目的点的迁移的抽象。
3、Client:操作位于源点处的Event,将其发送到Flume Agent。
4、Agent:一个独立的Flume进程,包含组件Source、Channel、Sink。
5、Source:用来消费传递到该组件的Event。
6、Channel:中转Event的一个临时存储,保存有Source组件传递过来的Event。
7、Sink:从Channel中读取并移除Event,将Event传递到Flow Pipeline中的下一个Agent(如果有的话)
下面我们分别介绍以上几个核心的概念。
Event
1、Event 是Flume数据传输的基本单元。
2、Flume 以事件的形式将数据从源头传输到最终的目的。
3、Event 由可选的header和载有数据的一个byte array构成。
1)载有的数据对Flume是不透明的。
2)Header 是容纳了key-value字符串对的无序集合,key在集合内是唯一的。
3)Header 可以在上下文路由中使用扩展。
Client
1、Client 是一个将原始log包装成events并且发送它们到一个或者多个agent的实体。
2、Client 在Flume的拓扑结构中不是必须的,它的目的是从数据源系统中解耦Flume
Agent
1、一个Agent包含Source、Channel、Sink和其他组件。
2、它利用这些组件将events从一个节点传输到另一个节点或最终目的地。
3、agent是Flume流的基础部分。
4、Flume 为这些组件提供了配置、生命周期管理、监控支持。
Agent之Source

1、Source负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个Channel。
2、Source包含event驱动和轮询两种类型。
3、Source 有不同的类型。
1)与系统集成的Source:Syslog,NetCat。
2)自动生成事件的Source:Exec
3)用于Agent和Agent之间的通信的IPC Source:Avro、Thrift。
4、Source必须至少和一个Channel关联。
Agent之Channel与Sink
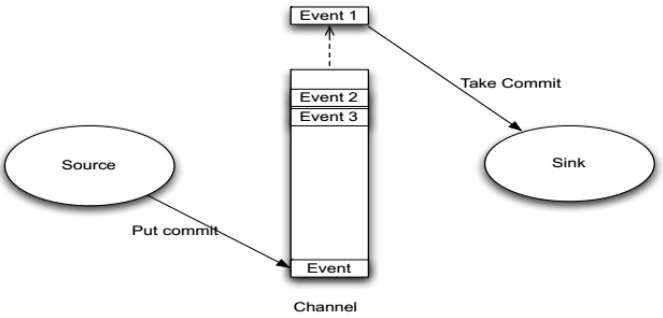
Agent之Channel
1、Channel位于Source和Sink之间,用于缓存进来的event。
2、当Sink成功的将event发送到下一跳的Channel或最终目的地,event才Channel中移除。
3、不同的Channel提供的持久化水平也是不一样的:
1)Memory Channel:volatile。
2)File Channel:基于WAL实现。
3)JDBC Channel:基于嵌入Database实现。
4、Channel支持事物,提供较弱的顺序保证。
5、Channel可以和任何数量的Source和Sink工作。
Agent之Sink
1、Sink负责将event传输到下一跳或最终目的,成功完成后将event从Channel移除。
2、有不同类型的Sink:
1)存储event到最终目的的终端Sink。比如HDFS,HBase。
2)自动消耗的Sink。比如:Null Sink。
3)用于Agent间通信的IPC sink:Avro。
3、Sink必须作用于一个确切的Channel。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
海量日志收集利器 —— Flume的更多相关文章
- 分布式日志收集框架Flume
分布式日志收集框架Flume 1.业务现状分析 WebServer/ApplicationServer分散在各个机器上 想在大数据平台Hadoop进行统计分析 日志如何收集到Hadoop平台上 解决方 ...
- 日志收集系统Flume及其应用
Apache Flume概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统.Flume 支持定制各类数据发送方,用于收集各类型数据:同时,Fl ...
- 学习笔记:分布式日志收集框架Flume
业务现状分析 WebServer/ApplicationServer分散在各个机器上,想在大数据平台hadoop上进行统计分析,就需要先把日志收集到hadoop平台上. 思考:如何解决我们的数据从其他 ...
- 日志收集框架flume的安装及简单使用
flume介绍 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS.hbase.h ...
- 分布式日志收集系统 —— Flume
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- Go实现海量日志收集系统(一)
项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机器规模不大,一个系统通常 ...
- Go实现海量日志收集系统(三)
再次整理了一下这个日志收集系统的框,如下图 这次要实现的代码的整体逻辑为: 完整代码地址为: https://github.com/pythonsite/logagent etcd介绍 高可用的分布式 ...
- 安装Flume——海量日志收集聚合系统
下载flume: 1.官方网站下载: http://flume.apache.org/download.html 2.百度网盘资源: apache-flume-1.9.0-bin.tar 链接:ht ...
- Go实现海量日志收集系统(四)
到这一步,我的收集系统就已经完成很大一部分工作,我们重新看一下我们之前画的图: 我们已经完成前面的部分,剩下是要完成后半部分,将kafka中的数据扔到ElasticSearch,并且最终通过kiban ...
随机推荐
- JSP标签和EL表达式
1.jsp标签: sun原生的,直接jsp使用 <jsp:include> -- 实现页面包含,动态包含 <jsp:include page="/index.jsp&quo ...
- 文件异步上传,多文件上传插件uploadify
本文中使用java作为例子 uploadify下载 http://files.cnblogs.com/chyg/uploadify.zip jsp页面中需要引入: <script type=&q ...
- stm32 奇怪的位赋值问题 出错了
转载请注明出处:http://blog.csdn.net/qq_26093511/article/category/6094215 1.在51单片机里 ,下面这两种操作方法都是一样的,没有什么问题! ...
- ES6学习之Generator函数
概念:可以把Generator 函数理解成状态机(封装了多个内部状态)或者是一个遍历器对象生成函数 写法:Generator函数的定义跟普通函数差不多,只是在function关键字后面加了一个星号 f ...
- WPF实现右键菜单
ContextMenu类就是用来做右键菜单的对象,对于任何的控件都可以进行对ContextMenu属性的操作进行设置右键菜单的功能. 下面代码就是对一个按钮添加一个WPF右键菜单的功能: < B ...
- Mac搭建nginx+rtmp服务器
nginx是非常优秀的开源服务器,用它来做hls或者rtmp流媒体服务器是非常不错的选择,本人在网上整理了安装流程,分享给大家并且作备忘. 一.安装Homebrow 已经安装了brow的可以直接跳过这 ...
- shell入门-变量
shell变量分为系统变量和用户自定义变量 查看变量的命令 #env 系统变量 或者 #set 包括env和自定义变量和额外变量 使用变量的命令是 #echo $[变量] //// ...
- 0008_Python变量
1.变量名:数字,字母,下划线组成,不能以数字开头,不能是Python内部关键字. 2.变量类型:数字,字符串,布尔值(首字母大写) 3.内存与变量: 4. = 赋值 == 比较 is == ...
- Centos 6.5 hadoop 2.2.0 全分布式安装
hadoop 2.2.0 cluster setup 环境: 操作系统:Centos 6.5 jdk:jdk1.7.0_51 hadoop版本:2.2.0 hostname ip master ...
- JavaScript学习系列5 ---ES6中的var, let 和const
我们都知道JavaScript中的var,在本系列的 JavaScript学习系列2一JavaScript中的变量作用域 中,我们详细阐述了var声明的变量的作用域 文章中提到,JavaScript中 ...