JobControl管理多job依赖完整示例
处理 复杂的要求的时候,有时一个mapreduce程序是完成不了的,往往需要多个mapreduce程序,这个时候就要牵扯到各个任务之间的依赖关系,所谓 依赖就是一个MR Job 的处理结果是另外的MR 的输入,以此类推,完成几个mapreduce程序,得到最后的结果
下面是用Mapreduce写的tf-idf算法微博关键字广告推送案例,总共三个job,贴出完整代码。
第一个job代码如下:
FirstMapper
import java.io.IOException;
import java.io.StringReader;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
/**
* 第一个MR,计算TF和计算
* @author root
*
*/
public class FirstMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String [] v=value.toString().trim().split("\t");//制表符隔开
if(v.length>=2){
String id=v[0].trim();
String content=v[1];
StringReader sr=new StringReader(content);
IKSegmenter ikSegmenter=new IKSegmenter(sr, true);
Lexeme word=null;
while((word=ikSegmenter.next())!=null){
String w=word.getLexemeText();
context.write(new Text(w+"_"+id),new IntWritable(1) );//某个词出现一次,输出1
}
context.write(new Text("count"), new IntWritable(1));//微博条数,每读一条输出1
}else {
System.out.println(value.toString()+"-----------------");
}
}
}
FirstPartition
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
/**
* 第一个map自定义分区
* @author root
*
*/
public class FirstPartition extends HashPartitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numReduceTasks) {
if(key.equals(new Text("count"))){
return 3;//代表第四个区,从0开始
}else{
return super.getPartition(key, value, numReduceTasks-1);
}
}
}
FirstReduce
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* C1_001,2 c1在001的微博中出现2次
* C2_002,1
* count ,1000 微博条数
* @author root
*
*/
public class FirstReduce extends Reducer<Text, IntWritable, Text,IntWritable >{
@Override
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
int sum=0;
for(IntWritable i:arg1){
//按微博分组,累加每个词在每条微博中出现的次数
sum=sum+i.get();
}
if(arg0.equals(new Text("count"))){
System.out.println(arg0.toString()+"-----"+sum);//微博总条数
}
arg2.write(arg0,new IntWritable(sum));
}
}
第二个job:
SecondMapper
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/**
* 统计df:词在多少个微博中出现过
* @author root
*
*/
public class TwoMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//获取当前mapper task 的数据片段
FileSplit fs=(FileSplit) context.getInputSplit();
if(!fs.getPath().getName().contains("part-r-00003")){//一个reduce一个文件,part-r-00003代表第四个分区生成的文件,文件内容为“count 微博条数”
//其余三个分区记录了词组在某条微博中出现的次数;
String[] v=value.toString().trim().split("\t");
if(v.length>=2){
String []ss=v[0].split("_");
if(ss.length>=2){
String word=ss[0];
context.write(new Text(word), new IntWritable(1));//词在微博中出现n次,每一条输出1
}
}else{
System.out.println(value.toString()+"---------------");
}
}
}
}
ScondReduce
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TwoReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
int sum=0;
for(IntWritable i:arg1){
sum=sum+i.get();
}
arg2.write(arg0, new IntWritable(sum));
}
}
第三个job:
ThirdMapper
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.text.NumberFormat;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/*最后计算
* @author root
*
*/
public class LastMapper extends Mapper<LongWritable,Text,Text,Text> {
// 存放微博总数
public static Map<String,Integer> cmap=null;
//存放df
public static Map<String,Integer> df=null;
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
FileSplit fs=(FileSplit) context.getInputSplit();
if(!fs.getPath().getName().endsWith("part-r-00003")){
String[] v = value.toString().trim().split("\t");
if(v.length>=2){
int tf=Integer.parseInt(v[1].trim());
String []ss=v[0].split("_");
if(ss.length>=2){
String word=ss[0];
String uid=ss[1];
double s=tf*Math.log(cmap.get("count")/df.get(word));
NumberFormat nf=NumberFormat.getInstance();
nf.setMinimumIntegerDigits(5);
context.write(new Text(uid), new Text(word+":"+nf.format(s)));
}else{
System.out.println(value.toString()+"------");
}
}
}
}
// 在map方法执行之前
@Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
System.out.println("----------------");
if(cmap==null || cmap.size()==0 || df==null || df.size()==0){
URI [] ss=context.getCacheFiles();
if(ss!=null){
for(int i=0;i<ss.length;i++){
URI uri=ss[i];
if(uri.getPath().endsWith("part-r-00003")){//该文件存放的微博的总条数
Path path=new Path(uri.getPath());
BufferedReader br=new BufferedReader(new FileReader(path.getName()));
String line=br.readLine();
if(line.startsWith("count")){
String []ls=line.split("\t");//制表符左边是count 右边是总微博数
cmap=new HashMap<String,Integer>();
cmap.put(ls[0], Integer.parseInt(ls[1].trim()));
}
br.close();
}else if(uri.getPath().endsWith("part-r-00000")){//每个次在所有微博中出现的总次数
df=new HashMap<String,Integer>();
Path path=new Path(uri.getPath());
BufferedReader br=new BufferedReader(new FileReader(path.getName()));
String line;
while((line=br.readLine())!=null){
String []ls=line.split("\t");
df.put(ls[0],Integer.parseInt(ls[1].trim()));
}
br.close();
}
}
}
}
}
}
ThirdReduce
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class LastReduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text arg0, Iterable<Text> arg1, Reducer<Text, Text, Text, Text>.Context arg2)
throws IOException, InterruptedException {
StringBuffer sb=new StringBuffer();
for(Text i:arg1){
sb.append(i.toString()+"\t");
}
arg2.write(arg0, new Text(sb.toString()));
}
}
以下是JobControl代码:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob;
import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class StarJob {
// 启动函数
public static void main(String[] args) throws IOException {
Configuration config=new Configuration();
config.set("fs.defaultFS", "hdfs://node4:8020");
FileSystem fs=FileSystem.get(config);
JobConf conf = new JobConf(StarJob.class);
// 第一个job的配置
@SuppressWarnings("deprecation")
Job job1 = new Job(conf, "join1");
job1.setJarByClass(StarJob.class);
job1.setJobName("weibo1");
job1.setMapperClass(FirstMapper.class);
job1.setCombinerClass(FirstReduce.class);
job1.setReducerClass(FirstReduce.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(IntWritable.class);
job1.setNumReduceTasks(4);
job1.setPartitionerClass(FirstPartition.class);
// 加入控制容器
ControlledJob ctrljob1 = new ControlledJob(conf);
ctrljob1.setJob(job1);
// job1的输入输出文件路径
FileInputFormat.addInputPath(job1, new Path("hdfs://node4:8020/usr/input/tf-idf"));
Path path1=new Path("hdfs://node4:8020/usr/output/weibo1");
if(fs.exists(path1)){
fs.delete(path1,true);
}
FileOutputFormat.setOutputPath(job1, path1);
// 第二个作业的配置
@SuppressWarnings("deprecation")
Job job2 = new Job(conf, "Join2");
job2.setJarByClass(StarJob.class);
job2.setJobName("weibo2");
job2.setMapperClass(TwoMapper.class);
job2.setCombinerClass(TwoReduce.class);
job2.setReducerClass(TwoReduce.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(IntWritable.class);
// 作业2加入控制容器
ControlledJob ctrljob2 = new ControlledJob(conf);
ctrljob2.setJob(job2);
// 设置多个作业直接的依赖关系
// 如下所写:
// 意思为job2的启动,依赖于job1作业的完成
ctrljob2.addDependingJob(ctrljob1);
// 输入路径是上一个作业的输出路径,因此这里填path1,要和上面对应好
FileInputFormat.addInputPath(job2, path1);
// 输出路径从新传入一个参数,这里需要注意,因为我们最后的输出文件一定要是没有出现过得
// 因此我们在这里new Path(args[2])因为args[2]在上面没有用过,只要和上面不同就可以了
Path path2=new Path("hdfs://node4:8020/usr/output/weibo2");
if(fs.exists(path2)){
fs.delete(path2,true);
}
FileOutputFormat.setOutputPath(job2, path2);
//第三个作业的配置
@SuppressWarnings("deprecation")
Job job3=new Job(conf,"join3");
job3.setJarByClass(StarJob.class);
job3.setJobName("weibo3");
// DistributedCache.addCacheFile(uri, conf);
//2.5
//把微博总数加载到内存
// job3.addCacheFile(new Path("hdfs:node4:8020/usr/output/weibo1/part-r-00003").toUri());
//把df加载到内存
// job3.addCacheFile(new Path("hdfs:node4:8020/usr/output/weibo2/part-r-00000").toUri());
job3.setOutputKeyClass(Text.class);
job3.setOutputValueClass(Text.class);
job3.setMapperClass(LastMapper.class);
job3.setReducerClass(LastReduce.class);
// 作业3加入控制容器
ControlledJob ctrljob3 = new ControlledJob(conf);
ctrljob3.setJob(job3);
ctrljob3.addDependingJob(ctrljob2);
FileInputFormat.addInputPath(job3, path2);
Path path3=new Path("hdfs://node4:8020/usr/output/weibo3");
if(fs.exists(path3)){
fs.delete(path3,true);
}
FileOutputFormat.setOutputPath(job3, path3);
// 主的控制容器,控制上面的总的3个子作业
JobControl jobCtrl = new JobControl("myctrl");
// 添加到总的JobControl里,进行控制
jobCtrl.addJob(ctrljob1);
jobCtrl.addJob(ctrljob2);
jobCtrl.addJob(ctrljob3);
// 在线程启动,记住一定要有这个
Thread t = new Thread(jobCtrl);
t.start();
while (true) {
if (jobCtrl.allFinished()) {// 如果作业成功完成,就打印成功作业的信息
System.out.println(jobCtrl.getSuccessfulJobList());
System.out.println("所有job执行完毕");
jobCtrl.stop();
break;
}
}
}
}
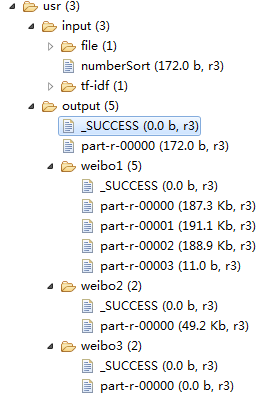
执行成功后文件下图所示
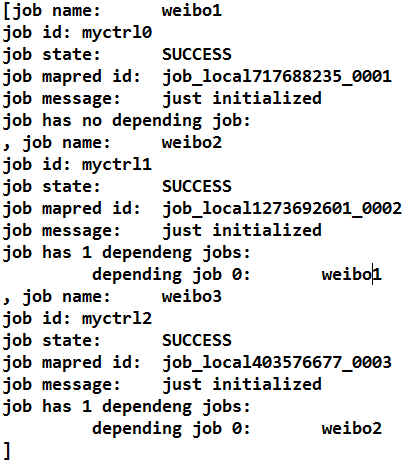
控制台打印:
JobControl管理多job依赖完整示例的更多相关文章
- Spring 3 AOP 概念及完整示例
AOP概念 AOP(Aspect Oriented Programming),即面向切面编程(也叫面向方面编程,面向方法编程).其主要作用是,在不修改源代码的情况下给某个或者一组操作添加额外的功能.像 ...
- springmvc 项目完整示例02 项目创建-eclipse创建动态web项目 配置文件 junit单元测试
包结构 所需要的jar包直接拷贝到lib目录下 然后选定 build path 之后开始写项目代码 配置文件 ApplicationContext.xml <?xml version=" ...
- eclipse 创建maven 项目 动态web工程完整示例 maven 整合springmvc整合mybatis
接上一篇: eclipse 创建maven 项目 动态web工程完整示例 eclipse maven工程自动添加依赖设置 maven工程可以在线搜索依赖的jar包,还是非常方便的 但是有的时候可能还需 ...
- Maven管理jar包依赖常出现的不能实例化类的问题
you'ji 在maven管理jar包依赖时,存在一种常见的问题. pom.xml文件配置没问题,通过eclipse里中的maven dependencies查看,也确实有这个jar 包,或者这个类. ...
- c语言智能指针 附完整示例代码
是的,你没有看错, 不是c++不是c#, 就是你认识的那个c语言. 在很长一段时间里,c的内存管理问题, 层出不穷,不是编写的时候特别费劲繁琐, 就是碰到内存泄漏排查的各种困难, 特别在多线程环境下, ...
- 【第四篇】ASP.NET MVC快速入门之完整示例(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- WCF服务开发与调用的完整示例
WCF服务开发与调用的完整示例 开发工具:VS2008 开发语言:C# 开发内容:简单的权限管理系统 第一步.建立WCF服务库 点击确定,将建立一个WCF 服务库示例程序,自动生成一个包括IServi ...
- springmvc 项目完整示例06 日志–log4j 参数详细解析 log4j如何配置
Log4j由三个重要的组件构成: 日志信息的优先级 日志信息的输出目的地 日志信息的输出格式 日志信息的优先级从高到低有ERROR.WARN. INFO.DEBUG,分别用来指定这条日志信息的重要程度 ...
- C连接MySQL数据库开发之Linux环境完整示例演示(增、删、改、查)
一.开发环境 ReadHat6.3 32位.mysql5.6.15.gcc4.4.6 二.编译 gcc -I/usr/include/mysql -L/usr/lib -lmysqlclient ma ...
随机推荐
- WebAPI 小知识
1.HttpResponseMessage.ReasonPhrase可以返回原因说明短语, 用JQuery中的$.ajax调用,返回函数第三个参数可以获取,如下: success:function(d ...
- 问题-File not "controls.res"(XE2+Win7虚拟机)
问题现象:我在Win7的虚拟机中安装XE2,前提是原来的系统上有D2007,安装后,新建个工程,F9报"File not controls.res".百思不得其解. 问题原因:因为 ...
- 异步网页采集利器CasperJs
在采集网页中,我们会经常遇到采集一些异步加载页面的网页,我们通常用的httpwebrequest类就采集不到了,这个时候我们通常会采用webbrowser来辅助采集,但是.net下自带的webbrow ...
- [iOS基础控件 - 3.4] 汤姆猫
@import url(http://i.cnblogs.com/Load.ashx?type=style&file=SyntaxHighlighter.css); @import url(/ ...
- ALM11 OTA API接口的问题
ALM11 在安装的时候好像不会自动加载OTA接口. 正常情况下, OTA的接口文件的路径为: C:\Program Files\Common Files\Mercury Interactive\Qu ...
- [五]SpringMvc学习-Restful风格实现
1.Restful风格的资源URL 无后缀资源的访问(csdn用法) 2.SpringMvc对Rest风格的支持 2.1将 /*.do改为/ 2.2 3.@PathVariable获取Url变量 @R ...
- php 接收 Content-Type 是 application/json的请求数据
工作中为其他公司编写了一个提供请求的接口,自己调试的时候是用form提交的,所以可以用$_POST取键接收方式,而对接联调的时候发现总是取不到数据,把$_POST整个序列化放入日志也是[] ,空的,于 ...
- mybatis-generator-core自动生成do、mapping、dao 代码
使用mybatis配置映射文件,有点麻烦,容易出错,可以使用jar工具自动生成代码,即高效又方便 一.下载两个jar,并放置在G:\tool\maven\generator目录下(自己定义) myba ...
- tomcat 6.0 压缩功能
官方文档: http://tomcat.apache.org/tomcat-6.0-doc/config/http.html
- iOS 根据文件名获取到文件路径
根据文件名来获取文件路径(Document目录下) //根据文件名来获取文件路径 - (NSString *)dataFilePath:(NSString *)sender { NSArray *pa ...