机器学习中的数学(3)-模型组合(Model Combining)之Boosting与Gradient Boosting
版权声明:
本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gmail.com
前言:
本来上一章的结尾提到,准备写写线性分类的问题,文章都已经写得差不多了,但是突然听说最近Team准备做一套分布式的分类器,可能会使用Random Forest来做,下了几篇论文看了看,简单的random forest还比较容易弄懂,复杂一点的还会与boosting等算法结合(参见iccv09),对于boosting也不甚了解,所以临时抱佛脚的看了看。说起boosting,强哥之前实现过一套Gradient Boosting Decision Tree(GBDT)算法,正好参考一下。
最近看的一些论文中发现了模型组合的好处,比如GBDT或者rf,都是将简单的模型组合起来,效果比单个更复杂的模型好。组合的方式很多,随机化(比如random forest),Boosting(比如GBDT)都是其中典型的方法,今天主要谈谈Gradient Boosting方法(这个与传统的Boosting还有一些不同)的一些数学基础,有了这个数学基础,上面的应用可以看Freidman的Gradient Boosting Machine。
本文要求读者学过基本的大学数学,另外对分类、回归等基本的机器学习概念了解。
本文主要参考资料是prml与Gradient Boosting Machine。
Boosting方法:
Boosting这其实思想相当的简单,大概是,对一份数据,建立M个模型(比如分类),一般这种模型比较简单,称为弱分类器(weak learner)每次分类都将上一次分错的数据权重提高一点再进行分类,这样最终得到的分类器在测试数据与训练数据上都可以得到比较好的成绩。
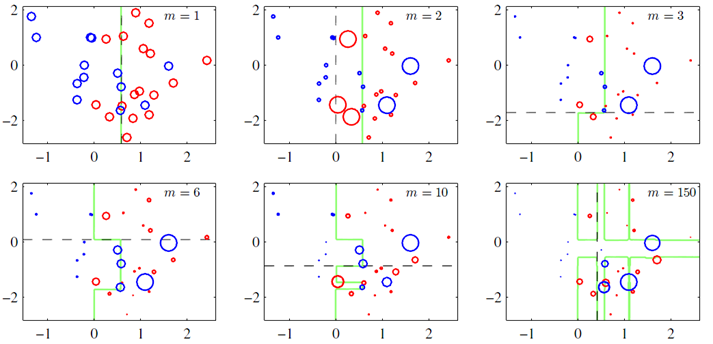
上图(图片来自prml p660)就是一个Boosting的过程,绿色的线表示目前取得的模型(模型是由前m次得到的模型合并得到的),虚线表示当前这次模型。每次分类的时候,会更关注分错的数据,上图中,红色和蓝色的点就是数据,点越大表示权重越高,看看右下角的图片,当m=150的时候,获取的模型已经几乎能够将红色和蓝色的点区分开了。
Boosting可以用下面的公式来表示: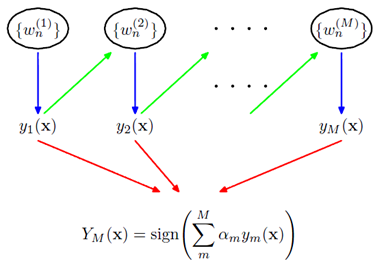
训练集中一共有n个点,我们可以为里面的每一个点赋上一个权重Wi(0 <= i < n),表示这个点的重要程度,通过依次训练模型的过程,我们对点的权重进行修正,如果分类正确了,权重降低,如果分类错了,则权重提高,初始的时候,权重都是一样的。上图中绿色的线就是表示依次训练模型,可以想象得到,程序越往后执行,训练出的模型就越会在意那些容易分错(权重高)的点。当全部的程序执行完后,会得到M个模型,分别对应上图的y1(x)…yM(x),通过加权的方式组合成一个最终的模型YM(x)。
我觉得Boosting更像是一个人学习的过程,开始学一样东西的时候,会去做一些习题,但是常常连一些简单的题目都会弄错,但是越到后面,简单的题目已经难不倒他了,就会去做更复杂的题目,等到他做了很多的题目后,不管是难题还是简单的题都可以解决掉了。
Gradient Boosting方法:
其实Boosting更像是一种思想,Gradient Boosting是一种Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向。这句话有一点拗口,损失函数(loss function)描述的是模型的不靠谱程度,损失函数越大,则说明模型越容易出错(其实这里有一个方差、偏差均衡的问题,但是这里就假设损失函数越大,模型越容易出错)。如果我们的模型能够让损失函数持续的下降,则说明我们的模型在不停的改进,而最好的方式就是让损失函数在其梯度(Gradient)的方向上下降。
下面的内容就是用数学的方式来描述Gradient Boosting,数学上不算太复杂,只要潜下心来看就能看懂:)
可加的参数的梯度表示:
假设我们的模型能够用下面的函数来表示,P表示参数,可能有多个参数组成,P = {p0,p1,p2….},F(x;P)表示以P为参数的x的函数,也就是我们的预测函数。我们的模型是由多个模型加起来的,β表示每个模型的权重,α表示模型里面的参数。为了优化F,我们就可以优化{β,α}也就是P。
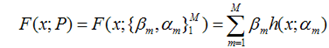
我们还是用P来表示模型的参数,可以得到,Φ(P)表示P的likelihood函数,也就是模型F(x;P)的loss函数,Φ(P)=…后面的一块看起来很复杂,只要理解成是一个损失函数就行了,不要被吓跑了。
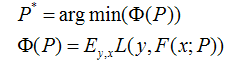 既然模型(F(x;P))是可加的,对于参数P,我们也可以得到下面的式子:
既然模型(F(x;P))是可加的,对于参数P,我们也可以得到下面的式子: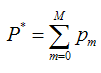 这样优化P的过程,就可以是一个梯度下降的过程了,假设当前已经得到了m-1个模型,想要得到第m个模型的时候,我们首先对前m-1个模型求梯度。得到最快下降的方向,gm就是最快下降的方向。
这样优化P的过程,就可以是一个梯度下降的过程了,假设当前已经得到了m-1个模型,想要得到第m个模型的时候,我们首先对前m-1个模型求梯度。得到最快下降的方向,gm就是最快下降的方向。
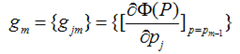 这里有一个很重要的假设,对于求出的前m-1个模型,我们认为是已知的了,不要去改变它,而我们的目标是放在之后的模型建立上。就像做事情的时候,之前做错的事就没有后悔药吃了,只有努力在之后的事情上别犯错:
这里有一个很重要的假设,对于求出的前m-1个模型,我们认为是已知的了,不要去改变它,而我们的目标是放在之后的模型建立上。就像做事情的时候,之前做错的事就没有后悔药吃了,只有努力在之后的事情上别犯错:
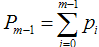 我们得到的新的模型就是,它就在P似然函数的梯度方向。ρ是在梯度方向上下降的距离。
我们得到的新的模型就是,它就在P似然函数的梯度方向。ρ是在梯度方向上下降的距离。
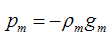 我们最终可以通过优化下面的式子来得到最优的ρ:
我们最终可以通过优化下面的式子来得到最优的ρ:
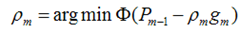
可加的函数的梯度表示:
上面通过参数P的可加性,得到了参数P的似然函数的梯度下降的方法。我们可以将参数P的可加性推广到函数空间,我们可以得到下面的函数,此处的fi(x)类似于上面的h(x;α),因为作者的文献中这样使用,我这里就用作者的表达方法:
 同样,我们可以得到函数F(x)的梯度下降方向g(x)
同样,我们可以得到函数F(x)的梯度下降方向g(x)
 最终可以得到第m个模型fm(x)的表达式:
最终可以得到第m个模型fm(x)的表达式:
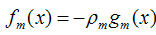
通用的Gradient Descent Boosting的框架:
下面我将推导一下Gradient Descent方法的通用形式,之前讨论过的:
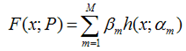 对于模型的参数{β,α},我们可以用下面的式子来进行表示,这个式子的意思是,对于N个样本点(xi,yi)计算其在模型F(x;α,β)下的损失函数,最优的{α,β}就是能够使得这个损失函数最小的{α,β}。
对于模型的参数{β,α},我们可以用下面的式子来进行表示,这个式子的意思是,对于N个样本点(xi,yi)计算其在模型F(x;α,β)下的损失函数,最优的{α,β}就是能够使得这个损失函数最小的{α,β}。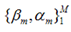 表示两个m维的参数:
表示两个m维的参数:
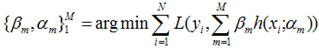 写成梯度下降的方式就是下面的形式,也就是我们将要得到的模型fm(x)的参数{αm,βm}能够使得fm的方向是之前得到的模型Fm-1(x)的损失函数下降最快的方向:
写成梯度下降的方式就是下面的形式,也就是我们将要得到的模型fm(x)的参数{αm,βm}能够使得fm的方向是之前得到的模型Fm-1(x)的损失函数下降最快的方向:
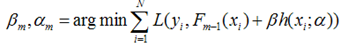
对于每一个数据点xi都可以得到一个gm(xi),最终我们可以得到一个完整梯度下降方向
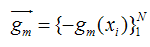
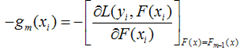 为了使得fm(x)能够在gm(x)的方向上,我们可以优化下面的式子得到,可以使用最小二乘法:
为了使得fm(x)能够在gm(x)的方向上,我们可以优化下面的式子得到,可以使用最小二乘法:
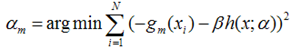 得到了α的基础上,然后可以得到βm。
得到了α的基础上,然后可以得到βm。 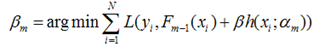 最终合并到模型中:
最终合并到模型中:
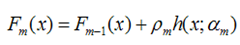
算法的流程图如下
 之后,作者还说了这个算法在其他的地方的推广,其中,Multi-class logistic regression and classification就是GBDT的一种实现,可以看看,流程图跟上面的算法类似的。这里不打算继续写下去,再写下去就成论文翻译了,请参考文章:Greedy function Approximation – A Gradient Boosting Machine,作者Freidman。
之后,作者还说了这个算法在其他的地方的推广,其中,Multi-class logistic regression and classification就是GBDT的一种实现,可以看看,流程图跟上面的算法类似的。这里不打算继续写下去,再写下去就成论文翻译了,请参考文章:Greedy function Approximation – A Gradient Boosting Machine,作者Freidman。
总结:
本文主要谈了谈Boosting与Gradient Boosting的方法,Boosting主要是一种思想,表示“知错就改”。而Gradient Boosting是在这个思想下的一种函数(也可以说是模型)的优化的方法,首先将函数分解为可加的形式(其实所有的函数都是可加的,只是是否好放在这个框架中,以及最终的效果如何)。然后进行m次迭代,通过使得损失函数在梯度方向上减少,最终得到一个优秀的模型。值得一提的是,每次模型在梯度方向上的减少的部分,可以认为是一个“小”的或者“弱”的模型,最终我们会通过加权(也就是每次在梯度方向上下降的距离)的方式将这些“弱”的模型合并起来,形成一个更好的模型。
有了这个Gradient Descent这个基础,还可以做很多的事情。也在机器学习的道路上更进一步了:)
机器学习中的数学(3)-模型组合(Model Combining)之Boosting与Gradient Boosting的更多相关文章
- 模型组合(Model Combining)之Boosting与Gradient Boosting
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- 机器学习中的数学-线性判别分析(LDA)
前言在之前的一篇博客机器学习中的数学(7)——PCA的数学原理中深入讲解了,PCA的数学原理.谈到PCA就不得不谈LDA,他们就像是一对孪生兄弟,总是被人们放在一起学习,比较.这这篇博客中我们就来谈谈 ...
- 机器学习:集成学习(Ada Boosting 和 Gradient Boosting)
一.集成学习的思路 共 3 种思路: Bagging:独立的集成多个模型,每个模型有一定的差异,最终综合有差异的模型的结果,获得学习的最终的结果: Boosting(增强集成学习):集成多个模型,每个 ...
- 机器学习中的算法——决策树模型组合之随机森林与GBDT
前言: 决策树这种算法有着很多良好的特性,比如说训练时间复杂度较低,预测的过程比较快速,模型容易展示(容易将得到的决策树做成图片展示出来)等.但是同时,单决策树又有一些不好的地方,比如说容易over- ...
- 机器学习中的算法-决策树模型组合之随机森林与GBDT
机器学习中的算法(1)-决策树模型组合之随机森林与GBDT 版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使 ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- 机器学习中的数学-矩阵奇异值分解(SVD)及其应用
转自:http://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html 版权声明: 本文由LeftNotE ...
- 机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- 机器学习中的数学-强大的矩阵奇异值分解(SVD)及其应用
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
随机推荐
- class卸载、热替换和Tomcat的热部署的分析
一 class的热替换 ClassLoader中重要的方法 loadClassClassLoader.loadClass(...) 是ClassLoader的入口点.当一个类没有指明用什么加载器加载的 ...
- AXURE制作APP抽屉式菜单
1.拖一个dynamic panel到窗体,将State1改名为State_首页: 2.拖2个dynamic panel到State_首页中,分别命名为侧边菜单及首页内容,首页内容盖住侧边菜单: 3. ...
- objectC时间用法
#define kDEFAULT_DATE_TIME_FORMAT (@"yyyy-MM-dd HH:mm:ss") //获取当前日期,时间+(NSDate *)getCurren ...
- /usr/lib/libstdc++.so.6: version `GLIBCXX_3.4.15' not found错误的解决
升级cmake时,提示"Error when bootstrapping CMake:Problem while running initial CMake",第二次运行./boo ...
- [HDOJ3974]Assign the task(建树胡搞)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3974 出现在窝bin的线段树专题里…第一时间想的是记录入度找出根节点,然后标记深度转换到线段树中.但是 ...
- hdu 4882 ZCC Loves Codefires (贪心 推导)
题目链接 做题的时候凑的规律,其实可以 用式子推一下的. 题意:n对数,每对数有e,k, 按照题目的要求(可以看下面的Hint就明白了)求最小的值. 分析:假设现在总的是sum, 有两个e1 k1 e ...
- ASP.NET MVC 学习5、登陆页面改为SSO验证
单点登录(SSO,single sign-on)是一个会话或用户身份验证过程,用户只需要登录一次就可以访问所有相互信任的应用系统,二次登录时无需重新输入用户名和密码.简化账号登录过程并保护账号和密码安 ...
- UVa 12304 (6个二维几何问题合集) 2D Geometry 110 in 1!
这个题能1A纯属运气,要是WA掉,可真不知道该怎么去调了. 题意: 这是完全独立的6个子问题.代码中是根据字符串的长度来区分问题编号的. 给出三角形三点坐标,求外接圆圆心和半径. 给出三角形三点坐标, ...
- hdu 4617 Weapon(叉积)
大一学弟表示刚学过高数,轻松无压力. 我等学长情何以堪= = 求空间无限延伸的两个圆柱体是否相交,其实就是叉积搞一搞 详细点就是求两圆心的向量在两直线(圆心所在的直线)叉积上的投影 代码略挫,看他的吧 ...
- BZOJ3540: [Usaco2014 Open]Fair Photography
3540: [Usaco2014 Open]Fair Photography Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 72 Solved: 29 ...