postgres 数据库 citus 集群分片
前言
什么时候需要考虑做数据切分?
1、能不切分尽量不要切分
- 并不是所有表都需要进行切分,主要还是看数据的增长速度。切分后会在某种程度上提升业务的复杂度,数据库除了承载数据的存储和查询外,协助业务更好的实现需求也是其重要工作之一。
- 不到万不得已不用轻易使用分库分表这个大招,避免"过度设计"和"过早优化"。分库分表之前,不要为分而分,先尽力去做力所能及的事情,例如:升级硬件、升级网络、读写分离、索引优化等等。当数据量达到单表的瓶颈时候,再考虑分库分表。
2、数据量过大,正常运维影响业务访问
这里说的运维,指:
- 对数据库备份,如果单表太大,备份时需要大量的磁盘IO和网络IO。例如1T的数据,网络传输占50MB时候,需要20000秒才能传输完毕,整个过程的风险都是比较高的
- 对一个很大的表进行DDL修改时,会锁住全表,这个时间会很长,这段时间业务不能访问此表,影响很大。在此操作过程中,都算为风险时间。将数据表拆分,总量减少,有助于降低这个风险。
- 大表会经常访问与更新,就更有可能出现锁等待。将数据切分,用空间换时间,变相降低访问压力
3、随着业务发展,需要对某些字段垂直拆分
举个例子,假如项目一开始设计的用户表如下:
id bigint #用户的ID
name varchar #用户的名字
last_login_time datetime #最近登录时间
personal_info text #私人信息
….. #其他信息字段
在项目初始阶段,这种设计是满足简单的业务需求的,也方便快速迭代开发。而当业务快速发展时,用户量从10w激增到10亿,用户非常的活跃,每次登录会更新 last_login_name 字段,使得 user 表被不断update,压力很大。而其他字段:id, name, personal_info 是不变的或很少更新的,此时在业务角度,就要将 last_login_time 拆分出去,新建一个 user_time 表。
personal_info 属性是更新和查询频率较低的,并且text字段占据了太多的空间。这时候,就要对此垂直拆分出 user_ext 表了。
4、数据量快速增长
- 随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。此时一定要选择合适的切分规则,提前预估好数据容量
5、安全性和可用性
鸡蛋不要放在一个篮子里。在业务层面上垂直切分,将不相关的业务的数据库分隔,因为每个业务的数据量、访问量都不同,不能因为一个业务把数据库搞挂而牵连到其他业务。利用水平切分,当一个数据库出现问题时,不会影响到100%的用户,每个库只承担业务的一部分数据,这样整体的可用性就能提高。
6、索引效率
随着数据量的增加,通过辅助索引查找的数据越来越多,大部分是需要进行回表操作,不能直接通过辅助索引找到数据,当数据量非常大时,回表查找将会消耗大量的时间,由于Oracle,MySQL,Postgresql查询优化器是基于cost代价模型来设计的,当查询返回值大于一定比例,执行优化器会选择走全表扫描
Citus能够横向扩展多租户(b2b)数据库,或者构建实时应用程序。citus使用分片,复制,查询并行化扩展postgres跨服务器来实现这一点,它是以前 pg_shard的升级版本。
Citus适用两种应用场景,这两种应用场景对应两种数据模型:对租户对应程序和实时分析
多租户适用于B2B应用场景。
一. 安装citus集群
有关苏宁易购的citus:
|
IP |
操作系统 |
端口 |
Citus版本 |
|
192.168.10.41 /master |
CentOS release 6.10 |
5432 |
7.2 |
|
192.168.10.51/woker |
CentOS release 6.10 |
5433 |
7.2 |
|
192.168.10.61/woker |
CentOS release 6.10 |
5434 |
7.2 |
步骤在所有节点上执行(我是root身份执行的)
curl https://install.citusdata.com/community/rpm.sh | sudo bash
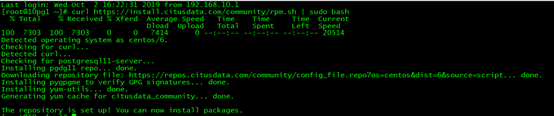
yum install -y citus72_10
##yum install -y citus83_11 (我安装10的版本)

配置postgres环境变量
集群官方网站来自:
https://docs.citusdata.com/en/stable/installation/multi_machine_rhel.html
单机:https://docs.citusdata.com/en/stable/installation/single_machine_rhel.html
以下是三台都需要操作的步骤
实例初始化:
service postgresql-10 initdb || sudo /usr/pgsql-10/bin/postgresql-10-setup initdb

修改vi /var/lib/pgsql/10/data/postgresql.conf配置,加入以下内容:
shared_preload_libraries='citus'
如果又多个shared_proload_librarues,shared_preload_libraries='citus'排在第一。
修改其他参数,比如监听参数。
并且修改pg_hba.conf 参数(加入以下)。
hostnossl all all 0.0.0.0/0 trust
启动postgres-10
service postgresql-10 start
chkconfig postgresql-10 on

配置环境变量:
export PATH=/usr/pgsql-10/bin:$PATH:
查看安装的数据库:
psql -p5432
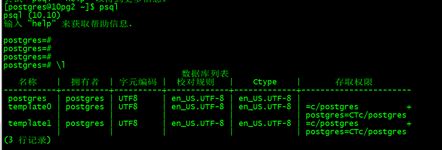
create extension citus;

select * from pg_extension ;

二. 在协调节点(主节点)上执行的步骤
a. 节点常规操作
SELECT * from master_add_node('192.168.10.51',5433);
SELECT * from master_add_node('192.168.10.61',5434);
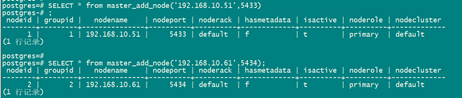
查看添加的节点:
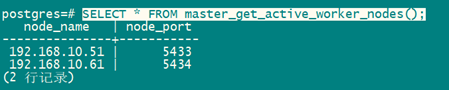
SELECT * FROM master_get_active_worker_nodes();
如果需要时删除节点:
比如说删除61 5434:
SELECT * from master_remove_node('192.168.10.61',5434);
查看:

已经删除了,只剩一个了。
禁用某个节点:
select master_disable_node('192.168.10.51',5433);

只看导5434端口的节点了,5433的没有活动。
重新启用节点:
select master_activate_node('192.168.10.51',5433);


b. 分布式集群测试
建立分布式表:
注意,cutis不能够创建数据库:
create database test; 需要所有节点创建数据库
create extension citus; 并且数据库创建插件
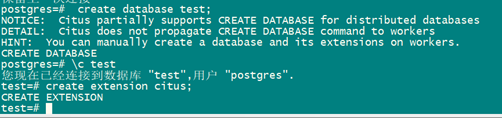
主节点上操作:
create table test(id int, name varchar(16));
查看默认分片数:
show citus.shard_count;
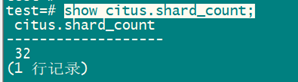
默认分片数是32,默认是采用hash mod 的分布方式,可以根绝实际情况进行调整,查了很多资料,官方建议OLTP场景(带分片字段SQL)小负载(小于100GB)32;大负载64或128;个人比较赞同的是:cpu核数*物理节点的分片数*物理节点数
将表test 分片(主库)
SELECT master_create_distributed_table('test', 'id', 'hash');

设定分片个数(2)以及每个分片副本数(2)
SELECT master_create_worker_shards('test', 2, 2);

执行完后查看节点表:
主节点:
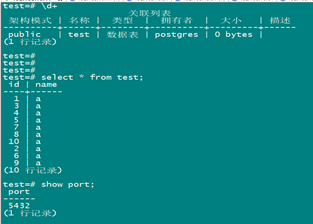
可以看出来,数据全部再子节点
节点2:
节点3:
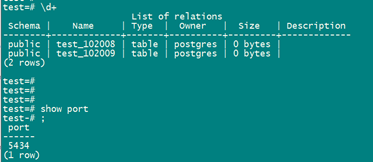
比如我插入10条数据:
主节点
insert into test select *,'a' from generate_series(1,10);
发现工作节点两便都是:
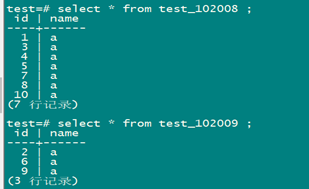
insert into test select id+10,name from test;
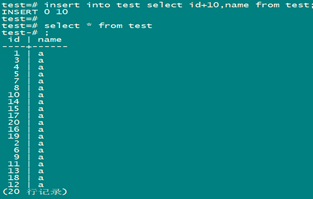
建索引:
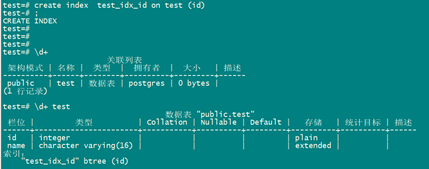
子节点:

c. Citus参数以及试图
查看试图:

有关参数,大多数的常用的都是
pg_dist_ 前缀的参数。
查看元数据的几个试图:
pg_dist_partition
pg_dist_shard
pg_dist_shard_placement
参数:
set citus.enable_repartition_joins = on
这个可以开启,开启分片表的亲和,可以优化设计夺标的sql和事务,也支持sql下推。
“Citus Maintenance Daemon”进程自动检测和处理分布式死锁。
citus.shard_replication_factor 分片的副本,默认值1
citus.shard_count 分偏数量 默认值32
citus.task_executor_type 它值为real-time 和task-tracker,默认为real-time,在跨多个分片的聚合和共同定位连接的查询性能最好。
idle_in_transaction_session_timeout 未防止连接资源被耗尽,可以进行设置事务连接时间,默认毫秒。
查看根据对应的分零篇键值,查找分片:
select get_shard_id_for_distribution_column('t',100);

Id=100的值分片为t_102018
查看创建分片函数:
create_distributed_table

d. Citus故障测试
如果主节点服务器坏点怎么处理?
哈哈,这个最开始架构选取的时候,就应该设置主备模式,利用VIP,主节点的citus换掉了,备节点接管服务。
其他节点点服务器down掉
模拟 51节点down 掉,主节点有数据进行插入。
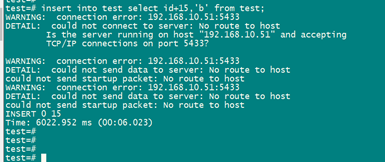
插入数据的时候,有提示51上异常,但是还是插入成功了。
起来之后,查看分片的情况:
SELECT * from pg_dist_shard_placement order by shardid, placementid;
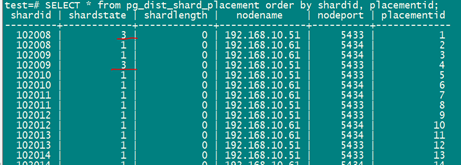
明显应该都是1的,直接把节点2,102008,102009 这两个重新同步一下
主节点执行:
把节点3的数据拷贝导节点2,主节点执行:
SELECT master_copy_shard_placement(102008, '192.168.10.61', 5434, '192.168.10.51', 5433);
SELECT master_copy_shard_placement(102009, '192.168.10.61', 5434, '192.168.10.51', 5433);

子节点:

主节点:
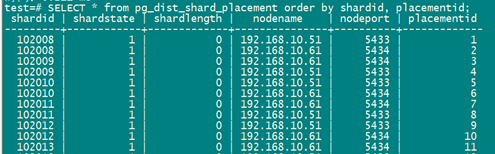
已经同步正常。
postgres 数据库 citus 集群分片的更多相关文章
- mongodb集群+分片部署(二)
机器:10.165.38.68 10.165.38.72 部署包:mongodb-linux-x86_64-rhel55-3.0.2.tgz(百度云盘下载地址:http://pan.baidu. ...
- Akka-Cluster(6)- Cluster-Sharding:集群分片,分布式交互程序核心方式
在前面几篇讨论里我们介绍了在集群环境里的一些编程模式.分布式数据结构及具体实现方式.到目前为止,我们已经实现了把程序任务分配给处于很多服务器上的actor,能够最大程度的利用整体系统的硬件资源.这是因 ...
- MySQL数据库企业集群项目实战(阶段三)
MySQL数据库企业集群项目实战(阶段三) 作者 刘畅 时间 2020-10-25 目录 1 架构拓扑图 1 1.1 方案一 1 1.2 方案二 2 ...
- 云原生分布式 PostgreSQL+Citus 集群在 Sentry 后端的实践
优化一个分布式系统的吞吐能力,除了应用本身代码外,很大程度上是在优化它所依赖的中间件集群处理能力.如:kafka/redis/rabbitmq/postgresql/分布式存储(CephFS,Juic ...
- 怎样加快master数据库的写操作?分表原则!将表水平划分!或者添加写数据库的集群
1.怎样加快master数据库的写操作?分表原则!将表水平划分!减少表的锁定时间!!! 或者或者添加写数据库的集群!!!或者添加写数据库的集群!!! 2.既然分表了,就一定要注意分表的规则!要在代码层 ...
- Akka(13): 分布式运算:Cluster-Sharding-运算的集群分片
通过上篇关于Cluster-Singleton的介绍,我们了解了Akka为分布式程序提供的编程支持:基于消息驱动的运算模式特别适合分布式程序编程,我们不需要特别的努力,只需要按照普通的Actor编程方 ...
- Deinstall卸载RAC之Oracle软件及数据库+GI集群软件
Deinstall卸载Oracle软件及数据库+GI集群软件 1. 本篇文档应用场景: 需要安装新的ORACLE RAC产品,系统没有重装,需要对原环境中的RAC进行卸载: #本篇文档,在AIX 6. ...
- 针对多类型数据库,集群数据库的有序GUID
一.背景 常见的一种数据库设计是使用连续的整数为做主键,当新的数据插入到数据库时,由数据库自动生成.但这种设计不一定适合所有场景. 随着越来越多的使用Nhibernate.EntityFramewor ...
- Akka Cluster之集群分片
一.介绍 当您需要在集群中的多个节点之间分配Actor,并希望能够使用其逻辑标识符与它们进行交互时,集群分片是非常有用的.你无需关心Actor在集群中的物理位置,因为这可能也会随着时间的推移而发生变 ...
随机推荐
- HDU - 2824 The Euler function 欧拉函数筛 模板
HDU - 2824 题意: 求[a,b]间的欧拉函数和.这道题卡内存,只能开一个数组. 思路: ϕ(n) = n * (p-1)/p * ... 可利用线性筛法求出所有ϕ(n) . #include ...
- lightoj 1095 - Arrange the Numbers(dp+组合数)
题目链接:http://www.lightoj.com/volume_showproblem.php?problem=1095 题解:其实是一道简单的组合数只要推导一下错排就行了.在这里就推导一下错排 ...
- kmp算法学习 与 传参试验(常回来看看)
之前在codeforces上做了一道类似KMP的题目,但由于之前没有好好掌握,现在又基本忘记,并没能解答.下面是对KMP算法的一点小总结. 首先KMP算法的核心是纸在匹配过程中,利用模式串的前后缀来加 ...
- 什么是WSGI
WSGI全称为Python Web Server Gateway Interface,Python Web服务器网关接口,它是介于Web服务器和Web应用程序(或Web框架)之间的一种简单而通用的接口 ...
- SpringCloud Feign 之 Fallback初体验
SpringCloud Feign 之 Fallback初体验 在微服务框架SpringCloud中,Feign是其中非常重要且常用的组件.Feign是声明式,模板化的HTTP客户端,可以帮助我们更方 ...
- 【Windows】PostgreSql安装
Installer安装包问题 Problem running post-install step. Installation may not complete correctly. The datab ...
- MicroPython TPYBoard v102 无线红外遥控舵机(基于红外解/编码模块)
转载请注明文章来源,更多教程可自助参考docs.tpyboard.com,QQ技术交流群:157816561,公众号:MicroPython玩家汇 红外解码/编码模块介绍 模块上搭载了红外接收头.红外 ...
- Disruptor中shutdown方法失效,及产生的不确定性源码分析
版权声明:原创作品,谢绝转载!否则将追究法律责任. Disruptor框架是一个优秀的并发框架,利用RingBuffer中的预分配内存实现内存的可重复利用,降低了GC的频率. 具体关于Disrupto ...
- 【Offer】[47] 【礼物的最大价值】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 在一个m*n的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于0).你可以从棋盘的左上角开始拿格子里的礼物,并每次向左(以自 ...
- 解决go get下载包失败问题
由于某些不可抗力的原因,国内使用go get命令安装包时会经常会出现timeout的问题.本文介绍几个常用的解决办法. 从github克隆 golang在github上建立了一个镜像库,如https: ...