Android 项目优化(三):MultiDex 优化
在整理MultiDex优化之前,先了解一下Apk的编译流程,这样有助于后面针对MultiDex优化。
一、Apk 编译流程
Android Studio 按下编译按钮后发生了什么?
1. 打包资源文件,生成R.java文件(使用工具aapt,这个工具在Android 使用 aapt 命令查看 apk 包名 提到过,感兴趣的可以了解一下)
2. 处理aidl文件,生成java代码(没有aidl 则忽略)
3. 编译 java 文件,生成对应.class文件(java compiler)
4. class 文件转换成dex文件(dex)
5. 打包成没有签名的apk(使用工具apkbuilder)
6. 使用签名工具给apk签名(使用工具Jarsigner)
在第4步,将class文件转换成dex文件,默认只会生成一个dex文件,单个dex文件中的方法数不能超过65536,不然编译会报错,但是我们在开发App时肯定会集成一堆库,方法数一般都是超过65536的,解决这个问题的办法就是:一个dex装不下,用多个dex来装,gradle增加一行配置:multiDexEnabled true。
具体配置方案可以参考:Android 分包 MultiDex 策略总结。
二、MultiDex 原理
虽然配置好了MultiDex分包策略,但是我们发现在Android 4.4 的手机上仅执行 MultiDex.install(context) 就可能消耗1秒多的时间,那么为什么会这么耗时呢?这里先分析一下MultiDex的原理。
2.1 MultiDex 原理
首先我们来看一下MultiDex.install()方法具体执行的内容:
public static void install(Context context) {
Log.i("MultiDex", "Installing application");
if (IS_VM_MULTIDEX_CAPABLE) { //5.0 以上VM基本支持多dex,啥事都不用干
Log.i("MultiDex", "VM has multidex support, MultiDex support library is disabled.");
} else if (VERSION.SDK_INT < 4) { //
throw new RuntimeException("MultiDex installation failed. SDK " + VERSION.SDK_INT + " is unsupported. Min SDK version is " + 4 + ".");
} else {
...
doInstallation(context, new File(applicationInfo.sourceDir), new File(applicationInfo.dataDir), "secondary-dexes", "", true);
...
Log.i("MultiDex", "install done");
}
}
从上面的源码可以看到,如果虚拟机本身就支持加载多个dex文件,那就啥都不用做;如果是不支持加载多个dex(5.0以下是不支持的),则走到 doInstallation 方法。
private static void doInstallation(Context mainContext, File sourceApk, File dataDir, String secondaryFolderName, String prefsKeyPrefix, boolean reinstallOnPatchRecoverableException) throws IOException, IllegalArgumentException, IllegalAccessException, NoSuchFieldException, InvocationTargetException, NoSuchMethodException, SecurityException, ClassNotFoundException, InstantiationException {
//获取非主dex文件
File dexDir = getDexDir(mainContext, dataDir, secondaryFolderName);
MultiDexExtractor extractor = new MultiDexExtractor(sourceApk, dexDir);
IOException closeException = null;
try {
// 1. 这个load方法,第一次没有缓存,会非常耗时
List files = extractor.load(mainContext, prefsKeyPrefix, false);
try {
//2. 安装dex
installSecondaryDexes(loader, dexDir, files);
}
}
}
看一下 1. MultiDexExtractor#load 具体都执行了哪些内容:
List<? extends File> load(Context context, String prefsKeyPrefix, boolean forceReload) throws IOException {
if (!this.cacheLock.isValid()) {
throw new IllegalStateException("MultiDexExtractor was closed");
} else {
List files;
if (!forceReload && !isModified(context, this.sourceApk, this.sourceCrc, prefsKeyPrefix)) {
try {
//读缓存的dex
files = this.loadExistingExtractions(context, prefsKeyPrefix);
} catch (IOException var6) {
Log.w("MultiDex", "Failed to reload existing extracted secondary dex files, falling back to fresh extraction", var6);
//读取缓存的dex失败,可能是损坏了,那就重新去解压apk读取,跟else代码块一样
files = this.performExtractions();
//保存标志位到sp,下次进来就走if了,不走else
putStoredApkInfo(context, prefsKeyPrefix, getTimeStamp(this.sourceApk), this.sourceCrc, files);
}
} else {
//没有缓存,解压apk读取
files = this.performExtractions();
//保存dex信息到sp,下次进来就走if了,不走else
putStoredApkInfo(context, prefsKeyPrefix, getTimeStamp(this.sourceApk), this.sourceCrc, files);
}
Log.i("MultiDex", "load found " + files.size() + " secondary dex files");
return files;
}
}
查找dex文件,有两个逻辑,有缓存就调用loadExistingExtractions方法,没有缓存或者缓存读取失败就调用performExtractions方法,然后再缓存起来。使用到缓存,那么performExtractions 方法想必应该是很耗时的,分析一下代码:
private List<MultiDexExtractor.ExtractedDex> performExtractions() throws IOException {
//先确定命名格式
String extractedFilePrefix = this.sourceApk.getName() + ".classes";
this.clearDexDir();
List<MultiDexExtractor.ExtractedDex> files = new ArrayList();
ZipFile apk = new ZipFile(this.sourceApk); // apk转为zip格式
try {
int secondaryNumber = ;
//apk已经是改为zip格式了,解压遍历zip文件,里面是dex文件,
//名字有规律,如classes1.dex,class2.dex
for(ZipEntry dexFile = apk.getEntry("classes" + secondaryNumber + ".dex"); dexFile != null; dexFile = apk.getEntry("classes" + secondaryNumber + ".dex")) {
//文件名:xxx.classes1.zip
String fileName = extractedFilePrefix + secondaryNumber + ".zip";
//创建这个classes1.zip文件
MultiDexExtractor.ExtractedDex extractedFile = new MultiDexExtractor.ExtractedDex(this.dexDir, fileName);
//classes1.zip文件添加到list
files.add(extractedFile);
Log.i("MultiDex", "Extraction is needed for file " + extractedFile);
int numAttempts = ;
boolean isExtractionSuccessful = false;
while(numAttempts < && !isExtractionSuccessful) {
++numAttempts;
//这个方法是将classes1.dex文件写到压缩文件classes1.zip里去,最多重试三次
extract(apk, dexFile, extractedFile, extractedFilePrefix);
...
}
//返回dex的压缩文件列表
return files;
}
这里的逻辑就是解压apk,遍历出里面的dex文件,例如class1.dex,class2.dex,然后又压缩成class1.zip,class2.zip...,然后返回zip文件列表。
只有第一次加载才会执行解压和压缩过程,第二次进来读取sp中保存的dex信息,直接返回file list,所以第一次启动的时候比较耗时。dex文件列表找到了,回到上面MultiDex#doInstallation方法的注释2,找到的dex文件列表,然后调用installSecondaryDexes方法进行安装,怎么安装呢?方法点进去看SDK 19 以上的实现:
private static final class V19 {
private V19() {
}
static void install(ClassLoader loader, List<? extends File> additionalClassPathEntries, File optimizedDirectory) throws IllegalArgumentException, IllegalAccessException, NoSuchFieldException, InvocationTargetException, NoSuchMethodException, IOException {
Field pathListField = MultiDex.findField(loader, "pathList");//1 反射ClassLoader 的 pathList 字段
Object dexPathList = pathListField.get(loader);
ArrayList<IOException> suppressedExceptions = new ArrayList();
// 2 扩展数组
MultiDex.expandFieldArray(dexPathList, "dexElements", makeDexElements(dexPathList, new ArrayList(additionalClassPathEntries), optimizedDirectory, suppressedExceptions));
...
}
private static Object[] makeDexElements(Object dexPathList, ArrayList<File> files, File optimizedDirectory, ArrayList<IOException> suppressedExceptions) throws IllegalAccessException, InvocationTargetException, NoSuchMethodException {
Method makeDexElements = MultiDex.findMethod(dexPathList, "makeDexElements", ArrayList.class, File.class, ArrayList.class);
return (Object[])((Object[])makeDexElements.invoke(dexPathList, files, optimizedDirectory, suppressedExceptions));
}
}
1. 反射ClassLoader 的 pathList 字段
2. 找到pathList 字段对应的类的makeDexElements 方法
3. 通过MultiDex.expandFieldArray 这个方法扩展 dexElements 数组,怎么扩展?看下代码:
private static void expandFieldArray(Object instance, String fieldName, Object[] extraElements) throws NoSuchFieldException, IllegalArgumentException, IllegalAccessException {
Field jlrField = findField(instance, fieldName);
Object[] original = (Object[])((Object[])jlrField.get(instance)); //取出原来的dexElements 数组
Object[] combined = (Object[])((Object[])Array.newInstance(original.getClass().getComponentType(), original.length + extraElements.length)); //新的数组
System.arraycopy(original, 0, combined, 0, original.length); //原来数组内容拷贝到新的数组
System.arraycopy(extraElements, 0, combined, original.length, extraElements.length); //dex2、dex3...拷贝到新的数组
jlrField.set(instance, combined); //将dexElements 重新赋值为新的数组
}
就是创建一个新的数组,把原来数组内容(主dex)和要增加的内容(dex2、dex3...)拷贝进去,反射替换原来的dexElements为新的数组,如下图:
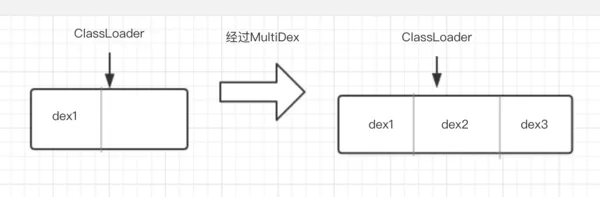
Tinker热修复的原理也是通过反射将修复后的dex添加到这个dex数组去,不同的是热修复是添加到数组最前面,而MultiDex是添加到数组后面。这样讲可能还不是很好理解?来看看ClassLoader怎么加载一个类的就明白了~
2.2 ClassLoader 加载类原理
不管是 PathClassLoader还是DexClassLoader,都继承自BaseDexClassLoader,加载类的代码在 BaseDexClassLoader中,具体文件路径如下:/dalvik/src/main/java/dalvik/system/BaseDexClassLoader.java。
代码如图:
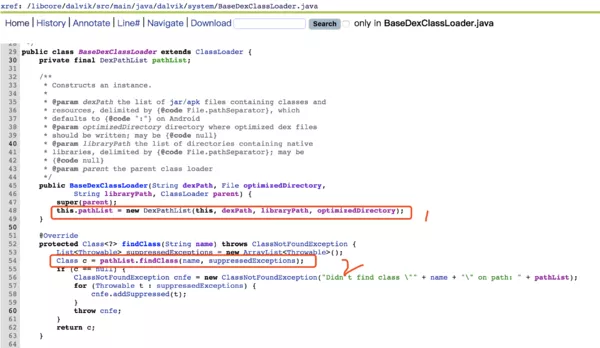
1.构造方法通过传入dex路径,创建了DexPathList。
2. ClassLoader的findClass方法最终是调用DexPathList 的findClass方法
接下来看一下DexPathList源码/dalvik/src/main/java/dalvik/system/DexPathList.java

DexPathList里面定义了一个dexElements 数组,findClass方法中用到,看下
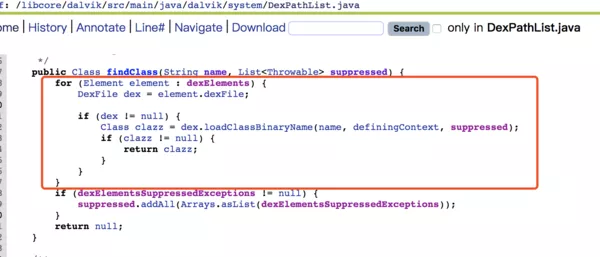
findClass方法逻辑很简单,就是遍历dexElements 数组,拿到里面的DexFile对象,通过DexFile的loadClassBinaryName方法加载一个类。
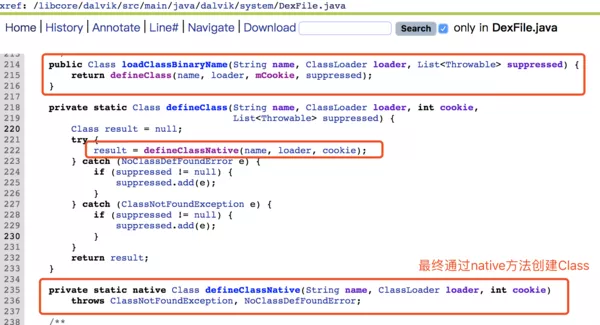
最终创建Class是通过native方法,就不追下去了,大家有兴趣可以看下native层是怎么创建Class对象的。
那么问题来了,5.0以下这个dexElements 里面只有主dex(可以认为是一个bug),没有dex2、dex3...,MultiDex是怎么把dex2添加进去呢?
答案就是反射DexPathList的dexElements字段,然后把dex2添加进去,当然,dexElements里面放的是Element对象,只有dex2的路径,必须转换成Element格式才行,所以反射DexPathList里面的makeDexElements 方法,将dex文件转换成Element对象即可。

dex2、dex3...通过makeDexElements方法转换成要新增的Element数组,最后一步就是反射DexPathList的dexElements字段,将原来的Element数组和新增的Element数组合并,然后反射赋值给dexElements变量,最后DexPathList的dexElements变量就包含新加的dex在里面了。
makeDexElements方法会判断file类型,上面讲dex提取的时候解压apk得到dex,然后又将dex压缩成zip,压缩成zip,就会走到第二个判断里去。仔细想想,其实dex不压缩成zip,走第一个判断也没啥问题吧,那谷歌的MultiDex为什么要将dex压缩成zip呢?
在Android开发高手课中看到张绍文也提到这一点:
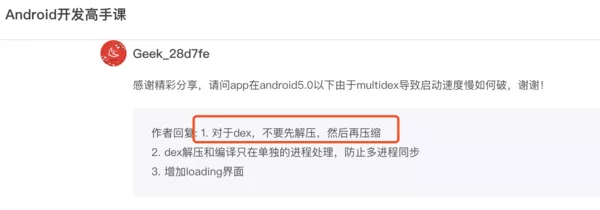
也就是说,这个压缩过程是多余的,后面我们会介绍一下头条App参考谷歌的MultiDex优化这个多余的压缩过程,后续会介绍一下头条的方案。
这里我们先总结一下ClassLoader的加载原理 <==> ClassLoader.loadClass -> DexPathList.loadClass -> 遍历dexElements数组 ->DexFile.loadClassBinaryName。
通俗点说就是:ClassLoader加载类的时候是通过遍历dex数组,从dex文件里面去加载一个类,加载成功就返回,加载失败则抛出Class Not Found 异常。
2.3 MultiDex原理总结
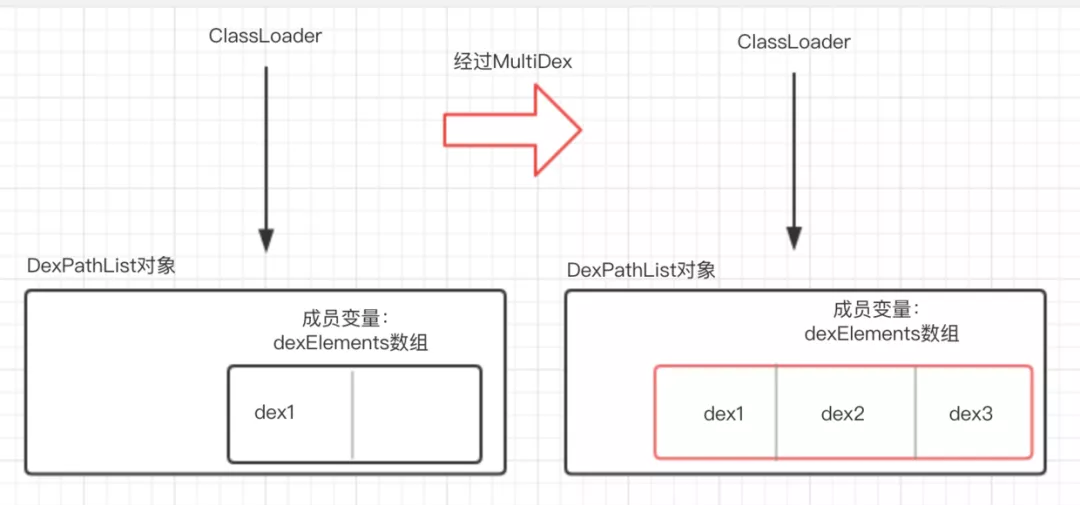
在明白ClassLoader加载类原理之后,我们可以通过反射dexElements数组,将新增的dex添加到数组后面,这样就保证ClassLoader加载类的时候可以从新增的dex中加载到目标类,经过分析后最终整理出来的原理图如下:
三、MultiDex 优化
我们了解了MultiDex原理之后,就应该考虑如何优化MultiDex了。
MultiDex的优化的重点在于解决install过程耗时,耗时的原因主要是涉及到解压apk取出dex、压缩dex、将dex文件通过反射转换成DexFile对象、反射替换数组。
想到优化此耗时问题,首先我们会想到异步,也就是开启一个子线程执行install操作,但是这样做真的可行吗?实践过后就发现,方案存在很大的问题。
3.1 子线程install(不推荐)
这个方案的思路为:在闪屏页开一个子线程去执行MultiDex.install,然后加载完才跳转到主页。需要注意的是闪屏页的Activity,包括闪屏页中引用到的其它类必须在主dex中,不然在MultiDex.install之前加载这些不在主dex中的类会报错Class Not Found。
如何保证闪屏页在主dex里面呢?这里我们可以使用Gradle来配置:
defaultConfig {
//分包,指定某个类在main dex
multiDexEnabled true
multiDexKeepProguard file('multiDexKeep.pro') // 打包到main dex的这些类的混淆规制,没特殊需求就给个空文件
multiDexKeepFile file('maindexlist.txt') // 指定哪些类要放到main dex
}
maindexlist.txt 文件指定哪些类要打包到主dex中,内容格式如下
com/lanshifu/launchtest/SplashActivity.class
但是,真正在已有项目中用使用这种方式,会发现编译运行在Android 4.4的机器上,启动闪屏页,加载完准备进入主页直接报错NoClassDefFoundError。NoClassDefFoundError 在这里出现知道就是主dex里面没有该类,一般情况下,这个方案的报错会出现在三方库的中,尤其是ContentProvider相关的逻辑。
应用进程不存在的情况下,从点击桌面应用图标,到应用启动(冷启动),大概会经历以下流程:
Launcher startActivity
AMS startActivity
Zygote fork 进程
ActivityThread main()
4.1. ActivityThread attach
4.2. handleBindApplication
4.3 attachBaseContext
4.4. installContentProviders
4.5. Application onCreateActivityThread 进入loop循环
Activity生命周期回调,onCreate、onStart、onResume...
整个启动流程我们能干预的主要是 4.3、4.5 和6,应用启动优化主要从这三个地方入手。理想状况下,这三个地方如果不做任何耗时操作,那么应用启动速度就是最快的,但是现实很骨感,很多开源库接入第一步一般都是在Application onCreate方法初始化,有的甚至直接内置ContentProvider,直接在ContentProvider中初始化框架,不给你优化的机会。
子线程install的方案之所以出现问题也正是因为上述的原理所说,即:ContentProvider初始化太早了,如果不在主dex中,还没启动闪屏页就已经crash了。
总结一下这种方案的缺点:
1. MultiDex加载逻辑放在闪屏页的话,闪屏页中引用到的类都要配置在主dex。
2. ContentProvider必须在主dex,一些第三方库自带ContentProvider,维护比较麻烦,要一个一个配置。
下面我们看一下今日头条是如何优化MultiDex的。
3.2 今日头条优化方案
1.在主进程Application 的 attachBaseContext 方法中判断如果需要使用MultiDex,则创建一个临时文件,然后开一个进程(LoadDexActivity),显示Loading,异步执行MultiDex.install 逻辑,执行完就删除临时文件并finish自己。
2. 主进程Application 的 attachBaseContext 进入while代码块,定时轮循临时文件是否被删除,如果被删除,说明MultiDex已经执行完,则跳出循环,继续正常的应用启动流程。
3.MultiDex执行完之后主进程Application继续走,ContentProvider初始化和Application onCreate方法,也就是执行主进程正常的逻辑。
注意:LoadDexActivity 必须要配置在main dex中。
Android 项目优化(三):MultiDex 优化的更多相关文章
- Android 项目Log日志输出优化
概述 Android开发过程中经常需要向控制台输出日志信息,有些人还在用Log.i(tag,msg)的形式或者system.out.println(msg)方式吗?本篇文章对日志信息输出进行优化,以达 ...
- Android 性能优化 三 布局优化ViewStub标签的使用
小黑与小白的故事,通过虚拟这两个人物进行一问一答的形式来共同学习ViewStub的使用 小白:Hi,小黑,ViewStub是什么?听说能够用来进行布局优化. 小黑:ViewStub 是一个隐藏的,不占 ...
- C#-Xamarin的Android项目开发(三)——发布、部署、打包
前言 部署,通常的情况下,它其实也是项目开发的一个难点. 为什么这么说呢?因为,它不是代码开发,所以很多开发者本能的拒绝学习它. 并且一个项目配置好一次以后,部署的步骤和部署的人通常很固定,所以大部分 ...
- Android项目开发三
微博客户端开发 本周学习计划 运用OAuth相关知识,解决上周出现的微博验证问题. 看懂微博客户端登录.用户主页等功能代码. 将程序中存在的问题解决. 实际完成情况 本周继续研究了OAuth相关知识, ...
- MySQL优化(三):优化数据库对象
二.优化数据库对象 1.优化表的数据类型 应用设计的时候需要考虑字段的长度留有一定的冗余,但不推荐很多字段都留有大量的冗余,这样既浪费磁盘空间,也在应用操作时浪费物理内存. 在MySQL中,可以使用函 ...
- Android基础之用Eclipse搭建Android开发环境和创建第一个Android项目(Windows平台)
一.搭建Android开发环境 准备工作:下载Eclipse.JDK.Android SDK.ADT插件 下载地址:Eclipse:http://www.eclipse.org/downloads/ ...
- Android 项目优化(七):阿里巴巴Android开发手册整理总结
本来之前觉得Android项目优化系列的文章基本整理完毕了,但是近期看了一下<阿里Android开发手册>有了很多收获,想再整理一篇,下面就开始吧. 先在这里列一下之前整理的文章及链接: ...
- 使用ant优化android项目编译速度,提高工作效率
1.Android项目编译周期长,编译项目命令取消困难 2.在进行Android项目的编译的同时,Eclipse锁定工作区不能进行修改操作 3.在只进行资源文件的修改时,Eclipse对资源文件的修改 ...
- Android 项目优化(六):项目开发时优化技巧总结
在之前我们讲了很多能够优化 Android 开发项目质量的方案,这些方案更多的是从一些比较专精的方向切入的,阐述的是一些比较重要且独立的优化方案. 本文我们将总结一下在日常开发过程中我们能够使用的一些 ...
随机推荐
- mysql中运用条件判断筛选来获取数据
### part1 单表查询 sql查询完整语法: select .. from .. where .. group by .. having .. order by .. limit .. 一.wh ...
- shell特殊符号及cut、sort_wc_uniq、tee_tr_split命令 使用介绍
第6周第2次课(4月24日) 课程内容: 8.10 shell特殊符号cut命令8.11 sort_wc_uniq命令8.12 tee_tr_split命令8.13 shell特殊符号下 扩展1. s ...
- zsh: /usr/local/bin/pod: bad interpreter: /System/Library/Frameworks/Ruby.framework/Versions/2.3/usr/bin/ruby: no such file or directory
系统升级为 macOS Catalina 发现 CocoaPods 不管用了. 解决方法: 打开 iTerm2 sudo gem update --system 输入电脑密码,然后 sudo gem ...
- 本地搭建的gitbook添加导航折叠插件
如果有多个目录,Gitbook在浏览器上打开时,默认所有的目录都会打开,当目录比较多时,全部显示不利于阅读. 可以使用插件配置目录折叠,使得打开浏览器时这些目录默认是关闭的. 在执行gitbook i ...
- Spring IOC容器装配Bean_基于注解配置方式
bean的实例化 1.导入jar包(必不可少的) 2.实例化bean applicationContext.xml(xml的写法) <bean id="userDao" cl ...
- #华为云·寻找黑马程序员#微服务-你真的懂 Yaml 吗?
在Java 的世界里,配置的事情都交给了 Properties,要追溯起来这个模块还是从古老的JDK1.0 就开始了的. "天哪,这可是20年前的东西了,我居然还在用 Properties. ...
- AI如何驱动软件开发?华为云DevCloud 权威专家邀你探讨
近期,国际著名咨询公司Gartner 在一份研究报告中将 "AI-Driven Development" 列为 2019 年的 Top 10 Strategic Technolog ...
- Plugin execution not covered by lifecycle configuration: org.codehaus.mojo:build-helper-maven-plugin:1.8:add-test-source (execution: add-functional-source, phase: generate-sources)
在maven项目中使用add-source时,pom.xml报如下错误: Plugin execution not covered by lifecycle configuration: org.co ...
- iOS使用Workspace来管理多项目 ( 转 )
开发中会有一些常用的类或方法,或者是某个特定功能的,比如一个自定义的弹框.一个更容易使用的网络请求库,可以把它们放到一个单独的工程里,通过静态库(library.FrameWork)的方式应用到任何其 ...
- 基于 SOA 架构,创建 ego-search-web 项目-solr集群-zookeeper集群
项目架构 Ego-search-web 服务的消费者,ego-rpc 服务提供者 建立 ego-search-web 项目 继承:ego 依赖:ego-common ego-rpc-service ...