[STL] Implement "map", "set"
STL: map, set
内存模型
Ref: STL中map的数据结构
C++ STL中标准关联容器set, multiset, map, multimap内部采用的就是一种非常高效的平衡检索二叉树:红黑树,也成为RB树(Red-Black Tree)。
RB树的统计性能要好于一般的平衡二叉树(有些书籍根据作者姓名,Adelson-Velskii和Landis,将其称为AVL-树),所以被STL选择作为了关联容器的内部结构。
本文并不会介绍详细AVL树和RB树的实现以及他们的优劣,关于RB树的详细实现参看红黑树: 理论与实现(理论篇)。本文针对开始提出的几个问题的回答,来向大家简单介绍map和set的底层数据结构。
(1) 为何map和set的插入删除效率比用其他序列容器高?
类似list高效(也只能用过list的link模式);因此插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点就OK了.
(2) 为何每次insert之后,以前保存的iterator不会失效?
因为是list的link模式,内存没有变,指向内存的指针怎么会失效呢。
(3) 当数据元素增多时(10000和20000个比较),map和set的插入和搜索速度变化如何?
这涉及到二叉树的性质,便容易理解了。
STL没有 tree
无必要性
前几天觉得STL中没有树和图真是一种莫大的遗憾啊,但是在网上搜了搜,发现其实可以用容器很简单的构造树。
There are two reasons you could want to use a tree:
You want to mirror the problem using a tree-like structure:
For this, we have boost graph library
Or you want a container that has tree-like access characteristics. For this we have
std::map (and std::multimap)
std::set (and std::multiset)
Basically, the characteristics of these two containers are such that they practically have to be implemented using trees (though this is not actually a requirement).
See also this question: C tree Implementation
The Boost Graph Library (BGL)
Ref: boost graph library
The BGL algorithms consist of a core set of algorithm patterns (implemented as generic algorithms) and a larger set of graph algorithms. The core algorithm patterns are
- Breadth First Search
- Depth First Search
- Uniform Cost Search
Boost 作为“准标准库”,其中包括了二十个分类,graph属于其中的一个。
By themselves, the algorithm patterns do not compute any meaningful quantities over graphs; they are merely building blocks for constructing graph algorithms. The graph algorithms in the BGL currently include
Dijkstra's Shortest Paths
Bellman-Ford Shortest Paths
Johnson's All-Pairs Shortest Paths
Kruskal's Minimum Spanning Tree
Prim's Minimum Spanning Tree
Connected Components
Strongly Connected Components
Dynamic Connected Components (using Disjoint Sets)
Topological Sort
Transpose
Reverse Cuthill Mckee Ordering
Smallest Last Vertex Ordering
Sequential Vertex Coloring
实现的图接口
二叉树基础
基本概念
基本性质
Ref: 二叉树总结(一)概念和性质
在二叉树中的第i层上至多有2(i-1)个结点(i>=1)。
深度为k的二叉树至多有2k - 1个节点(k>=1)。
对任何一棵二叉树T,如果其叶结点数目为n0,度为2的节点数目为n2,则n0=n2+1。
满二叉树:深度为k且具有2k-1个结点的二叉树。即满二叉树中的每一层上的结点数都是最大的结点数。
完全二叉树:深度为k具有n个结点的二叉树,当且仅当每一个结点与深度为k的满二叉树中的编号从1至n的结点一一对应。
具有n个节点的完全二叉树的深度为log2n + 1。
性质证明
- 性质1:二叉树第i层上的结点数目最多为 2{i-1} (i≥1)
证明:下面用"数学归纳法"进行证明。
(01) 当i=1时,第i层的节点数目为2{i-1}=2{0}=1。因为第1层上只有一个根结点,所以命题成立。
(02) 假设当i>1,第i层的节点数目为2{i-1}。这个是根据(01)推断出来的!
下面根据这个假设,推断出"第(i+1)层的节点数目为2{i}"即可。
由于二叉树的每个结点至多有两个孩子,故"第(i+1)层上的结点数目" 最多是 "第i层的结点数目的2倍"。即,第(i+1)层上的结点数目最大值=2×2{i-1}=2{i}。
故假设成立,原命题得证!
- 性质2:深度为k的二叉树至多有2{k}-1个结点(k≥1)
证明:在具有相同深度的二叉树中,当每一层都含有最大结点数时,其树中结点数最多。利用"性质1"可知,深度为k的二叉树的结点数至多为:
20+21+…+2k-1=2k-1
故原命题得证!
- 性质3:包含n个结点的二叉树的高度至少为log2 (n+1)
证明:根据"性质2"可知,高度为h的二叉树最多有2{h}–1个结点。反之,对于包含n个节点的二叉树的高度至少为log2(n+1)。
- 性质4:在任意一棵二叉树中,若终端结点的个数为n0,度为2的结点数为n2,则n0=n2+1
证明:因为二叉树中所有结点的度数均不大于2,所以结点总数(记为n)="0度结点数(n0)" + "1度结点数(n1)" + "2度结点数(n2)"。由此,得到等式一。
(等式一) n=n0+n1+n2
另一方面,0度结点没有孩子,1度结点有一个孩子,2度结点有两个孩子,故二叉树中孩子结点总数是:n1+2n2。此外,只有根不是任何结点的孩子。故二叉树中的结点总数又可表示为等式二。
(等式二) n=n1+2n2+1
由(等式一)和(等式二)计算得到:n0=n2+1。原命题得证!
二叉树的遍历
Ref: 二叉树总结(二)树的遍历
From: 二叉树遍历(前序、中序、后序、层次、深度优先、广度优先遍历)
From:二叉树的前序遍历,中序遍历和后序遍历分别有什么作用?
(1) 先序遍历:在第一次遍历到节点时就执行操作,一般只是想遍历执行操作(或输出结果)可选用先序遍历;
(2) 中序遍历:对于二分搜索树,中序遍历的操作顺序(或输出结果顺序)是符合从小到大(或从大到小)顺序的,故要遍历输出排序好的结果需要使用中序遍历
(3) 后序遍历:后续遍历的特点是执行操作时,肯定已经遍历过该节点的左右子节点,故适用于要进行破坏性操作的情况,比如删除所有节点
一、前序遍历
( root --> left --> right )
递归方法
vector<int> preorder(TreeNode* root){
vector<int> retInt;
if (root == NULL)
return retInt; // 0.空树
retInt.push_back(root->val); // 1.先访问值
vector<int> left = preorder(root->left); // 2.进入左子树
retInt.insert(retInt.end(), left.begin(), left.end()); // 复制左子树的访问结果,是个vector,把它加进来
vector<int> right = preorder(root->right); // 3.进入右子树
retInt.insert(retInt.end(), right.begin(), right.end()); // 复制右子树的访问结果,是个vector,把它加进来
return retInt;
}
非递归方法
利用函数调用天生的“栈”,或者自己模拟这个“栈”,其中存储的是指针,也就是个"指针栈".
vector<int> preorder(TreeNode* root) {
vector<int> retInt;
if (root == NULL)
return retInt; // 空树
stack<TreeNode *> s;
s.push(root); // 树根入栈,准备好了
while (!s.empty()){
TreeNode *p = s.top();
retInt.push_back(p->val); // (1) [读值], 先访问值 --> 先读了再说
if (p->left != NULL)
{
s.push(p->left); // (2) [压栈],遍历左子树,左子树入栈
}
else
{
s.pop(); // (3.1) 右子树是当前过程中的"最后一次操作",所以,[出栈].
while (p->right == NULL && !s.empty()){ //寻找非空右子树
p = s.top();
s.pop();
}
// (3.2) 右子树竟然有东西,那就再利用一次,[压栈]
if (p->right != NULL)
s.push(p->right);
}
}
return retInt;
}
《韭学》
- 注意右子树的判断,有两种情况.
二、中序遍历
中序遍历 为何具有顺序性?左小右大,Map默认按照key排序.
( left --> root --> right )
递归方法
vector<int> inorder(TreeNode* root){
vector<int> retInt;
if (root == NULL)
return retInt; // 0.空树
retInt = inorder(root->left); // 1.遍历左子树
retInt.push_back(root->val); // 2.访问当前节点值
vector<int> temp = inorder(root->right); // 3.遍历右子树
retInt.insert(retInt.end(), temp.begin(), temp.end()); //复制右子树的结果
return retInt;
}
非递归方法
vector<int> inorder(TreeNode* root){
vector<int> retInt;
if (root == NULL)
return retInt; // 空树
TreeNode *p = NULL;
stack<TreeNode *> s;
s.push(root); // 树根入栈
while (!s.empty()){
p = s.top(); // 获取栈顶元素
// 若先序,是在这里[读值]
if (p->left != NULL)
{
s.push(p->left); // (1) [压栈],找到遍历到“最左的“叶子结点
}
else
{ // 左子树为空了,已到了左子树的尽头
s.pop();
retInt.push_back(p->val); // (2) [读值],没有左子树才读
while (p->right == NULL && !s.empty()){ // (3) 寻找非空右子树
p = s.top(); // 若右子树为空,获取新的栈顶元素
retInt.push_back(p->val); // 访问新元素的值
s.pop();
}
if (p->right != NULL)
s.push(p->right);//右子树入栈
}
}
return retInt;
}
《韭学》
- 注意灰色字体,是与先序不一样的地方.
三、后序遍历
( left --> right --> root )
递归方法
vector<int> postorderTraversal2(TreeNode* root) {
vector<int> retInt;
if (root == NULL)
return retInt; // 0.空树
retInt = preorderTraversal2(root->left); // 1.进入左子树
vector<int> right = preorderTraversal2(root->right); // 2.进入右子树
retInt.insert(retInt.end(), right.begin(), right.end());
retInt.push_back(root->val); // 3.最后访问值
return retInt;
}
非递归方法
非递归方法值得细细品味,需要记录 “子结点” 是否已被访问过。也就是说:
(1) 左子树遍历完后,root出现在stack top一次.
(2) 右子树遍历完后,root出现在stack top又一次.
(3) 出现两次后,才能读取root的值.
vector<int> LeetCode::postorderTraversal(TreeNode* root) {
vector<int> retInt;
if (root == nullptr)
return retInt; // 空树
stack<TreeNode *> s;
TreeNode* visited = nullptr; // 记录前面已访问的树节点
TreeNode* p = root; // 记录当前节点
while (p || !s.empty()){ // !p保证根节点能入栈
while (p){ //[压栈] --> 一直找到 ”最左的“ 叶子结点
s.push(p);
p = p->left;
}
p = s.top();
if (!p->right || p->right == visited) // 右子树也没事了,就开始记录root值
{
retInt.push_back(p->val); // 左右子树都已访问或为空,则访问当前节点
visited = p; // 记录已访问的右节点
s.pop();
p = nullptr; // 置为空,防止重复遍历左子树
}
else
{
p = p->right;
}
}
return retInt;
}
《韭学》
- 特点就是每个小循环都找“最左”优先;
- 找到后就看“兄弟”右结点,然后在继续找“最左”优先;
- 向上返回时,再见到老节点时,是不能进入"while找最左"的循环的,故需要flag条件判断.
逆后序遍历镜像对称法
考研书,书中提供了一种新的思路,之前完全没有想到:

对于上面的二叉树,我们可以写出它的前序遍历方式:
A,B ,D,G,C,E,F
其后序遍历方式为:
G,D,B,E,F,C,A
如果我们把后序遍历逆序:
A,C,F,E,B,D,G
仔细看一看,我想你一定已经发现规律了,如果我们把后序遍历逆序后的结果称为逆后序遍历,那么逆后序遍历只不过是先序遍历过程中对左右子树遍历顺序交换所得到的结果。
因此,只需要将先序遍历的非递归算法中对左右子树的遍历顺序交换就可以得到逆后序遍历的序列,然后再将逆后序遍历的结果逆序就得到了后序遍历的结果,因此我们需要两个栈,一个栈stack1用于辅助做逆后序遍历,并将遍历结果序列压入另一个栈stack2,然后将stack2的元素全部出栈,所得到的序列就是后序遍历的结果。
四、层次遍历
广度优先,不需要递归也很容易理解的哈,使用 “queue" 即可。
非递归方法
template<class T> void BST<T>:breadthFirst()
{
Queue<BSTNode<T>*> queue;
BSTNode<T> *p = root; if (p != )
{
queue.enqueue(p);
while (!queue.empty())
{
p = queue.dequeue(); // [出队] visit(p);
if (p->left != )
queue.enqueue(p->left); // 子节点,[入队]
if (p->right != )
queue.enqueue(p->right); // 子节点,[入队]
}
}
}
《韭学》
处理出队口的父节点的同时,也把它的子节点入队。
二叉树的线索化
一、线索二叉树
[Threaded Binary Tree]
线索化的实质就是将二叉链表中的空指针改为指向前驱或后继的线索。由于前驱和后继信息只有在遍历该二叉树时才能得到.
所以,线索化的过程就是在遍历的过程中修改空指针的过程。
线索化
自然的,有先序,中序,后序三种序列化方法.
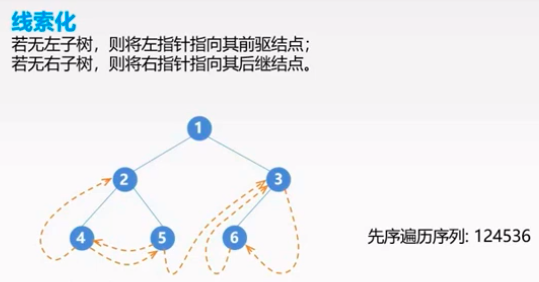
上图,2的前驱节点是谁?
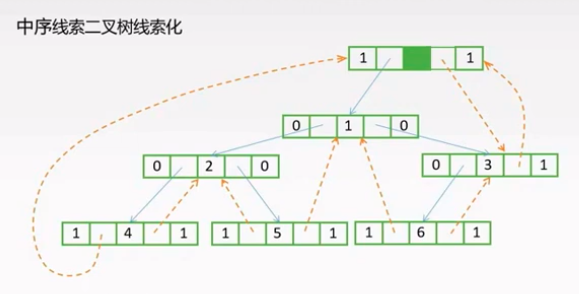
应该是1,但找起来非常复杂。中序线索二叉树 则天然地具有这方面的便捷性。
存储结构
到底是孩子还是前后继,则需要添加标志位.
typedef struct ThreadNode {
ElemType data;
struct ThreadNode *lchild, *rchild;
int ltag, rtag;
} ThreadNode, *ThreadTree;
二、遍历优势
(1) 从头到尾,从尾到头,都方便遍历。
(2) 遍历是递归,而不需要用迭代。
高级二叉树
本篇有点烧脑,前方高能,注意营养。
二叉搜索树
一、性质
[Binary Search Tree]
若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
任意节点的左、右子树也分别为二叉查找树。
没有键值相等的节点(no duplicate nodes)。
由上面的性质很容易看出来,二叉查找树的 中序遍历 是一个增序的序列。
因此,二叉搜索树的最小值是在最左边,最大值是在最右边。
二、优势就是查找
只查找
不需要迭代写法。
while循环一并到底。
查找并插入
当某个子树为空时,插入。也是停止查找的停止标志。
插入的过程,也就是“构造”的过程。但确定很明显,第一个值决定了tree的平衡性。
三、进一步的平衡
删除
删除节点的右子树进行 “中序遍历”,得到最小的那个节点替代到“删除点”。

删除再插入
同一个元素在二叉搜索树中删除后再插入位置可能不一样;
而且二叉搜索树多次插入删除后,可能会出现树枝偏向一边,即根节点的一边的子树节点很少,另一边节点很多,这种不平衡的状态。
因此,它的查找复杂度最坏可能是O(n),也就是 List 的情况。
平衡二叉搜索树
一、特点
AVL树是根据它的发明者G.M. Adelson-Velsky和E.M. Landis命名的。它是最先发明的自平衡二叉查找树,也被称为高度平衡树。相比于"二叉查找树",它的特点是:AVL树中任何节点的两个子树的高度最大差别为1。
AVL树的查找、插入和删除在平均和最坏情况下都是O(logn)。
如果在AVL树中插入或删除节点后,使得高度之差大于1。此时,AVL树的平衡状态就被破坏,它就不再是一棵二叉树;
为了让它重新维持在一个平衡状态,就需要对其进行旋转处理。
typedef int Type;
typedef struct AVLTreeNode{
Type key;
int height; // 当前节点的高度
struct AVLTreeNode *left; // 左孩子
struct AVLTreeNode *right; // 右孩子
}Node, *AVLTree;
二、平衡性判断
自然地,需要后序遍历。(child + child --> root)
三、"旋转"修复方法
四种基本情况


当插入一个元素使平衡二叉树不平衡时,可能出现以下的四种情况:
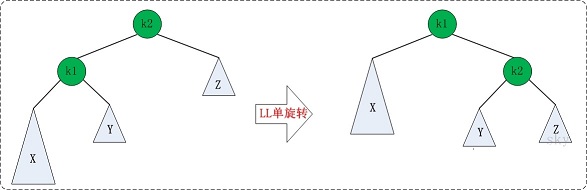
LL:称为"左左"。插入或删除一个节点后,根节点的左子树的左子树还有非空子节点,导致"根的左子树的高度"比"根的右子树的高度"大2,导致AVL树失去了平衡。
例如,在上面LL情况中,由于"根节点(8)的左子树(4)的左子树(2)还有非空子节点",而"根节点(8)的右子树(12)没有子节点";导致"根节点(8)的左子树(4)高度"比"根节点(8)的右子树(12)"高2。
LR:称为"左右"。插入或删除一个节点后,根节点的左子树的右子树还有非空子节点,导致"根的左子树的高度"比"根的右子树的高度"大2,导致AVL树失去了平衡。
例如,在上面LR情况中,由于"根节点(8)的左子树(4)的左子树(6)还有非空子节点",而"根节点(8)的右子树(12)没有子节点";导致"根节点(8)的左子树(4)高度"比"根节点(8)的右子树(12)"高2。
RL:称为"右左"。插入或删除一个节点后,根节点的右子树的左子树还有非空子节点,导致"根的右子树的高度"比"根的左子树的高度"大2,导致AVL树失去了平衡。
例如,在上面RL情况中,由于"根节点(8)的右子树(12)的左子树(10)还有非空子节点",而"根节点(8)的左子树(4)没有子节点";导致"根节点(8)的右子树(12)高度"比"根节点(8)的左子树(4)"高2。
RR:称为"右右"。插入或删除一个节点后,根节点的右子树的右子树还有非空子节点,导致"根的右子树的高度"比"根的左子树的高度"大2,导致AVL树失去了平衡。
例如,在上面RR情况中,由于"根节点(8)的右子树(12)的右子树(14)还有非空子节点",而"根节点(8)的左子树(4)没有子节点";导致"根节点(8)的右子树(12)高度"比"根节点(8)的左子树(4)"高2。
调整方法
LL旋转
当平衡二叉树失去平衡,显示出上面LL的情况时,可以用下面的一次调整使其恢复平衡。
RR旋转
当平衡二叉树失去平衡,显示出上面RR的情况时,可以用下面的一次调整使其恢复平衡。
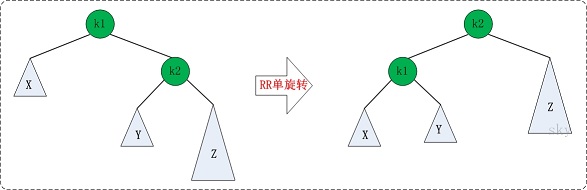
LR旋转
当平衡二叉树失去平衡,显示出上面LR的情况时,可以用下面的两次调整使其恢复平衡。

RL旋转
当平衡二叉树失去平衡,显示出上面RL的情况时,可以用下面的两次调整使其恢复平衡。

红黑树
一、定义和性质
基本性质
红黑树是一种含有红黑结点并能自平衡的二叉查找树。它必须满足下面性质:
- 性质1:每个节点要么是黑色,要么是红色。
- 性质2:根节点是黑色。
- 性质3:每个叶子节点(NIL)是黑色。
- 性质4:每个红色结点的两个子结点一定都是黑色。
- 性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
从性质5又可以推出:
- 性质5.1:如果一个结点存在黑子结点,那么该结点肯定有两个子结点
黑色完美平衡
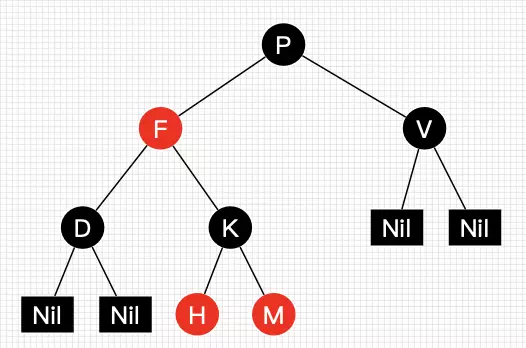
红黑树并不是一个完美平衡二叉查找树,从图1可以看到,根结点P的左子树显然比右子树高,但左子树和右子树的黑结点的层数是相等的,也即任意一个结点到到每个叶子结点的路径都包含数量相同的黑结点(性质5)。
所以我们叫红黑树这种平衡为黑色完美平衡。
二、红黑树的优势
Ref: 内核里的红黑树【进程组织管理】
因为它本身就是平衡的,所以查找也不会出现非常恶劣的情况,基于二叉树的操作的时间复杂度是 O(log(N))。
查找某个进程时,确保最差的情况 “不会太差”。
与平衡二叉树区别
- AVL树(平衡二叉树)
(1) 简介
AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,和红黑树相比,AVL树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而它的英文旋转非常耗时的。
由此我们可以知道AVL树适合用于:插入与删除次数比较少,但查找多的情况。
(2) 局限性
由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。
(3) 应用
在Windows NT内核中广泛存在。
- 红黑树
(1) 简介
一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)。
通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,
红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树)。
相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。
(2) 性质
/* 已上述提及 */
(3) 应用
广泛用于C ++的STL中,map和set都是用红黑树实现的;
著名的Linux的的进程调度完全公平调度程序,用红黑树管理进程控制块,
进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间;
IO多路复用的epoll的实现采用红黑树组织管理的sockfd,以支持快速的增删改查;
Nginx中用红黑树管理定时器,因为红黑树是有序的,可以很快的得到距离当前最小的定时器;
Java的中TreeMap中的中的实现;
End.
[STL] Implement "map", "set"的更多相关文章
- C++ STL中Map的按Key排序和按Value排序
map是用来存放<key, value>键值对的数据结构,可以很方便快速的根据key查到相应的value.假如存储学生和其成绩(假定不存在重名,当然可以对重名加以区 分),我们用map来进 ...
- STL中map与hash_map的比较
1. map : C++的STL中map是使用树来做查找算法; 时间复杂度:O(log2N) 2. hash_map : 使用hash表来排列配对,hash表是使用关键字来计算表位置; 时间复杂度:O ...
- STL中map,set的基本用法示例
本文主要是使用了STL中德map和set两个容器,使用了它们本身的一些功能函数(包括迭代器),介绍了它们的基本使用方式,是一个使用熟悉的过程. map的基本使用: #include "std ...
- STL中map与hash_map容器的选择收藏
这篇文章来自我今天碰到的一个问题,一个朋友问我使用map和hash_map的效率问题,虽然我也了解一些,但是我不敢直接告诉朋友,因为我怕我说错了,通过我查询一些帖子,我这里做一个总结!内容分别来自al ...
- C++ STL中Map的相关排序操作:按Key排序和按Value排序 - 编程小径 - 博客频道 - CSDN.NET
C++ STL中Map的相关排序操作:按Key排序和按Value排序 - 编程小径 - 博客频道 - CSDN.NET C++ STL中Map的相关排序操作:按Key排序和按Value排序 分类: C ...
- STL之map排序
描述 STL的map中存储了字符串以及对应出现的次数,请分别根据字符串顺序从小到大排序和出现次数从小到大排序. 部分代码已经给出,请补充完整,提交时请勿包含已经给出的代码. int main() { ...
- C++中的STL中map用法详解(转)
原文地址: https://www.cnblogs.com/fnlingnzb-learner/p/5833051.html C++中的STL中map用法详解 Map是STL的一个关联容器,它提供 ...
- C++ STL中Map的按Key排序跟按Value排序
C++ STL中Map的按Key排序和按Value排序 map是用来存放<key, value>键值对的数据结构,可以很方便快速的根据key查到相应的value.假如存储学生和其成绩(假定 ...
- [STL] Implement "vector", ”deque“ and "list"
vector “可增的”数组 vector是一块连续分配的内存,从数据安排的角度来讲,和数组极其相似. 不同的地方就是: (1) 数组是静态分配空间,一旦分配了空间的大小,就不可再改变了: (2) v ...
随机推荐
- 十款强大的IDEA插件-Java开发者的利器
xl_echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!! 插 ...
- Docker:镜像的迁移
从202将现有镜像搬到207的过程. 先说导出,两种方法:Docker save 和 docker export,前者保存镜像,后者导出容器. docker save docker.io/java:7 ...
- SpringBoot中关于Shiro权限管理的整合使用
转载:https://blog.csdn.net/fuweilian1/article/details/80309192 在整合Shiro的时候,我们先要确定一下我们的步骤: 1.加入Shiro的依 ...
- DNS域名解析服务及其配置
一.背景 到 20 世纪 70 年代末,ARPAnet 是一个拥有几百台主机的很小很友好的网络.仅需要一个名为 HOSTS.TXT 的文件就能容纳所有需要了解的主机信息:它包含了所有连接到 ARPAn ...
- springBoot配置elasticsearch搜索
1.本地安装elasticsearch服务,具体过程见上一篇文章(安装和配置elasticsearch服务集群) 2.修改项目中pom文件,引入搜索相关jar包 <!-- elasticsear ...
- ES5新增数组的一些方法
1.Array.indexof(value1,value2) Tip:用于返回某个数组或字符串中规定字符或者字符串的位置. (1)当Array.indexof(value1);里面只有一个值的时候,表 ...
- SCRUM的四大支柱
转自:http://www.scrumcn.com/agile/scrum-knowledge-library/scrum.html#tab-id-9 迭代开发 在Scrum的开发模式下,我们将开发周 ...
- HDU - 2824 The Euler function 欧拉函数筛 模板
HDU - 2824 题意: 求[a,b]间的欧拉函数和.这道题卡内存,只能开一个数组. 思路: ϕ(n) = n * (p-1)/p * ... 可利用线性筛法求出所有ϕ(n) . #include ...
- 牛客小白月赛6 A 鲲 数学
链接:https://www.nowcoder.com/acm/contest/136/A来源:牛客网 北冥有鱼,其名为鲲,鲲之大,不知其几千里也. ——<庄子·逍遥游> HtBest有一 ...
- CSU 1809 Parenthesis 思维+线段树
1809: Parenthesis Submit Page Summary Time Limit: 5 Sec Memory Limit: 128 Mb Submitte ...