mysql之innodb-锁
本篇主要根据innodb存储引擎的锁进行阐述,包括分类,算法,以及锁的一些问题
一、锁的概述
为了保证最大程度的利用数据库的并发访问,又要确保每个用户能以一致的方式读取和修改数据,为此锁就派上了用场,也就是锁的机制。锁机制也是用于区别数据库系统和文件系统的一个关节特性。
锁是为了支持对共享资源进行访问,提供数据的一致性和完整性。
innodb存储引擎支持行级别的锁,不过也可以在其他很多的地方上锁,比如,LRU列,删除,添加,移动LRU列中的元素。
innodb存储引擎提供了一致性的非锁定读,行级锁支撑,行级锁没有额外的开销,并可以同时保证并发和一致性。
二、innodb锁
2.1、lock和latch
虽然两个都是“锁”,但是两者有着截然不同的意义。
latch为轻量级锁:要求锁定的时间非常短,在innodb中,其又可以分为mutex(互斥量)和rwlock(读写锁),其目的是用来保证并发线程操作临界资源的正确性,没有死锁检查机制。
查看:show ENGINE innodb MUTEX

其中os_waits表示操作系统等待的次数,当不能获得latch时,操作系统就会进入等待状态,等待被唤醒。
lock为事务级锁:用来锁定数据库中的对象,比如,表、页、行。并且一般lock的对象仅在事务commit或者rollback后进行释放,有死锁机制。
2.2、innodb存储引擎中的锁
2.2.1、锁的类型
共享锁(S Lock):允许事务读一行数据,具有锁兼容性质,允许多个事务同时获得该锁。
排它锁(X Lock):允许事务删除或更新一行数据,具有排它性,某个事务要想获得锁,必须要等待其他事务释放该对象的锁。

X锁和其他锁都不兼容,S锁之和S锁兼容,S锁和X锁都是行级别锁,兼容是指对同一条记录(row)锁的兼容性情况。
此外,innodb支持多粒度锁定,这种锁允许事务在行级别和表级别上的锁同时存在,称之为意向锁(Intention Lock),意向锁将锁定的对象分为多个层次,意味着事务在更细粒度上进行加锁。意向锁设计的目的主要是为了在一个事务中揭示下一行将被请求的锁类型。
意向共享锁(IS Lock):事务想要获得一张表中的某几行的共享锁
意向排它锁(IX Lock):事务想要获得一张表中的某几行的排它锁
对数据库中的对象加锁,类似于这棵树,如下图所示:
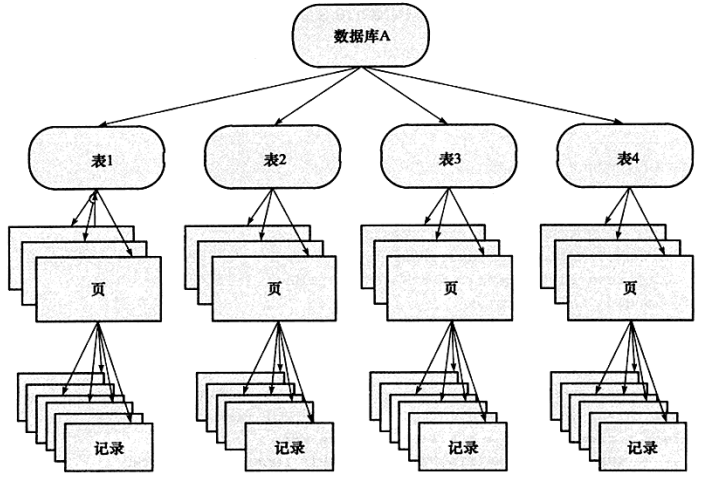
若将上锁看成如上的这颗树,那么对最下层对象的上锁,也就是最细粒度的上锁,首先需要对粗粒度进行上锁,如上图所示,如果我们需要对最底层的记录进行上X锁,那么需要对数据库,表,页上意向锁IX Lock,最后对最底层的记录上X锁,若其中的任意一个部分导致等待,则该操作需要等待粗粒度锁的完成。
由于innodb的支持行级锁,所以意向锁不会阻塞全表扫描以外的任何请求,故表级意向锁和行级锁的兼容如下表所示:

查看锁的方式:
1、show engine innodb status
2、show full processlist
3、在information_schema库中有三个表可以查看,分别是innodb_locks, innodb_trx, innodb_lock_waits.
innodb_trx表的结构(该表只用来显示当前运行innodb事务情况,不能判断锁的情况):

innodb_locks表的结构(可以查看锁的情况,当事务较小时,用户可以认为的只管判断,如果事务很大,则认为判断就不好判断了):
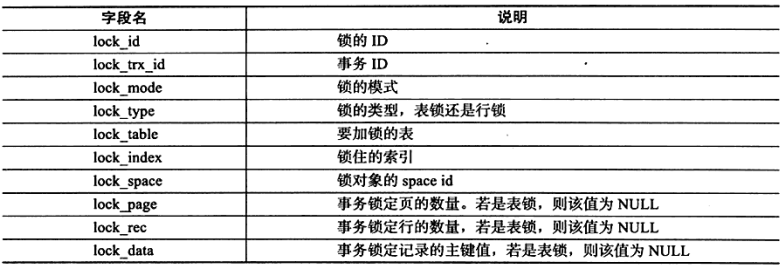
innodb_lock_waits表的结构:

实践部分:
我们通过两个会话提交事务,在会话1中开启事务,修改name,不提交,在会话2中一样修改name值,会话2中会被阻塞。

1、show engine innodb status\G; 查看
------------
TRANSACTIONS
------------
Trx id counter 10026
Purge done for trx's n:o < 10024 undo n:o < 0 state: running but idle
History list length 19
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 421685101706864, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 10025, ACTIVE 238 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 2 row lock(s)
MySQL thread id 8, OS thread handle 140209809667840, query id 74 localhost root updating
update test2.gxt set name='good boy' where id=1 #表示这个语句被阻塞,在申请锁
------- TRX HAS BEEN WAITING 19 SEC FOR THIS LOCK TO BE GRANTED: #表示该事务在申请锁已经等待了19秒
#表示test2.gxt表上的记录要申请的行锁(recode lock)是独占锁并且正在waiting,并且标明了该行记录所在表数据文件中的物理位置:表空间id为46,页码为3。
RECORD LOCKS space id 46 page no 3 n bits 80 index GEN_CLUST_INDEX of table `test2`.`gxt` trx id 10025 lock_mode X waiting
Record lock, heap no 8 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 6; hex 000000000606; asc ;;
1: len 6; hex 000000002728; asc '(;;
2: len 7; hex 3b00000130036d; asc ; 0 m;;
3: len 4; hex 80000001; asc ;;
4: len 4; hex 676f6f64; asc good;; ------------------
---TRANSACTION 10024, ACTIVE 262 sec
2 lock struct(s), heap size 1136, 4 row lock(s), undo log entries 1
MySQL thread id 7, OS thread handle 140209809397504, query id 70 localhost root
2、show full processlist\G;
*************************** 2. row ***************************
Id: 8
User: root
Host: localhost
db: NULL
Command: Query #正在运行
Time: 3
State: updating
Info: update test2.gxt set name='good boy' where id=1 #运行中的语句
*************************** 3. row ***************************
3、select * from information_schema.innodb_trx\G;
mysql> select * from information_schema.innodb_trx\G;
*************************** 1. row ***************************
trx_id: 10025
trx_state: LOCK WAIT #该事务在等在锁
trx_started: 2019-09-11 21:23:43
trx_requested_lock_id: 10025:46:3:8
trx_wait_started: 2019-09-11 21:36:09
trx_weight: 2
trx_mysql_thread_id: 8
trx_query: update test2.gxt set name='good boy' where id=1
trx_operation_state: starting index read
trx_tables_in_use: 1
trx_tables_locked: 1
trx_lock_structs: 2
trx_lock_memory_bytes: 1136
trx_rows_locked: 4
trx_rows_modified: 0
trx_concurrency_tickets: 0
trx_isolation_level: REPEATABLE READ
trx_unique_checks: 1
trx_foreign_key_checks: 1
trx_last_foreign_key_error: NULL
trx_adaptive_hash_latched: 0
trx_adaptive_hash_timeout: 0
trx_is_read_only: 0
trx_autocommit_non_locking: 0
*************************** 2. row ***************************
trx_id: 10024
trx_state: RUNNING #该事务正在运行
trx_started: 2019-09-11 21:23:19
trx_requested_lock_id: NULL
trx_wait_started: NULL
trx_weight: 3
trx_mysql_thread_id: 7
trx_query: NULL
trx_operation_state: NULL
trx_tables_in_use: 0
trx_tables_locked: 1
trx_lock_structs: 2
trx_lock_memory_bytes: 1136
trx_rows_locked: 4
trx_rows_modified: 1
trx_concurrency_tickets: 0
trx_isolation_level: REPEATABLE READ
trx_unique_checks: 1
trx_foreign_key_checks: 1
trx_last_foreign_key_error: NULL
trx_adaptive_hash_latched: 0
trx_adaptive_hash_timeout: 0
trx_is_read_only: 0
trx_autocommit_non_locking: 0
2 rows in set (0.00 sec)
4、 select * from information_schema.innodb_locks\G;
mysql> select * from information_schema.innodb_locks\G;
*************************** 1. row ***************************
lock_id: 10025:46:3:8
lock_trx_id: 10025
lock_mode: X #独占锁
lock_type: RECORD
lock_table: `test2`.`gxt`
lock_index: GEN_CLUST_INDEX
lock_space: 46
lock_page: 3
lock_rec: 8
lock_data: 0x000000000606 #锁住同一份资源,与下面事务相同,所以这里有一个需要等待,在innodb_trx表中可以明显看出来,如上所示
*************************** 2. row ***************************
lock_id: 10024:46:3:8
lock_trx_id: 10024
lock_mode: X
lock_type: RECORD
lock_table: `test2`.`gxt`
lock_index: GEN_CLUST_INDEX
lock_space: 46
lock_page: 3
lock_rec: 8
lock_data: 0x000000000606
2 rows in set, 1 warning (0.00 sec)
5、select * from information_schema.innodb_lock_waits\G;
mysql> select * from information_schema.innodb_lock_waits\G;
*************************** 1. row ***************************
requesting_trx_id: 10025 #申请事务的id ,表示在被阻塞,一直在等待资源
requested_lock_id: 10025:46:3:8 #申请锁的id
blocking_trx_id: 10024 #阻塞事务的id ,表示在运行,阻塞了其他事务
blocking_lock_id: 10024:46:3:8 #阻塞锁的id
1 row in set, 1 warning (0.00 sec)
2.2.2、一致性非锁定读
一致性非锁定读是innodb存储引擎通过多版本控制的方式来读取当前执行时间数据库中行的数据,如果读取到正在删除或者修改的记录,这时读取的操作不会等待行锁的释放,而是直接去读取快照中的数据。如下图所示:

一致性非锁定读,是因为不需要等待访问行上的X锁的释放。
快照数据只的是该行的以前版本的数据,通过undo段来实现,而undo用来事务中的回滚数据,因此快照数据没有额外的开销,此外,读取数据不要上锁,因为没有事务对历史数据修改。一致性非锁定读提高数据库的并发性(这是innodb的默认读取方式)。但是在不同的事务隔离级别下,读取方式不同,并不是每个事务隔离级别下都采用一致性非锁定读,就算采用一致性非锁定读,那还有可能就是快照数据的定义各不相同,比如快照可以有多个版本,所以这种技术称为多版本技术,由此带来的并发控制,称为多版本并发控制(MVCC)
例如在事务隔离级别
READ COMMITTED中:一致性非锁定读总是读取被锁定行的最新一份快照数据;
REPEATABLE READ中:一致性非锁定读总是读取事务开始时的行数据版本;
2.2.3、一致性锁定读
虽然innodb在默认情况下会采用一致性非锁定读方式进行读取,但是某些时候用户也可以显示对数据库读取操作进行加锁以保证数据的逻辑的一致性。
innodb存储引擎对select语句支持两种一致性锁定读的操作:
select ... for update #对读取行加X锁,其他事务不能对已锁定的行加任何锁
select ... lock in share mode #对读取行加S锁,其他事务允许加S锁,但是如果是X锁,则会阻塞
2.2.4、自增长与锁
在innodb的存储结构中,对每个含有自增长值的表都有一个自增长计数器,对于这样的表进行插入数据,则这个计数器会被初始化,插入操作会根据这个自增长的计数器值加1赋予自增长列,这种实现方式成为AUTO-INC Locking,这种锁为了提高插入的性能,锁并不是在一个事务完成后释放,而是在完成自增长值插入的sql语句后立即释放,但是还是存在性能上的问题。
msyql5.1.22版本开始,innodb提供了一种轻量级互斥的自增长实现机制,这个机制大大的提高插入的性能。由参数innodb_automic_lock_mode来控制自增长的模式(默认值为1)。
自增插入的分类如图所示:

innodb_automic_lock_mode设置如下图所示:

还有就是innodb的自增长的实现和myisam不同,myisam是表锁设计,自增长不需要考虑并发插入问题。
2.2.5、外键与锁
在innodb表中,创建外键的时候若外键列上没有索引,则会在创建过程中自动在外键列上隐式地创建索引。
存在这样一种情况,当向子表中插入数据的时候,会向父表查询该表中是否存在对应的值以判断将要插入的记录是否满足外键约束,因此此时使用select ... lock share mode,即主动对父表加S锁,并在表上加意向共享锁。如果此时父表上对应的记录正好有X锁,那么该操作就会阻塞。同理,从子表中删除或更新记录也是一样的。
三、锁带来的三个问题
通过锁机制可以实现事务的隔离性,使得事务更好并发的工作,提高了事务的并发性,但是锁会带来三个问题,如下:
1、脏读
2、不可重复
3、丢失更新
脏读:
先来了解几个概念:
脏页:表示缓冲池重的修改的页还没有刷新到磁盘中,使得缓冲池中的数据和磁盘数据不一致。脏页时允许读取的,页非常的正常,等刷新到磁盘,最终都会保持一致性。
脏数据:是指事务对缓冲池中的数据进行了修改,但是还没有提交事务。
脏读:指的是一个事务读取到了另一个事务没有提交的数据,违反了数据库的隔离性。
脏读只会发生在事务隔离级别为READ UNCOMMITTED。而现在数据库基本都设置成了READ COMMITTED和READ REPEATABLE隔离级别。
不可重复读:
指在一个事务中多次读取同一份数据,在这个事务没有结束过程中,其他事务对这份数据进行了修改,这样就导致这个事务读取到的数据和之前一次的数据是不一样的,这就是不可重复读。违反是事务的一致性。当设置隔离级别为READ COMMITTED时,是允许不可重复读的情况。
在innodb存储引擎中,通过使用Next-Key Lock算法,避免不可重复读问题,在该算法下,对索引的扫描,不仅锁住扫描到的索引,而且锁住这些索引覆盖的范围。因为在这个范围能不允许修改,更新,插入,这样就避免了不可重复读的现象。innodb默认的事务隔离级别为READ REPEATABLE隔离级别。
丢失更新:
指的就是一个事务更新的数据会被另一个事务的更新所覆盖,从而导致数据不一致。
1、事务1更新行r为v1,未提交
2、事务2更新行r为v2,未提交
3、事务1提交
4、事务2提交
其实当前的数据库都不会造成理论上的数据丢失问题,就算是READ UNCOMMITTED隔离级别,事务2在对r行更新时会被阻塞,要么等到事务1提交要么等待超时。
但是会出现下面情况:
1、用户1查询一行数据,存放本地内存
2、用户2查询一行数据,存放本地内存
3、用户1修改更新这行数据,并提交
4、用户2修改更新这行数据,并提交
这样就导致用户1的数据被覆盖了,可以通过加x锁使得步骤1,3串行,2,4串行执行,这样就可以避免数据丢失
四、锁的算法
innodb支持行级锁,但是它还支持范围锁。即对范围内的行记录加行锁。
有三种锁算法:
1.record lock:即行锁
2.gap lock:范围锁,但是不锁定行记录本身
3.next-key lock:范围锁加行锁,即范围锁并锁定记录本身,gap lock + record lock。
record lock是行锁,但是它的行锁锁定的是key,即基于唯一性索引键列来锁定。如果没有唯一性索引键列,则会自动在隐式列上创建索引并完成锁定。
next-key lock是行锁和范围锁的结合,innodb对行的锁申请默认都是这种算法。如果有索引,则只锁定指定范围内的索引键值,如果没有索引,则自动创建索引并对整个表进行范围锁定。之所以锁定了表还称为范围锁定,是因为它实际上锁的不是表,而是把所有可能的区间都锁定了,从主键值的负无穷到正无穷的所有区间都锁定,等价于锁定了表。
假设一个索引有10,11,13,20这四个值,那么索引可能被next-key lock设置的分区为:[-无穷,10),[10,11),[11,13),[13,20),[20,+无穷)
如果事务已经锁定范围[10,11),[11,13),那么当插入记录12时,那么锁定范围将会变成[10,11),[11,12),[12,13)
当查询的索引有唯一属性时,innodb会对next-key lock进行优化,降级为Record Lock。即锁住索引本身,而不是范围索引。
若唯一索引由多个列组成,而查询只是查找多个唯一索引列中的一列,那么查询还是范围查询。
如果存在辅助索引,需要对聚簇索引(一般以主键)和辅助索引分别锁定,如果对主键中的一个索引进行了行索引,那么与主键对应的辅助索引则是范围索引;
例如:create table z (a int , b int ,primary key(a) ,key(b));
insert into z values(1,1);
insert into z values(2,3);
insert into z values(3,6);
insert into z values(4,9);
insert into z values(5,11);
当我们对记录(3,6)进行锁定,聚簇索引锁定的知识a=3这行,而辅助索引锁住的是(3,6)和(6,9)
五、锁的其他状态(阻塞,死锁)
阻塞:
指的是由于不同锁之间可能是相互不兼容的,有些时候一个事务的锁需要等待别的事务释放锁之后才能获得资源,这就是阻塞。
innodb_lock_wait_timeout #控制锁的等待时间,默认50s,否则超时
innndb_rollback_on_timeout #控制是否等待超时事务回滚,默认OFF
死锁:
指的是两个或者两个以上的事务在执行的过程中,因争夺资源而造成的相互等待的过现象。
解决方法:
1、等待超时
2、wait-for graph(等待图),主动监测,innodb采用这种方式
等待图主要保存了两种信息:
1、锁的信息链表
2、事务等待链表
通过上述的链表构造出一张图,如果在图中存在回路,则说明存在死锁。
innodb存储引擎通过回滚undo量最小的事务进行回滚。
参考:
《mysql技术内幕:innodb存储引擎》
mysql之innodb-锁的更多相关文章
- MySQL中InnoDB锁不住表的原因
MySQL中InnoDB锁不住表是因为如下两个参数的设置: mysql> show variables like '%timeout%'; +-------------------------- ...
- MySQL- InnoDB锁机制
InnoDB与MyISAM的最大不同有两点:一是支持事务(TRANSACTION):二是采用了行级锁.行级锁与表级锁本来就有许多不同之处,另外,事务的引入也带来了一些新问题.下面我们先介绍一点背景知识 ...
- MySQL的innoDB锁机制以及死锁处理
MySQL的nnoDB锁机制 InnoDB与MyISAM的最大不同有两点:一是支持事务(TRANSACTION):二是采用了行级锁.行级锁与表级锁本来就有许多不同之处,innodb正常的select ...
- [MySQL Code]Innodb 锁分配和锁冲突判断
根据阿里月报 : MySQL · 引擎特性 · InnoDB 事务锁系统简介 MySQL · 引擎特性 · Innodb 锁子系统浅析 行锁的入口:rec_lock_rec
- mysql事务和锁InnoDB
背景 MySQL/InnoDB的加锁分析,一直是一个比较困难的话题.我在工作过程中,经常会有同事咨询这方面的问题.同时,微博上也经常会收到MySQL锁相关的私信,让我帮助解决一些死锁的问题.本文,准备 ...
- MySQL数据恢复和复制对InnoDB锁机制的影响
MySQL通过BINLOG记录执行成功的INSERT,UPDATE,DELETE等DML语句.并由此实现数据库的恢复(point-in-time)和复制(其原理与恢复类似,通过复制和执行二进制日志使一 ...
- mysql innodb锁简析(2)
继续昨天的innodb锁的分析: 注:此博文参考一下地址,那里讲的也很详细.http://xm-king.iteye.com/blog/770721 mysql事务的隔离级别分为四种,隔离级别越高,数 ...
- MySQL数据库InnoDB存储引擎中的锁机制
MySQL数据库InnoDB存储引擎中的锁机制 http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能 ...
- MySQL · 特性分析 · innodb 锁分裂继承与迁移
http://mysql.taobao.org/monthly/2016/06/01/ innodb行锁简介 行锁类型 LOCK_S:共享锁 LOCK_X: 排他锁 GAP类型 LOCK_GAP:只锁 ...
- [转]关于MYSQL Innodb 锁行还是锁表
关于mysql的锁行还是锁表,这个问题,今天算是有了一点头绪,mysql 中 innodb是锁行的,但是项目中居然出现了死锁,锁表的情况.为什么呢?先看一下这篇文章. 目时由于业务逻辑的需要,必须对数 ...
随机推荐
- LR有的JMeter也有之一“参数化”
酝酿了几天,一直想写点JMeter的东西,算是对学习东西的一个整理.:) 恩,一直觉得自己领悟能力不强,别人写的东西总要看老半天也不懂.好吧!一惯的傻瓜的方式(大量的截图+参数说明)嘻嘻. 参数化:简 ...
- C#使用WebClient调用接口
用于上传图片base64位 private void upLoadCunzai() { errorstring += " upLoadCunzai方法执行成功:用于上传已经存在人员摄像头照片 ...
- 【java提高】(17)---Java 位运算符
Java 位运算符 &.|.^.~.<<.>> 以前学过有关java的运算符,不过开发了这么久也很少用过这个.现在由于开发需要,所以现在再来回顾整理下有关java的运算 ...
- (二十九)c#Winform自定义控件-文本框(二)
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. 开源地址:https://gitee.com/kwwwvagaa/net_winform_custom_control ...
- (二十三)c#Winform自定义控件-等待窗体
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. 开源地址:https://gitee.com/kwwwvagaa/net_winform_custom_control ...
- Python 類別 class 的繼承 Inheritance
既然 Python 是面向物件 Object Oriented 語言,它就有類別 Class 與物件 Object 的概念. 甚麼是類別 class ? 簡單講: 類別好比蓋房子的施工藍圖 Blue ...
- .net打杂工程师的面试感想和总结
上个月26号辞职了,今天开始第一场面试,随便写写感想,后面还会继续分享一些感想 前言 这个时候找工作是不是找死? 开门见山吧,95年的,之前做过两份工作,第一家公司在做了2年2个月,在北京,也就是去年 ...
- JS中的分支结构
if语句 语法: if (expression1) { } else if (expression2) { } else { } 执行机制: 先对expression1做判定,如果为真,执行对应的代码 ...
- 蓝桥杯单片机CT107D 01 底层驱动基础
代码下载 https://share.weiyun.com/5NHvLxG 这两个代码文件是其他底层驱动代码的基础: 包含了控制138573(间接控制数码管led和蜂鸣器等).delay延时函数.CT ...
- python学习——字符串
1)字符串解释 字符串是python中常用的数据类型我们可以使用" "或' '来创建字符串. 2)字符串操作 """访问字符串中的值"&qu ...