7.5 高级数据源---Kafka
一、Kafka简介
Kafka是一种高吞吐量的分布式发布订阅消息系统,用户通过Kafka系统可以发布大量的消息,同时也能实时订阅消费消息。Kafka可以同时满足在线实时处理和批量离线处理。
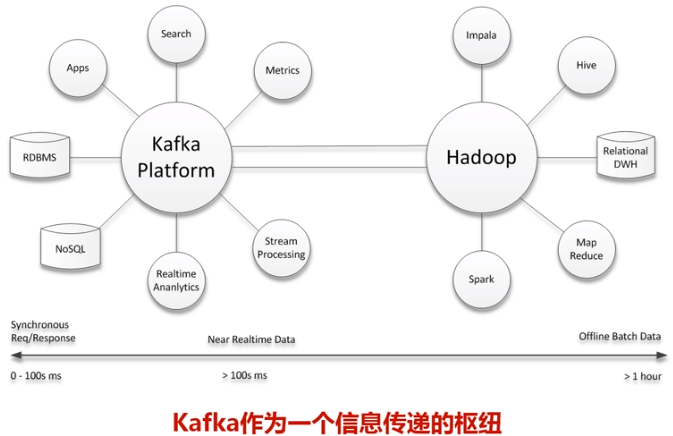
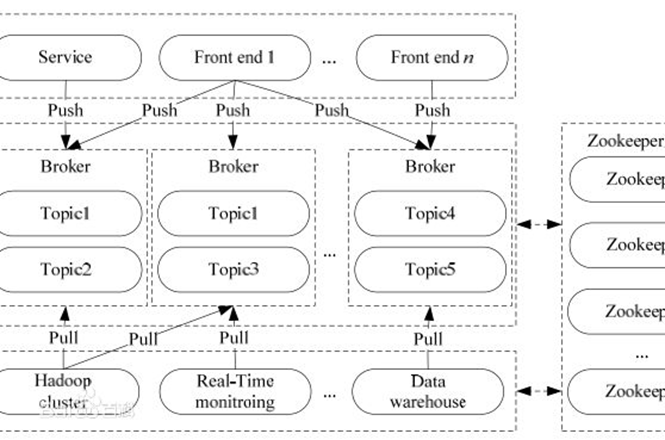
在公司的大数据生态系统中,可以把Kafka作为数据交换枢纽,不同类型的分布式系统(关系数据库、NoSQL数据库、流处理系统、批处理系统等),可以统一接入到Kafka,实现和Hadoop各个组件之间的不同类型数据的实时高效交换。
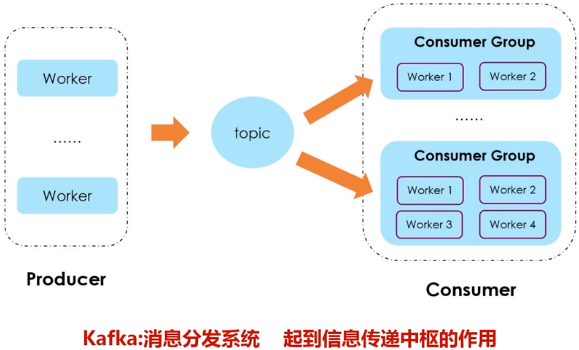


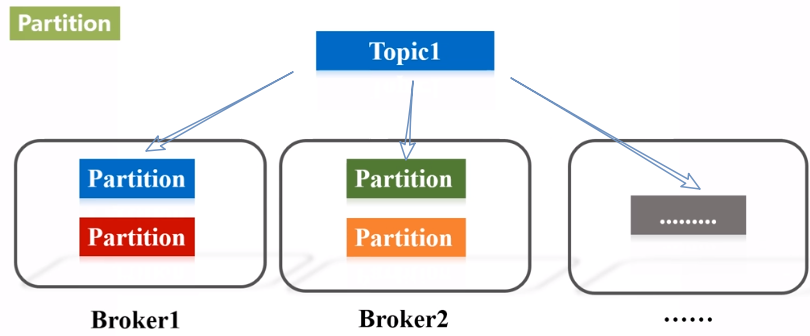
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker。
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)。
- Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition。
- Producer:负责发布消息到Kafka broker。
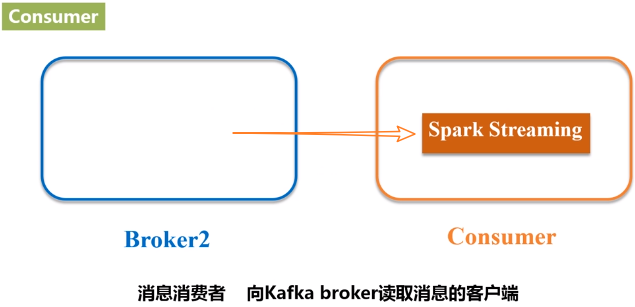
- Consumer:消息消费者,向Kafka broker读取消息的客户端。
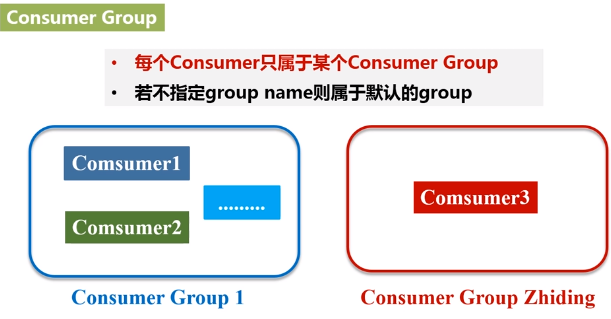
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
二、Kafka准备工作
1.安装Kafka
这里假设已经成功安装Kafka到“/usr/local/kafka”目录下
2.启动Kafka
下载的安装文件为Kafka_2.11-0.10.2.0.tgz,前面的2.11就是该Kafka所支持的Scala版本号,后面的0.10.2.0是Kafka自身的版本号。
打开一个终端,输入下面命令启动Zookeeper服务:

千万不要关闭这个终端窗口,一旦关闭,Zookeeper服务就停止了。
打开第二个终端,然后输入下面命令启动Kafka服务:

千万不要关闭这个终端窗口,一旦关闭,Kafka服务就停止了。
3.测试Kafka是否正常工作
再打开第三个终端,然后输入下面命令创建一个自定义名称为“wordsendertest”的Topic:

默认服务器启动的端口号是2181,replication-factor表示数据要复制1份,--topic后面加topic的名称。列出所有创建的topic,如果能看到wordsendertest,就说明创建成功。
下面用生产者(Producer)来产生一些数据,请在当前终端内继续输入下面命令:


上面命令执行后,就可以在当前终端内用键盘输入一些英文单词,比如可以输入:
hello hadoop
hello spark
现在可以启动一个消费者,来查看刚才生产者产生的数据。请另外打开第四个终端,输入下面命令:

可以看到,屏幕上会显示出如下结果,也就是刚才在另外一个终端里面输入的内容:
hello hadoop
hello spark
三、Spark准备工作
1.添加相关jar包
Kafka和Flume等高级输入源,需要依赖独立的库(jar文件),这些jar文件在安装好Spark的时候是不存在的。在spark-shell中执行下面import语句进行测试:


jar包下载地址:http://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-8_2.11/2.1.0
把jar文件复制到Spark目录的jars目录下

继续把Kafka安装目录的libs目录下的所有jar文件复制到“/usr/local/spark/jars/kafka”目录下,请在终端中执行下面命令:
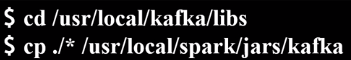
2.启动spark-shell
执行如下命令启动spark-shell:

启动成功后,再次执行如下命令:

四、编写Spark Streaming程序使用Kafka数据源
1.编写生产者(producer)程序
编写KafkaWordProducer程序。执行命令创建代码目录:

在KafkaWordProducer.scala中输入以下代码:

下面代码实现功能:每秒钟发m条消息,每条消息包含Y个单词




package org.apache.spark.examples.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._ object KafkaWordProducer {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCountProducer <metadataBrokerList> <topic> " +
"<messagesPerSec> <wordsPerMessage>")
System.exit(1)
}
val Array(brokers, topic, messagesPerSec, wordsPerMessage) = args
// Zookeeper connection properties
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props) // Send some messages
while(true) {
(1 to messagesPerSec.toInt).foreach { messageNum =>
val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString)
.mkString(" ")
print(str)
println()
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
}
Thread.sleep(1000)
}
}
}
2.编写消费者(consumer)程序
继续在当前目录下创建KafkaWordCount.scala代码文件,它会把KafkaWordProducer发送过来的单词进行词频统计,代码内容如下:




当数据量非常大时,不设置检查点有可能会发生信息的丢失。
package org.apache.spark.examples.streaming
import org.apache.spark._
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka.KafkaUtils object KafkaWordCount{
def main(args:Array[String]){
StreamingExamples.setStreamingLogLevels()
val sc = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sc,Seconds(10))
ssc.checkpoint("file:///usr/local/spark/mycode/kafka/checkpoint") //设置检查点,如果存放在HDFS上面,则写成类似ssc.checkpoint("/user/hadoop/checkpoint")这种形式,但是,要启动hadoop
val zkQuorum = "localhost:2181" //Zookeeper服务器地址
val group = "1" //topic所在的group,可以设置为自己想要的名称,比如不用1,而是val group = "test-consumer-group“ val topics = "wordsender" //topics的名称
val numThreads = 1 //每个topic的分区数
val topicMap =topics.split(",").map((_,numThreads.toInt)).toMap
val lineMap = KafkaUtils.createStream(ssc,zkQuorum,group,topicMap)
val lines = lineMap.map(_._2)
val words = lines.flatMap(_.split(" "))
val pair = words.map(x => (x,1))
val wordCounts = pair.reduceByKeyAndWindow(_ + _,_ - _,Minutes(2),Seconds(10),2) //这行代码的含义在下一节的窗口转换操作中会有介绍
wordCounts.print
ssc.start
ssc.awaitTermination
}
}
3.编写日志格式设置程序(通用)

继续在当前目录下创建StreamingExamples.scala代码文件,用于设置log4j:
package org.apache.spark.examples.streaming
import org.apache.spark.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}
4.编译打包程序
创建simple.sbt文件:

在simple.sbt中输入以下代码:

name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.1.0"
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka-0-8_2.11" % "2.1.0"
进行打包编译:

5.运行程序
打开一个终端,执行如下命令,运行“KafkaWordProducer”程序,生成一些单词(是一堆整数形式的单词):

执行上面命令后,屏幕上会不断滚动出现新的单词,如下图所示,不要关闭这个终端窗口,就让它一直不断发送单词

请新打开一个终端,执行下面命令,运行KafkaWordCount程序,执行词频统计:

运行上面命令以后,就启动了词频统计功能,屏幕上就会显示如下类似信息:

7.5 高级数据源---Kafka的更多相关文章
- 2018.5.12 storm数据源kafka堆积
问题现象: storm代码依赖4个源数据topic,2018.5.12上午8点左右开始收到告警短信,源头的4个topic数据严重堆积. 排查: 1.查看stormUI, storm拓扑结构如下: 看现 ...
- spark streaming基本概念一
在学习spark streaming时,建议先学习和掌握RDD.spark streaming无非是针对流式数据处理这个场景,在RDD基础上做了一层封装,简化流式数据处理过程. spark strea ...
- Kafka官方文档V2.7
1.开始 1.1 简介 什么是事件流? 事件流相当于人体的中枢神经系统的数字化.它是 "永远在线 "世界的技术基础,在这个世界里,业务越来越多地被软件定义和自动化,软件的用户更是软 ...
- Confluent之Kafka Connector初体验
概述 背景 Apache Kafka 是最大.最成功的开源项目之一,可以说是无人不知无人不晓,在前面的文章<Apache Kafka分布式流处理平台及大厂面试宝典>我们也充分认识了Kafk ...
- Kafka+Storm+HDFS整合实践
在基于Hadoop平台的很多应用场景中,我们需要对数据进行离线和实时分析,离线分析可以很容易地借助于Hive来实现统计分析,但是对于实时的需求Hive就不合适了.实时应用场景可以使用Storm,它是一 ...
- Kafka从入门到进阶
1. Apache Kafka是一个分布式流平台 1.1 流平台有三个关键功能: 发布和订阅流记录,类似于一个消息队列或企业消息系统 以一种容错的持久方式存储记录流 在流记录生成的时候就处理它们 ...
- Storm+kafka的HelloWorld初体验
从16年4月5号开始学习kafka,后来由于项目需要又涉及到了storm. 经过几天的扫盲,到今天16年4月13日,磕磕碰碰的总算是写了一个kafka+storm的HelloWorld的例子. 为了达 ...
- 实践部署与使用apache kafka框架技术博文资料汇总
前一篇Kafka框架设计来自英文原文(Kafka Architecture Design)的翻译及整理文章,非常有借鉴性,本文是从一个企业使用Kafka框架的角度来记录及整理的Kafka框架的技术资料 ...
- Kafka 介绍
Apache Kafka是一个分布式流式平台. 流平台有三个关键的能力: 发布和订阅记录流,类似于消息队列或企业消息传递系统. 使用容错耐用的方式存储记录流. 记录产生时处理数据. Kafka主要是用 ...
随机推荐
- ORACLE DATAGUARD 日志传输状态监控
ORACLE DATAGUARD的主备库同步,主要是依靠日志传输到备库,备库应用日志或归档来实现.当主.备库间日志传输出现GAP,备库将不再与主库同步.因此需对日志传输状态进行监控,确保主.备库间日志 ...
- 模块二之序列化模块以及collections模块
模块二之序列化模块以及collections模块 一.序列化模块 json模块 ''' 序列化:将python或其他语言的数据类型转换成字符串类型 json模块: 是一个序列化模块. json: 是一 ...
- MySQL第四课
CREATE TABLE biao( name VARCHAR(20) PRIMARY KEY, age INT(11) NOT NULL, sex CHAR(11)DEFAULT ...
- HTML5之图片转base64编码
之前在群里看到很多小哥哥小姐姐讨论关于图片base64互转的方法,刚好我之前用到的一个方法给大家分享一下. <!Doctype html><html> <head> ...
- Jmeter 压测使用以及参数介绍
. 下载地址 https://jmeter.apache.org/download_jmeter.cgi Binaries¶ 下的apache-jmeter-5.2.1.zipsha512pgp . ...
- Modbus RTU通信协议详解以及与Modbus TCP通信协议之间的区别和联系
Modbus通信协议由Modicon公司(现已经为施耐德公司并购,成为其旗下的子品牌)于1979年发明的,是全球最早用于工业现场的总线规约.由于其免费公开发行,使用该协议的厂家无需缴纳任何费用,Mod ...
- 2018-8-10-win10-uwp-关联文件
原文:2018-8-10-win10-uwp-关联文件 title author date CreateTime categories win10 uwp 关联文件 lindexi 2018-08-1 ...
- sqlite3数据库最大可以是多大?可以存放多少数据?读写性能怎么样?
sqlite是款不错的数据库,使用方便,不需要事先安装软件,事先建表.很多人担心它的性能和数据存储量问题. 比如有的网友问:Sqlite数据库最大可以多大呀?会不会像acc数据库那样,几十MB就暴掉了 ...
- 总结了Python中的22个基本语法
"人生苦短,我用Python".Python编程语言是最容易学习.并且功能强大的语言.只需会微信聊天.懂一点英文单词即可学会Python编程语言.但是很多人声称自己精通Python ...
- Java生鲜电商平台-SpringCloud微服务架构中网络请求性能优化与源码解析
Java生鲜电商平台-SpringCloud微服务架构中网络请求性能优化与源码解析 说明:Java生鲜电商平台中,由于服务进行了拆分,很多的业务服务导致了请求的网络延迟与性能消耗,对应的这些问题,我们 ...