【Redis深度历险】那些年Redis的数据结构
Redis端口号6379的来源
Redis的端口号是6379,但这个端口号并不是随机选择的,源于"MERZ",这个单词在手机当中的对应数字就是6379。"MERZ"在Redis作者Antirez的好友圈当中代表愚蠢的意思。
数据结构
Redis的key只能是字符串,value可以是String,Hash,List,Sorted Set(Zset)。
String
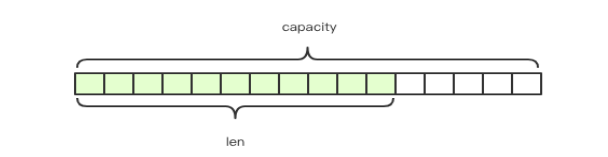
Redis的字符串是动态字符串(SDS Simple Dynamic String ),内部结构有点儿类似于java的ArrayList,都是采取预分配来减少内存的频繁扩容。如图len是实际字符串的长度,capacity是预分配的空间(数组容量)。创建字符串时,len和capacity一样长,使用字节数组存放内容。
struct SDS<T> {
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标识位
byte[] content; // 数组内容
}
- 如果在1M以内,都是加倍扩充容量
- 如果超过1M则,每次扩容1M
- 字符串的最大容量是512M

String的一些基础操作
- 普通get set
127.0.0.1:6379> set name amber
OK
127.0.0.1:6379> get name
"amber"
127.0.0.1:6379> exists name
(integer) 1
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- 批量mset,mget
127.0.0.1:6379> set name amber
OK
127.0.0.1:6379> set name2 nick
OK
127.0.0.1:6379> mget name name2
1) "amber"
2) "nick"
127.0.0.1:6379> mset name3 wade name4 hellen
OK
127.0.0.1:6379> mget name name2 name3 name4
1) "amber"
2) "nick"
3) "wade"
4) "hellen"
127.0.0.1:6379>
- 设置过期时间
- 第一种 expire
127.0.0.1:6379> set name amber
OK
127.0.0.1:6379> expire name 5
(integer) 1
127.0.0.1:6379> get name
"amber"
//等待5s
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- 利用setex
setex name 时间 value
127.0.0.1:6379> setex name 5 amber
OK
127.0.0.1:6379> get name
"amber"
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- 自增自减
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> incr age
(integer) 19
127.0.0.1:6379> incrby age 5
(integer) 24
127.0.0.1:6379> incrby age -5
(integer) 19
127.0.0.1:6379> decr age
(integer) 18
127.0.0.1:6379>
List
Redis的list结构有点像Java中的LinkedList,但实际上地产不仅仅是简单的linkedlist,底层是quicklist(太深入了等待作者以后学习...)
特点
list的插入删除效率很高,时间复杂度为O(1),但是索引的定位就很慢,即O(n)
操作
- 左进右出(队列)
127.0.0.1:6379> lpush names amber nick wade
(integer) 3
127.0.0.1:6379> rpop names
"amber"
127.0.0.1:6379> rpop names
"nick"
127.0.0.1:6379> rpop names
"wade"
127.0.0.1:6379> rpop names
(nil)
127.0.0.1:6379>
当然你也可以左近左出(栈),可以自己实验一下。
- 索引操作
- lindex相当于java的get(int index)根据索引取值,但是因为要遍历链表,如果数据很大,导致开销增大
- ltrim key index1 index2 保留index1和index2之间的数据
127.0.0.1:6379> lpush names amber nick wade
(integer) 3
127.0.0.1:6379> lindex names 0
"wade"
127.0.0.1:6379> lindex names 1
"nick"
127.0.0.1:6379> lindex names 2
"amber"
127.0.0.1:6379> ltrim names 0 1
127.0.0.1:6379> lindex names 0
"wade"
127.0.0.1:6379> lindex names 1
"nick"
127.0.0.1:6379> lindex names 2
(nil)
127.0.0.1:6379>
hash(散列)
Redis的hash类似java中的HashMap
特点
Redis中的Hash进行rehash时区别于java中的HashMap。
在redis进行rehash时会同时保留新旧两个结构,并在后续的定时任务当中慢慢把旧的数据移动到新数据。
操作
127.0.0.1:6379> hmset person name amber age 18
OK
127.0.0.1:6379> hgetall person
1) "name"
2) "amber"
3) "age"
4) "18"
127.0.0.1:6379> hget person name
"amber"
127.0.0.1:6379> hset person gender 1
(integer) 1
127.0.0.1:6379> hgetall person
1) "name"
2) "amber"
3) "age"
4) "18"
5) "gender"
6) "1"
set
Redis中的set相当于java中的HashSet,内部相当于实现了一个字典
特点
value唯一
操作
127.0.0.1:6379> sadd names amber
(integer) 1
127.0.0.1:6379> sadd names amber
(integer) 0
127.0.0.1:6379> sadd names nick wade
(integer) 2
127.0.0.1:6379> smembers names
1) "amber"
2) "wade"
3) "nick"
zset(sorted set)
Redis中的zset相当于java中sorted set和HashMap的结合。在set的基础上还可以给value赋予score(排序的权重)
特点
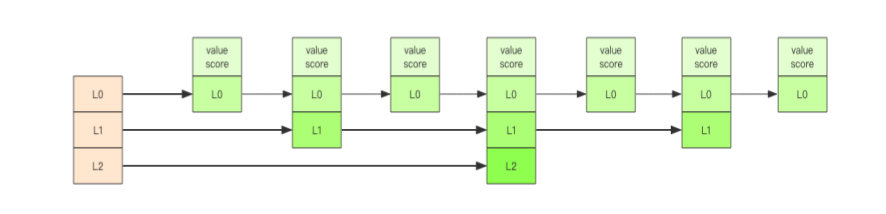
zset因为有score需要排序,但是采用普通的链表查找销量过低。因此zst采用层级制度。有点类似于国家->省级->市->xxx。最底层的乡镇肯帝就是我们的L0层级了,所有的元素都串联在一起,每个几个元素就选出市位于L2,同样的道理每隔几个L2层级的元素就选出省位于L3层级。当我们插入新的节点的时候,只需要从最顶层开始进行查找定位到相应位置就行了。是不是有点儿像数组的二分查找。
操作
其实还有一些操作,不过这里就不展示了
127.0.0.1:6379> zadd names 2 amber
(integer) 1
127.0.0.1:6379> zadd names 3 wade
(integer) 1
127.0.0.1:6379> zadd names 1 nick
(integer) 1
127.0.0.1:6379> zrange names 0 2
1) "nick"
2) "amber"
3) "wade"
127.0.0.1:6379>
数据结构知识点拓展
- redis的所有数据结构都可以设置时间
1. 设置时间
expire key 时间
2. 查看时间
ttl key

【Redis深度历险】那些年Redis的数据结构的更多相关文章
- 分布式Redis深度历险-Cluster
本文为分布式Redis深度历险系列的第三篇,主要内容为Redis的Cluster,也就是Redis集群功能. Redis集群是Redis官方提供的分布式方案,整个集群通过将所有数据分成16384个槽来 ...
- 分布式Redis深度历险-复制
Redis深度历险分为两个部分,单机Redis和分布式Redis. 本文为分布式Redis深度历险系列的第一篇,主要内容为Redis的复制功能. Redis的复制功能的作用和大多数分布式存储系统一样, ...
- Redis深度历险——核心原理与应用实践
高可用架构」的各位老铁们,你们好!你是否还记得上个月发布的文章中,有两篇深入讲解Redis的文章,分别是和,广大粉丝读者们对这两篇文章整体评价颇高.而我就是这两篇文章的原创作者「老钱」(钱文品),我是 ...
- Redis深度历险,全面解析Redis14个核心知识点
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取. 传送门: ...
- 《Redis深度历险:核心原理和应用实践》学习笔记一
1.redis五种数据结构 1.1 String字符串类型,对应java字符串类型 用户信息序列化后,可以用string类型存入redis中批量读写string类型,见效网络消耗数字类型的string ...
- 分布式Redis深度历险-Sentinel
上一篇介绍了Redis的主从服务器之间是如何同步数据的.试想下,在一主一从或一主多从的结构下,如果主服务器挂了,整个集群就不可用了,单点问题并没有解决.Redis使用Sentinel解决该问题,保障集 ...
- Redis 深度历险
学习资料 https://juejin.im/book/5afc2e5f6fb9a07a9b362527 包括下面几方面的内容 基础 应用 原理 集群 拓展 源码 to be done
- redis深度历险:核心原理与应用实践--笔记
- 《Redis深度历险:核心原理和应用实践》千帆竞发——分布式锁
随机推荐
- springboot新版本(2.0.0+)自定义ErrorController中使用ErrorAttributes
2.0.0之前使用: @Autowired private ErrorAttributes errorAttributes; private Map<String, Object> get ...
- Shell之命令执行的判断依据
目录 Shell之命令执行的判断依据 参考 Shell之命令执行的判断依据
- B/S 端 WebGL 3D 游戏机教程
前言 摘要:2D 的俄罗斯方块已经被人玩烂了,突发奇想就做了个 3D 的游戏机,用来玩俄罗斯方块...实现的基本想法是先在 2D 上实现俄罗斯方块小游戏,然后使用 3D 建模功能创建一个 3D 街机模 ...
- 夯实Java基础系列22:一文读懂Java序列化和反序列化
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial 喜欢的话麻烦点下 ...
- 安装sublime插件安装不上遇到的各种坑
为了学习VUE , 发现没有高亮代码, 百度原来需要安装插件,安装过程中遇到了各种坑,记录下来避免大家踩坑, 首先用代码安装快捷键 ctrl+` 粘贴代码 import urllib.reque ...
- Windows下IIS搭建Ftp服务器
第一步:启用Windows IIS Web服务器 1.1 控制面板中找到"程序"并打开 1.2 程序界面找到"启用或关闭Windows功能"并打开 1.3 上面 ...
- 设置Activity全屏的方法:
1)代码隐藏ActionBar 在Activity的onCreate方法中调用getActionBar.hide();即可 2)通过requestWindowFeature设置 requestWind ...
- 《深入理解Java虚拟机》-----第9章 类加载及执行子系统的案例与实战
概述 在Class文件格式与执行引擎这部分中,用户的程序能直接影响的内容并不太多, Class文件以何种格式存储,类型何时加载.如何连接,以及虚拟机如何执行字节码指令等都是由虚拟机直接控制的行为,用户 ...
- HTTPS 验证访问略记
背景 互联网刚刚兴起的时候,网络安全并没有被很好的重视.HTTP 是明文传输的,这为意图谋不道德之事者提供了诸多的便利.当越来越多的人利益受到侵害的时候,开始重视网络传输的安全问题了. HTTPS 加 ...
- MVC路径无匹配或请求api版本过低时处理
解决方案:RequestMappingHandlerMapping中重写handleNoMatch方法,springMVC和springboot中配置无区别. 另: 1.可搭配advice处理抛出的异 ...