AB实验的高端玩法系列3 - AB组不随机?观测试验?Propensity Score
背景
都说随机是AB实验的核心,为什么随机这么重要呢?有人说因为随机所以AB组整体不存在差异,这样才能准确估计实验效果(ATE)
\[
ATE = E(Y_t(1) - Y_c(0))
\]
那究竟随机是如何定义的呢? 根据Rubin Causal Model, 想要让上述估计无偏,随机实验需要满足以下两个条件:
- SUTVA
- 实验个体间不相互影响
- 实验个体间的treatment可比
- Ignorability(Unconfoundness是更强的假设)
是否受到实验干预和实验结果无关,从因果图的角度就是不存在同时影响treatment和outcome的其他变量
\[Y(1),Y(0) \perp Z \]
SUTVA在一般实验中是假定成立的,线上实验还好,很多线下实验很难保证这一点,像滴滴在部分地区投放更多车辆就会导致其他地区出现运力不足,所以个体间是隐含存在相互影响的。但这个不在本节讨论范围以内。
Ignorability在随机实验中,通过对样本随机采样得以保证。但是在观测性实验或者并未进行完全随机的实验中Ignorability是不成立的。解决办法就是把同时影响是否实验和实验结果的那些变量(Confounding Covariate)考虑进来得到conditional Ignorability。既
\[Y(1),Y(0) \perp Z | X\]
理论是如此,但X往往是未知且高维的。寻找X完全一样的样本来估计ATE并不现实,其中一个解决办法就是下面的Propensity Score Matching。名字很高端~计算较简单~使用需谨慎~
下面我介绍一下核心方法,并用kaggle一个医学相关数据集简单比较一下各个方法。
核心方法
原理
Propensity Score的核心方法分成两步,score的计算和score的使用。score计算如下:
\[
\text{Propensity Score} = P(Z=\text{treatment assignment}| X \in R^n)
\]
一种理解是它通过对影响Z的\(X \in R^N\)进行建模, 提炼所有Confounding Covariate的信息。另一种理解是把\(P(z|x)\)作为一种相似度(样本距离)的度量。我个人倾向于把它当作一种有目标的降维($N \to 1 $),或是聚类(相似样本)来理解。
然后基于score我们对样本进行聚合或匹配或加权,使样本满足上述的conditional Ignorability
Propensity Score 估计
估计本身就是一个经典的二分类问题,基于特征我们预测每个样本进入实验组的概率。几篇经典的paper(2011年之前)都是用LogisticRegression来解决问题,但放在今天xgBoost和LGB等等集合树算法在特征兼容和准确率上应该会表现更好。而且树对于样本划分的方式天然保证了叶节点的样本有相同的打分和相似的特征。[当然要是你的数据太小LR还是首选]
这里说两个建模时需要注意的点:
1. 特征选择
这里的特征可以大体被分为三类
- 影响treatment
- 影响outcome
- 同时影响treatment和outcome的confounder
毫无疑问confounder是必须要有的,移除confounding Bias是AB实验的核心。但是是否加入只影响treatment和outcome的特征不同论文给出了不同的观点。
结合各方结论,加入对outcome有影响的特征是okay的,其实结合上一篇AB实验的高端玩法系列2 - 更敏感的AB实验, CUPED!,可以发现加入对outcome有影响的特征近似于变相使用了CUPED,可能降低实验核心指标估计的方差。
加入只对treatment有影响的特征,可能会导致实验组和对照组样本的Propensity score最终分布重合度变低,导致部分实验样本找不到匹配的对照样本,需要谨慎考虑。
2. 模型检验
只用AUC,cross-entropy来评价模型的拟合在这里是不够的。这涉及到Propensity Score的Balancing性质:
\[
Z \perp X | PropensityScore
\]
简单说就是Score相近的样本,X也要相似。这里你可以直接用可视化boxplot/violinplot来检验,也可以更精确的用T-test等统计手段来检验X是否存在差异。
Score使用
Propensity Score通常有4种用法,我们逐一简单介绍一下
matching
一句话说按Propensity给实验组对照组进行配对。
按score对每一个实验组样本进行[1/N个][有/无放回]的样本匹配。这里的参数选择除了现实数据量的限制,一样是Bias-Variance的权衡。因此可以考虑根据样本量,在score相差小于阈值的前提下,分别计算1~N个匹配样本下的ATE,如果结果差异过大(sensitivity),则方法本身需要调整。
也有相应的trim方法旨在剔除score取值极端无法找到匹配的样本(eg. \(score \to 0\))。但在一些场景下trim方法会被质疑。( 小明:你扔掉了一些高收入的样本ROI肯定打不平啊怎么能这么算呢>_<)
在数据量允许情况下,我更倾向于Nto1有放回的匹配,因为大多数场景下都是无法完全考虑所有Covariate的,意味着Propensity score的估计一定在一些特征上是有偏差的,这种时候取多个样本匹配是可能降低偏差的
stratification
一句话说按相似Propensity对实验组对照组进行分组在组内计算ATE再求和。
具体怎么分组没有确定规则,只要保证每组内有足够的实验组对照组样本来计算ATE即可。这里一样是Bias-Variace的权衡,分组越多Bias越少方差越大。通常有两种分位数分桶方法
- 对全样本propensity score按人数等比例分组
- 对人数较少(通常是实验组)按人数确定分组边界
这里一样可以使用trim,但是请结合具体业务场景仔细考虑。
Inverse probability of treatment weighting(IPTW)
一句话说按Propensity score的倒数对样本进行加权。
一个完全随机的AB实验,Propensity Score应该都在0.5附近,而不完全随机的实验在用Propensity score调整后在计算ATE时Z也会被调整为等权,如下:
\[
\begin{align}
e &= P(Z=1|x) \\
w &= \frac{z}{e} + \frac{1-z}{1-e} \\
ATE & = \frac{1}{n}\sum_{i=1}^n\frac{z_iY_i}{e_i} - \sum_{i=1}^n\frac{(1-z_i)Y_i}{1-e_i}
\end{align}
\]
个人对这种方法持保留意见,原因有2: 其一上述matching和stratification虽然使用了score,但本质是使用了score给出的样本相似度的排序,而并没有使用score本身,所以对score估计的准确有一定容忍度。其二拿score做分母很容易碰到\(score \to 0/1\)从而导致的的极端值问题,这就需要人工调整,而调整本身是否合理也会被质疑。
Covariate adjusted
一句话说我没怎么接触过这种方法,也把model-dependency应用在这里不太感冒 >.<,有兴趣的朋友自己探索吧。要是以后发现它好用再加回来
应用示例
数据来源是Kaggle的开源数据集 Heart Disease UCI[数据链接]
数据本身是根据人们的性别,年龄,是否有过心口痛等医学指标预测人们患心脏病的概率。
数据量和特征都很少,以下仅用作方法探索,不对结果置信度做讨论
这里我们把数据当作一个观测性实验的样本,实验目的变成女性(sex=0)是否男性(sex=1)更易患上心脏病。数据如下:
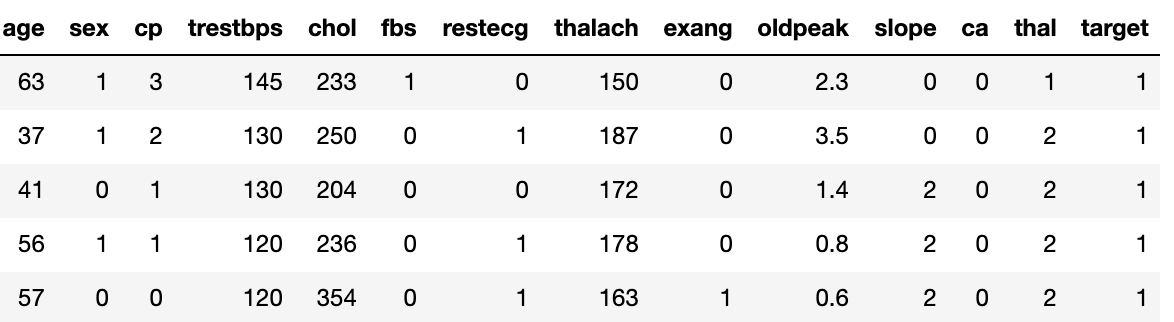

直接从数据计算男性比女性患心脏病的概率低30%!WHAT?!
考虑到数据非常小,我们用LR估计Propensity Score,男女的score分布如下
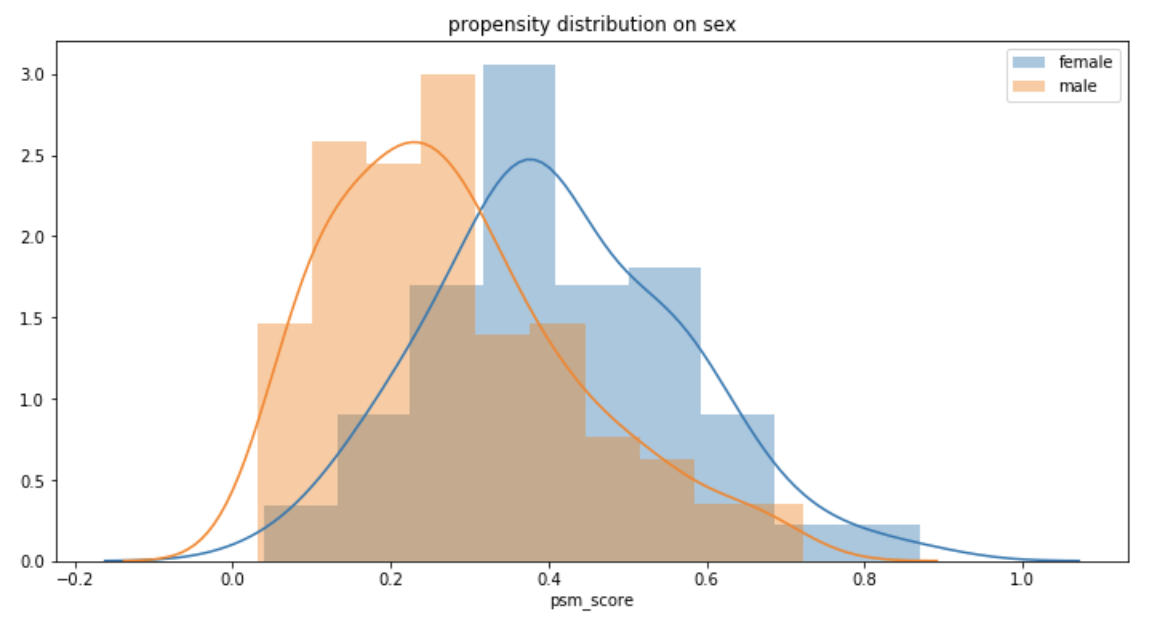
下面我分别使用了stratification,matching和IPTW来估计ATE
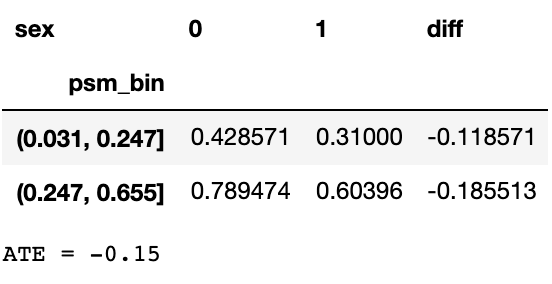
stratification
我分别尝试用实验组和用全样本找分位点的方式来计算ATE, 用实验组估计分位点时分3组会有一组对照组样本太少,于是改成2组。结果比较相似ATE在-0.15 ~ 0.16。比直接用全样本估计降低了一半!
这里stratification分组数的确定,需要在保证每组有足够的treatment和control样本的基础上,保证每组的Covariate分布相似

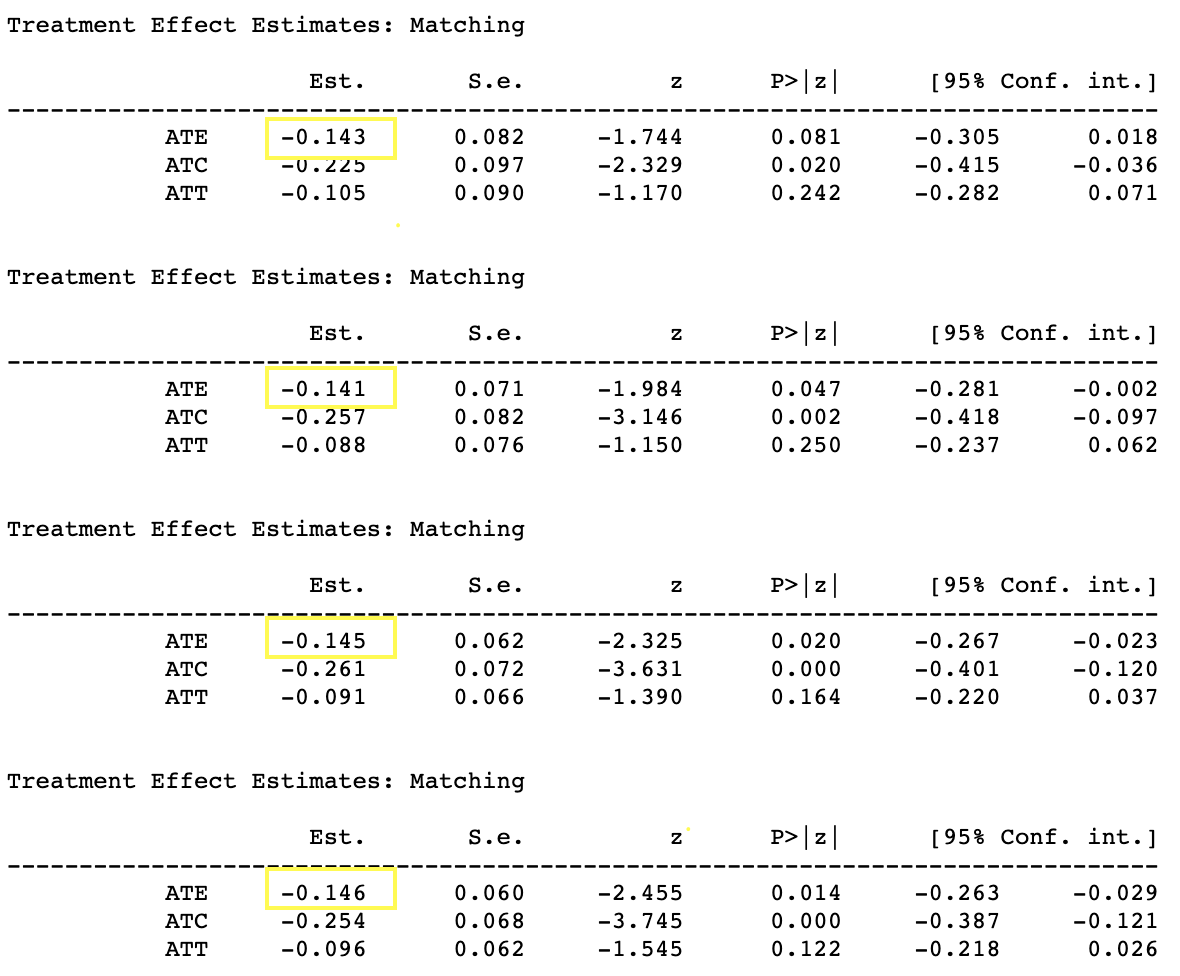
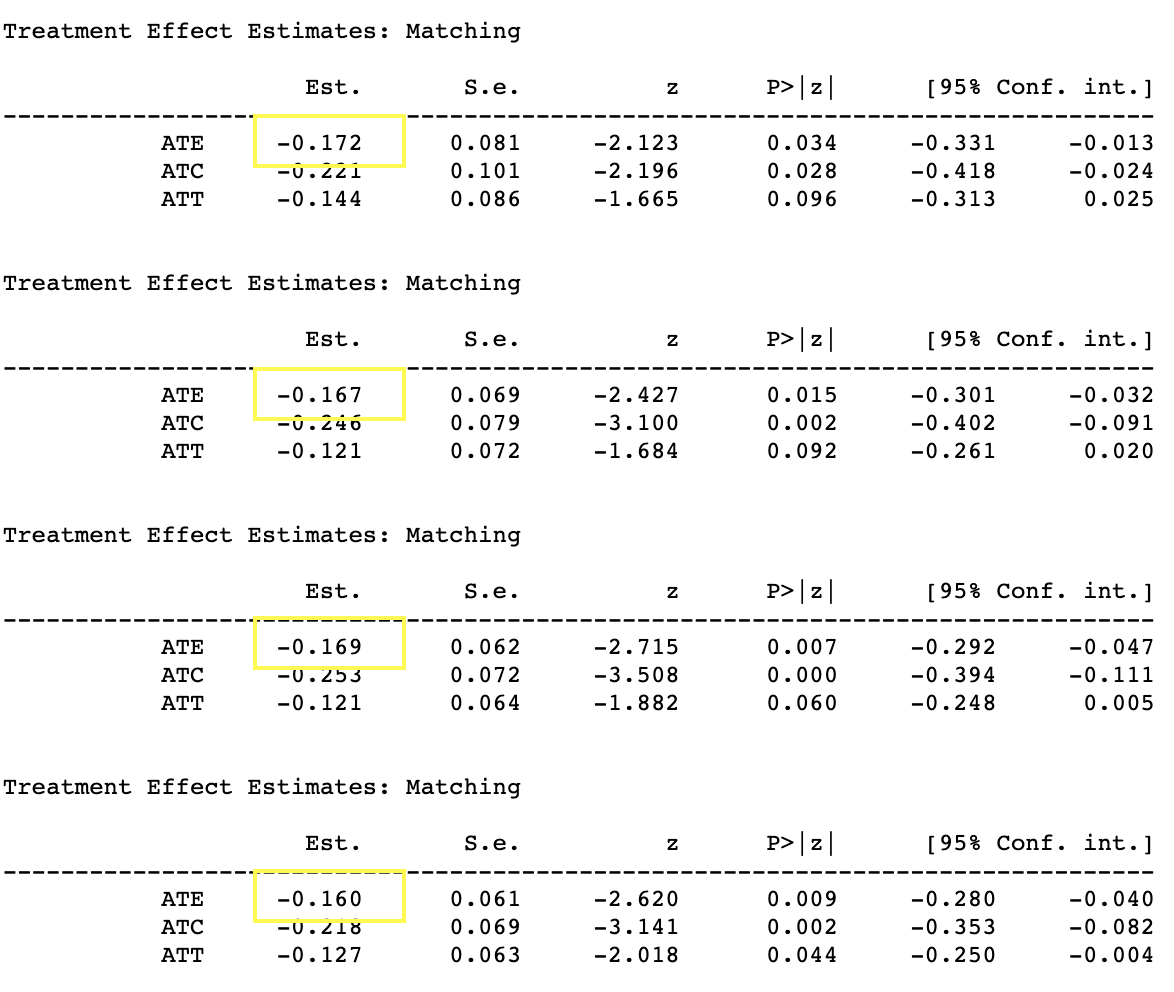
matching
以下结果分别是:有trim & match 1~4 + 无trim & match1~4。最终估计的ATE和上述stratification的结果相似ATE在-0.15~-0.16直接。而且相对稳健匹配数量并没有对ATE计算产生过大影响。
我们发现随着匹配的样本上升ATE会越来越显著,所以match的N越大越好?其实并不是,因为P值是样本量的函数,随着样本量上升'微小'的变动也会变显著。所以个人觉得选择最佳的N这里并不十分重要,比较ATE对不同的N是否稳定可能更有意义。
IPTW
。。。预料之中,这个结果是比较奇怪的。一方面数据少(100多),另一方面confonder特征也少,Score的拟合肯定不好。所以得到的竟然是正向的结果。。。
PSM差不多就说这么多,欢迎各种反馈各种评论~下一节我们讨论实验渗透低/效果稀释该怎么办? 对这个系列感兴趣的的盆友,
AB实验的高端玩法系列3 - AB组不随机?观测试验?Propensity Score的更多相关文章
- AB实验的高端玩法系列4- 实验渗透低?用户未被触达?CACE/LATE
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect.在观测数据中的应用需要和Instrument Variable ...
- AB实验的高端玩法系列2 - 更敏感的AB实验, CUPED!
背景 AB实验可谓是互联网公司进行产品迭代增加用户粘性的大杀器.但人们对AB实验的应用往往只停留在开实验算P值,然后let it go...let it go ... 让我们把AB实验的结果简单的拆解 ...
- 第四模块MySQL50题作业,以及由作业引申出来的一些高端玩法
一.表关系 先参照如下表结构创建7张表格,并创建相关约束 班级表:class 学生表:student cid caption grade_id ...
- Word 查找替换高级玩法系列之 -- 把论文中的缩写词快速变成目录下边的注释表
1. 前言 问题:Word写论文如何把文中的缩写快速转换成注释表? 原来样子: 想要的样子: 2. 步骤 使用查找替换高级用法,替换缩写顺序 选中所有文字 打开查找替换对话框,输入以下表达式: 替换后 ...
- windows下mongodb基础玩法系列二CURD附加一
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- windows下mongodb基础玩法系列二CURD操作(创建、更新、读取和删除)
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- windows下mongodb基础玩法系列一介绍与安装
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- Word 查找替换高级玩法系列之 -- 段首批量添加字符
打开「查找和替换」输入框,按照下图操作: 更多查找替换高级玩法,参看:Word查找替换高级玩法系列 -- 目录篇 未完 ...... 点击访问原文(进入后根据右侧标签,快速定位到本文)
- Hadoop大数据零基础高端实战培训系列配文本挖掘项目
随机推荐
- springboot 集成Redis单机
1.redis服务搭建 centos7 搭建redis服务 2.接入相关 pom文件依赖引入 <dependencies> <dependency> <groupId&g ...
- POJ 2533——Longest Ordered Subsequence(DP)
链接:http://poj.org/problem?id=2533 题解 #include<iostream> using namespace std; ]; //存放数列 ]; //b[ ...
- xpath语法分享
# xpath语法: ## 使用方式: 使用//获取整个页面当中的元素,然后写标签名,然后再写谓词进行提取.比如: ``` //div[@class='abc'] ``` ## 需要注意的知识点: 1 ...
- [JavaScript] 《JavaScript高级程序设计》笔记
1.|| 和 && 这两个逻辑运算符和c#是类似的,都是惰性的计算 a() || b() 若a()为真返回a()的结果,此时b()不计算: a()为假则返回b() a() &am ...
- Android NDK(二) CMake构建工具进行NDK开发
本文目录 一Androidstudio中需要的插件 二项目配置 ①build.gardle配置 ②CMakeLists.txt ③Android和Cpp的代码 ④so文件生成 ⑤so文件的位置 一.A ...
- SpringBoot返回JSON
目录 1.SpringBoot返回JSON简介 2.整合jackson-databind 3.整合Gson 4.整合fastjson 1.SpringBoot返回JSON简介 随着web开发前后端分离 ...
- springboot+thymeleaf国际化方法一:LocaleResolver
springboot中大部分有默认配置所以开发起项目来非常迅速,仅对需求项做单独配置覆盖即可 spring采用的默认区域解析器是AcceptHeaderLocaleResolver,根据request ...
- React入门学习
为了获得更好的阅读体验,请访问原地址:传送门 一.React 简介 React 是什么 React 是一个起源于 Facebook 的内部项目,因为当时 Facebook 对于市场上所有的 JavaS ...
- kubernetes垃圾回收器GarbageCollector源码分析(一)
kubernetes版本:1.13.2 背景 由于operator创建的redis集群,在kubernetes apiserver重启后,redis集群被异常删除(包括redis exporter s ...
- 【THE LAST TIME】this:call、apply、bind
前言 The last time, I have learned [THE LAST TIME]一直是我想写的一个系列,旨在厚积薄发,重温前端. 也是给自己的查缺补漏和技术分享. 欢迎大家多多评论指点 ...
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect.在观测数据中的应用需要和Instrument Variable ...
背景 AB实验可谓是互联网公司进行产品迭代增加用户粘性的大杀器.但人们对AB实验的应用往往只停留在开实验算P值,然后let it go...let it go ... 让我们把AB实验的结果简单的拆解 ...
一.表关系 先参照如下表结构创建7张表格,并创建相关约束 班级表:class 学生表:student cid caption grade_id ...
1. 前言 问题:Word写论文如何把文中的缩写快速转换成注释表? 原来样子: 想要的样子: 2. 步骤 使用查找替换高级用法,替换缩写顺序 选中所有文字 打开查找替换对话框,输入以下表达式: 替换后 ...
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
打开「查找和替换」输入框,按照下图操作: 更多查找替换高级玩法,参看:Word查找替换高级玩法系列 -- 目录篇 未完 ...... 点击访问原文(进入后根据右侧标签,快速定位到本文)
1.redis服务搭建 centos7 搭建redis服务 2.接入相关 pom文件依赖引入 <dependencies> <dependency> <groupId&g ...
链接:http://poj.org/problem?id=2533 题解 #include<iostream> using namespace std; ]; //存放数列 ]; //b[ ...
# xpath语法: ## 使用方式: 使用//获取整个页面当中的元素,然后写标签名,然后再写谓词进行提取.比如: ``` //div[@class='abc'] ``` ## 需要注意的知识点: 1 ...
1.|| 和 && 这两个逻辑运算符和c#是类似的,都是惰性的计算 a() || b() 若a()为真返回a()的结果,此时b()不计算: a()为假则返回b() a() &am ...
本文目录 一Androidstudio中需要的插件 二项目配置 ①build.gardle配置 ②CMakeLists.txt ③Android和Cpp的代码 ④so文件生成 ⑤so文件的位置 一.A ...
目录 1.SpringBoot返回JSON简介 2.整合jackson-databind 3.整合Gson 4.整合fastjson 1.SpringBoot返回JSON简介 随着web开发前后端分离 ...
springboot中大部分有默认配置所以开发起项目来非常迅速,仅对需求项做单独配置覆盖即可 spring采用的默认区域解析器是AcceptHeaderLocaleResolver,根据request ...
为了获得更好的阅读体验,请访问原地址:传送门 一.React 简介 React 是什么 React 是一个起源于 Facebook 的内部项目,因为当时 Facebook 对于市场上所有的 JavaS ...
kubernetes版本:1.13.2 背景 由于operator创建的redis集群,在kubernetes apiserver重启后,redis集群被异常删除(包括redis exporter s ...
前言 The last time, I have learned [THE LAST TIME]一直是我想写的一个系列,旨在厚积薄发,重温前端. 也是给自己的查缺补漏和技术分享. 欢迎大家多多评论指点 ...