Python爬虫(学习准备)
编码格式的认识:
- 字符:各种文字和符号的统称
- 字符集:多个字符的集合
- 字符集包括:ASCII字符集,GB2312字符集,GB18030,Unicode字符集等
- 1个字符ASCII编码占1个字节,用Unicode编码占2个字节
- UTF-8是Unicode的实习方式之一,是一种变长的编码方式,可以是1,2,3个字节等
在Python中字符串分为两种类型:
- bytes:二进制,互联网上数据都是以二进制传输
- str:unicode的呈现方式
str与bytes的转换:
encode() #str->bytes
decode() #bytes->str
- a = '华南理工大学广州学院'
- print(type(a)) #<class 'str'>
- b = a.encode() #参数不填默认utf-8编码
- print(b)
- print(type(b)) #<class 'bytes'>
- a = b.decode('utf-8')
- print(a) #华南理工大学广州学院
cookie和session区别:
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗
- session会在一定时间内保存在服务器。当访问增多,会比较占服务器性能
- 单个cookie保存的数据不能超过4k,很多浏览器都限制一个站点最多保存20个cookie
Http和Https:
Http
- 超文本传输协议
- 默认端口号:80
Https
- Http + ssl(安全套接字层)
- 默认端口号:443
Https比http更安全,但是性能更低(耗时更长)
Url的形式:

http请求格式:

http常见请求头:

常见响应状态码:
- 200:成功
- 302:转移至新的url
- 307:转移至新的url
- 404:not found
- 500:服务器内部错误
爬虫的分类:
- 通用爬虫:通常指搜索引擎的爬虫
- 聚焦爬虫:针对特定网站的爬虫
通用爬虫与聚焦爬虫的流程:
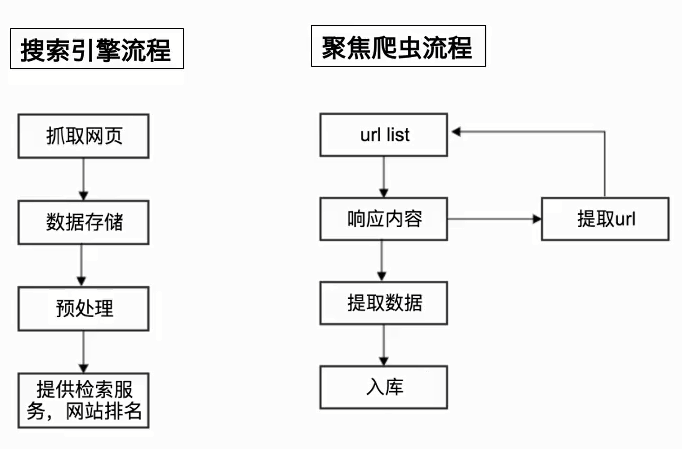
Robots协议:
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取
浏览器发送Http请求的过程:
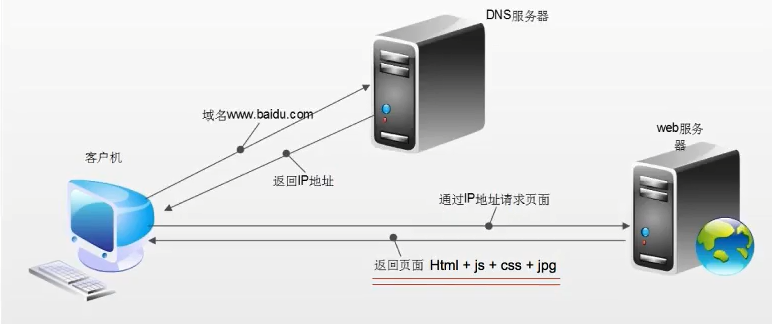
浏览器渲染出来的页面与爬虫请求的页面不一样
Python爬虫(学习准备)的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
随机推荐
- Linux - CentOS 7 通过Yum源安装 Nginx
添加源 sudo rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.no ...
- JVM进入老年代情况
1.躲过15次GC之后进入老年代 默认的设置下,当对象的年龄达到15岁的时候,也就是躲过15次Gc的时候,他就会转移到老年代中去 这个具体是多少岁进入老年代,可以通过JVM参数 “-XX:MaxTen ...
- springboot + springcloud +nacos实战
首先从整个软件的功能和应用场景来说,nacos更像consul,而非eureka,nacos设计的时候自带的配置中心功能,让我们省下了去搞springcloud config的时间,但这里并不是说na ...
- Complete_NGINX_Cookbook
Complete NGINX Cookbook 下载地址:Complete NGINX Cookbook
- condense 参数
" 删除左右空格,中间空格压缩至一格 result = condense( ' abc def ').result = condense( val = ' abc def '). " ...
- windows 下使用批处理执行 postgresql 命令行操作
1.准备好命令文件 loraserver.sql create role loraserver_as with login password 'dbpassword'; create role lor ...
- Linux搭建图片服务器减轻传统服务器的压力(nginx+vsftpd)
传统项目中的图片管理 传统项目中,可以在web项目中添加一个文件夹,来存放上传的图片.例如在工程的根目录WebRoot下创建一个images文件夹.把图片存放在此文件夹中就可以直接使用在工程中引用. ...
- 【2期】JVM必知必会
JVM之内存结构图文详解 Java8 JVM内存结构变了,永久代到元空间 Java GC垃圾回收机制 不要再问我“Java 垃圾收集器”了 Java虚拟机类加载机制 Java虚拟机类加载器及双亲委派机 ...
- ism 发布
ism 发布 ism 发布 ism 发布
- 三feng云,免费虚拟主机和免费云服务器
三feng云,免费虚拟主机和免费云服务器 链接:https://www.sanfengyun.com 虚拟主机 虚拟服务器 BGP多线路 独立IP地址 送免备案系统,永久免费 具备高在线率.高安全性. ...