大数据学习——spark学习
计算圆周率
[root@mini1 bin]# ./run-example SparkPi
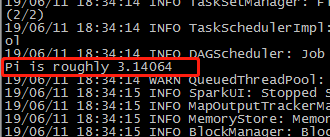
[root@mini1 bin]# ./run-example SparkPi

[root@mini1 bin]# ./run-example SparkPi

运行spark-shell的两种方式:
1直接运行spark-shell
单机通过多线程跑任务,只运行一个进程叫submit
2运行spark-shell --master spark://mini1:7077
将任务运行在集群中,运行submit在master上,运行executor在worker上
启动
[root@mini1 bin]# ./spark-shell
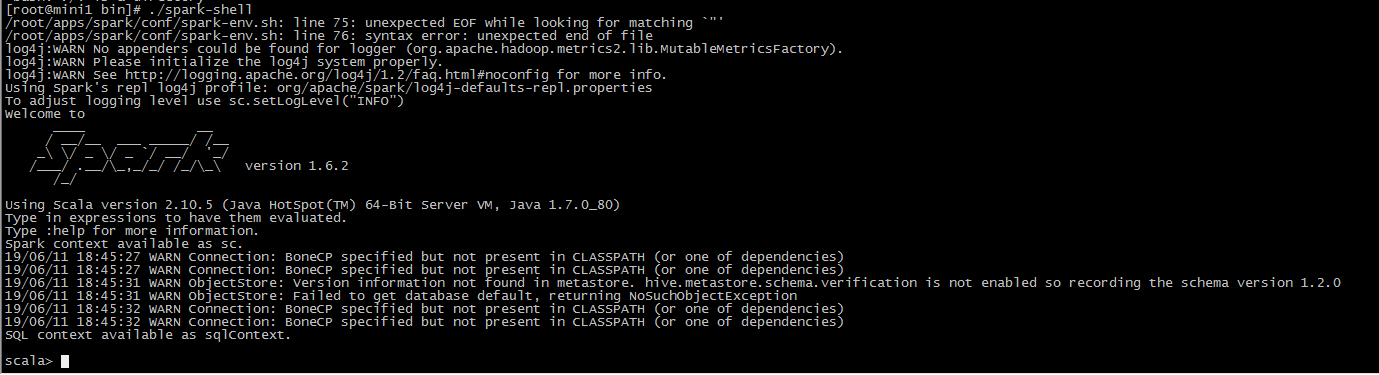
hdfs
hadoop/sbin/start-dfs.sh

计算wordcount
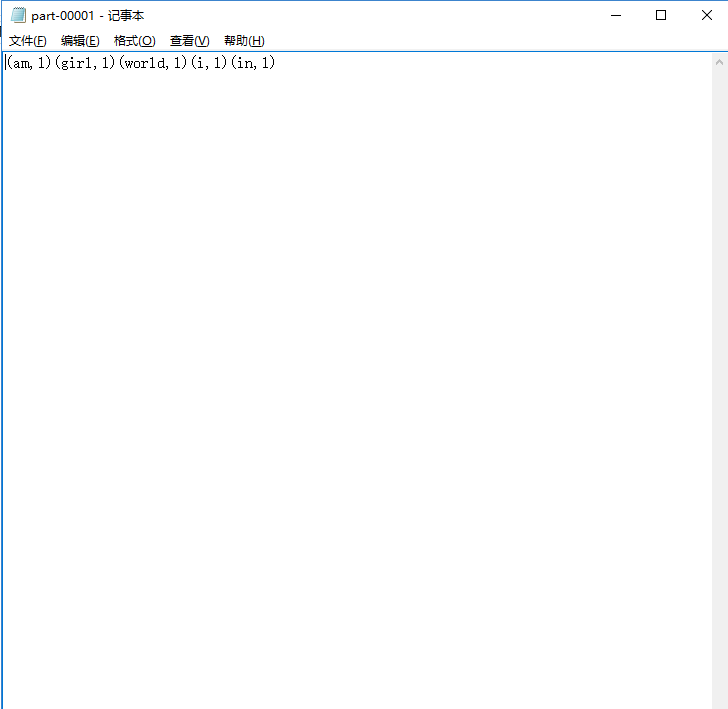
sc.textFile("/root/words.txt").flatMap(_.split(" ")).map((_,)).reduceByKey(_+_).collect

升序,降序排列

mapReduce执行流程
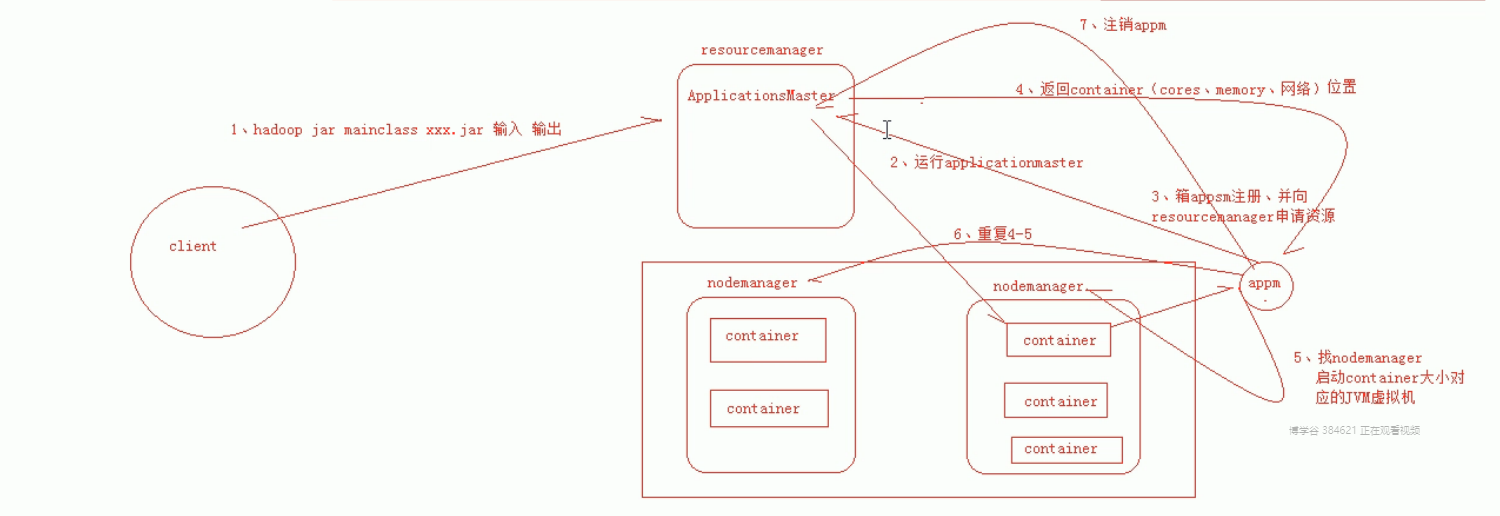
从hdfs采集数据
上传文件 hdfs dfs -put words.txt /
sc.textFile("hdfs://mini1:9000/words.txt").flatMap(_.split(" ")).map((_,)).reduceByKey(_+_).sortBy(_._2,false).collect
通过spark的api写wordcount
本地运行
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} /**
* Created by Administrator on 2019/6/11.
*/
object WordCount extends App {
//创建conf,设置应用的名字和运行的方式,local[2]运行2线程,产生两个文件结果 val conf = new SparkConf().setAppName("wordcount").setMaster("local[2]") //创建sparkcontext
val sc = new SparkContext(conf) val file: RDD[String] = sc.textFile("hdfs://mini1:9000/words.txt")
val words: RDD[String] = file.flatMap(_.split(" "))
//压平,分割每一行数据为每个单词
val tuple: RDD[(String, Int)] = words.map((_, 1))
//将单词转换为(单词,1)
val result: RDD[(String, Int)] = tuple.reduceByKey(_ + _)
//将相同的key进行汇总聚合
val resultSort: RDD[(String, Int)] = result.sortBy(_._2, false) //排序
// result.collect() //在命令行打印
resultSort.foreach(println) }
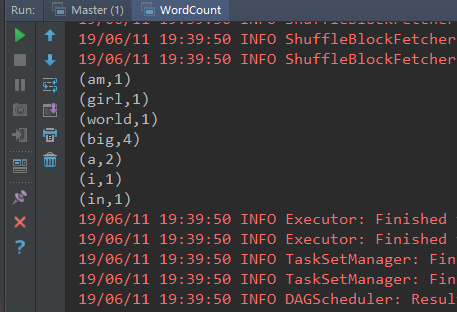
集群运行
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} /**
* Created by Administrator on 2019/6/11.
*/
object WordCount {
def main(args: Array[String]) { //创建conf,设置应用的名字和运行的方式,local[2]运行2线程,产生两个文件结果
//.setMaster("local[1]")采用1个线程,在本地模拟spark运行模式
val conf = new SparkConf().setAppName("wordcount") //创建sparkcontext
val sc = new SparkContext(conf) val file: RDD[String] = sc.textFile("hdfs://mini1:9000/words.txt")
val words: RDD[String] = file.flatMap(_.split(" "))
//压平,分割每一行数据为每个单词
val tuple: RDD[(String, Int)] = words.map((_, 1))
//将单词转换为(单词,1)
val result: RDD[(String, Int)] = tuple.reduceByKey(_ + _)
//将相同的key进行汇总聚合
val resultSort: RDD[(String, Int)] = result.sortBy(_._2, false) //排序
resultSort.saveAsTextFile(args(1)) } }
打包
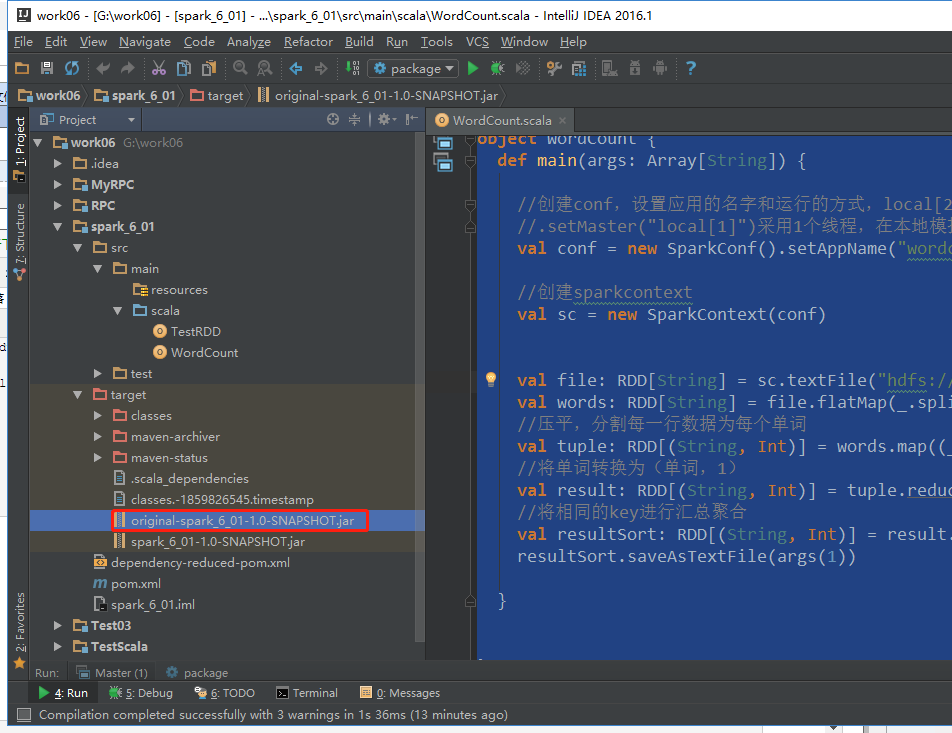

把该代码包传到任意一台装有spark的机器上

我上传到了bin下

提交
[root@mini1 bin]# ./spark-submit --help
#开始加了这两个参数 导致一直运行失败,链接超时,还去问了初夏老师
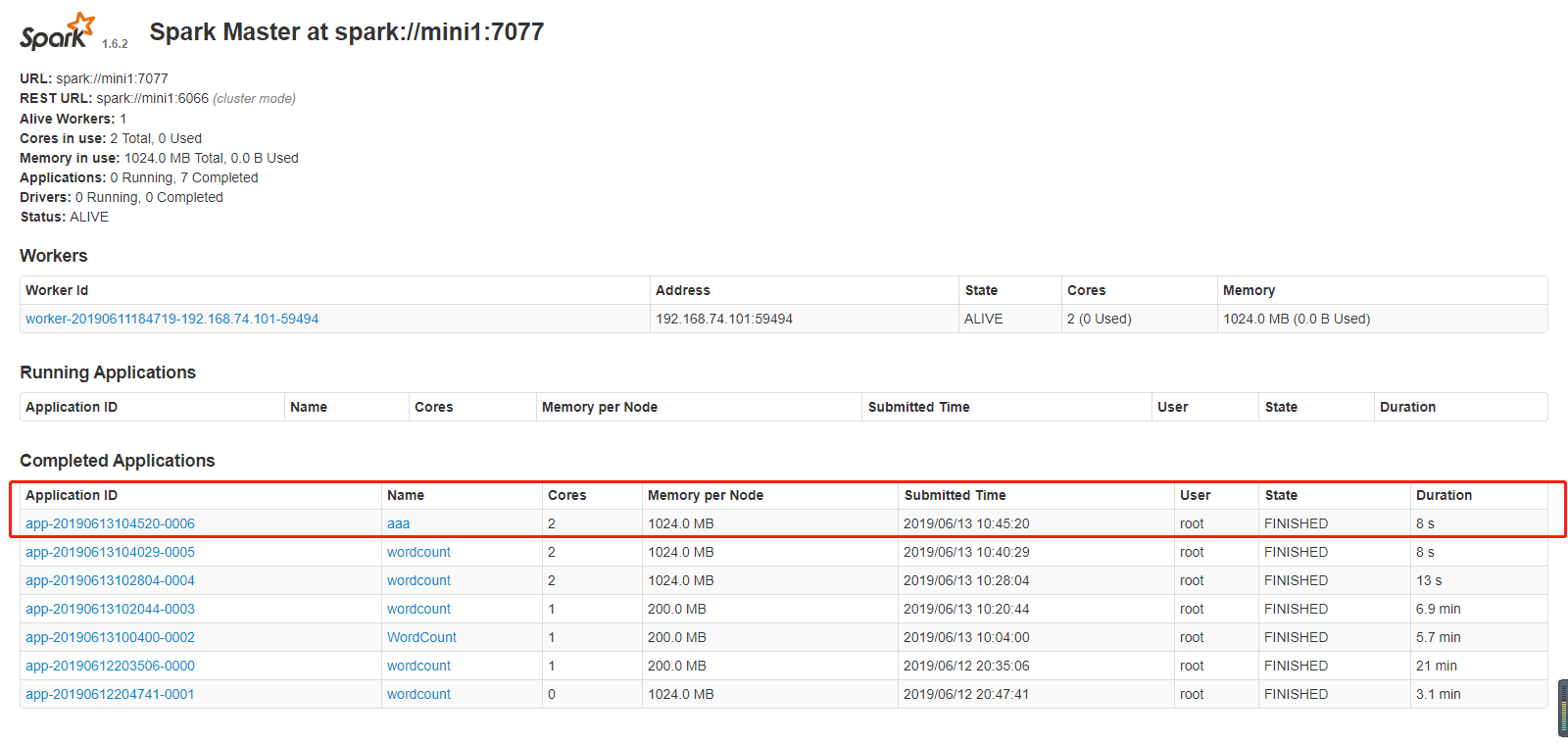
[root@mini1 bin]# ./spark-submit --master spark://mini1:7077--class com.cyf.WordCount --executor-memory 200M --total-executor-cores 1 original-spark_6_01-1.0-SNAPSHOT.jar hdfs://mini1:9000/words.txt hdfs://mini1:9000/ceshi/wordcountcluster
[root@mini1 bin]#./spark-submit --master spark://mini1:7077 --class com.cyf.WordCount original-spark_6_01-1.0-SNAPSHOT.jar hdfs://mini1:9000/words.txt hdfs://mini1:9000/ceshi/wordcountcluster
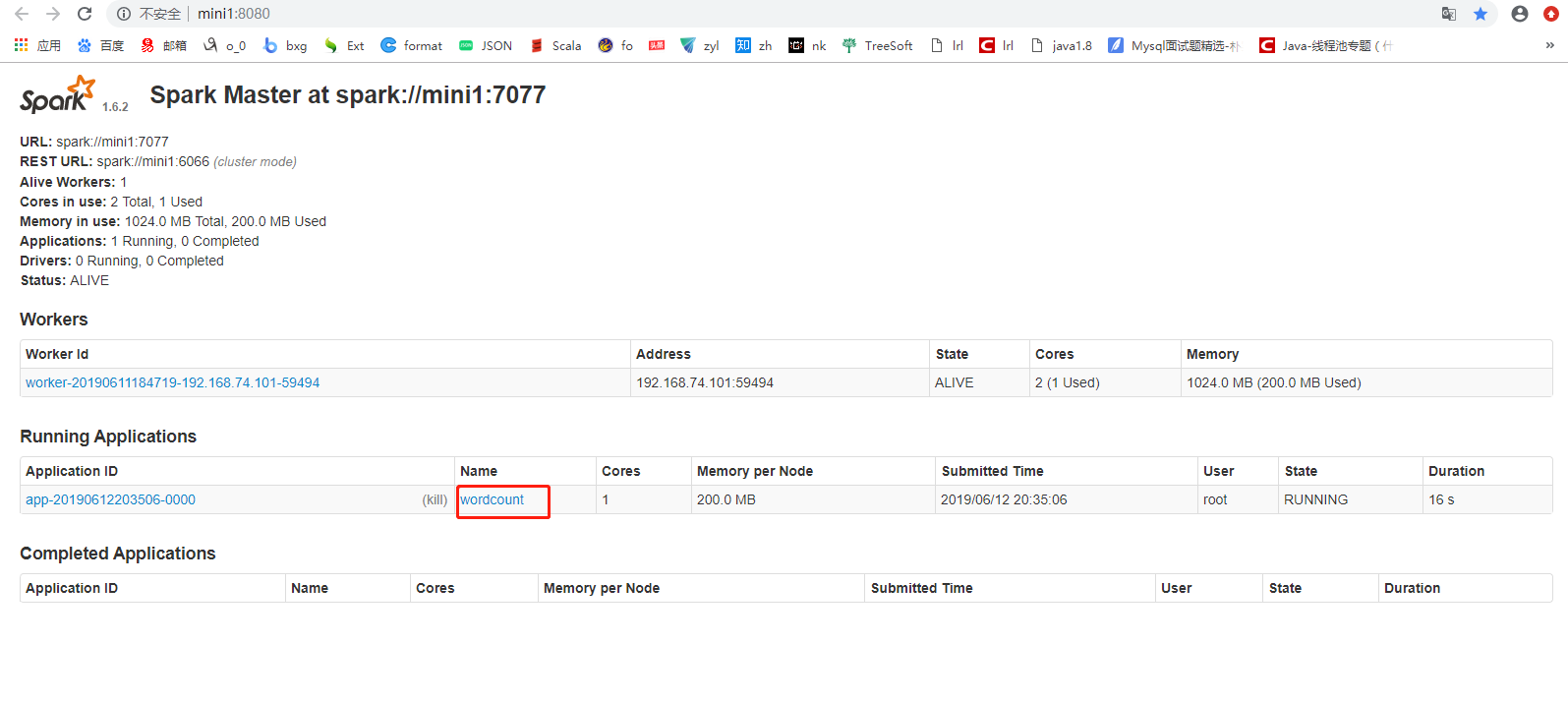
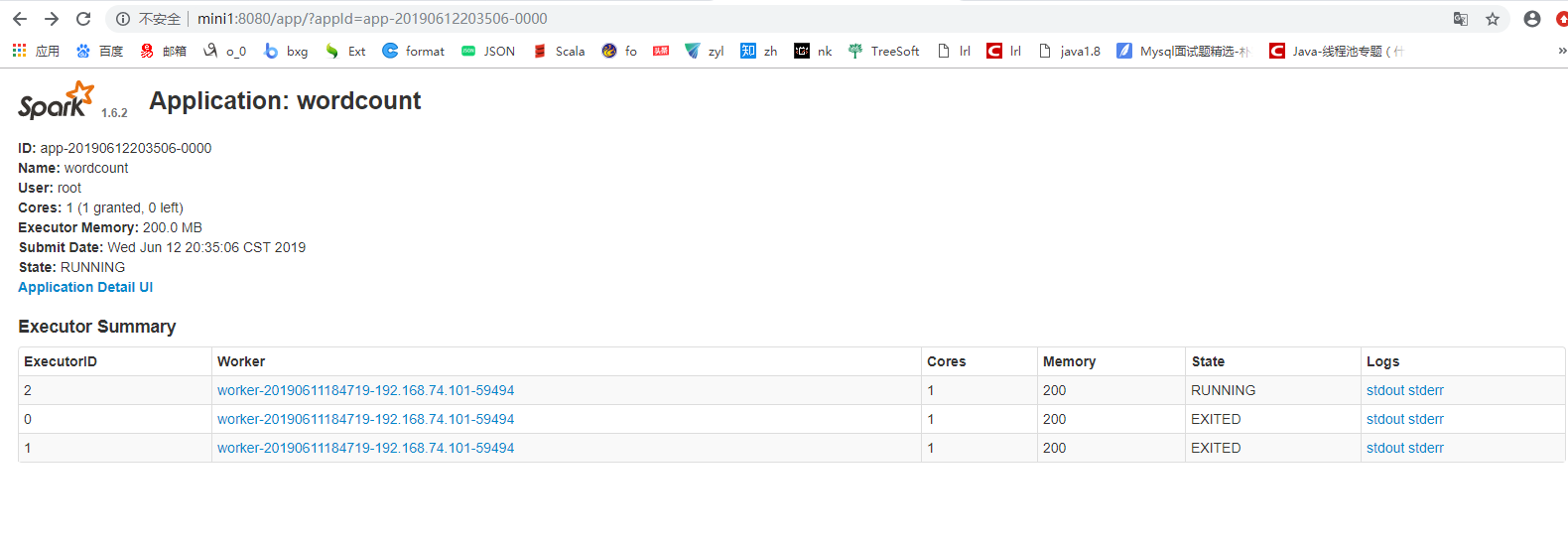
开始加上边两个参数运行,一直报连接超时的错误
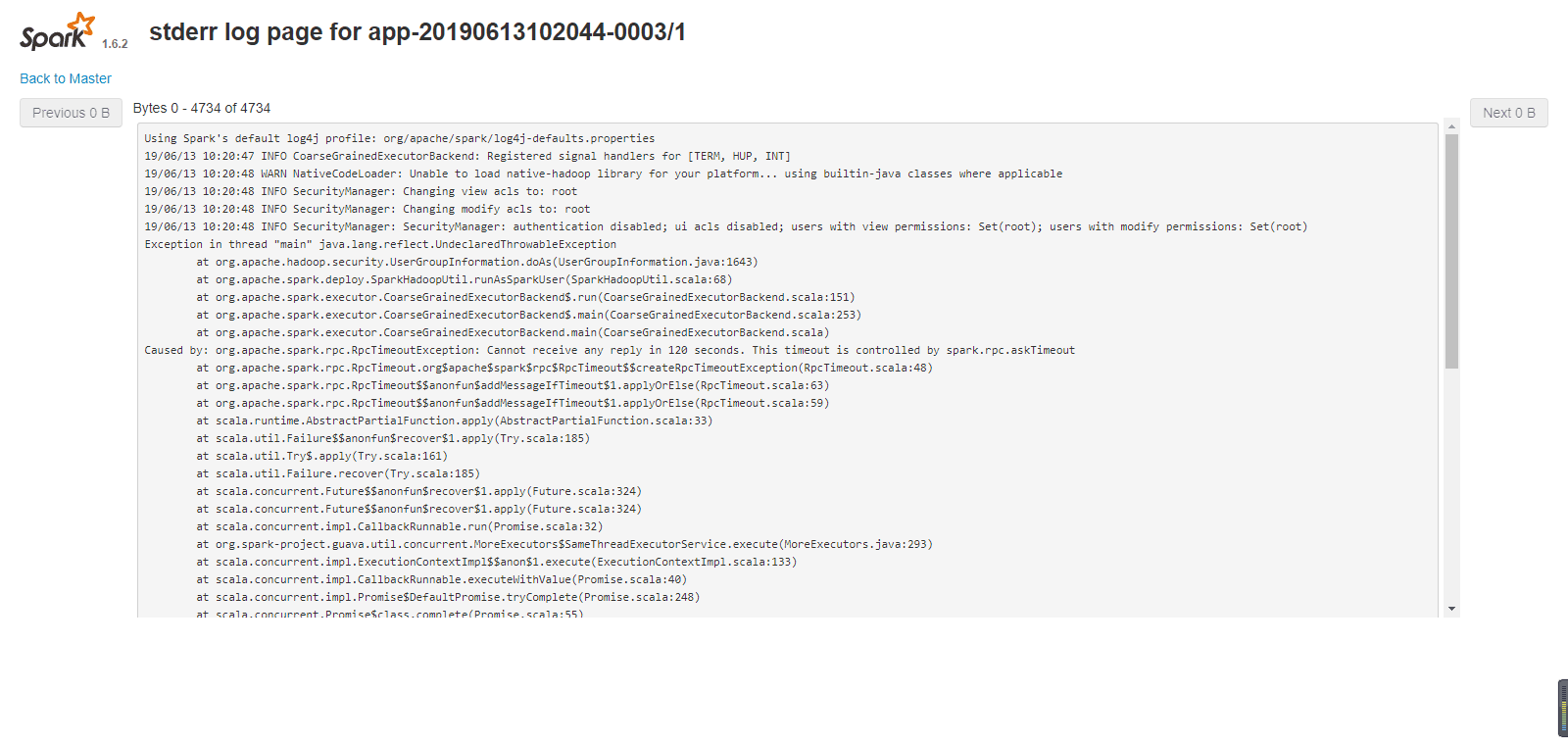
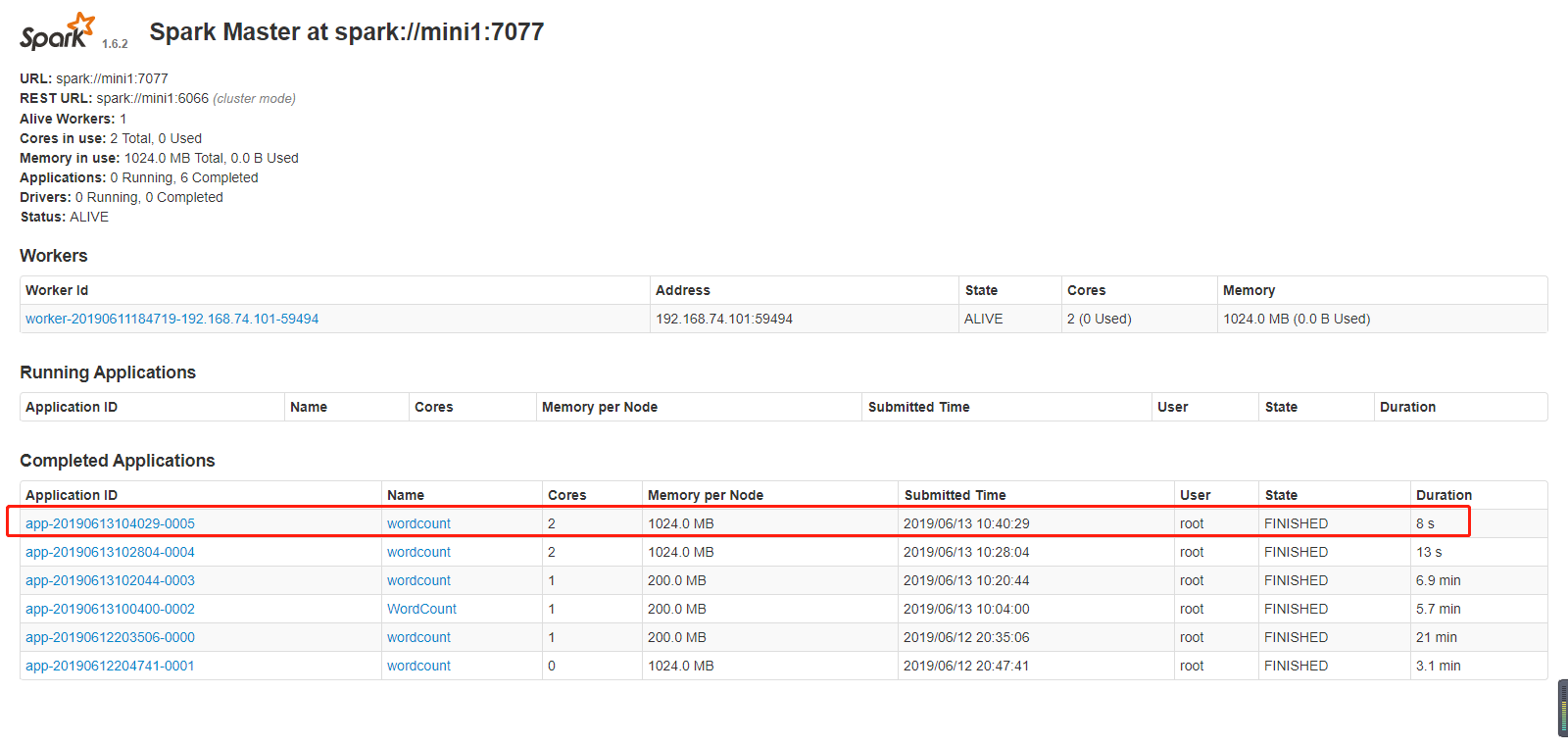
后来把参数去掉,运行成功了


python
wo.py
#!/usr/bin/python
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("aaa").setMaster("spark://mini1:7077")
sc = SparkContext(conf=conf)
data = ["tom", "lilei", "tom", "lilei", "wangsf"]
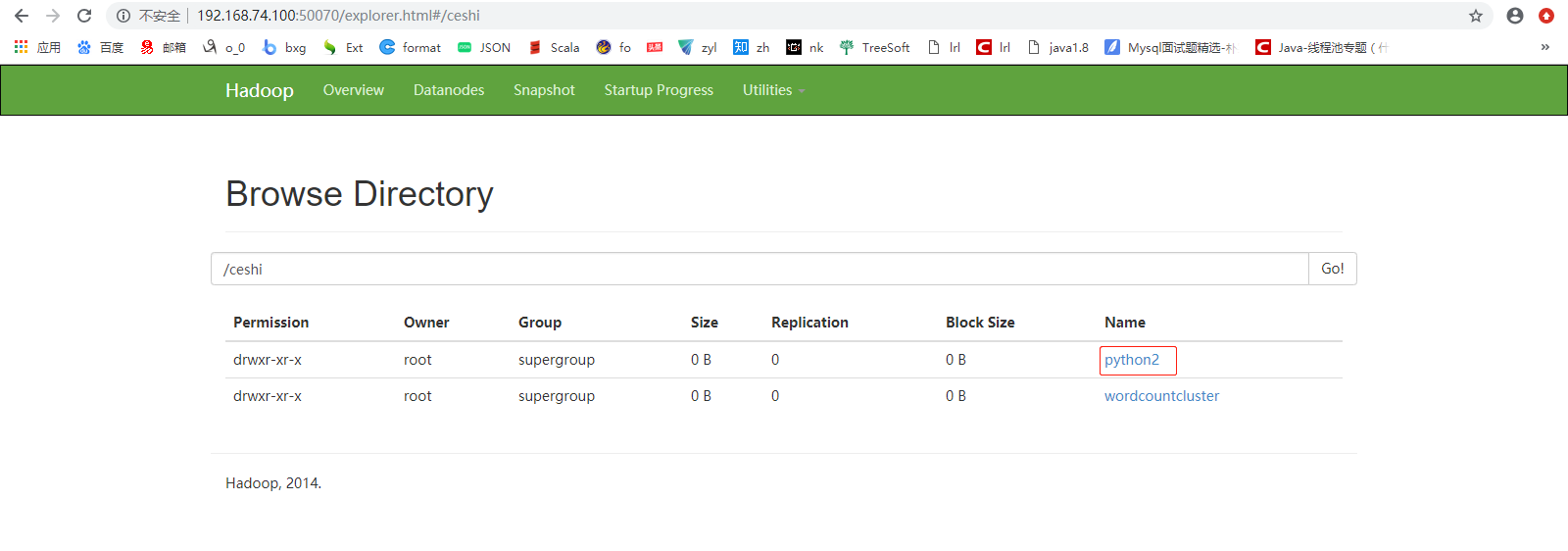
rdd = sc.parallelize(data).map(lambda x: (x, )).reduceByKey(lambda a, b: a + b).saveAsTextFile("hdfs://mini1:9000/ceshi/python2")
上传,运行
[root@mini1 bin]# ./spark-submit wo.py


大数据学习——spark学习的更多相关文章
- 【福利】送Spark大数据平台视频学习资料
没有套路真的是送!! 大家都知道,大数据行业spark很重要,那话我就不多说了,贴心的大叔给你找了份spark的资料. 多啰嗦两句,一个好的程序猿的基本素养是学习能力和自驱力.视频给了你们,能不能 ...
- 【互动问答分享】第8期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第8期互动问答分享] Q1:spark线上用什么版本好? 建议从最低使用的Spark 1.0.0版本,Spark在1.0.0开始核心 ...
- 【互动问答分享】第15期决胜云计算大数据时代Spark亚太研究院公益大讲堂
"决胜云计算大数据时代" Spark亚太研究院100期公益大讲堂 [第15期互动问答分享] Q1:AppClient和worker.master之间的关系是什么? AppClien ...
- 【互动问答分享】第13期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第13期互动问答分享] Q1:tachyon+spark框架现在有很多大公司在使用吧? Yahoo!已经在长期大规模使用: 国内也有 ...
- 【互动问答分享】第10期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第10期互动问答分享] Q1:Spark on Yarn的运行方式是什么? Spark on Yarn的运行方式有两种:Client ...
- 【互动问答分享】第7期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第7期互动问答分享] Q1:Spark中的RDD到底是什么? RDD是Spark的核心抽象,可以把RDD看做“分布式函数编程语言”. ...
- 【互动问答分享】第6期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第6期互动问答分享] Q1:spark streaming 可以不同数据流 join吗? Spark Streaming不同的数据流 ...
- 【大数据】Hive学习笔记
第1章 Hive基本概念 1.1 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表, ...
- 大数据-spark-hbase-hive等学习视频资料
不错的大数据spark学习资料,连接过期在评论区评论,再给你分享 https://pan.baidu.com/s/1ts6RNuFpsnc39tL3jetTkg
- 想转行大数据,开始学习 Hadoop?
学习大数据首先要了解大数据的学习路线,首先搞清楚先学什么,再学什么,大的学习框架知道了,剩下的就是一步一个脚印踏踏实实从最基础的开始学起. 这里给大家普及一下学习路线:hadoop生态圈——Strom ...
随机推荐
- POJ3252Round Numbers(数位dp)
题意 给出区间$[A, B]$,求出区间内的数转成二进制后$0$比$1$多的数的个数 $1 \leqslant A, B \leqslant 2,000,000,000$ Sol 比较zz的数位dp ...
- 3285 转圈游戏 2013年NOIP全国联赛提高组
3285 转圈游戏 2013年NOIP全国联赛提高组 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题目描述 Description n 个小伙伴 ...
- ionic 2 起航(一)
最近的工作项目开始接触Ionic2.学习了一段时间,现在跟大家分享一下. 什么是Ionic 2? 百度一下,ionic是一个用来开发混合手机应用的,开源的,免费的代码库.可以优化html.cs ...
- MySQL memory引擎 table is full 问题处理
解决mysql的内存表“table is full”错误 101209 13:13:32 [ERROR] /usr/local/mysql/bin/mysqld: The table ‘test_ ...
- Docker搭建
环境基于CentOS64位,内核最好3.10. 1.下载安装 docker dockersudo yum install docker-io (假如内核版本太低的话,会在下载安装Docker ...
- informix服务端卸载后重新安装不成功
可能原因: 1.实例未删除 2.配置文件未删除 安装成功后远程客户端连接不上问题: 1..如果自己设置的数据库实例报错,换一个数据库实例(database)试试,例如sysadmin
- selenium+python之自动换测试用例执行
1.一个用例为一个完整的场景,从用户登陆系统到最终退出并关闭浏览器. 2.一个用例只验证一个功能点,不要试图在用户登陆系统后把所有的功能都验证一遍. 3.尽可能少的编写逆向逻辑用例.一方面因为逆向逻辑 ...
- Distributed Transaction Coordinator(DTC)一些问题的解决方法
有时运行某个程序或者安装SQL Server时报错. 错误信息: 事务管理器不可用.(从 HRESULT 异常: 0x8004D01B) 启动服务Distributed Transaction Coo ...
- 11g 新特性 Member Kill Escalation 简介
首先我们介绍一下历史.在oracle 9i/10g 中,如果一个数据库实例需要驱逐(evict, alert 文件中会出现ora-29740错误)另一个实例时,需要通过LMON进程在控制文件(以下简称 ...
- FZOJβ #31.字符串
http://1572m36l09.iask.in:30808/problem/31 首先转化为保留尽量少的段使得字典序最大.考虑逐字符确定,显然我们可以将相同的连续字符缩在一起.注意到字典序最大的字 ...