Scrapyd部署
从github(https://github.com/scrapy/scrapyd)下载安装包
放到D:\python\Lib\site-packages\
解压压缩包:cd 到解压目录
python setup.py install
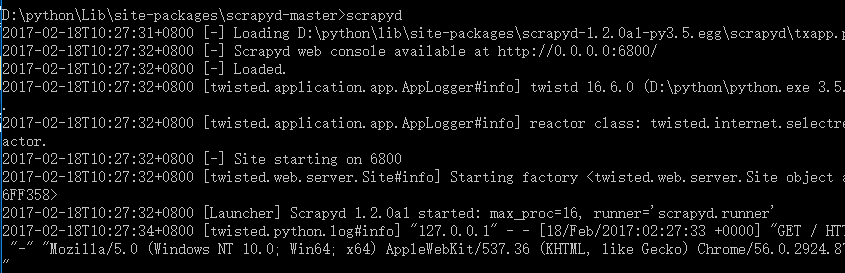
执行命令:Scrapyd;如下证明安装成功
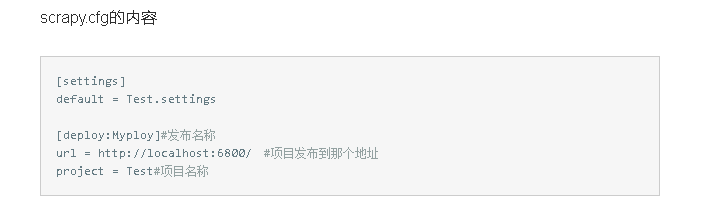
在项目中找到scrapy.cfg文件,编辑如下:
在scrapy.cfg所在目录中执行命令:
scrapyd-deploy Myploy -p Test #在scrapy.cfg文件有配置
报错:'scrapyd-deploy' 不是内部或外部命令,也不是可运行的程序 或批处理文件。在windows上使用scrapyd-client
安装后,并不能使用相应的命令'scrapyd-deploy'
需要在"C:\Python27\Scripts" 目录下 增加scrapyd-deploy.bat文件
内容填充为:
@echo off
"C:\python27\python.exe" "C:\python27\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
在scrapy.cfg所在目录中重新执行命令:
scrapyd-deploy Myploy -p Test #在scrapy.cfg文件有配置

现在只是将项目发布到目标地址,但是没有调度爬虫,调度爬虫需要用到curl命令,如下:
spd是自定义的:

curl http://localhost:6800/schedule.json -d project=testscrapy -d spider=spd
如果window下没有安装crul工具包,会报错:curl不是内部或外部命令,也不是可运行的程序 或批处理文件。
下载:http://curl.haxx.se/download.html;找到系统对应的版本;下载到本地并解压,找到curl.exe 所在路径配置到系统环境变量中;
再次输入:curl http://localhost:6800/schedule.json -d project=testscrapy -d spider=spd

参考:
http://www.jianshu.com/p/694a56b2199a
http://blog.wiseturtles.com/posts/scrapyd.html
http://blog.csdn.net/xxwang6276/article/details/45745181
Scrapyd部署的更多相关文章
- Scrapyd部署爬虫
Scrapyd部署爬虫 准备工作 安装scrapyd: pip install scrapyd 安装scrapyd-client : pip install scrapyd-client 安装curl ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 五十一 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:https://github.com/scrapy/scrapyd 建议安装 pip3 install s ...
- 爬虫部署 --- scrapyd部署爬虫 + Gerapy 管理界面 scrapyd+gerapy部署流程
---------scrapyd部署爬虫---------------1.编写爬虫2.部署环境pip install scrapyd pip install scrapyd-client 启动scra ...
- scrapyd部署、使用Gerapy 分布式爬虫管理框架
Scrapyd部署爬虫项目 GitHub:https://github.com/scrapy/scrapyd API 文档:http://scrapyd.readthedocs.io/en/stabl ...
- 潭州课堂25班:Ph201805201 爬虫高级 第九课 scrapyd 部署 (课堂笔记)
c rapyd是 scrapy 的部署, 是官方提供的一个爬虫管理工具, 通过他可以非常方便的上传控制爬虫的运行, 安装 : pip install scapyd 他提供了一个json ,web, s ...
- scrapy 项目通过scrapyd部署
年前的时候采用scrapy 爬取了某网站的数据,当时只是通过crawl 来运行了爬虫,现在还想通过持续的爬取数据所以需要把爬虫部署起来,查了下文档可以采用scrapyd来部署scrapy项目,scra ...
- 1.scrapyd部署相关问题
部署scrapy爬虫项目到6800上 启动scrapyd 出现问题 1: scrapyd-deloy -l 未找到相关命令 scrapyd-deploy -l 可以看到当前部署的爬虫项目,但是当我输 ...
- 使用Scrapyd部署Scrapy爬虫到远程服务器上
1.准备好爬虫程序 2.修改项目配置 找到项目配置文件scrapy.cnf,将里面注释掉的url解开来 本代码需要连接数据库,因此需要修改对应的数据库配置 其实就是将里面的数据库地址进行修改,变成远程 ...
随机推荐
- 手动创建DataTable并绑定gridview
原文发布时间为:2008-08-04 -- 来源于本人的百度文章 [由搬家工具导入] using System;using System.Data;using System.Configuration ...
- ADO:用代码调用存储过程
原文发布时间为:2008-08-02 -- 来源于本人的百度文章 [由搬家工具导入] using System;using System.Data;using System.Configuration ...
- Error querying database找不到数据库的错误可能发生的原因..
这个问题纠结了大概两个小时.原因是这样的,我刚刚换了一台新的电脑,准备把以前电脑上自己搭建的小项目放到新电脑上面,用myeclipse引入项目之后,启动项目在浏览器跑起来.然后输入账号密码登录主页,报 ...
- Django REST framework 的TokenAuth认证及外键Serializer基本实现
一,Models.py中,ForeignKey记得要有related_name属性,已实现关联对象反向引用. app_name = models.ForeignKey("cmdb.App&q ...
- AC日记——Propagating tree Codeforces 383c
C. Propagating tree time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- 微信小程序 赋值问题
通常我们在页面跳转传递过来的参数要用到页面渲染时或是请求接口回来的数据要用到页面渲染时 对page的data赋值可不能用简单的变量赋值,要用微信小微信专有的this.setData方法 Page({ ...
- 反向代理服务器(Reverse Proxy)
反向代理服务器(Reverse Proxy) 普通代理服务器是帮助内部网络的计算机访问外部网络.通常,代理服务器同时连接内网和外网.首先内网的计算机需要设置代理服务器地址和端口,然后将HTTP请求 ...
- Codeforces 471 D MUH and Cube Walls
题目大意 Description 给你一个字符集合,你从其中找出一些字符串出来. 希望你找出来的这些字符串的最长公共前缀*字符串的总个数最大化. Input 第一行给出数字N.N在[2,1000000 ...
- 358. Rearrange String k Distance Apart
/* * 358. Rearrange String k Distance Apart * 2016-7-14 by Mingyang */ public String rearrangeString ...
- Spring 让 LOB 数据操作变得简单易行,LOB 代表大对象数据,包括 BLOB 和 CLOB 两种类型
转自:https://www.ibm.com/developerworks/cn/java/j-lo-spring-lob/index.html 概述 LOB 代表大对象数据,包括 BLOB 和 CL ...