机器学习: R-CNN, Fast R-CNN and Faster R-CNN
做语义分割的大概都知道这几篇文章了,将一个传统的计算机视觉模型,用CNN一点一点的替换,直到最后构建了一个完整的基于CNN的端到端的模型。这几篇文章有一定的连贯性。从中可以看到一种研究的趋势走向。
上一篇文章里介绍过,Selective Search for Object Recognition,这篇 paper 发表于 2013 年,是一个传统的基于特征提取加分类识别的模型,这个模型主要分成三个部分:
1) 候选区域的提取,这里主要用到了图像分割以及区域融合,经过这一步,从一张图像里大概提取出 2000 个左右的候选区域。
2) 特征提取,从这 2000 个候选区域中,分别提取特征。
3) 分类识别,利用提取的特征,训练 SVM 分类器,对候选区域做分类识别。
看到这三个部分,对于经常接触 CNN 的人来说,首先想到的是怎么用神经网络来代替这三个部分,其实这个替代的过程,也就是这三篇 R-CNN, Fast R-CNN 和 Faster R-CNN 的诞生过程。
1) R-CNN 替代了上面的第二部分, 也就是特征提取部分。
2) Fast R-CNN 在 R-CNN 的基础上,替代了上面的第二,第三部分,特征提取和分类识别都是用神经网络来实现。
3) Faster R-CNN 把第一部分候选区域的提取也替代了,由此就构建了一个完整的端到端的深度神经网络。
这就是 R. B. G 大神的这三篇文章的一个走向。下面介绍一下这三篇文章。
R-CNN
R-CNN 就是用 CNN 替代了传统的特征提取的方法,这也是目前 CNN 比较流行的一种使用方法,为了能让CNN发挥特征提取的作用,这里面要对CNN网络做两次训练,
1) 第一次是先用CNN网络做一个一般的分类识别的学习,比如说ImageNet 的分类,用大量的数据去训练这个网络,让这个网络先具备一定的特征提取的能力;
2) 接下来,需要对训练过的CNN 做一个fine-tuning,就是说用一个特定的数据库,对这个训练过的网络,再训练一次,这样做的目的,是让这个网络能够更有针对性的提取特征。
训练的时候,如何选择正样本,负样本,以及每一个样本 batch 里正负样本的比例,可能需要一些经验。这些论文里面都有介绍。
经过这两次训练之后,这个CNN网络应该就可以用来做特征提取了。其他的步骤,其实和传统的方法基本一致的。
Fast R-CNN
R-CNN 实现的是用 CNN 代替传统的特征提取,R-CNN 有一个问题,就是对每个候选区域都要从头到尾的做一次卷积操作,比如对图像候选区域先做一些 warp,变形到固定的尺寸, 227×227,然后对这个区域用CNN操作一遍,提取特征,再用后面的SVM做分类识别,2000 个候选区域,就要用 CNN 做2000次这样的操作,实在是过于繁琐。而且,可能也会想,能不能用神经网络把后面的分类识别也替代了呢,大神就是大神,所以借鉴了何恺明大神的SPPnets (Spatial pyramid pooling networks)之后, 提出了 Fast R-CNN, 将特征提取和后面的分类检测都用神经网络来做了。
比起 R-CNN, Fast R-CNN 解决了几个非常重要的问题:
如何用CNN只对图像做一次操作,从而把所有的候选区域的特征都能提取出来
如何用神经网络提取出固定维度的特征
如何将分类与回归问题放在一个框架下同时解决
我们先来看第一个问题,我们知道卷积神经网络,不管前面怎么卷,最后都会连到一个全连接网络,就是我们传统的MLP来做分类,所以一般设计网络的时候,我们需要根据输入图像的尺寸,网络的深度,一层一层的设计好,以确保最后的全连接层是一个一维的神经元,这样的设计其实比较麻烦,不太灵活,对图像的输入尺寸定的很死,不能随便改变,何大神就想到了一种 Spatial pyramid pooling 的方式,不管最后一层卷积层的输出是什么,我都给它用 max pooling 的方式,把它们都变成一个一维的神经元,这下好了,不管输入图像是什么尺寸的,我都把最后一个卷积层的输出用这种方式 pooling 成一个固定维度的特征,然后把这个特征往后传递给全连接层继续下去,文章里的示意图非常形象:
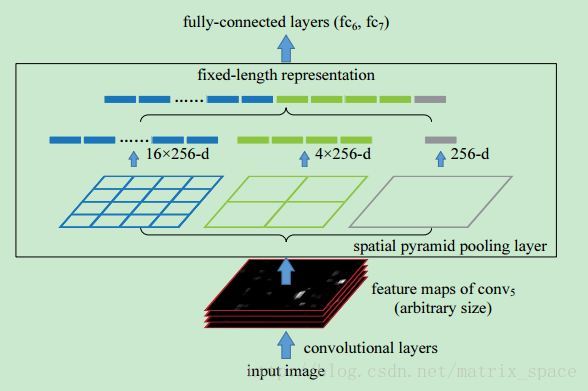
如上图所示,经过最后一层的卷积层,这个网络输出了 256 个 feature map,我们不管这 256 个 feature map 的尺寸,也就是长宽是多少,我们都给它做 pooling, 何大神用了三种 pooling 方式,
第一种是整个 feature map 做 pooling, 那么每个 feature map 就出来一个值,256 个 feature map 就有 256 个值
第二种是每个 feature map 分成 2×2=4 块,每一个 pooling 出一个值,那么每个 feature map 就有 4 个值,一共是 256×4
第二种是每个 feature map 分成 4×4=16 块,每一个 pooling 出一个值,那么每个 feature map 就有 16 个值,一共是 256×16
所有这三种全部连成一个一维的特征向量,接入全连接层,做后面的计算。
Fast R-CNN 就是借鉴了这一个思路,对图像做一次卷积操作,在最后一个卷积层,就会生成很多 feature map,然后利用 pooling 的思想,从 feature map 中提取对应的候选区域的特征,这里只用了一种尺度,文章中说的是 7×7,就是每一个原图的候选区域在 feature map 生的对应区域都分成 7×7 块,然后做 pooling, 相信很多人看到这里,跟我一样都有些懵逼了,原图的候选区域我们都很好理解,因为是分割出来的,但是后面的 feature map 经过层层卷积,尺寸已经改变了,怎么去确定对应的区域呢。这里先暂时不展开讲,后面的博客再详细说明一下。反正就是说经过这种设计,只要对图像做一次卷积操作,就可以把所有候选区域的特征都提取到,并且都 pooling 成固定尺寸,可以放到后面的全连接层继续训练。
介绍完特征提取,我们讲后面的分类识别,Fast R-CNN 设计了一个 MLP 来做后面的分类识别,如paper中的流程图所示:
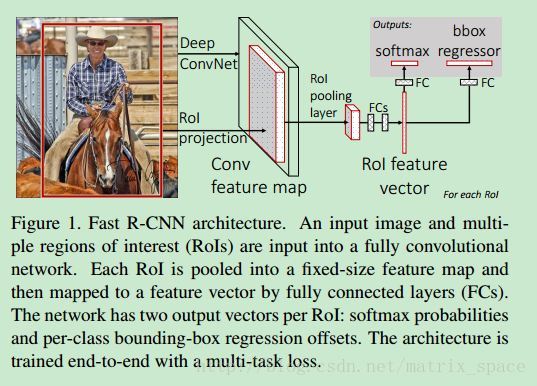
将 pooling 得到的特征,连到两个全连接层上,后面构建了两个输出端,一个是用来做分类的,判断这个候选区域里有没有某一类的目标,另外一个是用来做回归的,判断这个框检测的是否精确,分类器就是用一个 softmax 函数求出某一类的概率来做判断,回归器就是用最小二乘了。构造的 loss function 如下:
Lcls(p,u) 就是用来做分类,Lloc 就是做回归分析,对于 类别 u,我们有这个类别在图像中的位置 v=(vx,vy,vw,vh), 根据预测的概率 p 和预测的位置 tu=(tux,tuy,tuw,tuh) 进行调整,paper 里面也介绍了 Lloc 这个函数,是一个分段函数,论文中说这个函数比起均方误差函数要好,这个大概就是 Fast R-CNN 的基本流程。具体的细节,可以仔细阅读论文。
Faster R-CNN
下面介绍最后一篇文章,Faster R-CNN, 前面两篇文章已经将特征提取和分类识别都用神经网络代替了,就剩下候选区域的提取了,大神为了实现完整的神经网络端到端解决方案,所以又提出了 Faster R-CNN, 与前面两篇文章相比,这篇文章的主要贡献就是提出了一个 Region Proposal Network (RPN),将候选区域的提取也用神经网络实现了。先来看看整体的网络构造:
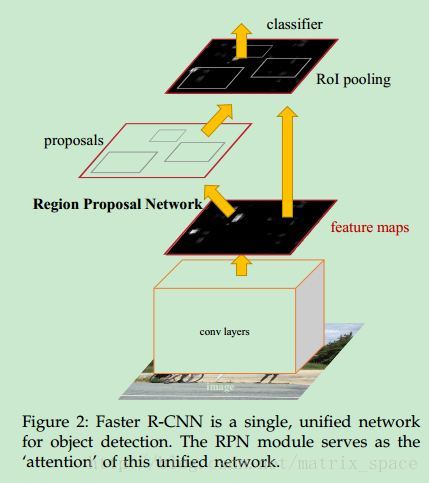
可以看到, RPN 网络其实也是在 feature map 上做提取的,也就是说前面先用卷积网络对输入图像做各种卷积,论文中说的是全卷积网络,也就是不带 pooling 层的卷积网络,所以得到的 feature map 应该比较大,在 feature map 上如何提取特征呢,大神设计了几种不同尺寸的矩形窗,每一个窗的中心称为一个 anchor,在 feature map 上进行滑动,在每一个选定点上,提取三种尺寸,三种比例的窗,所以生成了 9 个 anchor,论文中也提到对于一个 W×H 的 feature map,会有 9WH 个 anchor,说明在 feature map 上的滑动是逐点平移的,没有跳点。
论文中也提到了如何训练 RPN,利用了和 Fast R-CNN 类似的一个 loss function,
这个函数和前面的 Fast R-CNN 目标函数类似,训练的细节也可以在论文中找到。
接下来,我们看看如何将候选区域的提取和后面的特征提取,以及分类识别整合到一个网络里,从上面的流程图可以看到, RPN 和 后面的 Fast R-CNN 是有一些公用卷积层的,前面的卷积层都一面,只是后面要进入不同的分支。大神给出了三种方案:
交叉训练: 先训练 RPN, 然后利用训练好的 RPN 提取候选区域,训练 Fast R-CNN, 这个训练过程会对前面的公用卷积层做 fine tuned, 这个 fine tuned 过的公用卷积层,可以作为下一次训练 RPN 的初始值,训练 RPN, 如此反复交叉迭代,论文中好像采用的就是这个方案。
Approximate joint training, 这个方案,将 RPN 和 Fast R-CNN 整合到一起,前向传递的时候, RPN 固定不动,用来做单纯的候选区域提取,反向传递的时候,Fast R-CNN 部分还是和以前一样,不过公用卷积层的部分,需要把 RPN 的 loss function 也考虑进去。
Non-approximate joint training, 这个方案,会将 RPN 的输出的候选框的预测值作为 Fast R-CNN 的输入,为了实现这一目的,论文中引入了一个 ROI pooling 层,大神只是大概介绍了一下,由于论文采取的其实是方案一,所以没有提供太多细节。
下面,介绍一下方案一的具体训练细节:
第一步: 训练 RPN, 当然了,训练 RPN 之前,这个网络先得用 ImageNet 数据集跑一遍,标准流程,呵呵。然后再用现在要用的数据库的训练集做 fine tune。
第二步: 训练 Fast R-CNN,这个网络也得先用 ImageNet 数据集先跑一遍,然后再把 RPN 当做一个候选区域的提取网络,直接提取出候选区域,去训练 Fast R-CNN,注意,到这一步的时候,RPN 和 Fast R-CNN 还是没有任何公用卷积网络的。
第三步: 我们用训练过的 Fast R-CNN 的卷积层部分来初始化 RPN,但是,这些卷积层训练的时候不调整参数,只有对 RPN 单独拥有的那几层网络调整参数。现在,RPN 和 Fast R-CNN 就有了公用的卷积层。
第四步: 依然固定公用的卷积层,对 Fast R-CNN 单独拥有的几层网络做训练,调整参数。
这样整个四步走完,是一个回合,论文中也提到,可以多训练几个回合,不过好像然并卵。
从这四步,我们可以看到,
1) 用一个大的数据集对网络进行“预热”是非常重要的,这样比起随意的初始化要好的多,可能见得多了,网络的学习能力也能增强。
2) 公用卷积网络其实是在前面两步就训练好了的,后面两步只是对 RPN 和 Fast R-CNN 单独拥有的几层网络做个微调。
3) RPN 用来负责标识候选区域,Fast R-CNN 用来对标识出来的候选区域做分类识别。结合这两个网络的输出结果,就可以对图像做最后的语义分割了。
参考:
R-CNN 《Rich feature hierarchies for Accurate Object Detection and Segmentation》
SSPnets 《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
Fast R-CNN
Faster R-CNN
晓雷机器学习笔记 https://zhuanlan.zhihu.com/xiaoleimlnote
机器学习: R-CNN, Fast R-CNN and Faster R-CNN的更多相关文章
- CNN基础一:从头开始训练CNN进行图像分类(猫狗大战为例)
本文旨在总结一次从头开始训练CNN进行图像分类的完整过程(猫狗大战为例,使用Keras框架),免得经常遗忘.流程包括: 从Kaggle下载猫狗数据集: 利用python的os.shutil库,制作训练 ...
- R语言︱H2o深度学习的一些R语言实践——H2o包
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- R语言H2o包的几个应用案例 笔者寄语:受启发 ...
- R语言编程艺术(5)R语言编程进阶
本文对应<R语言编程艺术> 第14章:性能提升:速度和内存: 第15章:R与其他语言的接口: 第16章:R语言并行计算 ================================== ...
- 社交网络分析的 R 基础:(一)初探 R 语言
写在前面 3 年的硕士生涯一转眼就过去了,和社交网络也打了很长时间交道.最近突然想给自己挖个坑,想给这 3 年写个总结,画上一个句号.回想当时学习 R 语言时也是非常戏剧性的,开始科研生活时到处发邮件 ...
- TensorFlow.NET机器学习入门【7】采用卷积神经网络(CNN)处理Fashion-MNIST
本文将介绍如何采用卷积神经网络(CNN)来处理Fashion-MNIST数据集. 程序流程如下: 1.准备样本数据 2.构建卷积神经网络模型 3.网络学习(训练) 4.消费.测试 除了网络模型的构建, ...
- 机器学习实用案例解析(1) 使用R语言
简介 统计学一直在研究如何从数据中得到可解释的东西,而机器学习则关注如何将数据变成一些实用的东西.对两者做出如下对比更有助于理解“机器学习”这个术语:机器学习研究的内容是教给计算机一些知识,再让计算机 ...
- 10 种机器学习算法的要点(附 Python 和 R 代码)
本文由 伯乐在线 - Agatha 翻译,唐尤华 校稿.未经许可,禁止转载!英文出处:SUNIL RAY.欢迎加入翻译组. 前言 谷歌董事长施密特曾说过:虽然谷歌的无人驾驶汽车和机器人受到了许多媒体关 ...
- 机器学习中的EM算法具体解释及R语言实例(1)
最大期望算法(EM) K均值算法很easy(可參见之前公布的博文),相信读者都能够轻松地理解它. 但以下将要介绍的EM算法就要困难很多了.它与极大似然预计密切相关. 1 算法原理 最好还是从一个样例開 ...
- 机器学习-K-means聚类及算法实现(基于R语言)
K-means聚类 将n个观测点,按一定标准(数据点的相似度),划归到k个聚类(用户划分.产品类别划分等)中. 重要概念:质心 K-means聚类要求的变量是数值变量,方便计算距离. 算法实现 R语言 ...
随机推荐
- 生成二维码 加密解密类 TABLE转换成实体、TABLE转换成实体集合(可转换成对象和值类型) COOKIE帮助类 数据类型转换 截取字符串 根据IP获取地点 生成随机字符 UNIX时间转换为DATETIME\DATETIME转换为UNIXTIME 是否包含中文 生成秘钥方式之一 计算某一年 某一周 的起始时间和结束时间
生成二维码 /// <summary>/// 生成二维码/// </summary>public static class QRcodeUtils{private static ...
- Python 规范化LinkedIn用户联系人的职位名
CODE: #!/usr/bin/python # -*- coding: utf-8 -*- ''' Created on 2014-8-19 @author: guaguastd @name: j ...
- condarc文件
channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/ - https://mirrors.tuna.tsingh ...
- 深入理解Java 8 Lambda
- 转载:blog1, blog2 以上两篇博客是对lambda表达式的深入理解,用于后续加深理解. 如下先从零开始理解lambda, 1. 接触lambda表达式是从python,javascrip ...
- Redis源码试读(一)源码准备
这里开始查看Redis的源码,之前是在看Unix的环境编程,虽然这本书写的很好,但是只看这个感觉有点隔靴搔痒.你可以知道沙子.水泥.钢筋的特性,但是要想建一栋大楼仍然是另一回事.Unix环境编程要看, ...
- js关闭浏览器事件,js关闭浏览器提示及相关函数
关于浏览器关闭事件的相关描述 有些朋友想在浏览器关闭的时候,弹出alert .confirm或者prompt等.实验证明,这种做法是失败的,原因是浏览器关闭事件自动屏蔽执行js的某些方法,从而防止恶意 ...
- C语言的运算符的优先级与结合性+ASCII表
[0]README 0.1) 内容来源于 C程序设计语言, 旨在整理出C语言的运算符的优先级与结合性, 如下图所示(哥子 记了大半年都没有记住,也是醉了,每次都要去翻): Alert)以下内容转自:h ...
- Node.js面试题
Node.js面试题列表 什么是错误优先的回调函数? 如何避免回调地狱? 如何用Node来监听80端口? 什么是事件循环? 哪些工具可以用来保证一致的编程风格? 什么是测试金字塔?对于HTTP API ...
- C语言实现 操作系统 银行家算法
/**************************************************** 银行家算法 算法思想: 1. 在多个进程中,挑选资源需求最小的进程Pmin. 可能存在多类资 ...
- Android OpenGL 播放视频学习
1, 初步接触Open GL: http://www.cnblogs.com/TerryBlog/archive/2010/07/09/1774475.html 使用GLSurfaceView和Ren ...