word2vec改进之Negative Sampling
训练网络时往往会对全部的神经元参数进行微调,从而让训练结果更加准确。但在这个网络中,训练参数很多,每次微调上百万的数据是很浪费计算资源的。那么Negative Sampling方法可以通过每次调整很小的一部分权重参数,从而代替全部参数微调的庞大计算量。
词典D中的词在语料C中出现的次数有高有低,对于那些高频词,我们希望它被选为负样本的概率比较大,对于那些低频词,我们希望它被选中的概率比较小,这是我们对于负采样过程的一个大致要求,本质上可以认为是一个带权采样的问题。
一、基于Negative Sampling的CBOW模型
输入:基于CBOW的语料训练样本,词向量的维度大小Mcount,CBOW的上下文大小2c,步长η, 负采样的个数neg
输出:词汇表每个词对应的模型参数θ,所有的词向量xw
1. 随机初始化所有的模型参数θ,所有的词向量w
2. 对于每个训练样本(context(w0),w0),负采样出neg个负例中心词wi,i=1,2,...neg
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w0),w0,w1,...wneg)做如下处理:

d) 如果梯度收敛,则结束梯度迭代,否则回到步骤3继续迭代。
二、基于Negative Sampling的Skip-Gram模型
输入:基于Skip-Gram的语料训练样本,词向量的维度大小Mcount,Skip-Gram的上下文大小2c,步长η, , 负采样的个数neg。
输出:词汇表每个词对应的模型参数θ,所有的词向量xw
1. 随机初始化所有的模型参数θ,所有的词向量w
2. 对于每个训练样本(context(w0),w0),负采样出neg个负例中心词wi,i=1,2,...neg
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w0),w0,w1,...wneg)做如下处理:
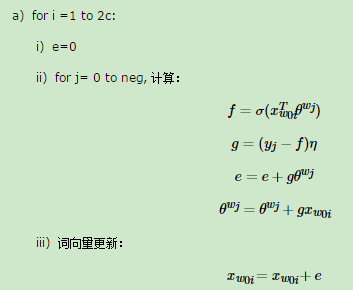
b)如果梯度收敛,则结束梯度迭代,算法结束,否则回到步骤a继续迭代。
参考内容:
https://www.cnblogs.com/pinard/p/7249903.html
word2vec改进之Negative Sampling的更多相关文章
- word2vec原理(三) 基于Negative Sampling的模型
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- word2vec 中的数学原理具体解释(五)基于 Negative Sampling 的模型
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了非常多人的关注. 因为 word2vec 的作者 Tomas ...
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
上篇博文提到,原始的CBOW / Skip-gram模型虽然去掉了NPLM中的隐藏层从而减少了耗时,但由于输出层仍然是softmax(),所以实际上依然“impractical”.所以接下来就介绍一下 ...
- 词表征 2:word2vec、CBoW、Skip-Gram、Negative Sampling、Hierarchical Softmax
原文地址:https://www.jianshu.com/p/5a896955abf0 2)基于迭代的方法直接学 相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词 ...
- Notes on Noise Contrastive Estimation and Negative Sampling
Notes on Noise Contrastive Estimation and Negative Sampling ## 生成负样本 在常见的关系抽取应用中,我们经常需要生成负样本来训练一个好的系 ...
- 论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
论文信息 论文标题:Self-supervised Graph Neural Networks without explicit negative sampling论文作者:Zekarias T. K ...
- [DeeplearningAI笔记]序列模型2.7负采样Negative sampling
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 负采样 Negative sampling Mikolov T, Sutskever I, Chen K, et a ...
- word2vec改进之Hierarchical Softmax
首先Hierarchical Softmax是word2vec的一种改进方式,因为传统的word2vec需要巨大的计算量,所以该方法主要有两个改进点: 1. 对于从输入层到隐藏层的映射,没有采取神经网 ...
- 【计算语言学实验】基于 Skip-Gram with Negative Sampling (SGNS) 的汉语词向量学习和评估
一.概述 训练语料来源:维基媒体 https://dumps.wikimedia.org/backup-index.html 汉语数据 用word2vec训练词向量,并用所学得的词向量,计算 pku_ ...
随机推荐
- Android 属性动画ObjectAnimator和ValueAnimator讲解
区别: ObjectAnimator 是直接对某个view进行更改. ValueAnimator 根据 TimeInterpolator 在不断产生相应的数据,来传进view ,view自己做改变. ...
- 操作系统:Bochs 2.6.8的配置文件bochsrc.bxrc修改
由于现在Bochs 2.6.8相比之前有些改动,之前的配置文件不能直接运行,针对配置文件需要有些修改. 1. 配置文件 ######################################## ...
- CodeForces - 450B Jzzhu and Sequences —— 斐波那契数、矩阵快速幂
题目链接:https://vjudge.net/problem/CodeForces-450B B. Jzzhu and Sequences time limit per test 1 second ...
- Technocup 2017 - Elimination Round 2 C. Road to Cinema —— 二分
题目链接:http://codeforces.com/problemset/problem/729/C C. Road to Cinema time limit per test 1 second m ...
- 狂配Nginx
一 .Nginx虚拟主机配置( 基于不同的域名,跳转到不同的项目) 1.基于域名的虚拟主机,通过域名来区分虚拟主机——应用:外部网站 2.基于端口的虚拟主机,通过端口来区分虚拟主机——应用:公司内部 ...
- ansible-playbook初始化服务器
hosts ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ [test] 0.0.0.0 ansible_ssh_us ...
- Power Strings--KMP
https://cn.vjudge.net/problem/POJ-2406 上面是比赛链接. 题目意思很明确,问最多是多少个子串连接而成的? 这个需要用到KMP,很好的理解KMP的Next数组.Ne ...
- (QACNN)自然语言处理:智能问答 IBM 保险QA QACNN 实现笔记
follow: https://github.com/white127/insuranceQA-cnn-lstm http://www.52nlp.cn/qa%E9%97%AE%E7%AD%94%E7 ...
- python中的linspace,meshgrid,concatenate函数
linspace可以用来实现相同间隔的采样. numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) ...
- bzoj 3527 [Zjoi2014] 力 —— FFT
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=3527 看了看TJ才推出来式子,还是不够熟练啊: TJ:https://blog.csdn.n ...