Hadoop1.0.3环境搭建流程
0x00 大数据平台相关链接
官网:http://hadoop.apache.org/
主要参考教程:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html
0x01 hadoop平台环境
操作系统:CentOS-6.5-x86_64
Java版本:jdk_1.8.0_111
Hadoop版本:hadoop-1.0.3
0x02 安装操作系统(简要)
2.1 准备安装镜像
CentOS-6.5-x86_64-bin-DVD1.iso
2.2 CentOS官方网站与文档
官网主页:http://www.centos.org/
官方WiKi:http://wiki.centos.org/
官方中文文档:http://wiki.centos.org/zh/Documentation
安装说明:http://www.centos.org/docs/
2.3 安装教程
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503770.html
2.4 建立一般用户
//新增用户
# useradd hadoop
//设置密码
# passwd 1234562.5 关闭防火墙机SELinux
关闭防火墙
//临时关闭
# service iptables stop
//永久关闭
# chkconfig iptables off
# service ip6tables stop
# chkconfig ip6tables off
关闭SELinux
# vim /etc/sysconfig/selinux
SELINUX=enforcing
|
SELINUX=disable接着执行如下命令
# setenforce 0
# getenforce0x03 hadoop安装
3.1 环境说明
| hostname | username | IP |
|---|---|---|
| master | hadoop | 192.168.1.10 |
| slave1 | hadoop | 192.168.1.11 |
| slave2 | hadoop | 192.168.1.12 |
3.2 网络配置
修改当前主机名
//查看当前主机名 # hostname //修改当前主机名 vim /etc/sysconfig/network NETWORKING 是否利用网络 GATEWAY 默认网关 IPGATEWAYDEV 默认网关的接口名 HOSTNAME 主机名 DOMAIN 域名修改当前机器IP
# vim /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE 接口名(设备,网卡) BOOTPROTO IP的配置方法(static:固定IP, dhcpHCP, none:手动) HWADDR MAC地址 ONBOOT 系统启动的时候网络接口是否有效(yes/no) TYPE 网络类型(通常是Ethemet) NETMASK 网络掩码 IPADDR IP地址 IPV6INIT IPV6是否有效(yes/no) GATEWAY 默认网关IP地址
配置'hosts'文件(必须)
# vim /etc/hosts 192.168.1.2 master 192.168.1.3 slave1 192.168.1.4 slave2
3.3 SSH无密钥验证配置
- SSH无密钥原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端Master复制到Slave上。 - 配置master和slave互相无密钥登录
所有密钥都是hadoop用户的公钥和私钥,即以hadoop用户的身份来执行生成密钥的命令。
$ ssh-keygen –t rsa –P ''
这条命令是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/home/hadoop/.ssh"目录下。
在所有slave节点执行该命令生成其密钥对。
将所有slave节点的公钥上传到master节点$ scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/slave1_id_rsa.pub $ scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/slave2_id_rsa.pub- 接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将所有slave的公钥追加到authorized_keys。 - 修改authorized_keys的权限
$ chmod 600 ~/.ssh/authorized_keys 将authorized_keys复制到所有的slave节点
$ scp ~/.ssh/authorized_keys hadoop@slave1:~/.ssh/ $ scp ~/.ssh/authorized_keys hadoop@slave2:~/.ssh/验证master和slave可以互相免密钥登录。
//master $ ssh slave1 //slave1 $ ssh master ...
3.4 所需软件
- JDK
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
JDK版本:jdk-8u111-linux-x64.tar.gz - hadoop
下载地址:http://hadoop.apache.org/releases.html
hadoop版本:hadoop1.0.3
3.5 Java环境安装和配置
root身份进行安装,如果系统已经安装了其他版本的java请先卸载旧版,再进行安装。
//解压
# tar -zxvf jdk-8u111-linux-x64.tar.gz
//移动文件夹到/usr下并重命名为java
# mv jdk1.8.0_111 /usr/java最好能利用软链,方便管理多版本应用软件
配置java环境变量【替换成自己的java安装路径和版本】
# vim /etc/profile
//在文件尾部追加
# set java environment
export JAVA_HOME=/usr/java/jdk1.6.0_31
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin使配置立即生效
$ source /etc/profile
验证是否安装成功
$ java -version
安装其它机器,使用linux scp命令将java文件夹和profile文件复制到其它机器即可。
scp -r /usr/java hadoop@slave1:/usr/
3.6 hadoop集群安装
所有的机器上都要安装hadoop,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装和配置hadoop需要以"root"的身份进行。
在/usr目录下新建文件夹cloud
# mkdir /usr/cloud
解压
# tar -zxvf hadoop-1.0.3.tar.gz
//移动到/usr/cloud文件夹下
# mv hadoop-xxx /usr/cloud/hadoop将读权限分配给hadoop用户
# chown -R hadoop:hadoop /usr/cloud/hadoop
配置hadoop环境变量【注意替换】
# vim /etc/profile
//最后追加
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH :$HADOOP_HOME/bin使配置立即生效
# source /etc/profile
创建tmp文件夹
# mkdir /usr/cloud/hadoop/tmp
3.7 hadoop集群配置
hadoop2.5.2配置文件目录变更为/hadoop/etc/hadoop
配置hadoop-env.sh
# vim /usr/cloud/hadoop/conf/hadoop-env.sh //在文件末尾追加 # set java environment export JAVA_HOME=/usr/java配置core-site.xml
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号。<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> (备注:请先在 /usr/hadoop 目录下建立 tmp 文件夹) <description>A base for other temporary directories.</description> </property> <!-- file system properties --> <property> <name>fs.default.name</name> <value>hdfs://192.168.1.2:9000</value> </property> </configuration>备注:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。
配置hdfs-site.xml
修改Hadoop中HDFS的配置,配置的备份方式默认为3。<configuration> <property> <name>dfs.replication</name> <value>1</value> (备注:replication 是数据副本数量,默认为3,salve少于3台就会报错) </property> <configuration>配置mapred-site.xml
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口。<configuration> <property> <name>mapred.job.tracker</name> <value>http://192.168.1.2:9001</value> </property> </configuration>- 配置master文件
修改localhost为master
# vim /usr/cloud/hadoop/conf/masters - 配置slaves文件【master主机独有】
去掉"localhost",每行只添加一个主机名,把剩余的Slave主机名都填上。
# vim /usr/cloud/hadoop/conf/slaves 配置其他机器
将 Master上配置好的hadoop所在文件夹"/usr/cloud/"复制到所有的Slave的"/usr/"目录下(实际上Slave机器上的slavers文件是不必要的, 复制了也没问题)。用下面命令格式进行。(备注:此时用户可以为hadoop也可以为root)# scp -r /usr/cloud hadoop@slave1:/usr/ # scp -r /usr/cloud hadoop@slave2:/usr/在slave上配置java和hadoop的环境变量
3.8 启动及验证
- 格式化HDFS文件系统
在master上使用普通用户hadoop进行操作。(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
# hadoop namenode -format - 启动hadoop
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭。
# ./start-all.sh

可以通过以下启动日志看出,首先启动namenode 接着启动datanode1,datanode2,…,然后启动secondarynamenode。再启动jobtracker,然后启动tasktracker1,tasktracker2,…。
启动 hadoop成功后,在 Master 中的 tmp 文件夹中生成了 dfs 文件夹,在Slave 中的 tmp 文件夹中均生成了 dfs 文件夹和 mapred 文件夹。 - 验证hadoop
在Master上用 java自带的小工具jps查看进程。

在Slave1上用jps查看进程。

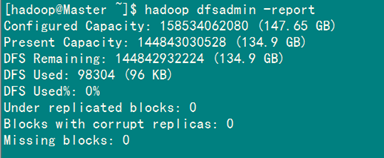
方法2:用"hadoop dfsadmin -report"
用这个命令可以查看Hadoop集群的状态。
网页查看集群
访问"http:192.168.1.2:50030"
访问"http:192.168.1.2:50070"0x04 常见问题
4.1 关于 Warning: $HADOOP_HOME is deprecated.
经查hadoop-1.0.0/bin/hadoop脚本和"hadoop-config.sh"脚本,发现脚本中对HADOOP_HOME的环境变量设置做了判断,笔者的环境根本不需要设置HADOOP_HOME环境变量。
解决方案一:编辑"/etc/profile"文件,去掉HADOOP_HOME的变量设定,重新输入hadoop fs命令,警告消失。
解决方案二:编辑"/etc/profile"文件,添加一个环境变量,之后警告消失:export HADOOP_HOME_WARN_SUPPRESS=1 # source /etc/profile博客中在配置hadoop是master的配置不需要改,否则会出错!!!!
2017年1月20日, 星期五
Hadoop1.0.3环境搭建流程的更多相关文章
- cocos2d-x 3.11 游戏开发环境搭建流程
cocos2d-x 3.11.1 游戏开发环境搭建流程 1. 准备下面的软件 1) Windows7 64Bit+ VS2013 (VC++) 这个不用多说. 2) cocos2d-x-3.11.1. ...
- 联盟链初识以及Fabric环境搭建流程
这篇文章首先简单介绍了联盟链是什么,再详细的介绍了Fabric环境搭建的整个流程. 区块链分类: 以参与方式分类,区块链可以分为:公有链.联盟链和私有链. 定义: 我们知道区块链就是一个分布式的,去中 ...
- android 5.0开发环境搭建
Android 5.0 是 Google 于 2014 年 10 月 15 日发布的全新 Android 操作系统.本文将就最新的Android 5.0 开发环境搭建做详细介绍. 工具/原料 jdk- ...
- Jira 6.0.5环境搭建
敏捷开发-Jira 6.0.5环境搭建[1] 我的环境 Win7 64位,MSSql2008 R2,已经安装tomcat了 拓展环境 jira 6.0.5 百度网盘下载 ...
- selenium win7+selenium2.0+python环境搭建
win7+selenium2.0+python环境搭建 by:授客 QQ:1033553122 步骤1:下载python 担心最新版的支持不太好,这里我下载的是python 2.7(selenium之 ...
- CentOS7 Redis5.0.5环境搭建
CentOS7 Redis5.0.5环境搭建 1基本环境配置 CentOS Linux release 7.6.1810 (Core) redis 5.0.5 1.下载解压redis.通过wget在官 ...
- hadoop1.2开发环境搭建
一:Vmware上安装Linux系统 二:配置Vmware NAT网络.(详细说明:vmware三种网络模式 - 简书). NAT是网络地址转换,是在宿主机和虚拟机之间增加一个地址转换服务,负责外部和 ...
- faster-rcnn(testing): ubuntu14.04+caffe+cuda7.5+cudnn5.1.3+opencv3.0+matlabR2014a环境搭建记录
python版本的faster-rcnn见我的另一篇博客: py-faster-rcnn(running the demo): ubuntu14.04+caffe+cuda7.5+cudnn5.1.3 ...
- Sqoop-1.4.6.bin__hadoop-2.0.4-alpha 环境搭建
一.Sqoop 环境搭建 1.下载安装包及解压 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz 1)拷贝sqoop-1.4.6.bin__hadoop-2 ...
随机推荐
- IOS 股票K线图、分时图
IOS 股票K线图.分时图,网上开源项目很少,质量也是参差不齐:偶尔搜索到看似有希望的文章,点进去,还是个标题党:深受毒害.经过一段时间的探索,终于在开源基础上完成了自己的股票K线图.分时图: 先放出 ...
- Yii实现Password Repeat Validate Rule
在使用Yii时遇到这样的需求:在一个注册的页面输入两次密码,并验证两次输入是否一致.可是password的repeat的字段在数据库 并不存在.问题来了,如何创建一个password_repeat的属 ...
- 安卓Visibility属性
可见(visible) XML文件:android:visibility="visible" Java代码:view.setVisibility(View.VISIBLE); 不可 ...
- [Angular Tutorial] 5-Filtering Repeaters
在上一步中,我们花了很大功夫来布局应用的基础,所以我们现在做点简单点的吧!我们将会添加一个全文本搜索框(没错,这很简单). ·我们的应用现在会有一个搜索框,注意页面中手机列表的改变取决于用户在搜索框键 ...
- [Angular Tutorial] 1-Static Template
为了说明Angular如何扩展了标准的html,您将会创建了一个纯粹的静态html页面,并且看到我们如何将这些html代码转换成Angular能动态展示相同结果的模板. 在这一步您将会在一个html页 ...
- 环信 之 iOS 客户端集成一:导入库
1. 导入 我采用cocoapod的方式,在project同级目录下创建Podfile,Podfile内容如下: platform :ios, '7.0' pod 'EaseMobSDKFull', ...
- 2.2. 添加托管对象模型(Core Data 应用程序实践指南)
右键分组Grocery Dude > New Group > Data Model New File > Core Data > 创建新的模板文件
- js架构设计模式——前端MVVM框架设计及实现(二)
前端MVVM框架设计及实现(二) 在前端MVVM框架设计及实现(一)中有一个博友提出一个看法: “html中使用mvvm徒增开发成本” 我想这位朋友要表达的意思应该是HTML定义了大量的语法标记,HT ...
- HDU-1598-find the most comfortable road(暴力+并查集)多看看,
题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=1598 题目思路:对于这个题目,可以先按速度的大小成小到大排序, 再成0 到 m ,把所有可以联通的道路 ...
- 以脚本方式直接执行修改密码的passwd命令
以脚本方式直接执行修改密码的passwd命令: 参考: http://bbs.csdn.net/topics/390001865 http://bbs.chinaunix.net/thread-993 ...