爬虫实例系列一(requests)
一 爬虫简介
'''
爬虫:通过编写程序,模拟浏览器上网,让其去互联网上爬取数据的过程 分类:
通用爬虫:爬取全部的页面数据
聚焦爬虫:抓取页面中局部数据
增量式爬虫:爬取网站中更新出的数据 反爬机制:门户网站会通过制定相关的技术手段,组织爬虫程序进行数据获取
反反爬策略:针对反爬机制制定的策略,为了获取数据 第一个反爬机制:
robots.txt协议:防君子不防小人的协议
'''
二 request 入门使用流程
'''
request使用流程:
- 制定url
- 发起请求
- 获取响应回来的页面数据
- 持久化存储
'''
三 实例
1 获取搜狗页面(反反爬机制:防君子不防小人)
import requests #获取搜狗页面数据 #1.指定url
url='https://www.sogo.com/' #2.发起请求
response=requests.get(url=url) #3.获取页面数据
response_text=response.text #4.持久化存储
with open('sogo.html',mode='w',encoding='utf8') as f:
f.write(response_text)
2 获取知乎页面数据(UA伪装)
'''
User-Agent:请求载体的身份标识
反爬机制:UA检测
反反爬策略:UA伪装
'''
#请求知乎 url='https://www.zhihu.com/' #指定请求头,进行UA伪装
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36'
}
response=requests.get(url=url,headers=headers) print(response.text)
3 post请求实例(请求百度翻译结果)

#请求百度翻译结果 #经过分析发现,百度翻译发送的请求是ajax请求
import requests url='https://fanyi.baidu.com/sug' #指定请求头,进行UA伪装
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36'
} #搜索数据不要写死 kw=input('input a word:')
#构建请求数据
data={
'kw':kw
} response=requests.post(url=url,headers=headers,data=data) print(response.json())
4 post 请求携带更多参数data={}
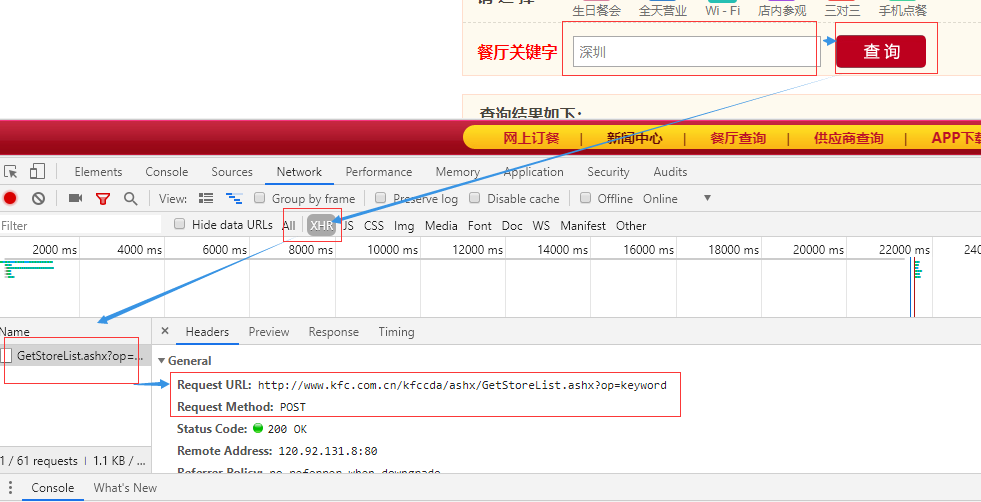

#爬取城市肯德基餐厅的位置信息 http://www.kfc.com.cn/kfccda/storelist/index.aspx '''
抓包获取的数据
Request URL: http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword
Request Method: POST
Status Code: 200 OK
Remote Address: 120.92.131.8:80
Referrer Policy: no-referrer-when-downgrade
''' import requests url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36'
} data={
'cname':'',
'pid':'',
'keyword': '深圳',
'pageIndex': 3,
'pageSize': 10,
} response=requests.post(url=url,headers=headers,data=data) print(response.json())
5 爬取豆瓣电影中的详细数据(ajax请求)
import requests
#爬取豆瓣电影中的详细数据(ajax请求)
#'https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=20&limit=20'
url='https://movie.douban.com/j/chart/top_list'
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36'
}
#此处参数已经写死,后续项目中在此基础修改
params={
'type': '',
'interval_id': '100:90',
'action':'',
'start':'',
'limit':'',
}
response=requests.get(url=url,headers=headers,params=params)
print(response.json())
爬虫实例系列一(requests)的更多相关文章
- 爬虫实例之使用requests和Beautifusoup爬取糗百热门用户信息
这次主要用requests库和Beautifusoup库来实现对糗百的热门帖子的用户信息的收集,由于糗百的反爬虫不是很严格,也不需要先登录才能获取数据,所以较简单. 思路,先请求首页的热门帖子获得用户 ...
- 爬虫入门系列(二):优雅的HTTP库requests
在系列文章的第一篇中介绍了 HTTP 协议,Python 提供了很多模块来基于 HTTP 协议的网络编程,urllib.urllib2.urllib3.httplib.httplib2,都是和 HTT ...
- 爬虫入门系列(三):用 requests 构建知乎 API
爬虫入门系列目录: 爬虫入门系列(一):快速理解HTTP协议 爬虫入门系列(二):优雅的HTTP库requests 爬虫入门系列(三):用 requests 构建知乎 API 在爬虫系列文章 优雅的H ...
- 爬虫系列(七) requests的基本使用
一.requests 简介 requests 是一个功能强大.简单易用的 HTTP 请求库,可以使用 pip install requests 命令进行安装 下面我们将会介绍 requests 中常用 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- [python爬虫]Requests-BeautifulSoup-Re库方案--Requests库介绍
[根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写 文章中部分图片来自老师PPT 慕课链接:https://www.icourse163.org/learn/BIT-10018 ...
随机推荐
- AspNetCore 基于流下载文件与示例代码
昨天说了,AspNetCore如何进行上传文件,其中写了两种方式ajax与模型,其文章地址为:https://www.cnblogs.com/ZaraNet/p/9949167.html 那么既然有上 ...
- .net core使用RPC方式进行高效的HTTP服务访问
传统的HTTP接口调用是一件比较繁琐的事情,特别是在Post数据的时候:不仅要拼访问的URL还是把数据序列化成流的方式给Request进行提交,获取Respons后还要对流进行解码.在实际应用虽然可以 ...
- 前端笔记之JavaScript(十一)event&BOM&鼠标/盒子位置&拖拽/滚轮
一.事件对象event 1.1 preventdefault()和returnValue阻止默认事件 通知浏览器不要执行与事件关联的默认动作. preventdefault() 支持Chrome等高 ...
- C#2.0 迭代器
迭代器 迭代器模式是和为模式的一种范例,我们访问数据序列中所有的元素,不用关心序列是什么类型.从数据管道中数据经过一系列不同的转换或过滤后从管道的另一端出来. 像数组.集合等已经内置了迭代器,我们可以 ...
- C语言实现邻接矩阵创建无向图&图的深度优先遍历
/* '邻接矩阵' 实现无向图的创建.深度优先遍历*/ #include <stdio.h> #include <stdlib.h> #define MaxVex 100 // ...
- Linux下的C#连接Mysql数据库
今天在尝试在 Linux 系统下使用C#连接数据库,发现网上这方面的信息很少,所以就写一篇博客记录一下. Linux下这里使用的是mono. 首先是缺少Mysql.Data.dll这个库的,所以需要安 ...
- Java——final关键字
前言 Java中的关键字final的含义通常为"这是无法改变的".下面将介绍final用于修饰数据.方法和类的这三种情况. final数据 许多编程语言都有某种方法,来向告诉编译器 ...
- win10 git bash 闪退
使用ghost重装了win10 专业版后.安装git,尝试重装了n个版本的git,右键git bash here 直接闪退,直接进入安装目录打开git-bash.exe依旧闪退, git右键点击Git ...
- 反射:修改请求头HttpWebRequest/Webclient Header属性的date值-"此标头必须使用适当的属性进行修改"
场景:调用外部接口,接口要求Header信息里面包涵Date信息,且Date信息必须是格式化好的,(他们用的是Java),但是C#默认的是Date属性不能被修改, 所以就会出现下面的错误: 未处理的异 ...
- vue的项目结构记录
vue的项目结构 不知道大家有没这样的情况,面对刚配置好的脚手架,创建的文件不知道该放哪个文件下,导致后面开发一些文件不好找,不利于维护. 接下来我说说我项目中的一些文件: 首先是components ...