[转]SQL中 OVER(PARTITION BY) 取上一条,下一条等
OVER(PARTITION BY)函数介绍
Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化,举例如下:
1:over后的写法:
over(order by salary) 按照salary排序进行累计,order by是个默认的开窗函数
over(partition by deptno)按照部门分区
2:开窗的窗口范围:
over(order by salary range between 5 preceding and 5 following):窗口范围为当前行数据幅度减5加5后的范围内的。
举例:
--sum(s)over(order by s range between 2 preceding and 2 following) 表示加2或2的范围内的求和
select name,class,s, sum(s)over(order by s range between 2 preceding and 2 following) mm from t2
adf 3 45 45 --45加2减2即43到47,但是s在这个范围内只有45
asdf 3 55 55
cfe 2 74 74
3dd 3 78 158 --78在76到80范围内有78,80,求和得158
fda 1 80 158
gds 2 92 92
ffd 1 95 190
dss 1 95 190
ddd 3 99 198
gf 3 99 198
举例:
select name,class,s, sum(s)over(order by s rows between 2 preceding and 2 following) mm from t2
adf 3 45 174 (45+55+74=174)
asdf 3 55 252 (45+55+74+78=252)
cfe 2 74 332 (74+55+45+78+80=332)
3dd 3 78 379 (78+74+55+80+92=379)
fda 1 80 419
gds 2 92 440
ffd 1 95 461
dss 1 95 480
ddd 3 99 388
gf 3 99 293
3、与over函数结合的几个函数介绍
下面以班级成绩表t2来说明其应用
t2表信息如下:
cfe 2 74
dss 1 95
ffd 1 95
fda 1 80
gds 2 92
gf 3 99
ddd 3 99
adf 3 45
asdf 3 55
3dd 3 78
select * from
(
select name,class,s,rank()over(partition by class order by s desc) mm from t2
)
where mm=1;
得到的结果是:
dss 1 95 1
ffd 1 95 1
gds 2 92 1
gf 3 99 1
ddd 3 99 1
注意:
1.在求第一名成绩的时候,不能用row_number(),因为如果同班有两个并列第一,row_number()只返回一个结果;
select * from
(
select name,class,s,row_number()over(partition by class order by s desc) mm from t2
)
where mm=1;
1 95 1 --95有两名但是只显示一个
2 92 1
3 99 1 --99有两名但也只显示一个
2.rank()和dense_rank()可以将所有的都查找出来:
如上可以看到采用rank可以将并列第一名的都查找出来;
rank()和dense_rank()区别:
--rank()是跳跃排序,有两个第二名时接下来就是第四名;
select name,class,s,rank()over(partition by class order by s desc) mm from t2
dss 1 95 1
ffd 1 95 1
fda 1 80 3 --直接就跳到了第三
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 3
asdf 3 55 4
adf 3 45 5
--dense_rank()l是连续排序,有两个第二名时仍然跟着第三名
select name,class,s,dense_rank()over(partition by class order by s desc) mm from t2
dss 1 95 1
ffd 1 95 1
fda 1 80 2 --连续排序(仍为2)
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 2
asdf 3 55 3
adf 3 45 4
--sum()over()的使用
select name,class,s, sum(s)over(partition by class order by s desc) mm from t2 --根据班级进行分数求和
dss 1 95 190 --由于两个95都是第一名,所以累加时是两个第一名的相加
ffd 1 95 190
fda 1 80 270 --第一名加上第二名的
gds 2 92 92
cfe 2 74 166
gf 3 99 198
ddd 3 99 198
3dd 3 78 276
asdf 3 55 331
adf 3 45 376
first_value() over()和last_value() over()的使用
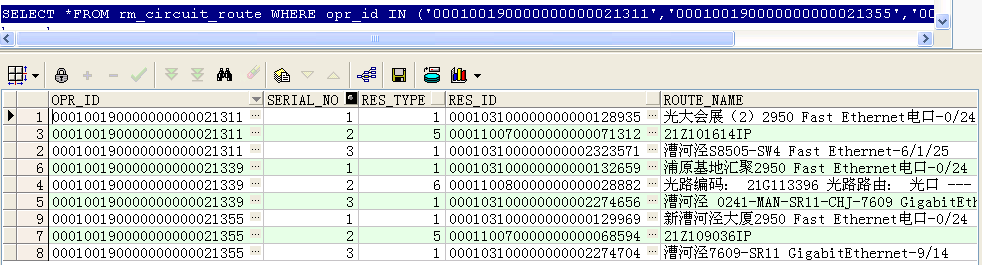
--找出这三条电路每条电路的第一条记录类型和最后一条记录类型
first_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) low,
last_value(res_type) over(PARTITION BY opr_id ORDER BY res_type rows BETWEEN unbounded preceding AND unbounded following) high
FROM rm_circuit_route
WHERE opr_id IN ('000100190000000000021311','000100190000000000021355','000100190000000000021339')
ORDER BY opr_id;
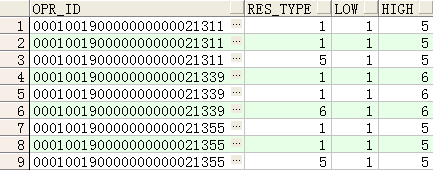
注:rows BETWEEN unbounded preceding AND unbounded following 的使用
--取last_value时不使用rows BETWEEN unbounded preceding AND unbounded following的结果
first_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) low,
last_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) high
FROM rm_circuit_route
WHERE opr_id IN ('000100190000000000021311','000100190000000000021355','000100190000000000021339')
ORDER BY opr_id;
如下图可以看到,如果不使用

数据如下:

取出该电路的第一条记录,加上ignore nulls后,如果第一条是判断的那个字段是空的,则默认取下一条,结果如下所示:

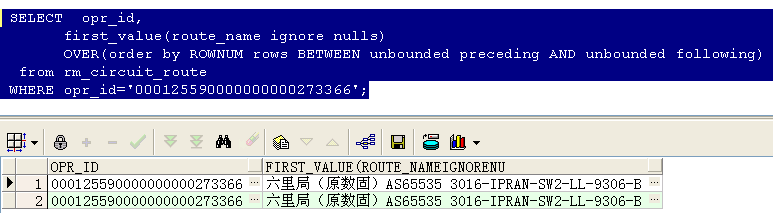
lag(expresstion,,)
with a as
(select 1 id,'a' name from dual
union
select 2 id,'b' name from dual
union
select 3 id,'c' name from dual
union
select 4 id,'d' name from dual
union
select 5 id,'e' name from dual
)
select id,name,lag(id,1,'')over(order by name) from a;
--lead() over()函数用法(取出后N行数据)
lead(expresstion,,)
with a as
(select 1 id,'a' name from dual
union
select 2 id,'b' name from dual
union
select 3 id,'c' name from dual
union
select 4 id,'d' name from dual
union
select 5 id,'e' name from dual
)
select id,name,lead(id,1,'')over(order by name) from a;
--ratio_to_report(a)函数用法 Ratio_to_report() 括号中就是分子,over() 括号中就是分母
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over(partition by a) b from a
order by a;
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over() b from a --分母缺省就是整个占比
order by a;
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over() b from a
group by a order by a;--分组后的占比
SELECT a.deptno,
a.ename,
a.sal,
a.r,
b.n,
(a.r-1)/(n-1) pr1,
percent_rank() over(PARTITION BY a.deptno ORDER BY a.sal) pr2
FROM (SELECT deptno,
ename,
sal,
rank() over(PARTITION BY deptno ORDER BY sal) r --计算出在组中的排名序号
FROM emp
ORDER BY deptno, sal) a,
(SELECT deptno, COUNT(1) n FROM emp GROUP BY deptno) b --按部门计算每个部门的所有成员数
WHERE a.deptno = b.deptno;
![]()
如下所示自己计算的pr1与通过percent_rank函数得到的值是一样的:
SELECT a.deptno,
a.ename,
a.sal,
a.r,
b.n,
c.rn,
(a.r + c.rn - 1) / n pr1,
cume_dist() over(PARTITION BY a.deptno ORDER BY a.sal) pr2
FROM (SELECT deptno,
ename,
sal,
rank() over(PARTITION BY deptno ORDER BY sal) r
FROM emp
ORDER BY deptno, sal) a,
(SELECT deptno, COUNT(1) n FROM emp GROUP BY deptno) b,
(SELECT deptno, r, COUNT(1) rn,sal
FROM (SELECT deptno,sal,
rank() over(PARTITION BY deptno ORDER BY sal) r
FROM emp)
GROUP BY deptno, r,sal
ORDER BY deptno) c --c表就是为了得到每个部门员工工资的一样的个数
WHERE a.deptno = b.deptno
AND a.deptno = c.deptno(+)
AND a.sal = c.sal;

如下,输入百分比为0.7,因为0.7介于0.6和0.8之间,因此返回的结果就是0.6对应的sal的1500加上0.8对应的sal的1600平均
SELECT ename,
sal,
deptno,
percentile_cont(0.7) within GROUP(ORDER BY sal) over(PARTITION BY deptno) "Percentile_Cont",
percent_rank() over(PARTITION BY deptno ORDER BY sal) "Percent_Rank"
FROM emp
WHERE deptno IN (30, 60);

SELECT ename,
sal,
deptno,
percentile_cont(0.6) within GROUP(ORDER BY sal) over(PARTITION BY deptno) "Percentile_Cont",
percent_rank() over(PARTITION BY deptno ORDER BY sal) "Percent_Rank"
FROM emp
WHERE deptno IN (30, 60);

注意:本函数与PERCENTILE_CONT的区别在找不到对应的分布值时返回的替代值的计算方法不同
SAMPLE:下例中0.7的分布值在部门30中没有对应的Cume_Dist值,所以就取下一个分布值0.83333333所对应的SALARY来替代
SELECT ename,
sal,
deptno,
percentile_disc(0.7) within GROUP(ORDER BY sal) over(PARTITION BY deptno) "Percentile_Disc",
cume_dist() over(PARTITION BY deptno ORDER BY sal) "Cume_Dist"
FROM emp
WHERE deptno IN (30, 60);
[转]SQL中 OVER(PARTITION BY) 取上一条,下一条等的更多相关文章
- SQL中 OVER(PARTITION BY)
OVER(PARTITION BY)函数介绍 开窗函数 Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返 ...
- onhashchange事件,只需要修改hash值即可响应onhashchange事件中的函数(适用于上一题下一题和跳转页面等功能)
使用实例: 使用onhashchange事件做一个简单的上一页下一页功能,并且当刷新页面时停留在当前页 html: <!DOCTYPE html><html><body& ...
- Linq-查询上一条下一条
//下一条 int pollid = poll.Where(f => f.PollID < CurrentId).OrderByDescending(o => o.PollID).F ...
- 动态sql中的条件判断取值来源于map 或者 model
- sql中对数值四舍五入取小数点后两位数字
用:cast(value as decimal(10,2)) 来实现.
- Sql Server 里的向上取整、向下取整、四舍五入取整
==================================================== [四舍五入取整截取] select round(54.56,0) ============== ...
- Sql Server 里的向上取整、向下取整、四舍五入取整的实例!
http://blog.csdn.net/dxnn520/article/details/8454132 =============================================== ...
- Thinkphp 3.2中文章详情页的上一篇 下一篇文章功能
额 简单2句话解释下 获取上一篇文章的原理,其实就是以当前文章的id为起点进行进行查询,例如id=5的文章 select * from article where (article_id<5 ...
- php 新闻上一条下一条
public function prevnext($table,$id,$where=[]){ $ids=db($table)->field('id,title')->order('sor ...
随机推荐
- Log4j的入门和使用
Log4j(log for java)是Apache的一个开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台.文件.GUI组件,甚至是套接口服务器.NT的事件记录器.UNIX Sy ...
- linux --- Ansible篇
ansible背景 1.什么是ansible? ansible是新出现的自动化运维工具,基于Python开发,集合了众多运维工具(puppet.cfengine.chef.func.fabric)的优 ...
- RxSwift 介绍
RxSwift 介绍 中文文档 https://beeth0ven.github.io/RxSwift-Chinese-Documentation/ https://medium.com/@DianQ ...
- 一、大体认识jspxcms
声明:jspxcms的license写明,允许将jspxcms用于商业和非商业用途.此处只是作为研究.分享使用心德,并不涉及商用. 使用版本:jspxcms 9.5.0 一.下载源码,并部署到ecl ...
- Android平台targetSdkVersion设置及动态权限
--关于Android动态权限和targetSdkVersion Android系统自6.0开始,提供动态权限机制,对于敏感权限(存储,定位,录音,拍照,录像等),需要在APP运行过程中动态向用户申请 ...
- 多线程之Synchronized锁的基本介绍
基本介绍 synchronized是Java实现同步的一种机制,它属于Java中关键字,是一种jvm级别的锁.synchronized锁的创建和释放是此关键字控制的代码的开始和结束位置,锁是有jvm控 ...
- git温习
git init:将文件变成git仓库 ls -ah:查看隐藏目录 git add 文件1 文件2 ...:将文件添加到缓存区 git commit -m ‘提交说明’:提交到本地仓库一次 并说明 ...
- 另存了一次网页之后其它word打开格式都变了
解决方案: 视图->页面视图 感觉自己很傻...原来另存word为网页后,默认的打开模式就是网页视图了.只需要把视图改回去即可
- Spring框架学习之--搭建spring框架
此文介绍搭建一个最最简单的spring框架的步骤 一.创建一个maven项目 二.在pom.xml文件中添加依赖导入spring框架运行需要的相关jar包 注意:在引入jar包之后会出现org.jun ...
- afn3.0源码解析---AFURLRequestSerialization
AFHTTPRequestSerialization: @方法1 - (NSMutableURLRequest *)requestWithMethod:(NSString *)method URLSt ...