HBase总结 LSM理解
转载的文章,觉得写的比较好
讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来:
- 哈希存储引擎 是哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就是your Mr.Right
- B树存储引擎是B树(关于B树的由来,数据结构以及应用场景可以看之前一篇博文)的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库(Mysql等)。
- LSM树(Log-Structured Merge Tree)存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
通过以上的分析,应该知道LSM树的由来了,LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能
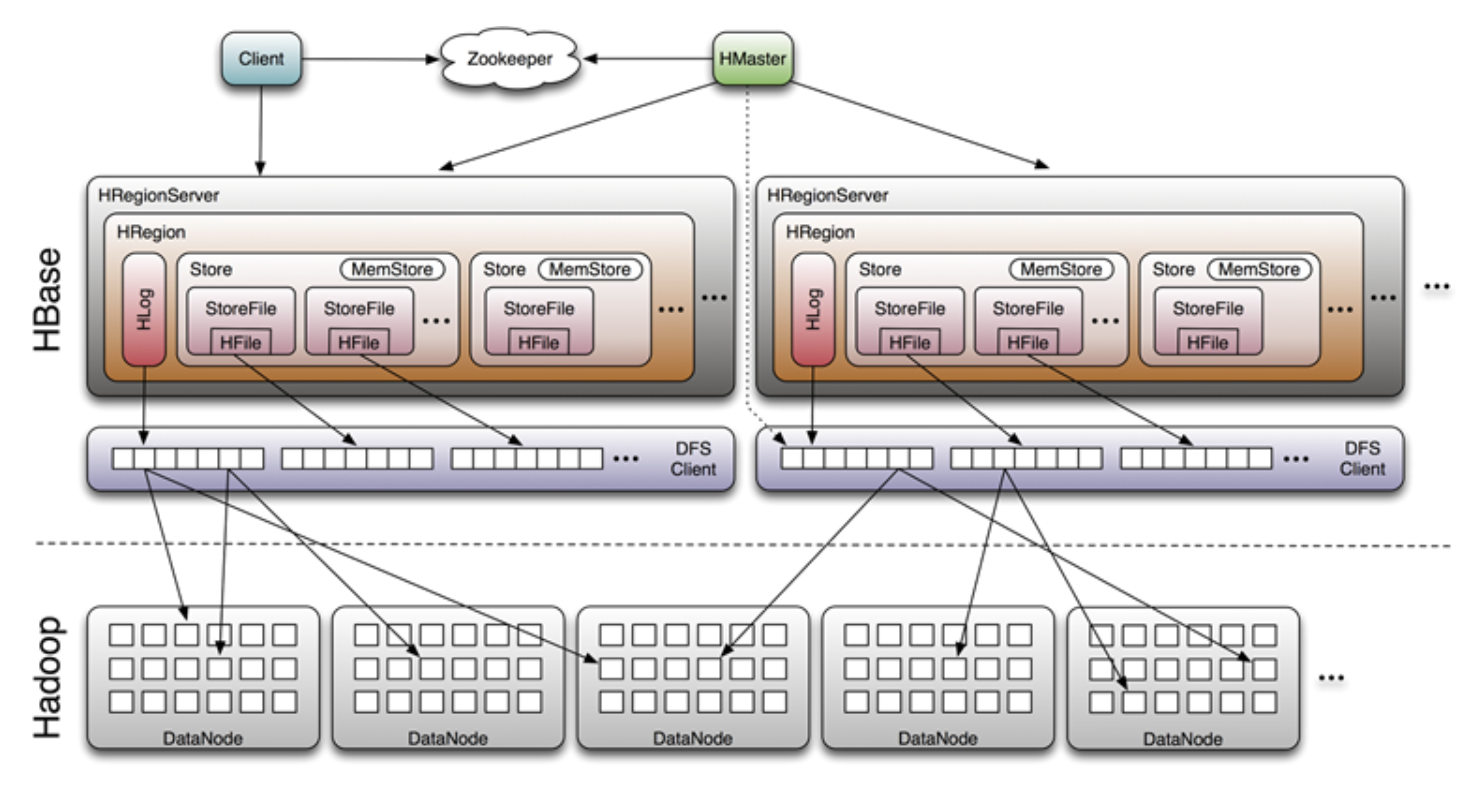
以上这些大概就是HBase存储的设计主要思想,这里分别对应说明下:
- 因为小树先写到内存中,为了防止内存数据丢失,写内存的同时需要暂时持久化到磁盘,对应了HBase的MemStore和HLog
- MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中(一般是Hadoop DataNode),这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。
关于LSM Tree,对于最简单的二层LSM Tree而言,内存中的数据和磁盘你中的数据merge操作,如下图
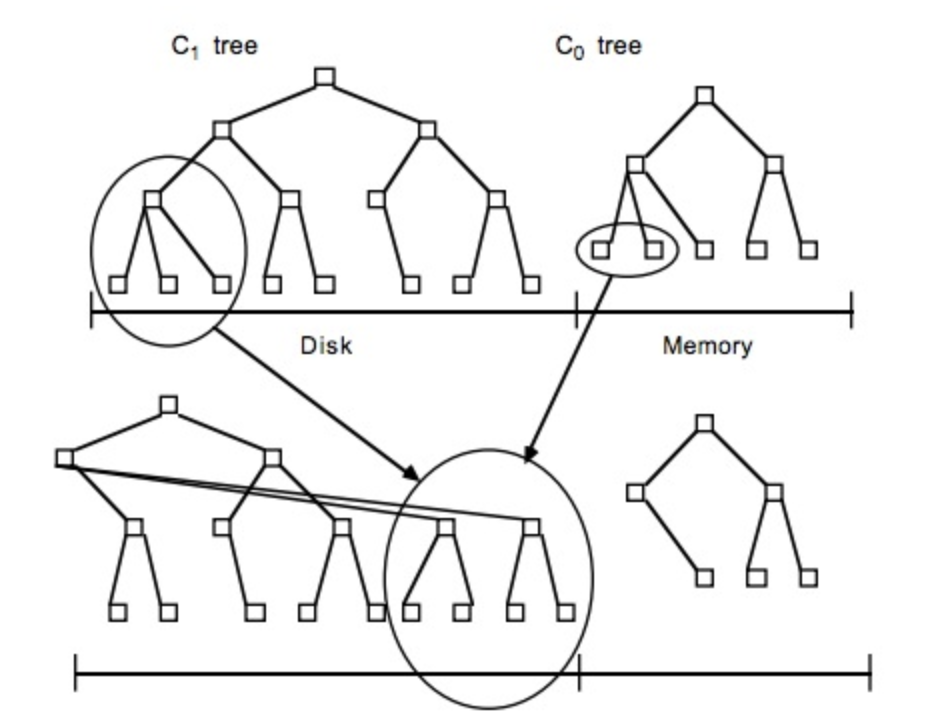
lsm tree,理论上,可以是内存中树的一部分和磁盘中第一层树做merge,对于磁盘中的树直接做update操作有可能会破坏物理block的连续性,但是实际应用中,一般lsm有多层,当磁盘中的小树合并成一个大树的时候,可以重新排好顺序,使得block连续,优化读性能。
hbase在实现中,是把整个内存在一定阈值后,flush到disk中,形成一个file,这个file的存储也就是一个小的B+树,因为hbase一般是部署在hdfs上,hdfs不支持对文件的update操作,所以hbase这么整体内存flush,而不是和磁盘中的小树merge update,这个设计也就能讲通了。内存flush到磁盘上的小树,定期也会合并成一个大树。整体上hbase就是用了lsm tree的思路。
HBase总结 LSM理解的更多相关文章
- sstable, bigtable,leveldb,cassandra,hbase的lsm基础
先看懂文献1和2 1. 先了解sstable.SSTable: Sorted String Table [2] [10] WiscKey: 类似myisam, key value分离, 根据ssd优 ...
- <HBase><读写><LSM>
Overview HBase中的一个big table,首先会按行划分成一些region(这些region之间是有序的,由startkey保证),每个region分配到不同的节点进行存储.因此,reg ...
- 快速理解 Phoenix : SQL on HBASE
转自:http://blog.csdn.net/colorant/article/details/8645081 ==是什么 == 目标Scope EasyStandard SQL access on ...
- hbase概念
1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有的HBase中的理念,都可 ...
- HBase概念及表格设计
HBase概念及表格设计 1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有 ...
- HBase写请求分析
HBase作为分布式NoSQL数据库系统,不单支持宽列表.而且对于随机读写来说也具有较高的性能.在高性能的随机读写事务的同一时候.HBase也能保持事务的一致性. 眼下HBase仅仅支持行级别的事务一 ...
- [Spark] 04 - HBase
BHase基本知识 基本概念 自我介绍 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”. ...
- 【转帖】LSM树 和 TSM存储引擎 简介
LSM树 和 TSM存储引擎 简介 2019-03-08 11:45:23 长烟慢慢 阅读数 461 收藏 更多 分类专栏: 时序数据库 版权声明:本文为博主原创文章,遵循CC 4.0 BY-S ...
- HBase原理 – 分布式系统中snapshot是怎么玩的?(转载)
snapshot(快照)基础原理 snapshot是很多存储系统和数据库系统都支持的功能.一个snapshot是一个全部文件系统.或者某个目录在某一时刻的镜像.实现数据文件镜像最简单粗暴的方式是加锁拷 ...
随机推荐
- 【Machine Translation】CMU的NMT教程论文:最全面的神经机器翻译学习教程
这是一篇CMU发的神经机器翻译教程论文,很全很详细,适合新手阅读,即使没有什么MT.DNN.RNN的基础知识. 另外它还配套了CMU自己的一个框架DyNet的练习. 全文共9章,从统计语言模型到DNN ...
- Windows Linux的cmd命令查询指定端口占用的进程并关闭
以端口8080为例: Windows 1.查找对应的端口占用的进程:netstat -aon|findstr "8080",找到占用8080端口对应的程序的PID号: 2.根 ...
- 【dp】求最长上升子序列
题目描述 给定一个序列,初始为空.现在我们将1到N的数字插入到序列中,每次将一个数字插入到一个特定的位置.我们想知道此时最长上升子序列长度是多少? 输入 第一行一个整数N,表示我们要将1到N插入序列中 ...
- 2733: [HNOI2012]永无乡 线段树合并
题目: https://www.lydsy.com/JudgeOnline/problem.php?id=2733 题解: 建n棵动态开点的权值线段树,然后边用并查集维护连通性,边合并线段树维护第k重 ...
- EXCEL(1)级联下拉框
EXCEL级联下拉框 http://jingyan.baidu.com/article/3c343ff756e0cf0d377963f9.html 在输入一些多级项目时,如果输入前一级内容后,能够自动 ...
- bootstrap学习: 折叠插件和面板
bootstrap提供了面板排版工具和折叠插件,能够用来实现新闻列表.留言板.博客分块等: 1.折叠插件: <a data-toggle="collapse" data-ta ...
- tensorflow Method源码阅读之 fully_connected
https://www.tensorflow.org/api_docs/python/tf/contrib/layers/fully_connected fully_connected: 1.先根据权 ...
- MySQL初步
一 写在开头1.1 本节内容本节的主要内容是MySQL的基本操作(来自MySQL 5.7官方文档). 1.2 工具准备一台装好了mysql的ubuntu 16.04 LTS机器. 二 MySQL的连接 ...
- JavaScript 基础六 'use strict'严格模式下的规则
why 严格模式 [1] 消除js语法的一些不合理.不严谨.不安全问题,减少怪异行为并保证代码运行安全 [2] 提高编译器效率,增加运行速度 使用 [1]整个脚本启用严格模式,在顶部执行:" ...
- luogu 4042 有后效性的dp
存在有后效性的dp,但转移方程 f[i] = min( f[i], s[i] + sigma f[j] ( j 是后效点) ) 每次建当前点和 转移点的边 e1, 某点和其会影响的点 e2 spfa ...