Azkaban日志中文乱码问题解决
Azkaban作为LinkedIn开源的任务流式管理工具,在工作中很大程度上被用到。但是,由于非国人开发,对中文的支持性很不好。大多数情况下,会出现几种乱码现象: - 执行内置脚本生成log乱码 - 直接command执行中文乱码 - 中文包名乱码等,其中对日常使用影响最大的就是日志乱码问题。不管是调度Hive、DataX还是Java程序,只要日志抛出来中文,中文都是乱码显示,将日志文件拷贝出来查看文件格式为GB2312,但是Linux系统编码和Azkaban日志编码明明设置的都是UTF-8,很疑惑,摸索许久,决定从源码入手开始层层解惑。
文中大部分内容从源码一步步进入解析,有经验的朋友可以跳至文末见具体解决方法。
根据页面获取日志的接口可以知道方法在 azkaban-web-server项目下package azkaban.webapp.servlet 下的方法handleAJAXAction,如下图 请求参数是fetchExecJobLogs

对应的处理方法为 ajaxFetchJobLogs(req, resp, ret, session.getUser(), exFlow)和ajaxFetchExecFlowLogs(req, resp, ret, session.getUser(), exFlow)

进入该方法后可以发现返回的data为经过 StringEscapeUtils.escapeHtml格式化过的,这就是引发乱码的原因之一。
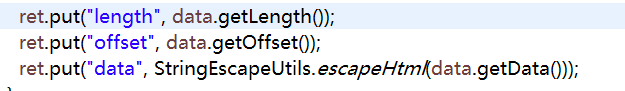
改用commons-lang3下的方法可以解决这个问题,增加如下依赖后更新gradle项目,将此处StringEscapeUtils.escapeHtml(data.getData())更改为 org.apache.commons.lang3.StringEscapeUtils.escapeHtml3(data.getData())
// https://mvnrepository.com/artifact/org.apache.commons/commons-lang3
compile group: 'org.apache.commons', name: 'commons-lang3', version: '3.4'
修改后为
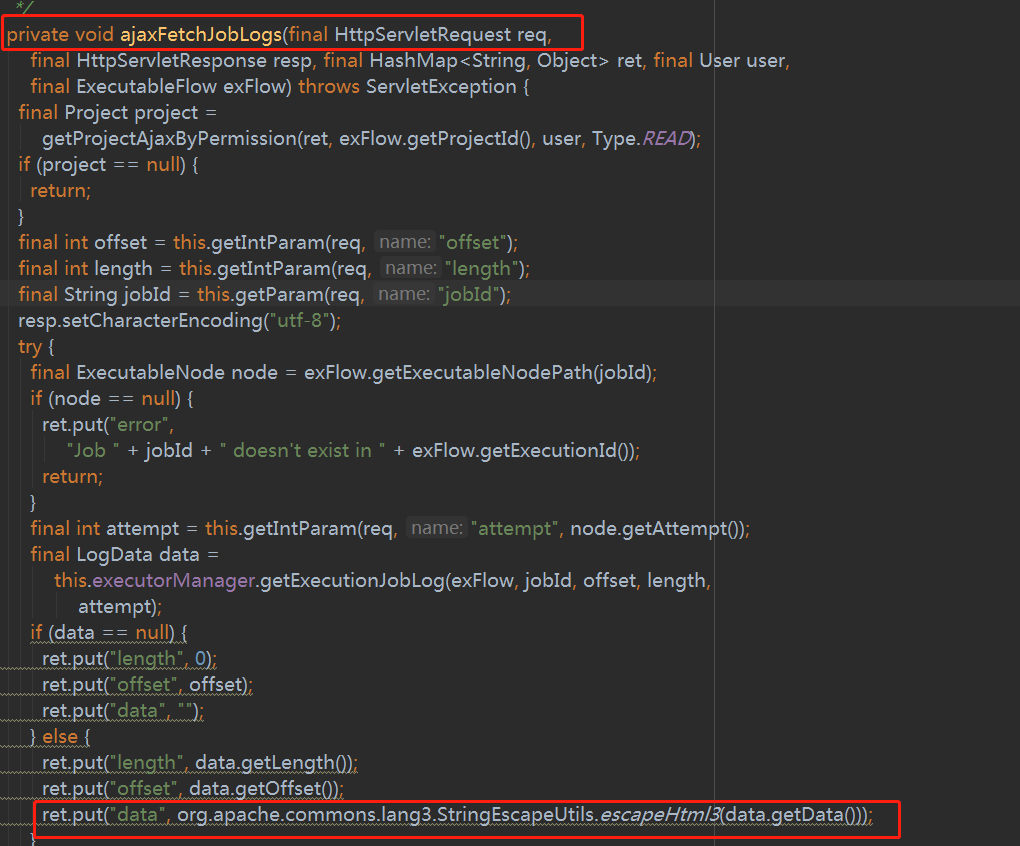
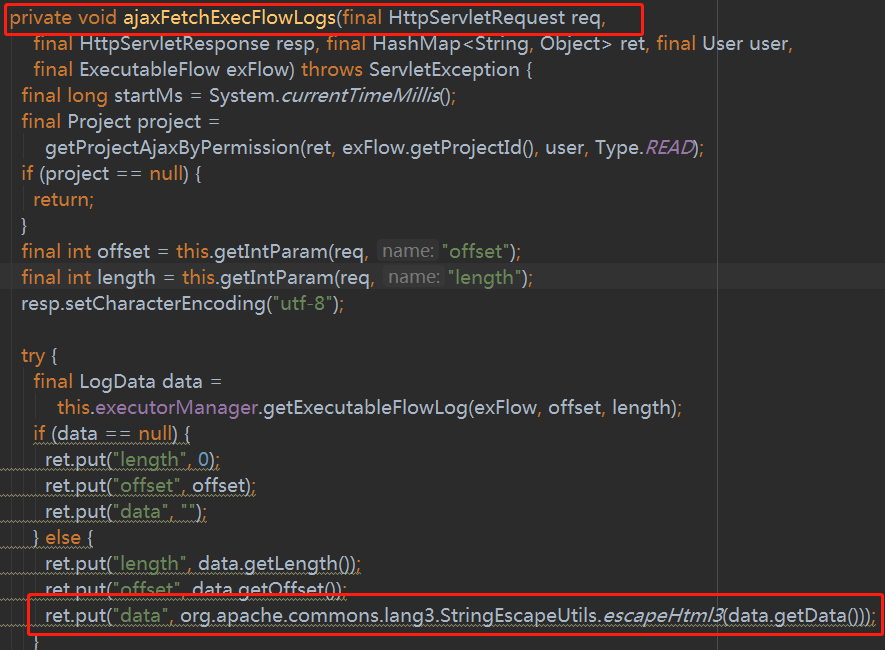
仔细研读代码可以发现其实这样还不够,读取日志的时候会先判断该任务是否正在执行,如果在执行的话就直接在服务器上暂存日志路径读取,否则是话就在mysql表读取,具体代码如下
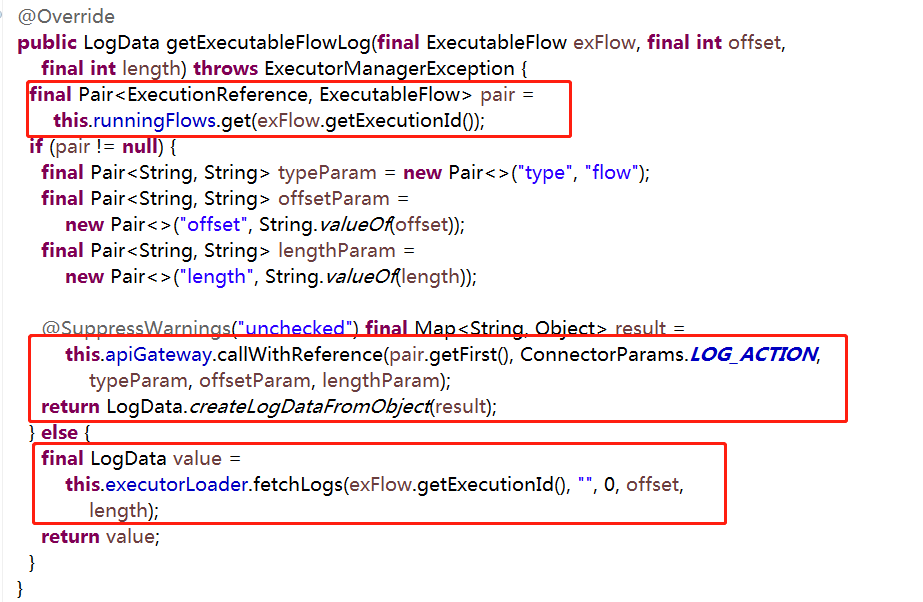
一.本地文件读取的话是走http请求的,对应的为azkaban-exec-server下的包package azkaban.execapp下的ExecutorServlet
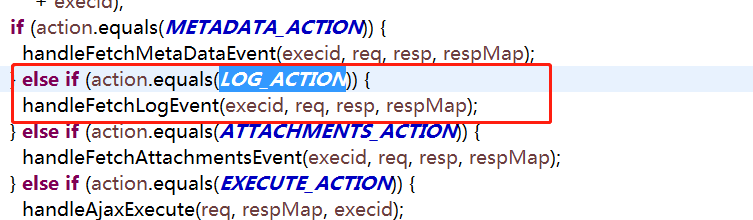
进入方法handleFetchLogEvent,一个是FlowLogs 一个是JobLogs ,
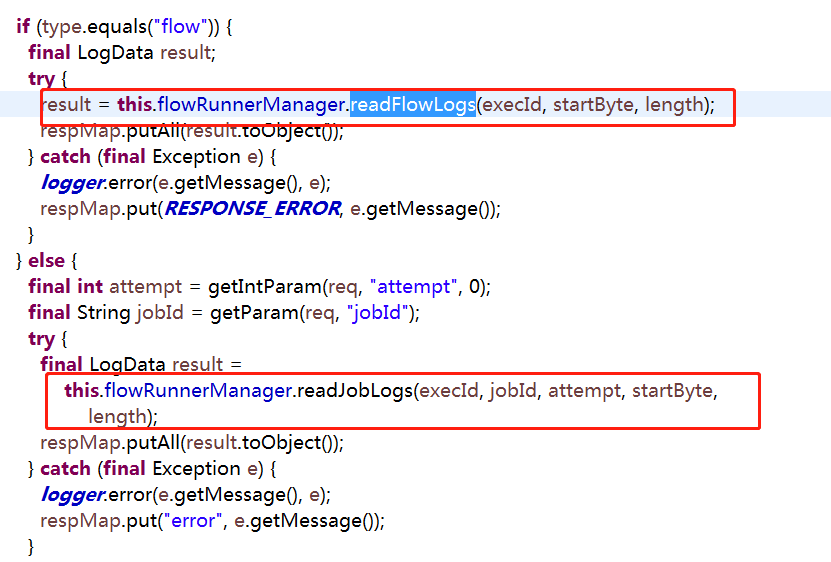
进入这两个方法后发现最终都是调用的FileIOUtils.readUtf8File()这个方法

读取日志的核心方法就是这个了
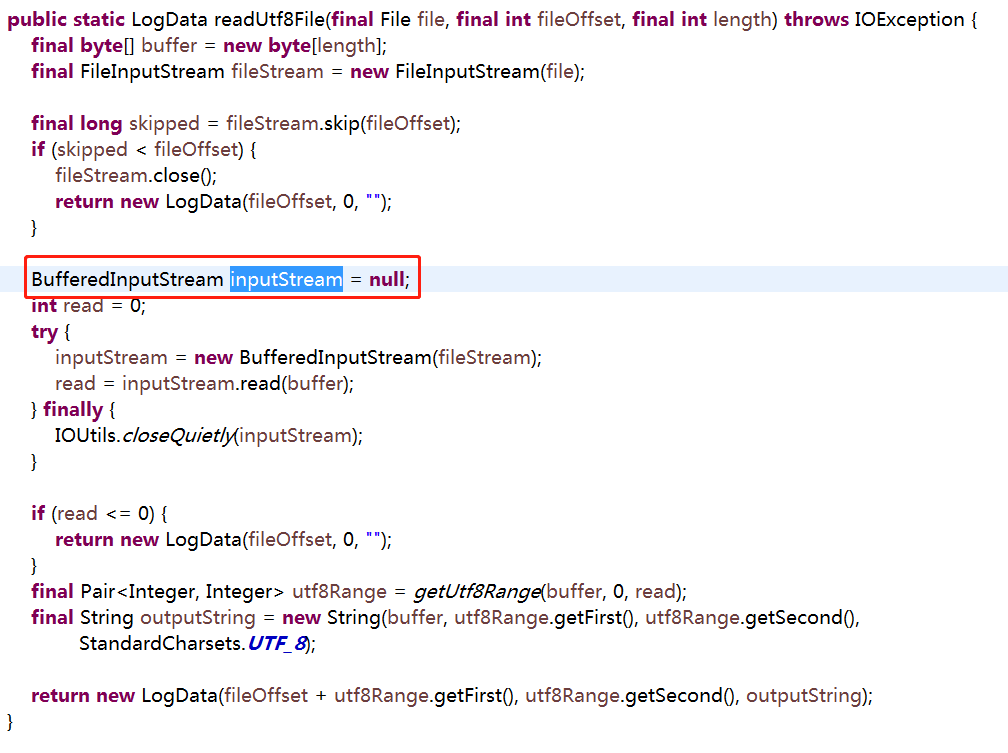
BufferedInputStream读取的是字节byte,因为一个汉字占两个字节,而当中英文混合的时候,有的字符占一个字节,有的字符占两个字节,所以如果直接读字节,而数据比较长,没有一次读完的时候,很可能刚好读到一个汉字的前一个字节,这样,这个中文就成了乱码,后面的数据因为没有字节对齐,也都成了乱码.所以我们需要用BufferedReader来读取,
它读到的是字符,所以不会读到半个字符的情况,不会出现乱码。
在这里修改方法后为一个新方法如下(编码方式GBK根据生成的日志编码格式设定)
public static LogData readUtf8FileEncode(final File file, final int fileOffset, final int length)
throws IOException {
final char[] chars = new char[length];
final FileInputStream fileStream = new FileInputStream(file); final long skipped = fileStream.skip(fileOffset);
if (skipped < fileOffset) {
fileStream.close();
return new LogData(fileOffset, 0, "");
} BufferedReader reader = null;
int read = 0;
try {
reader = new BufferedReader(new InputStreamReader(fileStream, "GBK"));
read = reader.read(chars);
} finally {
IOUtils.closeQuietly(reader);
} if (read <= 0) {
return new LogData(fileOffset, 0, "");
}
final byte[] buffer = new String(chars).getBytes();
final Pair<Integer, Integer> utf8Range = getUtf8Range(buffer, 0, read);
final String outputString = new String(buffer, utf8Range.getFirst(), utf8Range.getSecond(),
StandardCharsets.UTF_8); return new LogData(fileOffset + utf8Range.getFirst(), utf8Range.getSecond(), outputString);
}
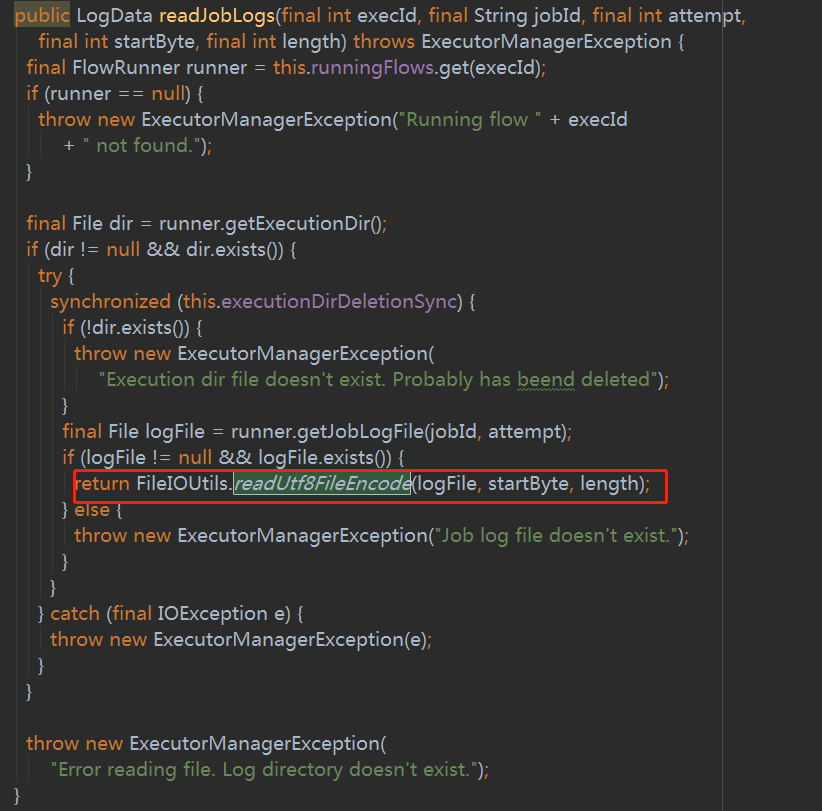
在原来引用的地方替换为新的即可,如下图。
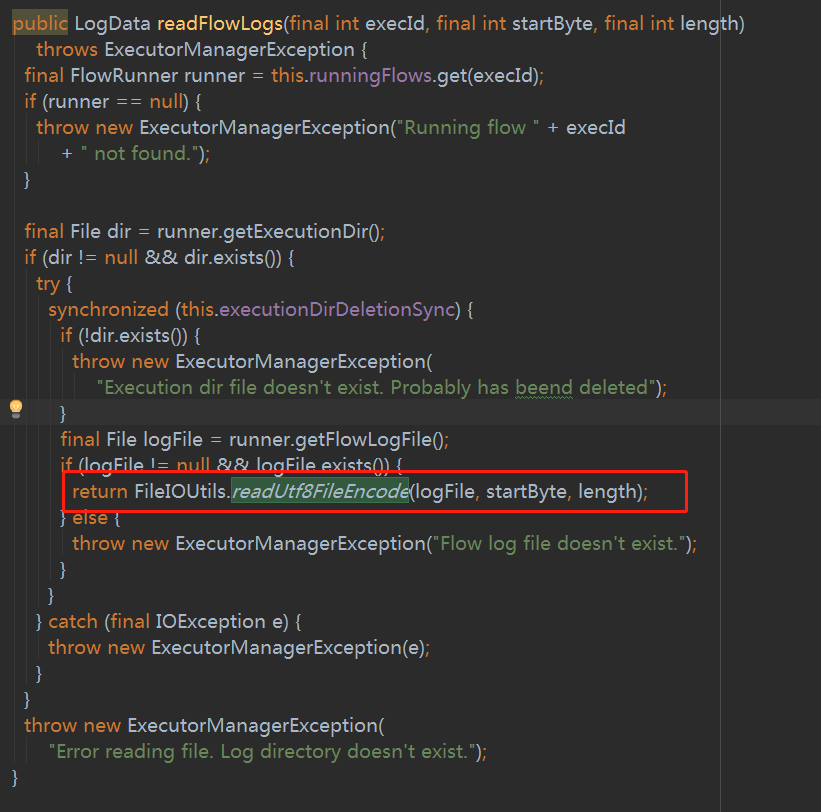
二.对于运行完成的,日志会被写入数据库,而且是经过压缩的,方法为 package azkaban.executor下的ExecutionLogsDao 搜索找到fetchLogs,在方法体中实例化了一个FetchLogsHandler
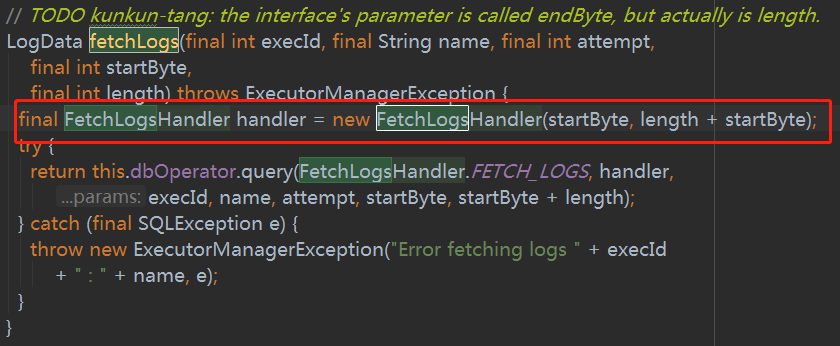
在FetchLogsHandler中核心方法为handle,在这个方法中可以发现这块会有解压缩的过程,开始怀疑是不是这块出现问题,测试后否定了这一猜想。
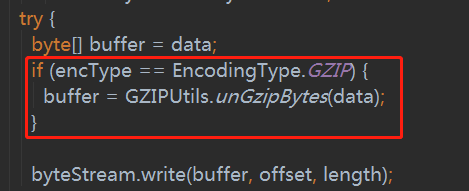
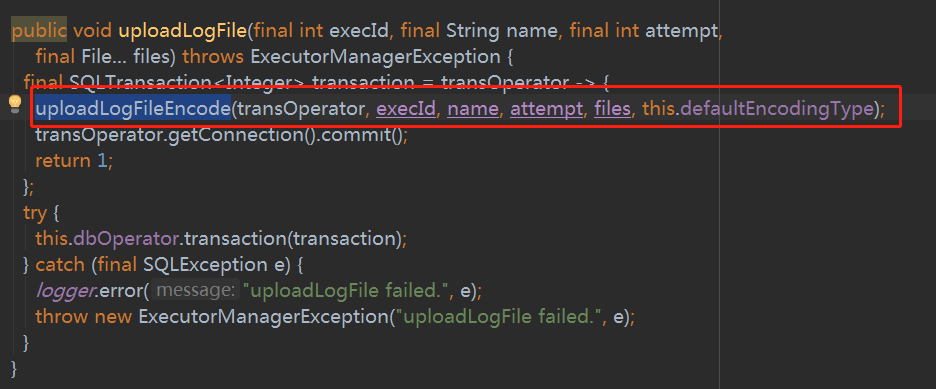
这里有解压,那在入库之前肯定会有压缩过程,再找到入库的方法(如何触发将本地文件写入到数据库在这里不讨论)uploadLogFile(ExecutionLogsDao方法中)
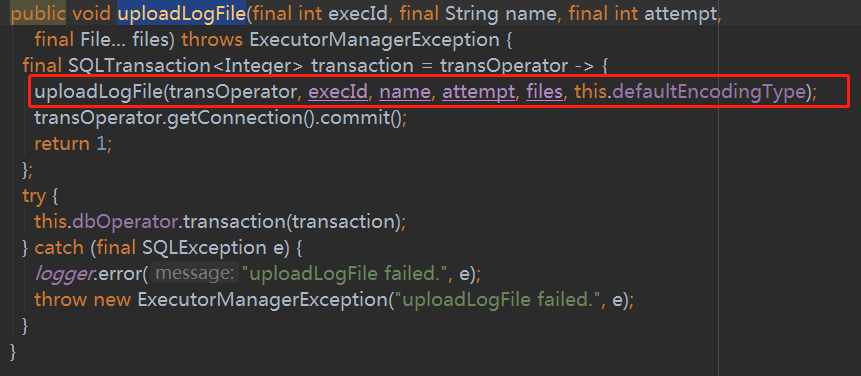
进入方法体后可以发现和之前类似,也是采用BufferedInputStream读取文件
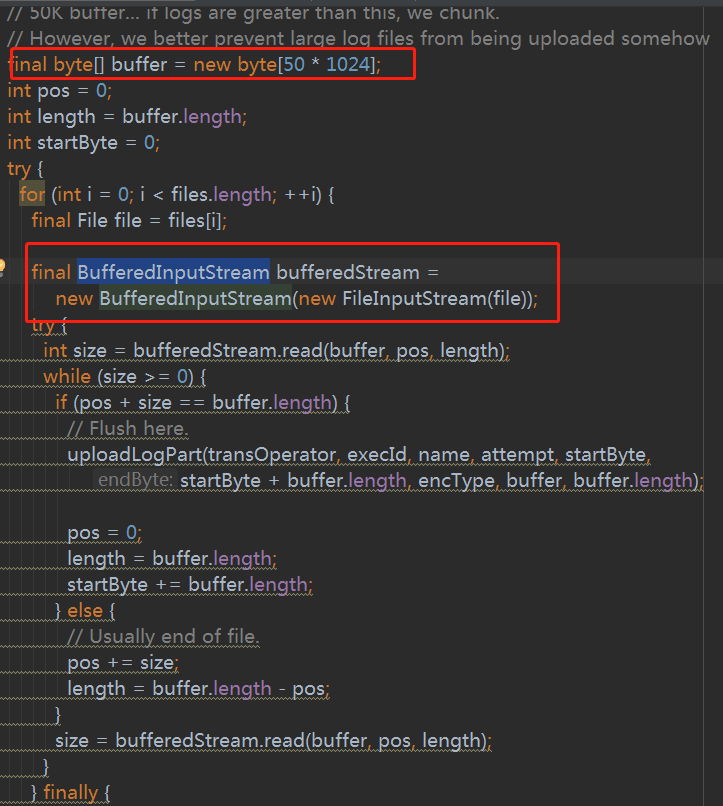
修改后的方法为如下(编码方式GBK根据生成的日志编码格式设定)
private void uploadLogFileEncode(final DatabaseTransOperator transOperator, final int execId, final String name,
final int attempt, final File[] files, final EncodingType encType) throws SQLException {
// 50K buffer... if logs are greater than this, we chunk.
// However, we better prevent large log files from being uploaded somehow
final char[] buffer = new char[50 * 1024];
int pos = 0;
int length = buffer.length;
int startByte = 0;
try {
for (int i = 0; i < files.length; ++i) {
final File file = files[i];
// BufferedInputStream读取的是字节byte,因为一个汉字占两个字节,而当中英文混合的时候,有的字符占一个字节,
// 有的字符占两个字节,所以如果直接读字节,而数据比较长,没有一次读完的时候,很可能刚好读到一个汉字的前一个字节,
// 这样,这个中文就成了乱码,后面的数据因为没有字节对齐,也都成了乱码.所以我们需要用BufferedReader来读取,
// 它读到的是字符,所以不会读到半个字符的情况,不会出现乱码
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file), "GBK"));
try {
int size = reader.read(buffer, pos, length);
while (size >= 0) {
if (pos + size == buffer.length) {
// Flush here.
uploadLogPart(transOperator, execId, name, attempt, startByte, startByte + buffer.length,
encType, buffer, buffer.length); pos = 0;
length = buffer.length;
startByte += buffer.length;
} else {
// Usually end of file.
pos += size;
length = buffer.length - pos;
}
size = reader.read(buffer, pos, length);
}
} finally {
IOUtils.closeQuietly(reader);
}
} // Final commit of buffer.
if (pos > 0) {
uploadLogPart(transOperator, execId, name, attempt, startByte, startByte + pos, encType, buffer, pos);
}
} catch (final SQLException e) {
logger.error("Error writing log part.", e);
throw new SQLException("Error writing log part", e);
} catch (final IOException e) {
logger.error("Error chunking.", e);
throw new SQLException("Error chunking", e);
}
} private void uploadLogPart(final DatabaseTransOperator transOperator, final int execId, final String name,
final int attempt, final int startByte, final int endByte, final EncodingType encType, final char[] buffer,
final int length) throws SQLException, IOException {
final String INSERT_EXECUTION_LOGS = "INSERT INTO execution_logs "
+ "(exec_id, name, attempt, enc_type, start_byte, end_byte, "
+ "log, upload_time) VALUES (?,?,?,?,?,?,?,?)"; byte[] buf = new String(buffer).getBytes();
if (encType == EncodingType.GZIP) {
buf = GZIPUtils.gzipBytes(buf, 0, buf.length);
} else if (length < buffer.length) {
buf = new String(buffer, 0, length).getBytes();
} transOperator.update(INSERT_EXECUTION_LOGS, execId, name, attempt, encType.getNumVal(), startByte,
startByte + length, buf, DateTime.now().getMillis());
以上代码直接放在ExecutionLogsDao内即可,修改引用的地方
至此日志显示中文乱码问题即可解决。以上为代码分析过程,操作过程可直接总结如下:
1.添加commons-lang3依赖
// https://mvnrepository.com/artifact/org.apache.commons/commons-lang3
compile group: 'org.apache.commons', name: 'commons-lang3', version: '3.4'
2.azkaban-web-server -->package azkaban.webapp.servlet-->ExecutorServlet-->将方法ajaxFetchExecFlowLogs和ajaxFetchJobLogs中的StringEscapeUtils.escapeHtml替换为org.apache.commons.lang3.StringEscapeUtils.escapeHtml3
3.azkaban-common-->package azkaban.utils-->FileIOUtils-->增加方法readUtf8FileEncode (文中第一段代码)
4.azkaban-common-->package azkaban.execapp-->FlowRunnerManager-->分别将readFlowLogs和readJobLogs中readUtf8File替换为readUtf8FileEncode
5.azkaban-common-->package azkaban.executor-->ExecutionLogsDao-->增加方法uploadLogFileEncode和uploadLogPart(重载)(文中第二段代码),将uploadLogFile(在70行左右的这个方法public void uploadLogFile(final int execId, final String name, final int attempt, final File... files))中的uploadLogFile替换为uploadLogFileEncode
代码修改就是这些,我们可以发现代码中解析文件流都是采用UTF-8,如果生成的日志是其他编码就会出现乱码的情况,所以需要在读取文件的地方指定日志文件编码(还有一种思路就是Log4j写日志时候就指定编码,尝试没有成功就采用了现在的方式),来张前后对比图(对于已经写入数据库的日志,中文乱码问题无法解决,因为写入数据库前读取文件的方法不支持中文,修改代码之后入数据库的日志可以支持中文,另外代码中的GBK可以根据日志编码更换)

Azkaban日志中文乱码问题解决的更多相关文章
- WingIDE中文乱码问题解决方法
WingIDE中文乱码问题解决方法 安装完WingIDE后,首次运行python脚本时,若脚本中含有UTF-8中文,在Debug I/O输出框中,全部变成了乱码. 这时其实我们设置下WingIDE的编 ...
- ubuntu mysql emma中文乱码问题解决
ubuntu mysql emma中文乱码问题解决 emma默认用apt-get 安装的话,emma是不支持中文的,配置文件或直接修改emma程序源文件(python). apt-get安装emma ...
- Spring MVC3返回JSON数据中文乱码问题解决(转)
Spring MVC3返回JSON数据中文乱码问题解决 查了下网上的一些资料,感觉比较复杂,这里,我这几使用两种很简单的办法解决了中文乱码问题. Spring版本:3.2.2.RELEASE Jack ...
- Ubuntu下Eclipse中文乱码问题解决(转)
Ubuntu下Eclipse中文乱码问题解决 把Windows下的工程导入到了Linux下Eclipse中,由于以前的工程代码,都是GBK编码的(Windows下的Eclipse 默认会去读取系统的编 ...
- 【转】asp.net Cookie值中文乱码问题解决方法
来源:脚本之家.百度空间.网易博客 http://www.jb51.net/article/34055.htm http://hi.baidu.com/honfei http://tianminqia ...
- soapUI参数中文乱码问题解决方法 (groovy脚本中文乱码)
soapUI参数中文乱码问题解决方法 可能方案1: 字体不支持中文,将字体修改即可: file-preferences-editor settings-select font 修改字体,改成能显示中文 ...
- oracle中文乱码问题解决
中文乱码问题解决:1.查看服务器端编码select userenv('language') from dual;我实际查到的结果为:AMERICAN_AMERICA.ZHS16GBK2.执行语句 se ...
- 【其他】【navicat】【1】navicat导入txt文件中文乱码问题解决
正文: TXT文件默认编码为ANSI,另存为编码为UTF-8的文本文件即可 备注: 1,一般需要导入的数据都是一张excel表,需要将excel表另存为“文本文件(制表符分隔)(*.txt)”保存类型 ...
- LoadRunner中文乱码问题解决方法
LoadRunner中文乱码问题解决方法 前段时间在录制,增强,整合LoadRunner脚本,期间两次遇到了中文乱码问题.在此记录一下中文乱码问题的解决办法. 一.录制回放中文乱码 我录制登陆的脚本, ...
随机推荐
- 非阻塞connect:Web客户程序
一.web.h #include <stdio.h> #include <netdb.h> #include <errno.h> #include <fc ...
- Python核心编程笔记 第三章
3.1 语句和语法 3.1.1 注释( # ) 3.1.2 继续( \ ) 一般使用换行分隔,也就是说一行一个语句.一行过长的语句可以使用反斜杠( \ ) 分 ...
- Arduino—运算符
赋值运算符: = += -+ *= /= %= 取余等于 &= 与等于 &=(与等于)对某个变量的值按位进行与运算,例如:G&=x ...
- vue-router.esm.js:1905 TypeError: Cannot convert undefined or null to object
环境:vue+vuex+element 报错原因 ...mapState('isDialNumber') mapState如果传递一个参数,参数必须是数组 ...mapState(['isDialNu ...
- Eclipse使用Git检出项目
1.打开Eclipse——File——Import...: 2.在弹出的Import框中选择Git——Projects from Git——NEXT: 3.选择Clone URI——Next: 4.输 ...
- mac 删除文件夹里所有的.svn文件
先用命令行,进入你要删除的文件夹中(./ 为这个文件夹的当前路径,也可以填写绝对路径) 命令行下输入: sudo find ./ -name ".svn" -exec rm -r ...
- 关于shell变量的继承总结
结论: 默认,父shell和子shell的变量是隔离的. sh方式运行脚本,会重新开启一个子shell,无法继承父进程的普通变量,能继承父进程export的全局变量. source或者. 方式运行脚本 ...
- JAVA学习笔记(2)—— java初始化三个原则
1. 初始化原则 (1) 静态对象(变量)优先于非静态对象(变量)初始化,其中静态对象(变量)初始化一次,非静态对象(变量)可能会初始化多次. (2) 父类优先于子类初始化 (3) 按照成 ...
- 记录一个pom文件
rt <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://m ...
- fiddler限制网速
在测试过程中,经常会要求测试弱网络情况时的一些特殊情况,这时候IOS还好说,在开发者选项中调整网络模式即可,但android就只能通过别的方式了,这里整理了通过fiddler抓包工具来设置弱网模式,在 ...