机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析
在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去改进从而使下次得到的model更加令人满意呢?
”偏差-方差分解(bias-variance decomposition)“是解释学习算法泛化能力性能的一种重要工具。偏差-方差分解试图对学习算法的期望泛化错误率进行拆解。
假设测试样本为x,yd 为 x 在数据集中的标记(注意,有可能出现噪声使得 yd != y,即所谓的打标样本不纯),y 为 x 的真实标记,f(x;D)为在训练集 D 上训练得到的模型 f 在 x 上的预测输出。
以回归任务为例,学习算法的期望预测为:
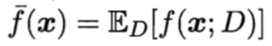
上式可被分解为:

整理得:
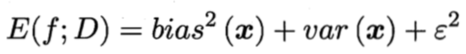
即,泛化误差可分解为:偏差、方差、噪声之和。
0x1:方差:模型的预测稳定性 - 数据扰动对模型的影响
使用样本数相同,但是不同批次的训练集产生的预测方差为:
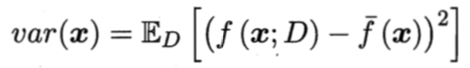
预测方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
笔者插入:上式中其实也蕴含了结构风险公式的内涵,即结构风险越小,模型抗扰动的能力就越强。
一个具备良好泛化能力的模型应该有较小的扰动方差。这和算法模型采取的”归纳偏好策略“有关,一个典型的例子就是SVM的支持向量最大距离策略,这种策略保证了在相同的支持向量候选集(即候选假设空间)中,选择距离支持向量相对距离最远的那个超分界面。同时这也符合”奥卡姆剃刀原则“,若有多个假设与观察一致,则选最简单的那个。
那么在实际操作中,有几种策略和方法可以降低模型的方差:
. 控制训练轮数、提前停止训练、学习率逐渐减小渐进逼近等策略;
. 使用例如决策树里的剪枝策略,控制模型复杂度;
. 使用正则化等手段,控制模型复杂度;
. 使用Dropout手段,控制模型复杂度;
0x2:噪声:模型在当前任务能达到的期望泛化误差的下届 - 数据决定算法的上界,算法只是在逼近这个上界
如果我们的打标样本中存在噪声,即错误标记,则噪声公式为:
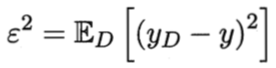
很显然,如果一个训练集中全部都是噪声(即所有样本都标记错误了),则模型的预测期望为0。噪声表达了在当前任务上”任何“学习算法(和具体算法无关)所能得到的期望泛化误差的下界,即刻画了学习问题本身的难度。
毫无疑问,在开始机器学习的模型开发之前,一件非常重要的事情就是”样本打标提纯“,这件事非常重要,甚至某种程度上来说比特征工程、模型选择、模型调参等环节都重要。但有时候会遭到开发者的忽略,拿到样本后就急匆匆开始项目,笔者自己在项目中也吃过类似的亏,需要牢记一句话:数据决定算法的上界,算法只是在逼近这个上界。
0x3:偏差:考察模型本身拟合能力
期望输出与真实标记的差别称为偏差(bias),即:
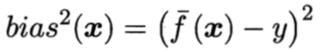
它体现了模型的拟合能力,这其实也就是经验风险的计算公式。
0x4:偏差-方差窘境(bias-variance dilemma)
偏差-方差分解说明,泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定的。给定一个学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。
一般来说,偏差与方差是有冲突的,这称为”偏差-方差窘境“,下图中,给定学习任务,假定我们能控制学习算法的训练程度,则在不同训练程度下,偏差-方差的取值曲线如下:

在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;
随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;
在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的普遍特性被学习器学到了,则将发生过拟合。
0x5:经验误差与泛化能力之间的矛盾
在整个偏差-方差公式中,提高训练样本的数量N是我们无法控制的,在实际项目中,高质量的打标样本是比较困难获取的,即使可以获取也要付出比较高的成本,我们能做的就是在现有的样本集上,得到一个相对最好的模型。 另一方面,打标样本的提纯是我们可以做的,但是人工的成本往往巨大,能否做到100%的提纯也是一个挑战。
抛开这两个因素不谈,我们本文重点讨论一下模型预测方差和模型拟合偏差的问题,也就是经验误差和泛化能力之间的平衡,即兼顾overfitting和underfitting的方法,如何让我们的模型尽可能靠近上图中那个”交汇点“。
这里多谈一点,可能有读者会有疑问,上图中的交汇点为什么不在横轴上呢?即为什么取值不能为零?即找到一个完美的解决方案,即没有方差也没有偏差。
关于这一点,可以这样理解:机器学习面临的问题通常是 NP 难甚至更难,而有效的学习算法必然是在多项式时间内运行完成(假设搜索空间过于庞大),若可彻底避免过拟合,则通过经验误差最小化就能获得最优解,这就意味着我们构造性地证明了”P=NP“,因此,主要相信”P != NP“,过拟合和欠拟合就不可完全调和。
综上所述,在一个项目中针对算法部分,我们需要做的最重要的工作就是防住过拟合,同时让模型尽量去拟合训练样本。我们接下来的内容会围绕过拟合这个话题以及如何避免过拟合展开讨论。
2. 经验误差(empirical error)与过拟合(overfitting)
一般地,我们把学习器的实际预测输出与样本的真实输出之间的差异称为“误差(error)”,学习器在训练集上的误差称为“训练误差”或“经验误差”,在未来的新样本上的误差称为“泛化误差”。显然,我们希望得到泛化误差小的学习器。
然而,我们事先不可能知道新样本是什么样的(即我们不可能知道事物的完整全貌),我们实际能做的是努力使经验误差最小化,但遗憾的是,经验最小化的学习器,未必就是泛化误差小的学习器。
我们实际希望的是在新样本上能表现得很好的学习器,为了达到这个目的,应该从训练样本中尽可能学出适用于所有潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确的判别。
然后,当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点(甚至可能是噪音)当做了所有样本都会具有的一般性质,这样就会导致泛化性能下降。这种现象在机器学习中称为“过拟合(overfitting)”。与过拟合相对的是”欠拟合(underfitting)“,这是指对训练样本的一般性质尚未学号。

0x1:假设空间(hypothesis space)
给定学习算法 A,它所考虑的所有可能概念的集合称为假设空间,用符号 H 表示。对于假设空间中的任一概念,我们用符号 h 表示,由于并不能确定它是否真是目标概念,因此称为“假设”(hypothesis)
1. 模型空间/模型搜索空间
模型空间针对的是模型结构上的定义,例如使用线性回归模型、高斯分布模型、DNN复合线性模型、包含非线性激活函数的非线性DNN模型、CNN模型等。
即使是选定了线性多项式函数作为目标函数,函数的项目有多少?每项的幂次是多少?这些都属于模型搜索的范畴。
2. 模型参数搜索空间
模型参数搜索,也就是所谓的模型训练过程,本质上是在做模型超参数的搜索过程,我们本章接下来统一都叫参数搜索过程,笔者知道它们二者是相同的即可。
参数搜索解决的最主要的问题就是“权重分配”,机器学习中的目标函数都是多元的,即由大量的“原子判别函数”组成,所有的原子判别函数共同作用于待预测数据,给出一个最终的综合判断结果。
参数搜索会根据训练数据中包含的概率分布,对所有的原子判别函数的权重进行最优化调整,使其最大程度地拟合训练数据。
0x2:什么是过拟合?
首先,先抛出笔者的几个观点:
观点1:过拟合不是一个理论分析的结果,目前还不存在一个明确的理论,可以量化地分析过拟合是否发生、以及过拟合的程度(数值化)有多少。过拟合是一种可以被观测到的现象,在具体的场景中,当观测到某些现象的时候,我们说,此时发生了过拟合。
观点2:不是说使用了复杂函数就一定代表了过拟合,复杂函数不等于过拟合。
1. 判断发生过拟合的现象 - 训练集上得到的模型无法适应测试集
我们通过一个例子来讨论过拟合现象
1)数据集
假设我们要对一个简单的数据集建立模型:

我们的目标是构建一个模型,得到基于 x 的能预测 y 的函数。
2)选用复杂函数进行拟合
这里假设我们把 y 建模为关于 x 的多项式,这里多项式就是模型选择的结果。
并且省略模型参数搜索过程,直接假设最终多项式为 。
。
函数拟合的图像如下:

可以看到,函数精确拟合了数据
3)选用简单函数进行拟合
使用线性模型

4)是否发生了过拟合呢?哪个模型更容易产生过拟合呢?
严格来说,是否发生了过拟合,哪个模型更可能产生过拟合,这两个问题非常微妙。简单来说,答案是:实践是检验真理的唯一标准。
我们说过,过拟合是一种在项目实践中遇到的一个常见的现象,并不是一种高深的理论。
笔者希望向读者朋友传达的一个观点是:
上面两种函数(复杂的和简单的),都有可能产生过拟合,也都可能不产生过拟合,也可能复杂函数产生过拟合而简单函数泛化能力很好,所谓的“简单函数的泛化能力更好”不是一个有着坚实理论和数学基础的理论定理,它只是在长久的数据科学项目中,数据科学家们发现的一个普遍现象。
可以理解为属于经验科学的一个范畴,简单的模型不容易产生过拟合,简单的模型泛化能力更好,甚至所谓的奥卡姆剃刀原理。这个经验在很多时候是有效的,我们也没有什么理由不去应用这个经验。毕竟数据科学还是一个偏向实践和以结果说话的学科,得到好的结果是最重要的。
只是说,笔者希望读者朋友们不要太过于简单粗暴地认死理,认为说你设计的模型一定就需要遵循简单原理,凡是复杂的模型就是不好的。
判断发生过拟合的方法很简单,就是测试集。当我们用一份新的测试集去测试模型的时候,如果precision和recall发生了很严重的下降,则说明发生了过拟合,不管是什么内在原因(我们后面会分析可能的原因),过拟合肯定是发生了,模型在训练集和测试集上表现不一致就是过拟合的最主要的现象。
2. 过拟合产生的本质原因
过拟合发生的本质原因,是由于监督学习问题的不适定。过拟合现象的发生原因,可以分解成以下三点:
. 训练集和测试机特征分布不一致:
假如给一群天鹅让机器来学习天鹅的特征,经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的弯曲的,天鹅的脖子是长长的有点曲度,天鹅的整个体型像一个“”且略大于鸭子.这时候你的机器已经基本能区别天鹅和其他动物了。但是很不巧训练集中的天鹅全是白色的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅。
可以看到,训练集中的规律,“天鹅的体型是全局特征”,但是“天鹅的羽毛是白的”这实际上并不是所有天鹅都有的特征,只是局部样本的特征。
机器在学习全局特征的同时,又大量学习了局部特征,这才导致了泛化能力变产,最终导致不能识别黑天鹅的情况. . 在有限的样本中搜索过大的模型空间
在高中数学我们知道,从 n 个(线性无关)方程一定可以解 n 个变量,但是解 n+ 个变量就会解不出。因为有2个变量可能不在一个维度上。
在监督学习中,往往数据(对应了方程)远远少于模型空间(对应了变量)。
在有监督学习中,如果训练样本数小于模型搜索空间,则有限的训练数据不能完全反映出一个模型的好坏,然而我们却不得不在这有限的数据上挑选模型,因此我们完全有可能挑选到在训练数据上表现很好而在测试数据上表现很差的模型,因为我们完全无法知道模型在测试数据上的表现。
显然,如果模型空间很大,也就是有很多很多模型可以给我们挑选,那么挑到对的模型的机会就会很小。 . 训练过程中函数过多吸收了噪音数据的影响
fit model的时候加的parameter太多了,导致model太精准地抓住了这组数据的所有variance,不管是主要的数据趋势带来的variance还是噪音带来的variance都一并被拟合在了模型里。
用这个模型去预测原数据肯定是准确性更高,但放在一组具有相同趋势但细节不同的数据里时,预测效果就会下降。
3. 泛化误差评估方法
通常,我们通过实验测试来对学习器的泛化误差进行评估并进而做出选择。为此,需要一个和训练集互斥的数据集来测试学习器对新样本的判别能力,然后我们以测试集上的”测试误差(testing error)“作为泛化误差的近似。有几种方法得到测试集
1. 留出法(hold-out)
直接将数据集D划分为两个互斥的集合。需要注意的是,训练/测试集的划分要尽可能保持原始数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响,这种采样方式通常称为”分层采用(stratified sampling)“。
同时,单次使用留出法得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行试验评估取平均值作为留出法的评估结果。
此外,读者朋友要特别注意的是,我们希望评估的是用整个D数据集训练出的模型的性能,但留出法需要划分训练集/测试集,这就会导致一个窘境:
. 若令训练集S包含绝大多数样本,则训练出的模型可能更接近于D训练出的模型,但由于T比较小,评估结果可能不够稳定准确;
. 若令测试集T多包含一些样本,则训练集S与D的差别更大了,被评估的模型与用D训练出的模型相比可能有较大的差别,从而降低了评估结果的保真性;
从”偏差-方差“的角度来理解:测试集小时,评估结果方差较大;训练集小时,评估结果偏差较大。
2. 交叉验证法(cross validation)
交叉验证法是先将数据集D划分为 k 个大小相同的互斥子集,每个子集都尽可能保持数据分布的一致性。然后每次使用 k-1 个子集进行训练,余下的 1 个子集进行测试。
本质上来说,k折交叉验证和留出法没有区别
3. 自助法(bootstrapping)
我们希望评估的是用D训练出的模型,但在留出法和交叉验证法中,由于保留了一部分样本用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差。
自助法是一个比较好的解决方案,它直接以自助采样法(bootstrap sampling)为基础:
. 给定包含m个样本的数据集D,每次随机从D中随机采集一个样本,并放入D'中,并放回该样本;
. 这个过程重复m次后,我们就得到了包含m个样本的数据集D’;
显然,D中有一部分样本会在D'中多次出现,而另一部分样本根本不出现,可以做一个简单的估计,样本在m次采样中始终不被采到的概率为: ,取极限可以得到:
,取极限可以得到:
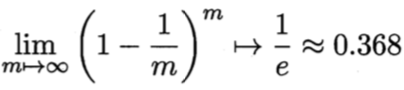
通过自助采样法,初始数据集D中约有36.8%的样本未出现在采样数据集D'中。于是我们可将D'用作训练集,而另外那36.8%作为测试集。
这样,从概率上,实际评估的模型与期望估计的模型都使用m个训练样本,而我们仍有36.%的样本没在训练集中被用作测试。这样的测试结果,被称为”包外估计(out-of-bag
estimate)“
笔者插入:自助法在数据集较小、难以有效划分训练/测试集时很有用。此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处。然而,自助法产生的数据集改变了原始数据集的分布,这会引入估计额外的新的估计偏差。
因此,在初始数据量足够时,留出法和交叉验证法更常用一些。
笔者插入:不管我们采取了什么测试集划分方法,在评估结束后,模型参数选定后,我们需要采用全集D进行训练,将数据集D训练得到的模型交付给业务方,这才是我们最终的模型。
0x3:复杂函数一定不好吗?复杂函数一定会导致过拟合吗?
我们从介绍两个正确结果是复杂模型的例子开始这个小节的讨论。
1. 复杂函数得到正确结果的例子
在 1940 年代物理学家马塞尔施恩(Marcel Schein)宣布发现了一个新的自然粒子。
他工作所在的通用电气公司欣喜若狂并广泛地宣传了这一发现。但是物理学家汉斯贝特(Hans Bethe)却怀疑这一发现。贝特拜访了施恩,并且查看了新粒子的轨迹图表。施恩向贝特一张一张地展示,但是贝特在每一张图表上都发现了一些问题,这些问题暗示着数据应该被丢弃。
最后,施恩向贝特展示了一张看起来不错的图表。贝特说它可能只是一个统计学上的巧合。施恩说「是的,但是这种统计学巧合的几率,即便是按照你自己的公式,也只有五分之一。」贝特说「但是我们已经看过了五个图表。」最后,施恩说道「但是在我的图表上,每一个较好的图表,你都用不同的理论来解释,然而我有一个假设可以解释所有的图表,就是它们是新粒子。」贝特回应道「你我的学说的唯一区别在于你的是错误的而我的都是正确的。你简单的解释是错的,而我复杂的解释是正确的。」随后的研究证实了大自然是赞同贝特的学说的,之后也没有什么施恩的粒子了。
这个例子中,施恩声称自己发现的新粒子,就代表了一种简单模型。
另一个例子是,1859 年天文学家勒维耶(Urbain Le Verrier)发现水星轨道没有按照牛顿的引力理论,形成应有的形状。
它跟牛顿的理论有一个很小很小的偏差,一些当时被接受的解释是,牛顿的理论或多或少是正确的,但是需要一些小小的调整。1916 年,爱因斯坦表明这一偏差可以很好地通过他的广义相对论来解释,这一理论从根本上不同于牛顿引力理论,并且基于更复杂的数学。尽管有额外的复杂性,但我们今天已经接受了爱因斯坦的解释,而牛顿的引力理论,即便是调整过的形式,也是错误的。这某种程度上是因为我们现在知道了爱因斯坦的理论解释了许多牛顿的理论难以解释的现象。此外,更令人印象深刻的是,爱因斯坦的理论准确的预测了一些牛顿的理论完全没有预测的现象。但这些令人印象深刻的优点在早期并不是显而易见的。如果一个人仅仅是以朴素这一理由来判断,那么更好的理论就会是某种调整后的牛顿理论。
在这个例子中,牛顿定理,就代表了一种简单模型。
2. 故事背后的意义
这些故事有三个意义:
第一,判断两个解释哪个才是真正的「简单」是一个非常微妙的事情;
第二,即便我们能做出这样的判断,简单是一个必须非常谨慎使用的指标;
第三,真正测试一个模型的不是简单与否,更重要在于它在预测新的情况时表现如何;
0x4:解决过拟合的一个有效的方法 - 正则化
谨慎来说,经验表明正则化的神经网络(在传统机器学习算法中也一样)通常要比未正则化的网络泛化能力更好。
事实上,研究人员仍然在研究正则化的不同方法,对比哪种效果更好,并且尝试去解释为什么不同的方法有更好或更差的效果。所以你可以看到正则化是作为一种「杂牌军」存在的。虽然它经常有帮助,但我们并没有一套令人满意的系统理解为什么它有帮助,我们有的仅仅是没有科学依据的经验法则。
笔者翻阅了大量的书籍和文献,在《机器学习导论》、《深入理解机器学习》这两本书的前部分章节中,介绍一些一些理论分析框架,可以从侧面对过拟合和正则化带来泛化能力上的优化背后的原理做了一些解释。篇幅非常长也很理论化,建议读者自行购书阅读。
笔者这里做一个概括性的总结:
. 经典的 bias-variance decomposition;
. PAC-learning 泛化界解释;
. Bayes先验解释,这种解释把正则化变成先验
1. 正则化作用一 - 减少权值参数个数
减小权值参数个数,主要是为了解决假设空间太大的问题。
先看一下二次多项式和十次多项式的区别——
二次多项式:
十次多项式:
下图可以看出来十次项的形式很复杂,虽然可以拟合训练集全部数据,但是“可能”严重过拟合。我们尝试把十次项出现的机会打压一下,即减少权值参数个数。
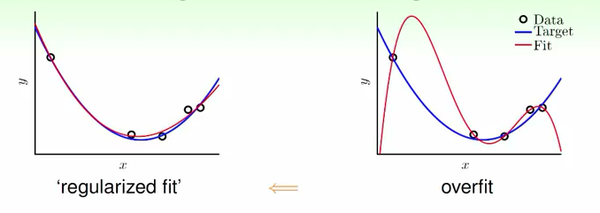

其实只要让后面的w系数全等于零,那么二次多项式和十次多项式本质上是一样的,这样子就客观上把假设空间缩小了,这里就是正则化的过程。
2. 正则化作用二 - 降低权值参数数值
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。
因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。
可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,一种流行的说法是『抗扰动能力强』。
Relevant Link:
https://www.jianshu.com/p/1aafbdf9faa6
https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap3/c3s5ss2.html
https://www.zhihu.com/question/32246256
https://www.zhihu.com/question/20700829
3. 从模型搜索空间限制角度看线性模型中的正则化(Regularization)
0x1:正则化简介
在机器学习中,不管是常规的线性模式,还是像深度学习这样的复合线性模型,几乎都可以看到损失函数后面会添加一个额外项。
常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。
所谓『惩罚』是指对损失函数中的某些参数做一些限制。具体是什么限制,我们接下来会详细讨论。
对于线性回归模型,使用L1正则化的模型叫做Lasso回归;使用L2正则化的模型叫做Ridge回归(岭回归)。
0x2:Lasso回归 - 包含L1正则化的线性回归
线性回归模型中,Lasso回归的损失函数如下:
 ,后面一项 α||w||1 即为L1正则化项。||w||1 是指权值向量 w 中各个元素的绝对值之和。
,后面一项 α||w||1 即为L1正则化项。||w||1 是指权值向量 w 中各个元素的绝对值之和。
一般都会在正则化项之前添加一个系数,Python中用 α 表示,一些文章也用 λ 表示。这个系数需要用户指定。
1. L1正则化的作用
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0。
我们知道,通常机器学习中特征数量很多(人工提取地或者因为自动编码产生的),例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。
在预测或分类时,但是如果代入所有这些特征,可能会最终得到一个非常复杂的模型,而绝大部分特征权重是没有贡献的,即该模型更容易产生过拟合(回想前面过拟合原因的分析)。
加入L1正则化后,得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,因此提高了模型的泛化能力。
2. 以二维损失函数几何角度解释 L1正则化是如何影响模型权重分配的
在项目中我们的特征肯定都是超高维的,不利于解释原理本质,我们以可视化的二维函数作为讨论对象,解释 L1正则化的原理。
假设有如下带L1正则化的损失函数:
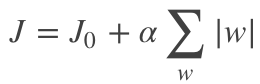
其中 J0 是原始的损失函数,加号后面的一项是L1正则化项,α 是正则化系数。
注意到 L1 正则化是权值的绝对值之和,J 是带有绝对值符号的函数,因此 J 是不完全可微的。机器学习的任务就是要通过最优化方法(例如梯度下降)求出损失函数的最小值。
当我们在原始损失函数 J0 后添加 L1 正则化项时,相当于对 J0 做了一个约束。
令 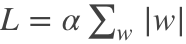 ,则 J = J0 + L,此时我们的任务变成在 L 约束下求出 J0 取最小值的解。
,则 J = J0 + L,此时我们的任务变成在 L 约束下求出 J0 取最小值的解。
在二维的情况,即只有两个权值 w1 和 w2,此时 L = a * ( ||w1| + |w2| )。L 函数在二维坐标系上是一个菱形,读者朋友可以自己推导下。
对于梯度下降法,求解 J0 的过程可以画出等值线,同时 L1 正则化的函数 L 也可以在 w1,w2 的二维平面上画出来。如下图:

图中等值线是 J0 的等值线,黑色方形是某个指定惩罚系数α(例如1)时,L 函数的图形。
在图中,当 J0 等值线与 L 图形首次相交的地方就是最优解。
上图中 J0 与 L在 L 的一个顶点处相交,这个顶点就是最优解。注意到这个顶点中,w1 = 0,w2 = w。
在惩罚系数 α 不同时,这个菱形会不断扩大和缩小,可以直观想象,因为 L 函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0 与这些角接触的机率会远大于与 L 其它部位接触的机率( 随着α缩小,L 的尖角总是最先碰到 J0 ),而在这些角上,会有很多权值等于0,这就是为什么 L1正则化可以产生稀疏模型,进而可以用于特征选择。
另一方面,而正则化前面的系数 α,可以控制 L 图形的大小。
α 越小,L 的图形越大(上图中的黑色方框);
α 越大,L 的图形就越小,可以小到黑色方框只超出原点范围一点点;
通过扩大 α 的大小,使得 w 可以取到很小的值。
综上可以看到,L1正则化能够做到两件事:
. 使得权重向量 w 尽量稀疏,即被选中的特征尽量少。且 ;
. 即使被选中,也有能力尽量使得 w 尽量小;
3. L1正则化的惩罚因子参数怎么选择
α越大,越容易使得权值向量 w 取得稀疏情况,同时 权值向量 w 值也越小。
0x3:Ridge回归 - 包含L2正则化的线性回归
线性回归模型中,Ridge回归的损失函数如下:
 ,式中加号后面一项 α||w||2 即为L2正则化项。||w||2 是指权值向量 w 中各个元素的平方和然后再求平方根。
,式中加号后面一项 α||w||2 即为L2正则化项。||w||2 是指权值向量 w 中各个元素的平方和然后再求平方根。
一般都会在正则化项之前添加一个系数,Python中用 α 表示,一些文章也用 λ 表示。这个系数需要用户指定。
1. L2正则化的作用
L2正则化可以防止模型过拟合(overfitting)。但是这不是L2正则化的专利,L1正则化也能一定程度上防止模型过拟合。
2. 以二维损失函数可视化解释 L2正则化是如何使模型权重分配趋向于小值
假设有如下带L2正则化的损失函数:
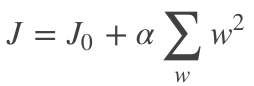
分析的过程和L1正则化是一样的,我们省略,同样可以画出他们在二维平面上的图形,如下:

二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此 J0 与 L 相交时使得 w1 或 w2 等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
但是L2正则化对 w1 和 w2 的整体压制效果还是一样的,我们从数学公式上分析下,L2正则化对权值参数压制的原理。
以线性回归中的梯度下降法为例。假设要求的参数为 θ,hθ(x) 是我们的假设函数,那么线性回归的代价函数如下:

那么在梯度下降法中,最终用于迭代计算参数 θ 的迭代式为(省略求导过程的推导): 
其中 α 是learning rate。在原始代价函数之后添加L2正则化,则迭代公式会变成下面的样子:

其中 λ 就是正则化参数。从上式可以看到:
与未添加L2正则化的迭代公式相比,每一次迭代,θj 都要先乘以一个小于 的因子,从而使得 θj 不断减小,因此总得来看,θ是不断减小的;
而且 λ 越大,每次减少的程度也越大;
和 L1正则化相比,而且因为均方根的放大作用,L2对 w 的限制力要更强,因此 L2正则化更适合压制权值w,使其尽量取小值。
3. L2正则化的惩罚因子参数怎么选择
λ越大,L2惩罚力度就越大,参数被小值化压制的程度也越大。
0x4:L1、L2正则化各自适合的场景
. ridge regression(L2) 并不具有产生稀疏解的能力,也就是说参数并不会真出现很多零。假设我们的预测结果与两个特征相关,L2正则倾向于综合两者的影响,给影响大的特征赋予高的权重;
. 而 L1 正则倾向于选择影响较大的参数,而舍弃掉影响较小的那个;
实际应用中 L2正则表现往往会优于 L1正则,但 L1正则会大大降低我们的计算量
0x5:不同惩罚参数下,正则化效果可视化
为了更好的直观体会L1和L2正则化对权重的制约过程,我们在mnist上训练一个经典的CNN分类器,提取出所有的权重,求出其分布来看看。所有权重初始化为均值0,方差0.5的正态分布。
# -*- coding: utf- -*- from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Flatten, Input
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
from keras import initializers
import numpy as np
import matplotlib.pyplot as plt
from keras import regularizers (x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape[], , , )
x_test = x_test.reshape(x_test.shape[], , , )
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255.0
x_test /= 255.0
y_train = keras.utils.to_categorical(y_train, )
y_test = keras.utils.to_categorical(y_test, ) def my_reg(weight_matrix):
#return # 无正则化
return 1.0 * K.sum(K.abs(weight_matrix)) # L1正则化
#return 2.0 * K.sum(K.abs(weight_matrix)) # L1正则化
#return 1.0 * K.sum(K.pow(K.abs(weight_matrix), )) # L2正则化
#return 2.0 * K.sum(K.pow(K.abs(weight_matrix), )) # L2正则化
#return 1.0 * K.sum(K.abs(weight_matrix)) + 1.0 * K.sum(K.pow(K.abs(weight_matrix), )) # L1-L2混合正则化
#return K.sum(K.pow(K.abs(weight_matrix), )) # L3正则化 # 所有权重初始化为均值0,方差0.5的正态分布
init = initializers.random_normal(mean=, stddev=0.25, seed=) input = Input(shape=(, , ))
conv1 = Conv2D(, kernel_size=(, ), activation='relu', kernel_initializer=init, kernel_regularizer=my_reg)(input)
conv2 = Conv2D(, (, ), activation='relu', kernel_initializer=init, kernel_regularizer=my_reg)(conv1)
pool1 = MaxPooling2D(pool_size=(, ))(conv2)
conv3 = Conv2D(, (, ), activation='relu', kernel_initializer=init, kernel_regularizer=my_reg)(pool1)
pool2 = MaxPooling2D(pool_size=(, ))(conv3)
flat = Flatten()(pool2)
dense1 = Dense(, activation='relu', kernel_initializer=init, kernel_regularizer=my_reg)(flat)
output = Dense(, activation='softmax', kernel_initializer=init, kernel_regularizer=my_reg)(dense1)
model = Model(inputs=input, outputs=output)
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy'])
model.summary() for i in range():
model.fit(x_train, y_train, batch_size=, epochs=, verbose=, validation_data=(x_test, y_test)) # 每次只训练一轮
score = model.evaluate(x_test, y_test, verbose=)
weights = model.get_weights()
all_weights = np.zeros([, ])
for w in weights:
w_flatten = np.reshape(w, [-])
all_weights = np.concatenate([all_weights, w_flatten], axis=)
plt.hist(all_weights, bins=, color="b", normed=True, range=[-, ])
print("epoch=" + str(i) + " loss=%.2f ,acc=%.3f" % (score[], score[]))
plt.title("epoch=" + str(i) + " loss=%.2f ,acc=%.3f" % (score[], score[]))
plt.savefig("mnist_model_weights_hist_%d.png" % (i))
plt.clf()
读者在运行的时候可以逐项把my_reg里的注释去除,逐个体验不同的正则化惩罚因子,对权重参数的制约作用。代码运行可能较慢,读者们不要着急。
笔者在学习这部分的时候,可视化带来了很多的有趣的思考,相信你也可以体会到数学公式的微小改变,给optimization带来的巨大变化;以及机器学习项目中,提取出来的特征是如何被模型选择,我们如何去干预这个特征选择过程等等。
代码运行完毕后会在本地目录产生很多.png图片,读者朋友可以用这个来生成gif动图,非常直观。
1. 无正则化

2. L1正则化 - 惩罚因子 = 1e-4

很明显,L1惩罚因子让 w 朝着系数矩阵的方向优化。
3. L1正则化 - 惩罚因子 = 1e-3
可以看到,在这个实验中,1e-3 对权值的压制作用就已经非常明显了。在第一轮训练后,权值向量的分布就大幅度集中在均值附近,即很多 w 被置为0。

笔者思考:在这个项目中,因为权值向量的维数不高,所以 L1惩罚因子的影响非常显著,在具体的项目中,你的特征feature可能高达上万或者上百万。相应的,L1惩罚因子可以选择稍微大一些,提高制约能力。
4. L2正则化 - 惩罚因子 = 1e-4

5. L2正则化 - 惩罚因子 = 1e-3

可以看到,惩罚因子越大,制约能力越强。
6. L1-L2混合正则化

7. L3正则化

0x5:从不同正则化参数效果图中我们可以得到什么信息
. L1/L2正则化都可以将权重往0的方向压制,但是L1的压制效果更强,L2比较慢一些,相同惩罚参数的情况下,L2要比L1花更久的时间达到相同的压制效果。
. 在保证准确率的前提下,L1/L2正则化能够省下更多的元素,这就意味着模型能够大大地减少其存储空间(将矩阵变成稀疏矩阵的形式保存)
. 从L1/L2的函数图像来看:
) 元素绝对值在[,]之间的时候,L1对于元素的惩罚更大,L2的惩罚小,相对的容忍度更大;
) 元素绝对值在[,∞]之间的时候,L1对于元素的惩罚更小,L2的惩罚大,相对的容忍度更小
. 从斜率角度来看:
) L2正则化的斜率大要在[,∞]才能发挥其功力,在[,]之间,往0赶的能力不是很强;
) 然而L1在所有地方斜率都一样,相对而言,在[,]之间,其往0赶的能力强
笔者思考:
这些理论理解了对我们更好的使用机器学习进行项目开发非常有用,在实际的项目中,笔者的经验是综合使用L1/L2,基本上在各种垂直领域场景下,这都是最好的实践结果。
笔者思考:
某种意义上来说,dropout正则化技术和亚里士多德的《政治学》观点是一致的。
正则化通过随机的切断神经元之间的连接,从而强迫网络中的所有神经元都”共同参与最终决策“以提高泛化能力。
但是如果我们将正则化后的权重分配打印出来会发现,正则化的结果就是”权重集中在了少数几个神经元上“。换句话说就是:”最终的决策由少数人来作出是最优的,也是集体的自然选择“。
这正体现了政治学中的国家力量,国家的作用就是将广大人民的自由权利,集中到少数精英手中进行集中决策。从这点看,自由与民主是不冲突的。
Relevant Link:
https://vimsky.com/article/969.html
https://blog.csdn.net/jinping_shi/article/details/52433975
https://blog.csdn.net/yuweiming70/article/details/81513742
https://blog.csdn.net/zouxy09/article/details/24971995
https://blog.csdn.net/yuweiming70/article/details/81513742
4. 从贝叶斯估计的角度看线性模型中的正则化
首先,先抛出笔者的一个观点:从贝叶斯的角度来看,正则化等价于对模型参数引入先验分布。
其中正则化项对应后验估计中的先验信息;
损失函数对应后验估计中的似然函数;
0x1:不包含正则化的原始线性回归
我们先看下最原始的Linear Regression:

从概率分布的角度来看,线性回归对应的概率分布为:

1. 由最大似然估计(MLE) - 针对不包含正则项的概率分布进行极大似然估计

取对数:

即:
这就导出了我们原始的 least-squares 损失函数(损失函数极小),但这是在我们对参数 w 没有加入任何先验分布的情况下。在数据维度很高的情况下,我们的模型参数很多,模型复杂度高,容易发生过拟合。
这个时候,我们可以对参数 w 引入先验分布,降低模型复杂度。
0x2:引入高斯分布先验的线性回归 - Ridge Regression
继续上面的线性回归函数,我们对参数 w 引入协方差为 的零均值高斯先验。

取对数:

等价于:。绝对值后面的下标2表示L2范数的意思。
这等价于 Ridge Regression(L2正则化)
即:对参数引入 高斯先验 等价于L2正则化。
0x3:引入拉普拉斯分布(Laplace distribution)先验的线性回归 - LASSO Regression
继续上面的线性回归函数,我们对参数 w 引入拉普拉斯分布(Laplace distribution)。
LASSO - least absolute shrinkage and selection operator.

拉普拉斯分布公式如下:


使用相同的推导过程我们可以得到:
 。绝对值后面的下标1表示L1范数的意思。
。绝对值后面的下标1表示L1范数的意思。
0x4:引入L1-L2先验的线性回归 - Elastic Net

最终的凸优化函数如下:
 。绝对值后面的下标1和下标2表示L1/L2范数的意思。
。绝对值后面的下标1和下标2表示L1/L2范数的意思。
下图展示L1、L2、Elastic Net添加的正则项在二维情况时的约束函数。可以看到,Elastic Net是L1和L2的一种折中方案。

笔者插入思考:
笔者在思考Elastic Net和L1/L2的关系的时候,突然想到之前学习过的CART树算法中的评价指标(基尼指数、熵之半、分类误差率)时,它们有异曲同工之妙,仅仅是通过数学公式的一些微小改变可以带来非常明显的效果提升。
https://www.cnblogs.com/LittleHann/p/7309511.html#_label3_4_0_2
搜索:. 基于基尼指数来评估分类特征的效果
Relevant Link:
https://www.zhihu.com/question/23536142/answer/90135994
https://www.jianshu.com/p/c9bb6f89cfcc
https://blog.csdn.net/zhuxiaodong030/article/details/54408786
http://charleshm.github.io/2016/03/Regularized-Regression/#fn:5
https://ask.julyedu.com/question/150
5. 从经验风险/结构风险的角度看线性模型中的正则化
笔者认为,经验风险/结构化风险更多地是一种指导理论,在实际的算法中,更多的是以L1/L2惩罚、引入先验分布、结构dropout、提前剪枝等操作来实现该目的。
https://www.cnblogs.com/LittleHann/p/7749661.html#_label3_0_2_0
搜索:0x3:正则化与交叉验证 - 缓解过拟合的发生
李航《统计学习方法》中指出:结构风险最小化等价于正则化。
笔者思考:实际上,笔者认为,结构风险最小化等于 正则化、CART/ID3树剪枝、深度神经网络Dropout、CNN卷积网络Maxpool、引入先验分布的贝叶斯估计,等等。它们都体现了结构化最小化的思想。
但同时,笔者也希望提醒读者:结构化风险最小是一个非常“实用”的策略,它在很多情况下确实能发挥很好的效果。但是不一定100%所有的场景都需要简单模型,有时候我们恰恰就需要训练一个复杂模型,当我们遇到欠拟合问题的时候,就要慎重使用结构化最小化策略了。
Relevant Link:
https://blog.csdn.net/zhihua_oba/article/details/78728880
6. 非线性模型中的正则化
0x1:决策树中的正则化
关于决策树的剪枝相关的讨论,读者可以参阅relevant link中的文章,这里就不赘述了。
Relevant Link:
https://www.cnblogs.com/LittleHann/p/7309511.html
7. 从概念描述空间看泛化问题
0x1:什么是概念描述空间
概念描述空间(concept description splace)是机器学习模型学习的结果,由一组规则表示。例如下列一组有关天气问题的规则:

带有数值属性的天气数据
假设机器学习数据中提取出的规则如下:

注意,对于一组数据集来说,其中包含的规则集往往不只一个,所有的规则集共同组成了代表特定问题域的概念描述空间。
- 记忆性规则集:最极端的情况下,对每个样本生成一个对应的规则,这样模型仅仅只是存储和记忆了原始数据集。
- 概括泛化型规则集:最完美的情况下,从所有样本中提取出一个唯一的规则集。这个规则集可以完美概括训练数据集,同时在测试集和未来的未知数据上也能有很好的表现。
0x2:训练学习的本质 - 枚举概念空间
机器学习模型训练的最核心目标就是得到一个泛化性能优良的模型。而泛化的过程可以认为是在一个庞大的,但有限的搜索空间中进行搜索。
1. 理想情况下的泛化训练过程
原则上,可以枚举所有的描述,从中删除一些不符合样本的描述来解决问题:
- 一个肯定的样本会去除所有不匹配的描述;
- 而一个否定的样本则会去除所有匹配的描述;
每个样本都会导致剩余的描述集缩小(或保持不变),如果训练到最后只剩下一个描述,那么它就是目标描述(目标概念)。
2. 真实情况下的训练过程
在实际情况中,整个处理过程只涵盖唯一一个可接受的描述是很少见的,所以会产生两种情况:
- 样本在处理后,仍然存在大量的描述,模型不确定熵依然很高
- 或者所有的描述都被去除
出现第一种情况的原因是没有充分理解样本,所以除”正确的描述“之外,其余的描述没有被去除。
出现第二种情况的原因是因为描述语言表达不充分,不能把握住真正的概念,也即是模型逼近误差(欠拟合)。或者是因为样本中有噪声。
但是需要注意的是,如果剩下多个描述,仍然可以用来对未知的事物进行分类:
- 如果未知的事物与所有剩余的描述集相匹配,就应该将其分到所匹配的目标
- 如果未知的事物不能和其中任何一个相匹配,就把它分到目标概念以外
- 如果未知的事物仅和其中一部分相匹配,就会出现模糊,也就是我们常说的误报和漏报的零和博弈。
0x3:从搜索角度看偏差
把泛化看成是一个在所有可能的概念空间的搜索,就可以清楚地指出在机器学习系统里最重要的3大决策因素:
- 概念描述语言:例如CART4结构或线性回归方程结构
- 在空间中搜索的次序:启发式还是梯度导向式
- 对于特定训练数据避免过度拟合的方法
当讨论搜索的偏差时,通常提到3个属性:
- 语言偏差(language bias)
- 搜索偏差(search bias)
- 避免过度拟合偏差(overfitting-avoidance bias)
在选择一种表达概念的语言时、在为一个可以接受的描述搜索一个特殊途径时、在需要对一个复杂的概念进行简化时,都会使学习方案产生偏差。
1. 语言偏差
对于语言偏差来说,最重要的问题是概念描述语言是否具有普遍性,或者它是否在能够被学到的概念上加约束条件。
如果考虑一个包含所有可能性的样本集,那么概念就是将这个集合划分为多个子集的分界线。
如果概念描述语言允许包括逻辑或(析取),那么任何一个子集都能表示。如果描述语言是基于规则的,那使用分开的规则就能够达到分离的目的。
2. 搜索偏差
在实际的数据挖掘问题中,存在一些可选的概念描述,它们都与数据相匹配,我们往往需要根据某些标准(通常是最简单的标准)找出”最好的“一个概念描述。
我们使用统计学的术语拟合(fit),意味着寻找一个与数据合理拟合的最好的描述。但是,在整个空间进行搜索通常是计算不可行的,所以搜索过程是启发式的,并且不能100%保证最终结构是最优的。
这为产生偏差创造了空间,不同的搜索启发方式以不同的方式在搜索过程中产生偏差。例如:
- 采用”贪心(greedy)“搜索策略的搜索:在每一阶段找出最好的规则,然后将其加入规则集。但是问题是,1+1不一定>=2,最好的一对规则并不是单独两个最好规则的简单叠加。
- 构造决策树:最先作出的基于一个特定属性的分割。但是问题是,在后续节点构建时会发现,父节点的选择并不是一个好的决定
- ......
3. 避免过度拟合偏差
过度拟合是一种常见的学习现象,通常解决这个问题的办法是从一个最简单的概念描述出发,逐渐将它复杂化。这是一种避免过度拟合的好方法,有时候称之为正向剪枝(forward pruning)或先剪枝(prepruning)。
与此相对的,另一种方法称之为反向剪枝(backward pruning)或后剪枝(post-pruning)。
直观上看,”偏差“是一个贬义词,”避免过度拟合偏差“表面上看给模型带来了不安定的偏差因素,但反过来,也正是因为这种偏差,给模型带来了更好的泛化能力。我们需要对立客观地看待这两个概念。
8. 缓解过拟合的另一种思路 - 集成学习
我们已经讨论了很多关于正则化技术的原理及应用方面的技术,现在我们将目光转向另一种非常有用的技术,集成学习。
集成学习,通过将训练数据分成多个不同的训练集,在每一个训练数据集上学习一种模型,然后将各个模型组合产生一个学习模型集群,这样的方法通常会获得更好的性能。
按照哲学家伊壁鸠鲁(Epicurus)的观点,明智的人在作出某个关键决策时,通常要考虑多个专家的意见而不是只依赖于自己的判断或依赖于某个唯一被信任的顾问。在民主的条件下,对不同的观点进行讨论也许可以达成一致意见,如果不能还可以进行投票,不管采用哪种方法,不同专家的意见被组合在一起。
在机器学习中,是通过一种称为集成学习的方法来实现该目的的,其中主要的方法有:
- 装袋(bagging)
- 提升(boosting)
- 堆栈(stacking)
在大多数情形下,与单个模型相比较,它们都能使预测性能有所提高,并且是可用于数值预测和分类预测的通用技术。
0x1:装袋(bagging)
组合不同模型的决策意味着由不同的输出结果合并产生一个预测结果。对于分类问题,最简单的方法就是进行投票,对于数值预测问题,就是计算平均值。
回到“偏差-方差分解(bias-variance decomposition)”理论上来看,一个分类器的总期望误差是由偏差和方差这两部分之和构成的,而bagging这种集成学习方法能够通过减少方差分量来降低期望误差值,包含的分类器越多,方差减少量就越大。
从泛化稳定性的角度来看,当学习方法不稳定时,即输入数据的微小变化能导致生成差别相当大的分类器。正则化技术是通过调整输入权重分配和校准输出的思路来缓解该问题的。而集成学习提供了另一种解决问题的思路,
实际上,尽可能地使学习方法不稳定,增加集成分类器中的多样性,有助于提高分类器性能。
例如:
- 当对决策树使用装袋技术时,决策树已经是不稳定的,如果不对树进行剪枝,经常可以获得更好的性能,而这会使决策树变得不稳定
- 旋转森林(rotation foreast)的集成学习方法结合了随机子空间和装袋方法,利用主成分特征构建决策树集群。在每一次迭代中,输入属性被随机分类k个不相连的子集,在每个子集中使用主成分分析,以便产生子集中属性的线性组合,即对原始轴的旋转。
0x2:提升(boosting)
装袋法充分利用了学习算法内在的不稳定性,从直觉上看,只有当各个模型之间存在明显差异,并且每种模型都能正确处理一定合理比例的数据时,组合多种模型才能发挥作用。理想情况是这些模型对于其他模型来说是一个补充,每个模型是这个领域中某一部分的专家,而其他模型在这部分的表现却不是很好,就像决策者总是要寻觅那些技能和经验互补的顾问,而不是技能和经验互相重复的顾问。
提升方法利用明确地搜寻与另一个模型互补的模型这个思想来组合多种模型。
- 首先,相似点是与装袋法一样,提升利用你投票(用于分类)或者取平均值(用于数值预测)来组合各个模型的输出。
- 另外,也与装袋一样,它组合同一类型的模型,例如决策树。然而,提升是迭代的,在装袋中各个模型是单独建立的,而提升的每个新模型是受先前已建立模型的性能影响的。提升法鼓励新模型成为处理先前模型所不能正确分类的实例的专家。
- 最后一个不同点是,提升根据模型的性能来对每个模型的贡献加权,而不是赋予每个模型相同的权值
最经典的提升算法是adaboost算法,关于其细节的讨论可以参阅另一篇文章,这里不再赘述。
提升技术的想法起源于机器学习研究的计算学习理论(computational learning theory)这一分支。可以看到,随着迭代次数的增加,在训练数据上的组合分类器误差很快地向0靠拢。
但是令人惊讶的是,当在训练数据上的组合分类器误差降到0后,持续进行更多次的提升迭代仍然能够在新数据上减小误差。表面上看,这似乎与正则化所代表的奥科姆剃刀原则相悖,奥卡姆剃刀原理宣称在两个能同样好地解释试验数据的假设中,简单的那个优先。
进行更多次的提升迭代而不减少训练误差,这并没有对训练数据做出任何更好的解释,但肯定增加了分类器的复杂度。
考虑分类器在所做预测上的置信度可以解决这一矛盾,更具体地说,这个置信度是根据真实类的估计概率和除了真实类以外最有可能的预测类的估计概率之间的差别,称为边际(margin)的量来度量的。
这个边际越大,分类器能预测出真实类的置信度就越大。提升法在训练误差降到0之后能继续增大边际,所以考虑边际来解释试验数据没有发生过拟合现象,奥卡姆剃刀原理还是同样能够被满足。
机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探的更多相关文章
- lecture9-提高模型泛化能力的方法
HInton第9课,这节课没有放论文进去.....如有不对之处还望指正.话说hinton的课果然信息量够大.推荐认真看PRML<Pattern Recognition and Machine L ...
- 机器学习:模型泛化(L1、L2 和弹性网络)
一.岭回归和 LASSO 回归的推导过程 1)岭回归和LASSO回归都是解决模型训练过程中的过拟合问题 具体操作:在原始的损失函数后添加正则项,来尽量的减小模型学习到的 θ 的大小,使得模型的泛化能力 ...
- python 机器学习中模型评估和调参
在做数据处理时,需要用到不同的手法,如特征标准化,主成分分析,等等会重复用到某些参数,sklearn中提供了管道,可以一次性的解决该问题 先展示先通常的做法 import pandas as pd f ...
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
原文:http://blog.csdn.net/abcjennifer/article/details/7716281 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 机器学习:模型泛化(LASSO 回归)
一.基础理解 LASSO 回归(Least Absolute Shrinkage and Selection Operator Regression)是模型正则化的一定方式: 功能:与岭回归一样,解决 ...
- 机器学习:模型泛化(岭回归:Ridge Regression)
一.基础理解 模型正则化(Regularization) # 有多种操作方差,岭回归只是其中一种方式: 功能:通过限制超参数大小,解决过拟合或者模型含有的巨大的方差误差的问题: 影响拟合曲线的两个因子 ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数(转)
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数 非常好,必看
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
随机推荐
- thymeleaf th:href url传递多参数
<a th:href="@{/teacherShowMember(class_id=${class.classId},class_name=${class.className})}&q ...
- Android项目实战(五十二):控制EditText输入内容大小写转换
今日需求,EditText内容为一串字符串,要求将用户软键盘输入的小写字母在输入的时候自动转为大写字母,反之亦然. 效果如下: 第一次做该需求,原先想法: EditText.addTextChange ...
- Android View的重绘ViewRootImpl的setView方法
博客首页:http://www.cnblogs.com/kezhuang/p/ 本篇文章来分析一下WindowManager的后续工作,也就是ViewRootImpl的setView函数的工作 /i* ...
- maven+springMVC(一)
[目录]
- Microsoft SQL Server 2016 RC3 安装
首先下载SQL Server 2016 RC3 安装iso 下载链接 ed2k://|file|cn_sql_server_2016_rc_3_x64_dvd_8566578.iso|24648232 ...
- socket字符流循环截取
场景:socket 客户端将一个单向链表序列化后发送给服务端,服务端将之解析,重新构建单向链表. Client.cpp //遍历链表,填充到缓冲区 ]) { ListNode* tmp = p; // ...
- linux添加crontab定时任务
1.crontab -e命令进入linux定时任务编辑界面,举个简单的例子,比如我要定时往txt文件写入 */ * * * * .txt */1就是每隔一分钟像文件写入,其他一些详细的操作大家可以去网 ...
- Postman学习之【压力测试】
Postman请自行下载 下面是在网上随便抓了一个请求地址来做演示,把请求地址填入地址栏,此请求为GET请求.点击Send发送请求,请求结果将会在下方显示出来.每次的请求历史数据,会被记录下来,但是经 ...
- 【RL-TCPnet网络教程】第2章 嵌入式网络协议栈基础知识
第2章 嵌入式网络协议栈基础知识 本章教程为大家介绍嵌入式网络协议栈基础知识,本章先让大家有一个全面的认识,后面章节中会为大家逐一讲解用到的协议. 基础知识整理自百度百科,wiki百科等 ...
- codeforces#1136E. Nastya Hasn't Written a Legend(二分+线段树)
题目链接: http://codeforces.com/contest/1136/problem/E 题意: 初始有a数组和k数组 有两种操作,一,求l到r的区间和,二,$a_i\pm x$ 并且会有 ...