python从爬虫基础到爬取网络小说实例
一.爬虫基础
1.1 requests类
1.1.1 request的7个方法
requests.request() 实例化一个对象,拥有以下方法
requests.get(url, *args)
requests.head() 头信息
requests.post()
requests.put()
requests.patch() 修改一部分内容
requests.delete()
url = "http://quanben5.com/n/doupocangqiong/6.html"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
r = requests.get(url, headers=headers)
data = {
"pinyin": "doupocangqiong",
"content_id": "",
}
r = requests.post(url, data=data, headers=headers)
1.1.2*arg里面的参数
params 字典或者字节序列,作为参数增加到url中
data 字典字节序列文件对象, 放在url里面对应的地方
json 作为requests的内容
headers 字典 模拟服务头
cookies 字典 cookieJar
auth 元组
files 字典类型,传输文件
timeout 设定的超时时间
proxies 字典类型,设定访问代理服务器,可以增加登录认证 pxs={"http":"http://user:pass@10.10.1.1234"}
allow_redirects 默认True 是否允许重定向
stream 默认TRUE 获得数据立刻下载
verity 默认True 认证SSL证书开关
cert 本地SSL证书路径
1.2 BeautifulSoup类
soup = BeautifulSoup("","html.parser")
soup.prettify()
soup.find_all(name, attrs, recursive, string, **kwargs)
name: 标签名称
attrs: 属性
string: 检索字符串
soup.head
soup.head.contents 列表
soup.body.contents[1]
soup.body.children
soup.body.descendants
.parent
.parents
.next_sibling 下一个
.previous_sibling 上一个
.next_siblings 下一个所有 迭代
.previous_siblings 上一个所有
1.3 selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu') d = webdriver.Chrome(chrome_options=chrome_options) # 设置成不显示浏览器的模式
d.get('http://quanben5.com/n/dazhuzai/23241.html')
time.sleep(2)
print(d.page_source) # 显示出的是加载完之后的内容
查找单个和多个元素
d.find_element_by_id
d.find_elements_by_id
元素交互
from selenium import webdriver d = webdriver.Chrome()
d.get('http://www.baidu.com')
inputText = d.find_element_by_id("kw")
inputText.send_keys("萝莉")
button = d.find_element_by_id("su")
button.click()
二.实战
首先要找到可以在线看小说的网页
这里我随便百度了一下,首先选择了一个全本5200小说网("https://www.qb5200.tw")
打开某小说章节目录表
https://www.qb5200.tw/xiaoshuo/0/357/
查看源代码

发现正文卷是在class为listmain的div下面的第二个dt标签里
之后的路径标签为a
url_text = soup.find_all('div', 'listmain')[0] # 找到第一个class=listmain的div标签
main_text = url_text.find_all('dt')[1] # 找到下面的第二个dt标签
for tag in main_text.next_siblings:
try:
url = ''.join(['https://', host, tag.a.attrs['href']])
print('parsering', url)
except:
continue
找到每个章节的url
在随便打开一章
查看源代码为:

def getHTMLText(url, headers={}):
"""
获取网站源码
:param url:
:return: class response
"""
if headers != {}:
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"}
# proxies = get_random_ip()
proxies = {}
try:
# print("start", url)
r = requests.get(url, proxies=proxies, headers=headers)
r.raise_for_status()
# r.encoding = r.apparent_encoding
# print('end', url)
return r
except:
return r.status_code
def parseByQB5200(soup, host, f):
"""
在全本小说网的源码下爬取小说
:param soup, host:
:param f:
:return:
"""
url_text = soup.find_all('div', 'listmain')[0]
main_text = url_text.find_all('dt')[1]
x = 0
for tag in main_text.next_siblings:
time.sleep(1)
try:
url = ''.join(['https://', host, tag.a.attrs['href']])
print('parsering', url)
soup = BeautifulSoup(getHTMLText(url).text, "html.parser")
passage = soup.find_all("div", "content")[0]
title = passage.h1.string
f.writelines(''.join([title, '\n']))
passage = soup.find_all("div", "showtxt")[0]
for i in passage.descendants:
if i.name != "br":
st = i.string
if st.strip().startswith('http') or st.strip().startswith('请记住本书'):
continue
f.writelines(''.join([' ', st.strip(), '\n']))
x += 1
print('%d.%s 下载完成' % (x, title))
except:
continue
def getNovelUrls(url):
"""
通过小说的目录网址判断小说所在的网站
并调用属于该网站的爬虫语句
:param url:
:return:
"""
response = getHTMLText(url)
host = url.split('//')[1].split('/')[0]
host_list = {
"www.qb5200.tw": parseByQB5200,
# "www.qu.la": parseByQuLa,
"quanben5.com": parseByQB5
}
print(response)
soup = BeautifulSoup(response.text, 'html.parser')
with open('1.txt', 'w', encoding='utf8') as f:
host_list[host](soup, host, f)
if __name__ == '__main__':
getNovelUrls("https://www.qb5200.tw/xiaoshuo/0/357/")
在全本5200爬取小说txt
问题在于
全本小说网("www.qb5200.tw")在这样的暴力获取下只允许爬3次,之后就403错误
本来以为是同一IP限制访问次数, 使用了IP代理之后发现问题依旧
猜测应该是跟请求头有关
因此加上了访问该网站时浏览器的所有请求头,并且把User-Agent设置为随机
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
headers = {"User-Agent": random.choice(USER_AGENT_LIST),
"Host": "www.qb5200.tw",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Upgrade-Insecure-Requests": "",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Referer": "https://www.qb5200.tw/xiaoshuo/0/355/",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "UM_distinctid=16736c47b1d8b-04bd85d2b5e8ab-50422618-144000-16736c47b1e1f2; bcolor=; font=; size=; fontcolor=; width=; CNZZDATA1260750615=1497982366-1542811927-%7C1542882690; fikker-7ZUK-qXIL=qDaKEBihatSNEFgtMlGVIKubCHYLi89J; fikker-7ZUK-qXIL=qDaKEBihatSNEFgtMlGVIKubCHYLi89J; fikker-Sbwr-GN9F=GbMX3HOhwvoDMxopLMGt3VWliXQIK0SP; fikker-Sbwr-GN9F=GbMX3HOhwvoDMxopLMGt3VWliXQIK0SP; fikker-yJ3O-W61D=UfinETMnCR38ADWZEl1KNHQRU2m81Fwb; fikker-yJ3O-W61D=UfinETMnCR38ADWZEl1KNHQRU2m81Fwb; fikker-rWK3-6KHs=T9T5b7lYVJReTQviPm2IdLPyHu83RwFM; fikker-rWK3-6KHs=T9T5b7lYVJReTQviPm2IdLPyHu83RwFM" }
随机请求头
解决问题.
三.使用ajax动态加载的实例:
全本5小说网("quanben5.com")
同样的方法搜索源代码


然而发现了问题
给出的html页面只有一半的源码
因此按F12打开检查
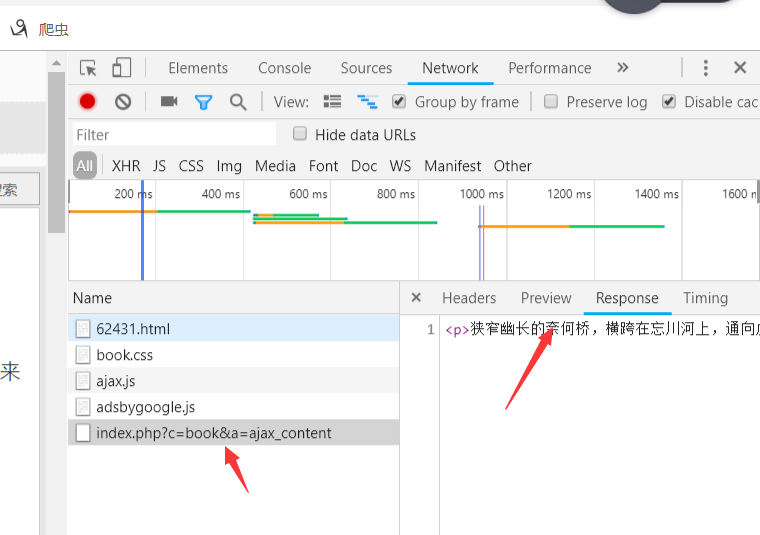
发现所有的文本存在这个xhr里
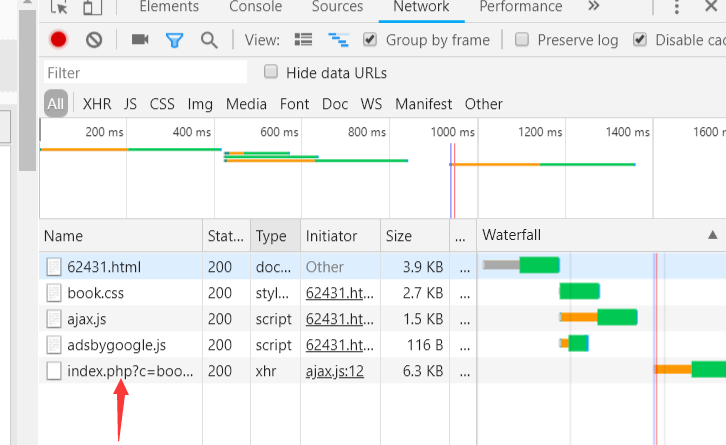
点击查看请求头信息
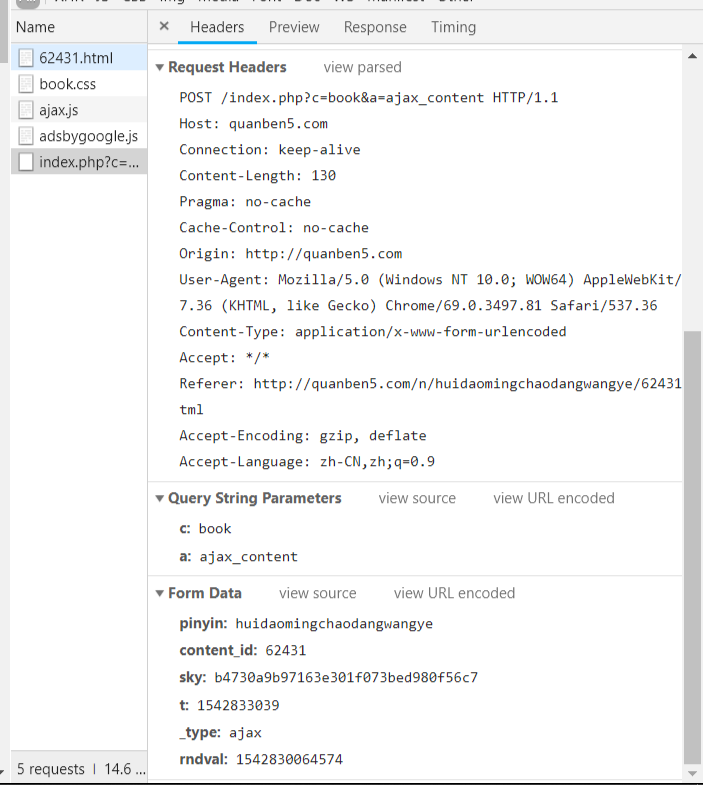
发现是post请求
请求的url是/index.php?c=book&a=ajax_content
请求的数据在最下面的form表单里
打开网页源文件和js文件,搜索这些表单信息
分别在ajax.js里和源文件里找到了这些

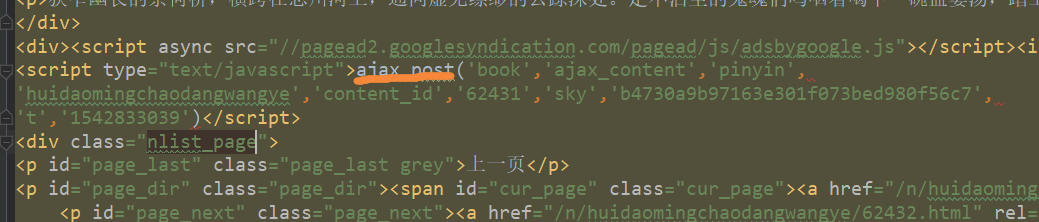
源文件里面的可以直接生成data数据表单
在ajax.js里可以知道rndval字段是当前时间,精确到毫秒
四.优化
采用了gvent进行异步IO处理,每一张网页保存在temp里面,最后将文件合成一个txt
加入了搜索功能,目前仅支持一个小说网站
代码如下:
#!/usr/bin/env python
# encoding: utf-8 """
@version:
@author: Wish Chen
@contact: 986859110@qq.com
@file: get_novels.py
@time: 2018/11/21 19:43 """
import gevent
from gevent import monkey
monkey.patch_all()
import requests, time, random, re, os
from bs4 import BeautifulSoup dir = os.path.dirname(os.path.abspath(__file__)) def getHTMLText(url, data=[], method='get'):
"""
获取网站的源代码
请求默认为get
:param url:
:param data:
:param method:
:return:
"""
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"}
proxies = {}
try:
# print("start", url)
r = requests.request(method, url, proxies=proxies, headers=headers, data=data)
r.raise_for_status()
# r.encoding = r.apparent_encoding
# print('end', url)
return r
except:
return r.status_code def fetch_async(x, url):
"""
异步IO所需要执行的操作
获取源文件
模拟向ajax请求获取完整文字
每一章输入到temp文件夹下
:param x:
:param url:
:return:
"""
url_main = "http://quanben5.com/index.php?c=book&a=ajax_content"
r = getHTMLText(url) # 获取每一章的源文件
title = re.search(r'<h1 class="title1">(.*)</h1>', r.text).group(1)
result = re.search(r'<script type="text/javascript">ajax_post\((.*)\)</script>', r.text).group(1)
num_list = result.split("','")
num_list[9] = num_list[9][:-1]
content = {} # 开始模拟post请求发送的表单
for i in range(1, 5):
content[num_list[i * 2]] = num_list[i * 2 + 1]
content['_type'] = "ajax"
content['rndval'] = int(time.time() * 1000)
r = getHTMLText(url_main, data=content, method='post') # 模拟post请求
soup = BeautifulSoup(r.text, "lxml")
with open(os.path.join(dir, 'temp', "%s.txt" % x), "w", encoding='utf8') as f:
f.writelines(''.join([str(x), '.', title, '\n\n']))
for tag in soup.body.children:
if tag.name == 'p':
f.writelines(''.join([' ', tag.string.strip(), '\n\n']))
print('%d.%s 下载完成' % (x, title)) def get_together(name, author, x):
"""
将temp目录下的各网页下载下来的txt
合并在一起
并删除temp文件
:param name:
:param author:
:return:
"""
with open(os.path.join(dir, "%s.txt" % name), "w", encoding='utf8') as f:
f.writelines(''.join([name, '\n\n作者:', author, '\n\n'])) for i in range(x):
try:
f.write(open(os.path.join(dir, 'temp', "%s.txt" % (i+1)), "r", encoding='utf8').read())
f.write('\n\n')
# os.remove(os.path.join(dir, 'temp', "%s.txt" % (i+1)))
except:
continue def parseByQB5(response, host):
"""
在全本5小说网的源码下爬取小说
获得书名和作者
采用gevent异步IO优化
:param response:
:param host:
:return:
"""
soup = BeautifulSoup(response.text, 'html.parser')
url_text = soup.find_all('div', 'box')[2]
main_text = url_text.find_all('h2')[0].next_sibling
url_list = []
for tag in main_text.descendants:
if tag.name == 'li':
url = ''.join(['http://', host, tag.a.attrs['href']])
url_list.append(url)
from gevent.pool import Pool
pool = Pool(100) gevent.joinall([pool.spawn(fetch_async, i+1, url=url_list[i]) for i in range(len(url_list))]) name = re.search(r"<h3><span>(.*)</span></h3>", response.text).group(1)
author = re.search(r'<span class="author">(.*)</span></p>', response.text).group(1)
print("%d文档已下载,正在合并..." % len(url_list))
get_together(name, author, len(url_list)) def getNovelUrls(url):
"""
通过小说的目录网址判断小说所在的网站
并调用属于该网站的爬虫语句
:param url:
:return:
""" response = getHTMLText(url)
host = url.split('//')[1].split('/')[0]
host_list = {
"quanben5.com": parseByQB5
}
host_list[host](response, host) def get_url():
input_name = input('>>')
r = getHTMLText("http://quanben5.com//index.php?c=book&a=search&keywords=%s" % input_name)
soup = BeautifulSoup(r.text, "html.parser")
main_book = soup.find_all("div", "pic_txt_list")
for i in range(len(main_book)):
tag = main_book[i].h3
print("%s.%s %s" %(i, tag.span.text, tag.next_sibling.next_sibling.text))
choice = int(input(">>"))
if choice in range(len(main_book)):
return ''.join(["http://quanben5.com", main_book[choice].h3.a["href"], "xiaoshuo.html"]) if __name__ == '__main__':
# url_list = [
# "https://www.qu.la/book/365/",
# "https://www.qb5200.tw/xiaoshuo/0/357/",
# "http://quanben5.com/n/doupocangqiong/xiaoshuo.html",
# "http://quanben5.com/n/dazhuzai/xiaoshuo.html",
# "http://quanben5.com/n/douluodalu/xiaoshuo.html",
# "http://quanben5.com/n/renxingderuodian/xiaoshuo.html"
# ]
# if not os.path.exists('temp'):
# os.mkdir('temp')
# getNovelUrls(url_list[5])
while True:
url = get_url()
time_start = time.time()
getNovelUrls(url)
print("成功爬取! 用时:%ds" % (int((time.time()-time_start)*100)/100))
异步IO+搜索
封装性还不够好
最好一个网站用一个类来封装
采用scrapy框架
正在设计中...
五.未解决问题:
代理IP问题:
目前只有免费的代理IP网
生成随机IP并使用代理IP访问
多网站定制
要观察各个网站的目录源代码结构以及文章源代码结构
每一个网站都可以用一个parse函数来解析其内容
python从爬虫基础到爬取网络小说实例的更多相关文章
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- python3爬虫-使用requests爬取起点小说
import requests from lxml import etree from urllib import parse import os, time def get_page_html(ur ...
- python爬虫基础应用----爬取校花网视频
一.爬虫简单介绍 爬虫是什么? 爬虫是首先使用模拟浏览器访问网站获取数据,然后通过解析过滤获得有价值的信息,最后保存到到自己库中的程序. 爬虫程序包括哪些模块? python中的爬虫程序主要包括,re ...
- Python爬虫基础--分布式爬取贝壳网房屋信息(Client)
1. client_code01 2. client_code02 3. 这个时候运行多个client就可以分布式进行数据爬取.
- python 爬取网络小说 清洗 并下载至txt文件
什么是爬虫 网络爬虫,也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人.其目的一般为编纂网络索引. 网络搜索引擎等站点通过爬虫软件更新自身的网站内容或其对其他网站的索引.网络爬虫可以 ...
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
- Python爬虫基础--分布式爬取贝壳网房屋信息(Server)
1. server_code01 2. server_code02 3. server_code03
随机推荐
- pd.read_csv() 、to_csv() 之 常用参数
本文简单介绍一下read_csv()和 to_csv()的参数,最常用的拿出来讲,较少用的请转到官方文档看. 一.pd.read_csv() 作用:将csv文件读入并转化为数据框形式. pd.read ...
- LOJ2396 JOISC2017 长途巴士 斜率优化
传送门 将乘客按照\(D_i\)从小到大排序并重新标号.对于服务站\(j\),如果\(S_j \mod T \in (D_i , D_{i+1})\),那么可以少接一些水,在保证司机有水喝的情况下让编 ...
- Docker镜像拉不下来?试试这些
DaoCloud 加速器1.0(永久免费) DaoCloud是国内第一家Dock Hub加速器提供商 注意,加速器 2.0 需要使用 DaoCloud 自己的云服务器才可以使用.官方宣称会继续支持加速 ...
- Mysql数据的增删改查
一 介绍 MySQL数据操作: DML 在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,包括 使用INSERT实现数据的插入 UPDATE实现数据的更新 使用DELETE实现 ...
- opentack-openstack组件及功能(1)
一. OpenStack各组件间的关系 图22.1 OpenStack各组件间的关系 1.基础管理服务包含Keystone,Glance,Nova,Neutron,Horizon五个服务 (1)Key ...
- JMeter二次开发(1)-eclipse环境配置及源码编译
1.下载src并解压 http://jmeter.apache.org/download_jmeter.cgi 2.获取所需jar包,编译 ant download_jars ant instal ...
- Flutter之SliverAppBar
new SliverAppBar( leading: GestureDetector( child: Icon(Icons.arrow_back), onTap: () => Navigator ...
- mysql 导入出csv
load data infile '/var/lib/mysql-files/ip_address.csv' into table ip_address fields terminated by ', ...
- FFMPEG系列课程(一)打开视频解码器
测试环境:windows10 开发工具:VS2013 从今天开始准备些FFmpeg的系列教程,今天是第一课我们研究下打开视频文件和视频解码器.演示环境在windows上,在Linux上代码也是一样. ...
- Tensorflow 大规模数据集训练方法
本文转自:Tensorflow]超大规模数据集解决方案:通过线程来预取 原文地址:https://blog.csdn.net/mao_xiao_feng/article/details/7399178 ...