Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
排名函数是Sql Server2005新增的功能,下面简单介绍一下他们各自的用法和区别。我们新建一张Order表并添加一些初始数据方便我们查看效果。
CREATE TABLE [dbo].[Order](
[ID] [int] IDENTITY(,) NOT NULL,
[UserId] [int] NOT NULL,
[TotalPrice] [int] NOT NULL,
[SubTime] [datetime] NOT NULL,
CONSTRAINT [PK_Order] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] GO
SET IDENTITY_INSERT [dbo].[Order] ON GO
INSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (, , , CAST(0x0000A419011D32AF AS DateTime))
GO
INSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (, , , CAST(0x0000A419011D40BA AS DateTime))
GO
INSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (, , , CAST(0x0000A419011D4641 AS DateTime))
GO
INSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (, , , CAST(0x0000A419011D4B72 AS DateTime))
GO
INSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (, , , CAST(0x0000A419011D50F3 AS DateTime))
GO
INSERT [dbo].[Order] ([ID], [UserId], [TotalPrice], [SubTime]) VALUES (, , , CAST(0x0000A419011E50C9 AS DateTime))
GO
SET IDENTITY_INSERT [dbo].[Order] OFF
GO
ALTER TABLE [dbo].[Order] ADD CONSTRAINT [DF_Order_SubTime] DEFAULT (getdate()) FOR [SubTime]
GO
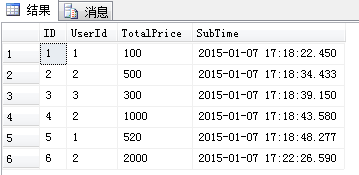
表结构和初始数据Sql
附上表结构和初始数据图:
一、ROW_NUMBER
row_number的用途的非常广泛,排序最好用他,一般可以用来实现web程序的分页,他会为查询出来的每一行记录生成一个序号,依次排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。row_number用法实例:
select ROW_NUMBER() OVER(order by [SubTime] desc) as row_num,* from [Order]
查询结果如下图所示:
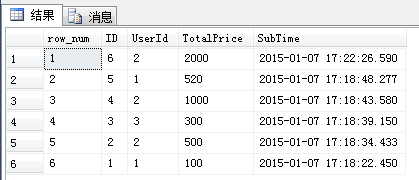
图中的row_num列就是row_number函数生成的序号列,其基本原理是先使用over子句中的排序语句对记录进行排序,然后按照这个顺序生成序号。over子句中的order by子句与SQL语句中的order by子句没有任何关系,这两处的order by 可以完全不同,如以下sql,over子句中根据SubTime降序排列,Sql语句中则按TotalPrice降序排列。
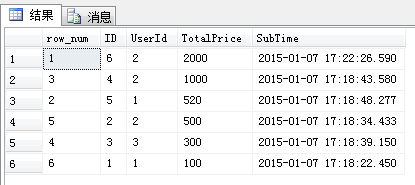
select ROW_NUMBER() OVER(order by [SubTime] desc) as row_num,* from [Order] order by [TotalPrice] desc
查询结果如下图所示:
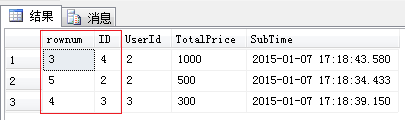
利用row_number可以实现web程序的分页,我们来查询指定范围的表数据。例:根据订单提交时间倒序排列获取第三至第五条数据。
with orderSection as
(
select ROW_NUMBER() OVER(order by [SubTime] desc) rownum,* from [Order]
)
select * from [orderSection] where rownum between 3 and 5 order by [SubTime] desc
查询结果如下图所示:
二、RANK
rank函数用于返回结果集的分区内每行的排名, 行的排名是相关行之前的排名数加一。简单来说rank函数就是对查询出来的记录进行排名,与row_number函数不同的是,rank函数考虑到了over子句中排序字段值相同的情况,如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当前的记录数生成序号,后面的记录依此类推。可能我描述的比较苍白,理解起来也比较吃力,我们直接上代码,rank函数的使用方法与row_number函数完全相同。
select RANK() OVER(order by [UserId]) as rank,* from [Order]
查询结果如下图所示:
![]()
由上图可以看出,rank函数在进行排名时,同一组的序号是一样的,而后面的则是根据当前的记录数依次类推,图中第一、二条记录的用户Id相同,所以他们的序号是一样的,第三条记录的序号则是3。
三、DENSE_RANK
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第四名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。将上面的Sql语句改由dense_rank函数来实现。
select DENSE_RANK() OVER(order by [UserId]) as den_rank,* from [Order]
查询结果如下图所示:
![]()
图中第一、二条记录的用户Id相同,所以他们的序号是一样的,第三条记录的序号紧接上一个的序号,所以为2不为3,后面的依此类推。
四、NTILE
ntile函数可以对序号进行分组处理,将有序分区中的行分发到指定数目的组中。 各个组有编号,编号从一开始。 对于每一个行,ntile 将返回此行所属的组的编号。这就相当于将查询出来的记录集放到指定长度的数组中,每一个数组元素存放一定数量的记录。ntile函数为每条记录生成的序号就是这条记录所有的数组元素的索引(从1开始)。也可以将每一个分配记录的数组元素称为“桶”。ntile函数有一个参数,用来指定桶数。下面的SQL语句使用ntile函数对Order表进行了装桶处理:
select NTILE(4) OVER(order by [SubTime] desc) as ntile,* from [Order]
查询结果如下图所示:
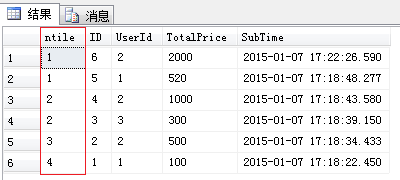
Order表的总记录数是6条,而上面的Sql语句ntile函数指定的组数是4,那么Sql Server2005是怎么来决定每一组应该分多少条记录呢?这里我们就需要了解ntile函数的分组依据(约定)。
ntile函数的分组依据(约定):
1、每组的记录数不能大于它上一组的记录数,即编号小的桶放的记录数不能小于编号大的桶。也就是说,第1组中的记录数只能大于等于第2组及以后各组中的记录数。
2、所有组中的记录数要么都相同,要么从某一个记录较少的组(命名为X)开始后面所有组的记录数都与该组(X组)的记录数相同。也就是说,如果有个组,前三组的记录数都是9,而第四组的记录数是8,那么第五组和第六组的记录数也必须是8。
这里对约定2进行详细说明一下,以便于更好的理解。
首先系统会去检查能不能对所有满足条件的记录进行平均分组,若能则直接平均分配就完成分组了;若不能,则会先分出一个组,这个组分多少条记录呢?就是 (总记录数/总组数)+1 条,之所以分配 (总记录数/总组数)+1 条是因为当不能进行平均分组时,总记录数%总组数肯定是有余的,又因为分组约定1,所以先分出去的组需要+1条。
分完之后系统会继续去比较余下的记录数和未分配的组数能不能进行平均分配,若能,则平均分配余下的记录;若不能,则再分出去一组,这个组的记录数也是(总记录数/总组数)+1条。
然后系统继续去比较余下的记录数和未分配的组数能不能进行平均分配,若能,则平均分配余下的记录;若还是不能,则再分配出去一组,继续比较余下的......这样一直进行下去,直至分组完成。
举个例子,将51条记录分配成5组,51%5==1不能平均分配,则先分出去一组(51/5)+1=11条记录,然后比较余下的 51-11=40 条记录能否平均分配给未分配的4组,能平均分配,则剩下的4组,每组各40/4=10 条记录,分配完成,分配结果为:11,10,10,10,10,晓菜鸟我开始就错误的以为他会分配成 11,11,11,11,7。
根据上面的两个约定,可以得出如下的算法:
//mod表示取余,div表示取整.
if(记录总数 mod 桶数==0)
{
recordCount=记录总数 div 桶数;
//将每桶的记录数都设为recordCount.
}
else
{
recordCount1=记录总数 div 桶数+1;
int n=1;//n表示桶中记录数为recordCount1的最大桶数.
m=recordCount1*n;
while(((记录总数-m) mod (桶数- n)) !=0)
{
n++;
m=recordCount1*n;
}
recordCount2=(记录总数-m) div (桶数-n);
//将前n个桶的记录数设为recordCount1.
//将n+1个至后面所有桶的记录数设为recordCount2.
}
int recordTotal = ;//记录总数.
int tcount = ;//总组数.
string groupResult = "将" + recordTotal + "条记录分成" + tcount + "组,";
int recordCount = ;//平均分配时每组的记录数.
//不能平均分配
int recordCount1 = ;//前n个组每组的记录数.
int recordCount2 = ;//第n+1组至后面所有组每个组的记录数.
int n = ;//组中记录数为recordCount1的最大组数(前n组).
if (recordTotal % tcount == )//能平分.
{
recordCount = recordTotal / tcount;//每组的记录数.
}
else//不能平分.
{
recordCount1 = recordTotal / tcount + ;//不能平分则先分出一组-前n组每组的记录数.
int m = recordCount1 * n;//已分配的记录数.
while ((recordTotal - m) % (tcount - n) != )//余下的记录数和未分配的组不能进行平分.
{
//还是不能平分,继续分出一组.
n++;
m = recordCount1 * n;
}
recordCount2 = (recordTotal - m) / (tcount - n);//余下的记录数和未分配的组能进行平分或者只剩下最后一组了-第n+1组至后面所有组每个组的记录数.
}
//输出.
if (recordCount != )
{
groupResult += "能平均分配,每组" + recordCount + "个.";
}
else
{
groupResult += "不能平均分配,前" + n + "组,每组" + recordCount1 + "个,";
if (n < tcount - )
{
//groupResult += "第" + (groupNumber + 1) + "组至后面所有组,每组" + recordCount2 + "个.";
groupResult += "第" + (n + ) + "组至第" + tcount + "组,每组" + recordCount2 + "个.";
}
else
{
groupResult += "第" + (n + ) + "组" + recordCount2 + "个.";
}
}
ViewData["result"] = groupResult;
NTILE()函数算法实现代码
根据上面的算法,如果总记录数为59,总组数为5,则 n=4 , recordCount1=12 , recordCount2=11,分组结果为 :12,12,12,12,11。
如果总记录数为53,总组数为5,则 n=3 , recordCount1=11 , recordCount2=10,分组结果为:11,11,11,10,10。
就拿上面的例子来说,总记录数为6,总组数为4,通过算法得到 n=2 , recordCount1=2 , recordCount2=1,分组结果为:2,2,1,1。
select ntile,COUNT([ID]) recordCount from
(
select NTILE(4) OVER(order by [SubTime] desc) as ntile,* from [Order]
) as t
group by t.ntile
运行Sql,分组结果如图:
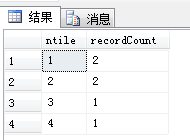
比对算法与Sql Server的分组结果是一致的,说明算法没错。:)
总结:
在使用排名函数的时候需要注意以下三点:
1、排名函数必须有 OVER 子句。
2、排名函数必须有包含 ORDER BY 的 OVER 子句。
3、分组内从1开始排序
转载:https://www.cnblogs.com/52XF/p/4209211.html
Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介的更多相关文章
- SQL Server中排名函数row_number,rank,dense_rank,ntile详解
SQL Server中排名函数row_number,rank,dense_rank,ntile详解 从SQL SERVER2005开始,SQL SERVER新增了四个排名函数,分别如下:1.row_n ...
- SQL Server:排名函数row_number,rank,dense_rank,ntile详解
1.Row_Number函数 row_number函数大家比较熟悉一些,因为它的用途非常的广泛,我们经常在分页与排序中用到它,它的功能就是在每一行中生成一个连续的不重复的序号 例如: select S ...
- 好用的排名函数~ROW_NUMBER(),RANK(),DENSE_RANK() 三兄弟
排名函数三兄弟,一看名字就知道,都是为了排名而生!但是各自有各自的特色!以下一个例子说明问题!(以下栗子没有使用Partition By 的关键字,整个结果集进行排序) RANK 每个值一个排名,同样 ...
- Spark2 Dataset分析函数--排名函数row_number,rank,dense_rank,percent_rank
select gender, age, row_number() over(partition by gender order by age) as rowNumber, ...
- Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)(转载)
Sql 四大排名函数(ROW_NUMBER.RANK.DENSE_RANK.NTILE)简介 排名函数是Sql Server2005新增的功能,下面简单介绍一下他们各自的用法和区别.我们新建一张O ...
- SQL With As 用法Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
Sql 四大排名函数(ROW_NUMBER.RANK.DENSE_RANK.NTILE)简介 排名函数是Sql Server2005新增的功能,下面简单介绍一下他们各自的用法和区别.我们新建一张O ...
- ROW_NUMBER()/RANK()/DENSE_RANK()/ntile() over()
ROW_NUMBER()/RANK()/DENSE_RANK()/ntile() over() 今天女票问我SqlServer的四种排序,当场写了几句Sql让她了解,现把相关Sql放上来. 首先, ...
- 知方可补不足~row_number,rank,dense_rank,ntile排名函数的用法
回到目录 这篇文章介绍SQL中4个很有意思的函数,我称它的行标函数,它们是row_number,rank,dense_rank和ntile,下面分别进行介绍. 一 row_number:它为数据表加一 ...
- SQL Server - 四种排序, ROW_NUMBER() /RANK() /DENSE_RANK() /ntile() over()
>>>>英文版 (更简洁易懂)<<<< 转载自:https://dzone.com/articles/difference-between-rownum ...
随机推荐
- 网易云歌词解析(配合audio标签实现本地歌曲播放,歌词同步)
先看下效果 github上做的一个音乐播放器: https://github.com/SorrowX/electron-music 中文歌曲 英文歌曲(如果有翻译的中文给回返回出去) 韩文歌曲 来看下 ...
- 《通过C#学Proto.Actor模型》之Mailbox
邮箱是Actor模型的一个重要组成部分,负责接收发过来的消息,并保存起来,等待Actor处理.邮箱中维护着两种队列,一种是存系统消息,另一个是存用户消息,系统省是指Started,Stoping,St ...
- Java 200+ 面试题补充② Netty 模块
让我们每天都能看到自己的进步.老王带你打造最全的 Java 面试清单,认真把一件事做到最好. 本文是前文<Java 最常见的 200+ 面试题>的第二个补充模块,第一模块为:<Jav ...
- rs485引脚定义
转自:http://blog.chinaunix.net/uid-9688646-id-3275796.html rs485有两种,一种是半双工模式,只有DATA+和DATA-两线,另一种是全双工模式 ...
- Flask —— 信号(5)
Flask框架中的信号基于blinker,其主要就是让开发者可是在flask请求过程中定制一些用户行为. pip3 install blinker 1. 内置信号 request_started = ...
- Tomcat服务器下载、安装、配置环境变量教程(超详细)
请先配置安装好Java的环境,若没有安装,请参照我以下的步骤进行安装! 请先配置安装好Java的环境,若没有安装,请参照我以下的步骤进行安装! 请先配置安装好Java的环境,若没有安装,请参照我以下上 ...
- UVA 1627 Team them up!
https://cn.vjudge.net/problem/UVA-1627 题目 有n(n≤100)个人,把他们分成非空的两组,使得每个人都被分到一组,且同组中的人相互认识.要求两组的成员人数尽量接 ...
- 从备份文件bak中识别SQL Server的版本
SQLServer 的备份文件是以.bak 为后缀的文件,如果想要通过备份文件查看数据库版本,通常的做法就是把数据库还原,但是在还原的过程,如果不是相同的数据库版本,就会导致无法还原: 在数据库中,低 ...
- Windows 7 下安装 docker 应用容器引擎
文档地址 ====================================== 安装篇 下载工具 https://get.daocloud.io/toolbox/ 下载完成点击安装 (可参考: ...
- BZOJ4671异或图
题目描述 定义两个结点数相同的图 G1 与图 G2 的异或为一个新的图 G, 其中如果 (u, v) 在 G1 与 G2 中的出现次数之和为 1, 那么边 (u, v) 在 G 中, 否则这条边不在 ...