Python数据结构应用5——排序(Sorting)

在具体算法之前,首先来看一下排序算法衡量的标准:
- 比较:比较两个数的大小的次数所花费的时间。
- 交换:当发现某个数不在适当的位置时,将其交换到合适位置花费的时间。
冒泡排序(Bubble Sort)
这是一个面试经常考的排序,虽然简单,但是要保证一点都不出错也不简单。
冒泡,顾名思义,每一次冒出一个泡泡出来,这个泡泡是剩余数中最大的那个数。所以,如果有n个数待排序,那么需要冒(n-1)次泡泡。即最外层循环需要len(list)-1次。
每一次冒泡的过程即内层循环。每次取一对数(pair),按顺序从最开始的一对数开始,比较两个数哪个数比较大就交换到上部(右边/冒泡),然后依次执行下一对数(每次进1),这个内层循环的次数随着外层循环的次数增加而减少,因为一旦进行了一次外层循环,已经排好序的数就多了一个。
一次冒泡的过程如下图:
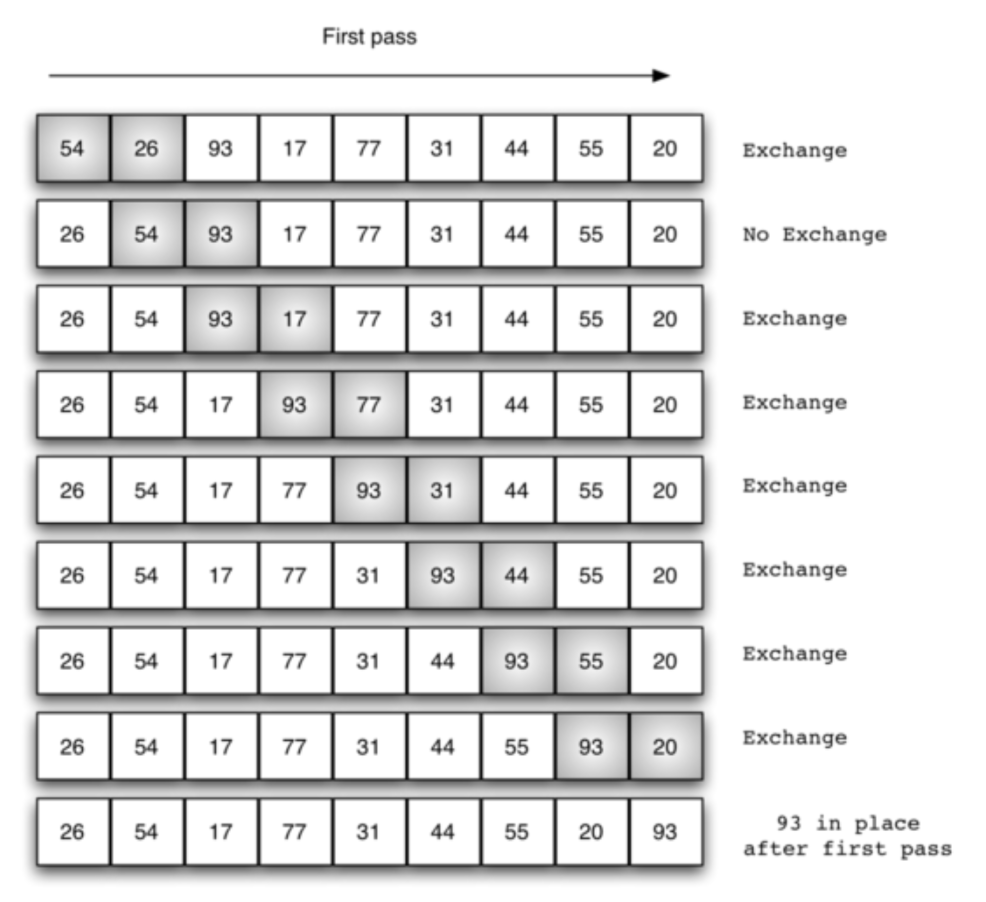
def bubble_sort(a_list):
for pass_num in range(len(a_list)-1,0,-1):
for i in range(pass_num):
if a_list[i] > a_list[i+1]:
a_list[i],a_list[i+1] = a_list[i+1],a_list[i]
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
bubble_sort(a_list)
print(a_list)
[17, 20, 26, 31, 44, 54, 55, 77, 93]
这种冒泡排序是很耗时间的,每一次外层循环,需要比较的次数如下图所示:

所以,一共需要\(\frac{1}{2}n^{2}-\frac{1}{2}n\) 次比较,时间复杂度是\(O(n^{2})\),如果看最坏的情况,即每次比较后都需要交换两个数,那么总时间✖️2
事实上,在很多情况下,冒泡排序并不需要完成所有的外循环就已经将所有数排好序啦,但是由于程序的笨蛋性,他还是在一直的执行下去,浪费时间。那么,我们可以将冒泡排序进行改进,让其知道一旦所有数据已经是按顺序排好时就停止工作,以进行时间优化:
def short_bubble_sort(a_list):
exchanges = True # 此标志用来记录一轮循环中是否进行了交换
pass_num = len(a_list)-1
while pass_num > 0 and exchanges:
exchanges = False
for i in range(pass_num):
if a_list[i]>a_list[i+1]:
exchanges = True
a_list[i],a_list[i+1] = a_list[i+1],a_list[i]
pass_num -= 1
a_list=[20, 30, 40, 90, 50, 60, 70, 80, 100, 110]
short_bubble_sort(a_list)
print(a_list)
[20, 30, 40, 50, 60, 70, 80, 90, 100, 110]
选择排序(Selection Sort)
选择排序其实每次外层循环的结果和冒泡排序很像,即每次在待排序元素中找到最大的元素,将其与应该放的位置交换。即每进行一次外层循环就多排好了一个元素。
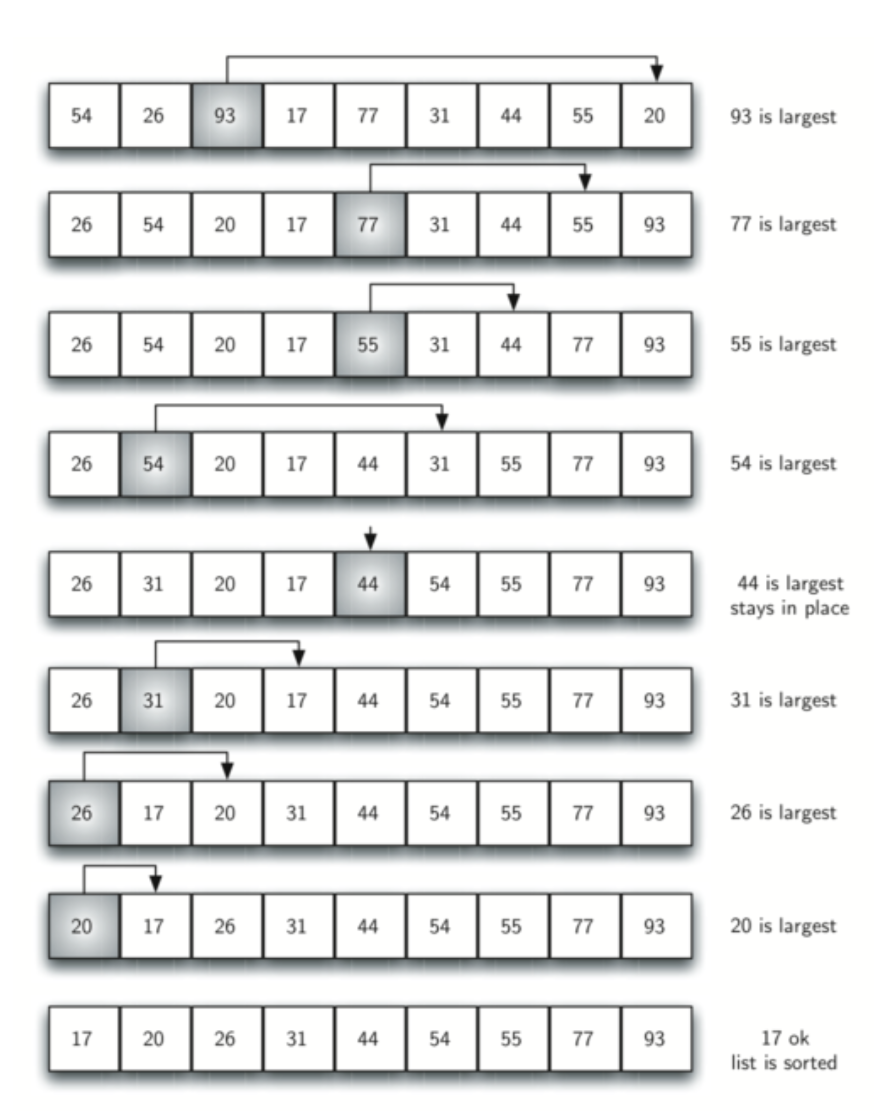
选择排序的时间复杂度仍为\(O(n^{2})\),但是由于其元素交换的次数比冒泡排序要少,所以消耗的时间比冒泡排序要短。
def selection_sort(a_list):
for fill_slot in range(len(a_list)-1,0,-1):
# fill_slot 这一轮最大元素将要放入的位置
pos_of_max=0
# 这一轮最大元素的位置
for location in range(1, fill_slot+1):
if a_list[location]>a_list[pos_of_max]:
pos_of_max = location
a_list[fill_slot],a_list[pos_of_max]=a_list[pos_of_max],a_list[fill_slot]
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
selection_sort(a_list)
print(a_list)
[17, 20, 26, 31, 44, 54, 55, 77, 93]
插入排序(Insertion Sort)
插入排序就像插扑克牌,每一次插一张牌到合适大小的位置,直到n张牌插入完毕。所以插入排序需要n-1次插入操作,即外层循环。每一次插入操作需要在已经排好序的数中依次进行比较,直到找到合适的位置。所以插入排序的时间复杂度在最好的情况下为\(O(n)\),最坏情况下为\(O(n^{2})\)。
插入排序过程如下图所示:

def insertion_sort(a_list):
for index in range(1, len(a_list)):
# index 为该轮要插入元素的位置
current_value = a_list[index]
position = index
while position>0 and a_list[position-1]>current_value:
a_list[position] = a_list[position-1]
position = position - 1
a_list[position] = current_value
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
insertion_sort(a_list)
print(a_list)
[17, 20, 26, 31, 44, 54, 55, 77, 93]
希尔排序(Shell Sort)
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率,但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
如下图所示,这个list中一共有9个数,我们将这9个数分成三个sublists,位置增量为3(如图每一列的深色部分为一个sublist)。对于每个sublist进行一次插入排序,且保持原来的位置放置在一个新的list中。
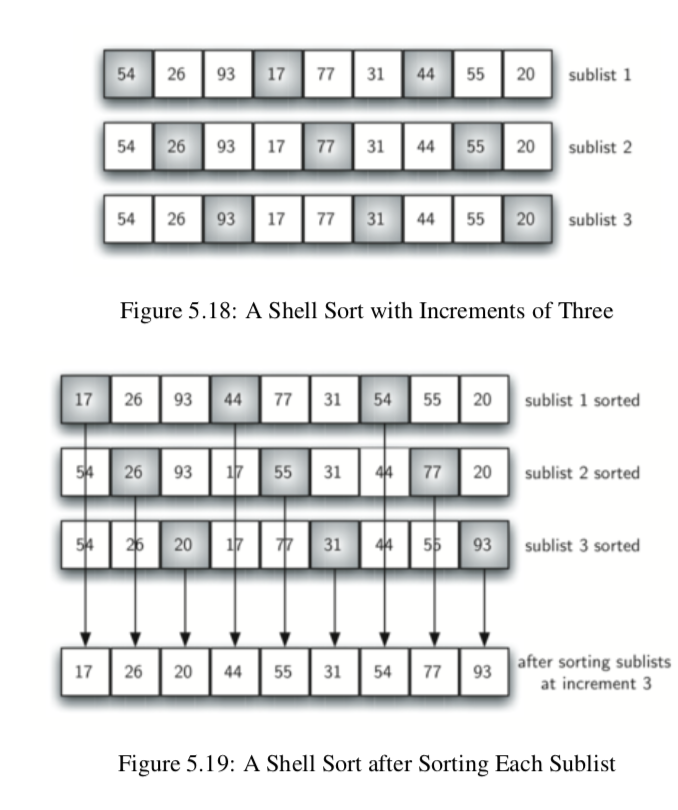
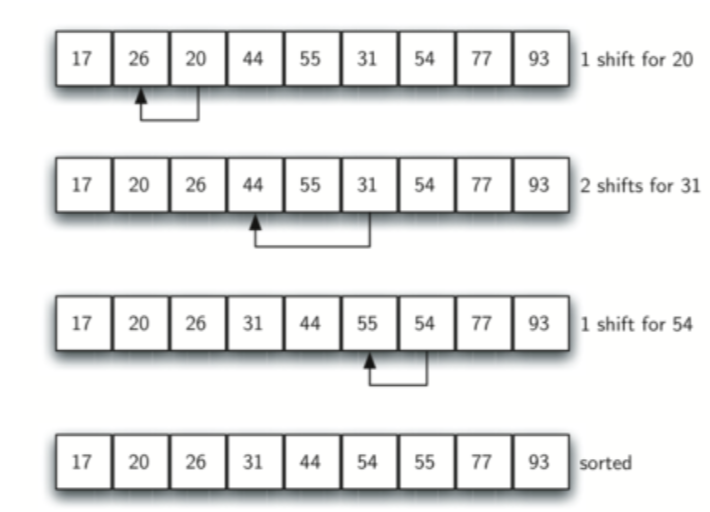
对于这个新的list,我们进行一次标准的插入排序。注意到,由于我们对于之前的sublist已经进行过排序,所以我们减少了这次标准插入排序的移动操作数。
def shell_sort(a_list):
increment = len(a_list) // 2 # (步进数)
while increment > 0:
for start_position in range(increment):
gap_insertion_sort(a_list, start_position, increment)
print("After increments of size", increment, "The list is",a_list)
increment = increment // 2
def gap_insertion_sort(a_list, start, gap):
for i in range(start+gap, len(a_list), gap):
# 以下为插入排序
current_value = a_list[i]
position = i
while position >= gap and a_list[position-gap]>current_value:
a_list[position] = a_list[position-gap]
position = position - gap
a_list[position] = current_value
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
shell_sort(a_list)
print(a_list)
After increments of size 4 The list is [20, 26, 44, 17, 54, 31, 93, 55, 77]
After increments of size 2 The list is [20, 17, 44, 26, 54, 31, 77, 55, 93]
After increments of size 1 The list is [17, 20, 26, 31, 44, 54, 55, 77, 93]
[17, 20, 26, 31, 44, 54, 55, 77, 93]
步进increment在希尔排序中是一个重要的参数。上列函数shell_sort()使用了不同的步进。首先,创造了n/2个sublist,接下来,创造了n/4个sublist,步进也逐次减小。下图是第一次循环中的sublist选择:
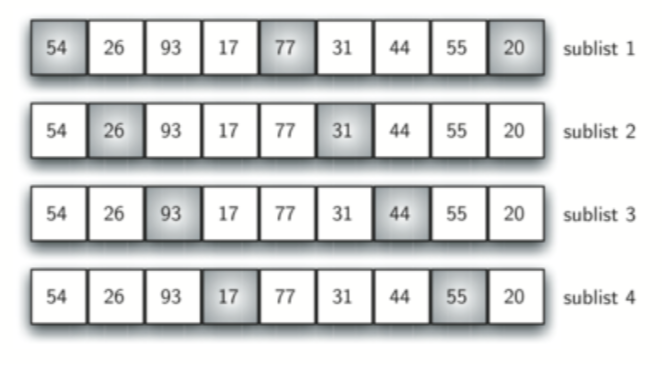
归并排序(Merge Sort)
从这里,开始介绍分治策略(divide and conquer)。
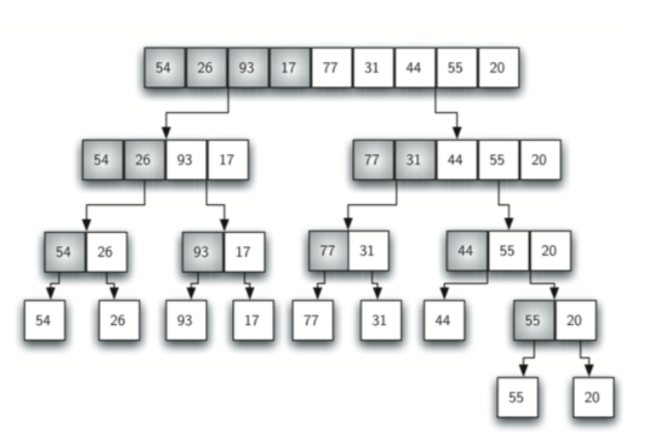
归并排序其实跟二分搜索很相像,采用的是递归的方法。每次将待排序的list'平均'分成左右两个sublists,然后分别进行排序,依次递归,直到sublist的长度<=1。
第一个图是list的divide的过程:
第二个图是sublists的conquer(merge)的过程:
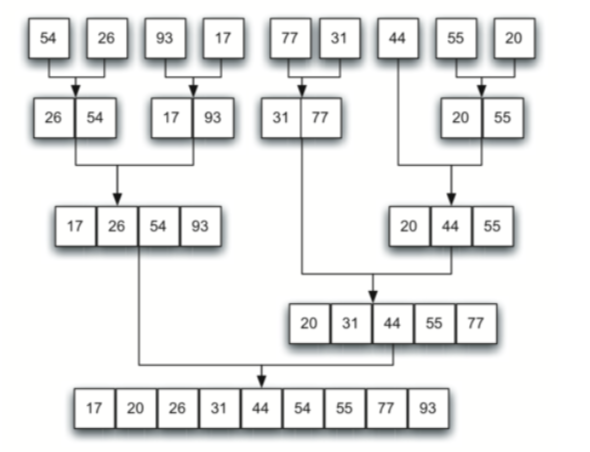
def merge_sort(a_list):
print('splitting', a_list)
if len(a_list)>1:
mid = len(a_list) // 2
# 这两个half需要额外的空间
left_half = a_list[:mid]
right_half = a_list[mid:]
merge_sort(left_half)
merge_sort(right_half)
# 当左右两个sublist都排好序时,每次选择两个sublist的最小的数
# 然后在这两数中选择更小的数依次放入待返回的list中
i,j,k=0,0,0
while i<len(left_half) and j<len(right_half):
if left_half[i] < right_half[j]:
a_list[k] = left_half[i]
i = i + 1
else:
a_list[k] = right_half[j]
j = j + 1
k = k + 1
while i < len(left_half):
a_list[k] = left_half[i]
i = i + 1
k = k + 1
while j < len(right_half):
a_list[k] = right_half[j]
j = j + 1
k = k + 1
print("Merging ", a_list)
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
merge_sort(a_list)
print(a_list)
splitting [54, 26, 93, 17, 77, 31, 44, 55, 20]
splitting [54, 26, 93, 17]
splitting [54, 26]
splitting [54]
splitting [26]
Merging [26, 54]
splitting [93, 17]
splitting [93]
splitting [17]
Merging [17, 93]
Merging [17, 26, 54, 93]
splitting [77, 31, 44, 55, 20]
splitting [77, 31]
splitting [77]
splitting [31]
Merging [31, 77]
splitting [44, 55, 20]
splitting [44]
splitting [55, 20]
splitting [55]
splitting [20]
Merging [20, 55]
Merging [20, 44, 55]
Merging [20, 31, 44, 55, 77]
Merging [17, 20, 26, 31, 44, 54, 55, 77, 93]
[17, 20, 26, 31, 44, 54, 55, 77, 93]
归并排序的时间复杂度,又是时候祭出这张图了(来自《算法导论》)。来看这个图,对于每一个conquer(merge)过程,merge后进行排序的时间消耗为len(sublist),在图中体现为n, n/2, n/4, ...。所以,图中每一行消耗的总时间为 n/len(sublist) * len(sublist),其中n为list的总长度。而一共有log(n)个这样的行,所以归并排序的时间复杂度为\(O(nlog(n))\)
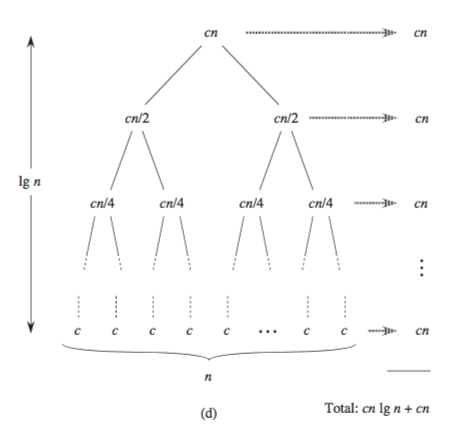
快速排序
快速排序也是一种分治策略,相对于归并排序来说,快速排序没有使用额外的空间。
快速排序会在list中选择一个主元(pivot value),也可以叫它分割点(split point),通常是list的首尾元素,如下图,主元是54。接下来,在除去主元的剩余数中最左边为左标记(leftmark),最右边为右标记(rightmark),左标记向右移,直到移到的数小于主元数为止;右标记向左移,直到移到的数大于主元数为止。然后,交换此时两个标记的数。这个过程一直进行下去,直到两个标记移动交叉(cross)则停止移动。
此时,将主元数插入到左标记和右标记之间,则主元左边的数全都小于主元,主元右边的数全都大于主元。
对左右两边的数构成的sublist进行递归quicksort。整个过程如下图:
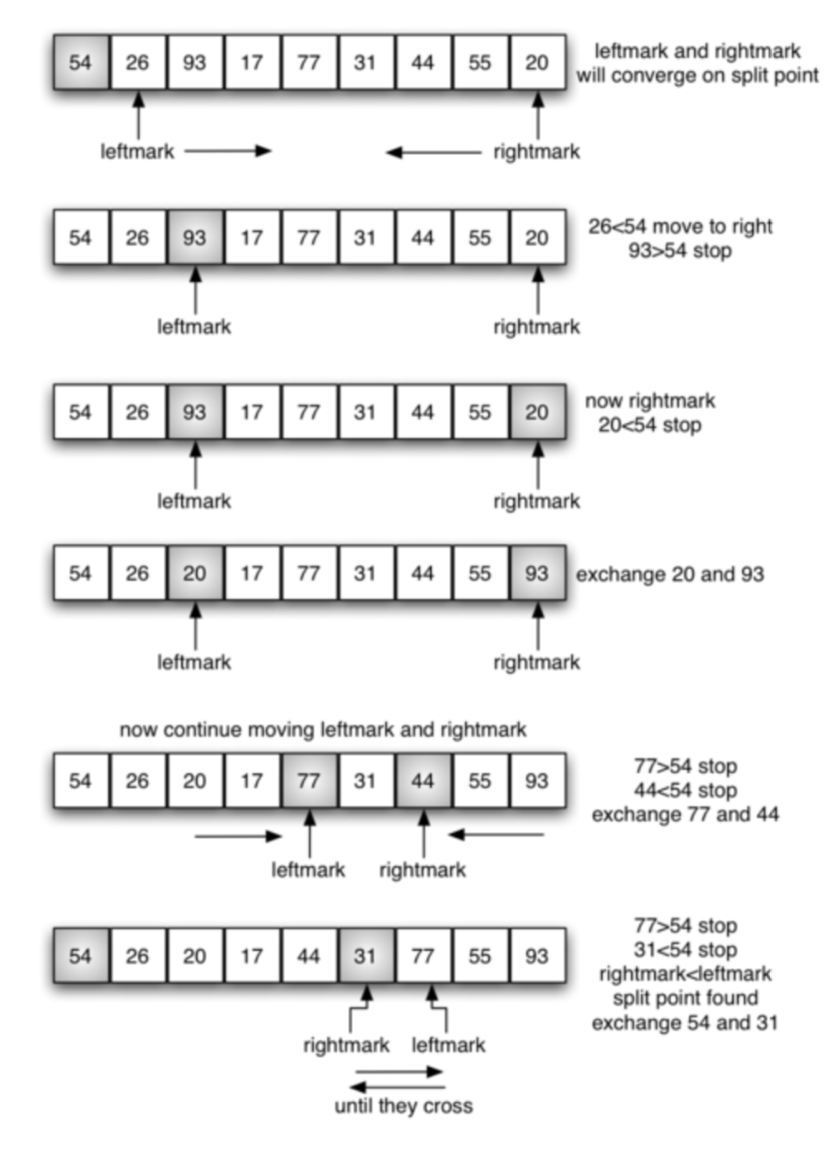
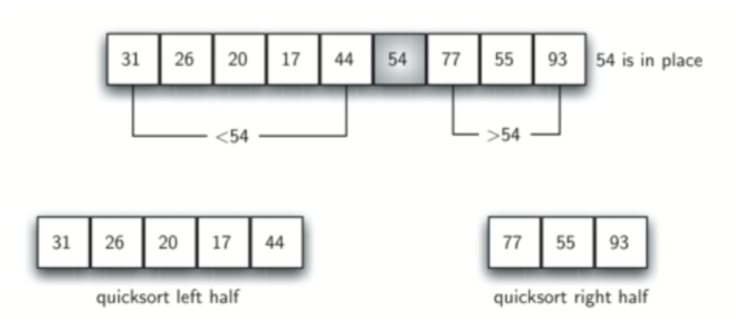
def quick_sort(a_list):
quick_sort_helper(a_list, 0, len(a_list) - 1)
def quick_sort_helper(a_list, first, last):
# first和last分别是a_list的首尾位置,由于快速排序没有额外空间,
# 所以需要记录sublist的首尾位置
if first < last: # 若len(sublist)>0
split_point = partition(a_list, first, last)
quick_sort_helper(a_list, first, split_point - 1)
quick_sort_helper(a_list, split_point + 1, last)
def partition(a_list, first, last):
pivot_value = a_list[first]
left_mark = first+1
right_mark = last
done = False
while not done:
#
while left_mark <= right_mark and a_list[left_mark] <= pivot_value:
left_mark = left_mark + 1
while left_mark <= right_mark and a_list[right_mark] >= pivot_value:
right_mark = right_mark - 1
if right_mark < left_mark:
done = True
else: # (right_mark - left_mark) == 1
a_list[left_mark],a_list[right_mark]=a_list[right_mark],a_list[left_mark]
a_list[first],a_list[right_mark] = a_list[right_mark],a_list[first]
return right_mark
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
quick_sort(a_list)
print(a_list)
[17, 20, 26, 31, 44, 54, 55, 77, 93]
快速排序的时间复杂度取决于主元的选择,如果主元的大小每次都在整个list的中间,那么divide的过程则就类似于归并排序的过程,时间复杂度的结果就是\(O(nlog(n))\)。
然而,并不是所有情况都是这么好的。想象一下最坏情况,如果每次主元都正好选到了剩余list中最小或者最大的那个数,则每次divide只能分割掉一个元素,这就和选择排序基本无异了,时间复杂度上升为\(O(n^{2})\)
所以,为了避免这种情况的发生,我们可以尝试随机选择主元,这可以减少原始数据的本来结构对于复杂度的影响。
- Reference:
Python数据结构应用5——排序(Sorting)的更多相关文章
- python数据结构之选择排序
选择排序(select_sort)是一个基础排序,它主要通过查找已给序列中的元素的最大或者最小元素,然后将其放在序列的起始位置或者结束位置,并通过多次这样的循环完成对已知序列的排序,在我们对n个元素进 ...
- python数据结构之希尔排序
def shell_sort(alist): n=len(alist) gap= int(n / 2) #步长 while gap>0: for i in range(gap,n): j=i w ...
- python数据结构与算法
最近忙着准备各种笔试的东西,主要看什么数据结构啊,算法啦,balahbalah啊,以前一直就没看过这些,就挑了本简单的<啊哈算法>入门,不过里面的数据结构和算法都是用C语言写的,而自己对p ...
- 漫谈python中的搜索/排序
在数据结构那一块,搜索有顺序查找/二分查找/hash查找,而排序有冒泡排序/选择排序/插入排序/归并排序/快速排序.如果遇到数据量和数组排列方式不同,基于时间复杂度的考虑,可能需要用到混合算法.如果用 ...
- Python数据结构与算法--算法分析
在计算机科学中,算法分析(Analysis of algorithm)是分析执行一个给定算法需要消耗的计算资源数量(例如计算时间,存储器使用等)的过程.算法的效率或复杂度在理论上表示为一个函数.其定义 ...
- python数据结构之直接插入排序
python数据结构之直接插入排序 #-*-encoding:utf-8-*- ''' 直接插入排序: 从序列的第二个元素开始,依次与前一个元素比较,如果该元素比前一个元素大, 那么交换这两个元素.该 ...
- Python - 数据结构 - 第十五天
Python 数据结构 本章节我们主要结合前面所学的知识点来介绍Python数据结构. 列表 Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和 ...
- Python实现的选择排序算法原理与用法实例分析
Python实现的选择排序算法原理与用法实例分析 这篇文章主要介绍了Python实现的选择排序算法,简单描述了选择排序的原理,并结合实例形式分析了Python实现与应用选择排序的具体操作技巧,需要的朋 ...
- [python学习] 语言基础—排序函数(sort()、sorted()、argsort()函数)
python的内建排序函数有 sort.sorted两个. 1.基础的序列升序排序直接调用sorted()方法即可 ls = list([5, 2, 3, 1, 4]) new_ls = sorted ...
随机推荐
- eclipse中英文(等各国语言)版本转换发放
eclipse界面语言的切换方法 1.该方法只支持安装过中文包的eclipse(其实中文包中几乎包含了全世界所有的语言,只是调用了其中的中文简体而已) 2.在桌面的快捷方式中目标的地址后面加上参数-n ...
- 关于mybatis更新数据的问题
前两天用mybatis的时候,发现这样一个问题,日志显示mytatis更新数据已经成功了,但是实际上数据库是没有更新到的,经过一番查找,发现mybatis更新的时候默认返回的是查找到的数据(Rows ...
- C#程序自动更新软件版本号
最近因为服务器程序管理多,所以在查看服务器程序的时候,只能通过EXE的编译时间来判断服务器程序版本时间,费神伤身啊 现在想了一个方式,在目录下新增一个version文件,里面写上年月日,并且只是在程序 ...
- 【js-xlsx和file-saver插件】前端html的table导出数据到excel的表格合并显示boder
最近在做项目,需要从页面的表格中导出excel,一般导出excel有两种方法:一.习惯上是建模版从后台服务程序中导出:二.根据页面table中导出:综合考虑其中利弊选择二.根据页面table中导出ex ...
- 关于SpringMVC控制器的一点补充
首先复习一下之前控制器的写法:http://www.cnblogs.com/eco-just/p/7882016.html. 我们可以看到,之前的写法是这样的: @RequestMapping(&qu ...
- 寻找DevExpress破解经历之旅
众所周知DevExpress是收费的,但是破解版的也不少,近期公司需要做发票套打的功能让我找个打印工具,我寻思着DevExpress这个软件好像挺不错的,功能强大,看了下价格方面,好吧!2W多呢,市面 ...
- 一天搞懂深度学习-训练深度神经网络(DNN)的要点
前言 这是<一天搞懂深度学习>的第二部分 一.选择合适的损失函数 典型的损失函数有平方误差损失函数和交叉熵损失函数. 交叉熵损失函数: 选择不同的损失函数会有不同的训练效果 二.mini- ...
- python笔记:#009#判断语句
判断(if)语句 目标 开发中的应用场景 if 语句体验 if 语句进阶 综合应用 01. 开发中的应用场景 生活中的判断几乎是无所不在的,我们每天都在做各种各样的选择,如果这样?如果那样?-- 程序 ...
- SpringBoot整合Kafka和Storm
前言 本篇文章主要介绍的是SpringBoot整合kafka和storm以及在这过程遇到的一些问题和解决方案. kafka和storm的相关知识 如果你对kafka和storm熟悉的话,这一段可以直接 ...
- 第一课:Hadoop集群环境搭建
一. 检查列表 1.1.网络访问 设置电脑IP以及可以访问网络设置:进入etc/sysconfig/network-scripts/,使用命令"ls -all" 查看文件.会看到i ...