HashMap实现分析
HashMap最基本的实现思想如下图所示,使用数组加链表的组合形式来完成数据的存储。
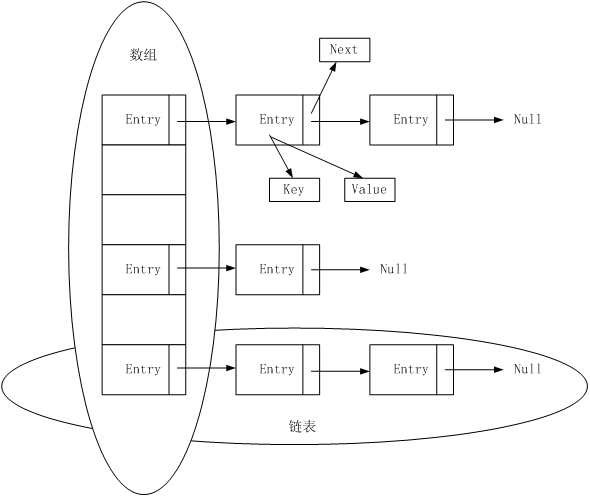
Entry在数组中的位置是由key的hashcode决定的。
向一个数组长度为16,负载因子为0.75的HashMap中插入key的hashcode为26、126、1、337、184、12、31、111的对象后的结构为:
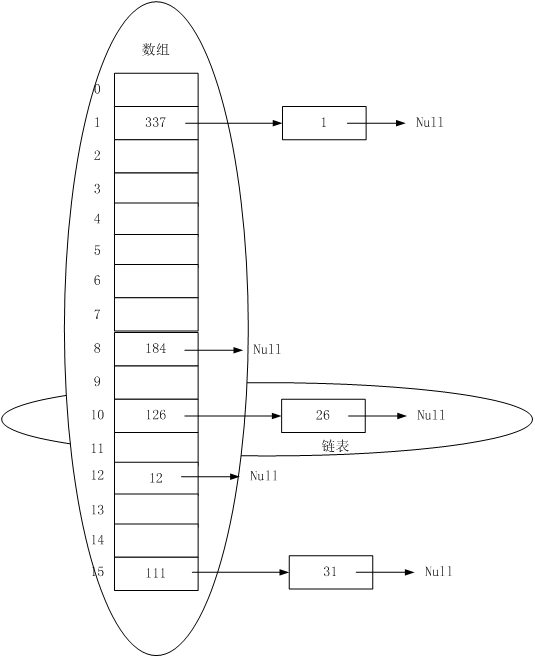
1%16 =1 ,337%16 =1。数组中存储的是最后插入的数据,并用next指针指向之前已经存在的数据。
HashMap查找数据的依据是:现根据key的hashcode查找位于数组中的位置,在使用next依次遍历链表中的元素,调用key的equals方法,如果key equals Entry对应的key,则Entry中的value就是所找的值。所以使用对象作为HashMap的key时,重写hashcode方法的同时需要重写equals方法。
可以参考HashMap的get方法的代码,就会更清楚上面的描述:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
HashMap中的Hash算法是经过了优化之后的,可以看到
int hash = hash(key.hashCode());对hashcode又进行了二次散列操作,这样做的目的是使得计算出的hash比hashcode在数组上的分布将更为均匀,HashMap的空间利用率也越高。
HashMap对hashcode的二次散列如下:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
HashMap在使用hash计算位于数组中的位置时也不是简单的%操作,而是用的indexFor来完成的。%操作比较耗资源,当HashMap中数组的length是2 的n次方时,h& (length-1)运算等价于h%length,但是&比%具有更高的效率。
static int indexFor(int h, int length) {
return h & (length-1);
}
理解了二次散列和indexFor,上面的代码就比较的好理解了。table数组就是图中的Entry数组。
HashMap可以存储key为null的Entry,该Entry将被放在数组指标为0的位置。
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中。最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是rehash。
那么HashMap什么时候进行扩容呢?当HashMap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
这一策略在源码中的实现是通过modCount域,modCount顾名思义就是修改次数,对HashMap内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount。
在迭代过程中,判断modCount跟expectedModCount是否相等,如果不相等就表示已经有其他线程修改了Map:
modCount的修饰符为volatile,保证线程之间修改的可见性。
HashSet的底层也是用HashMap来实现的,使用HashMap的key来进行存储与散列。
HashMap实现分析的更多相关文章
- HashMap底层分析
以下基于 JDK1.7 分析. 如图所示,HashMap 底层是基于数组和链表实现的.其中有两个重要的参数: 容量 负载因子 容量的默认大小是 16,负载因子是 0.75,当 HashMap 的 si ...
- HashMap的分析(转)
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- 面试必问---HashMap原理分析
一.HashMap的原理 众所周知,HashMap是用来存储Key-Value键值对的一种集合,这个键值对也叫做Entry,而每个Entry都是存储在数组当中,因此这个数组就是HashMap的主干.H ...
- HashMap 底层分析
以下基于 JDK1.7 分析 如图所示,HashMap底层是基于数组和链表实现的,其中有两个重要的参数: ---容量 ---负载因子 容量的默认大小是16,负载因子是0.75,当HashMap的siz ...
- ConcurrentHashMap 并发HashMap原理分析
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁.如图 左边便是Hashtable的实现方式---锁整个hash表:而右边则是Concurrent ...
- Java基础之HashMap原理分析(put、get、resize)
在分析HashMap之前,先看下图,理解一下HashMap的结构 我手画了一个图,简单描述一下HashMap的结构,数组+链表构成一个HashMap,当我们调用put方法的时候增加一个新的 key-v ...
- 聊聊经典数据结构HashMap,逐行分析每一个关键点
本文基于JDK-8u261源码分析 本文原创首发于 奇客时间(qiketime) 1 简介 HashMap是一个使用非常频繁的键值对形式的工具类,其使用起来十分方便.但是需要注意的是,HashMap不 ...
- 2021超详细的HashMap原理分析,面试官就喜欢问这个!
一.散列表结构 散列表结构就是数组+链表的结构 二.什么是哈希? Hash也称散列.哈希,对应的英文单词Hash,基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出 这个映射的规则就是对 ...
- HashMap原理分析
HashMap 实现Map.Cloneable.Serializable接口,继承AbstractMap基类. HashMap map = new HashMap(); 实例化一个HashMap,在构 ...
随机推荐
- itoa函数,sprintf函数
itoa函数 itoa 为c语言的一个函数.itoa 函数是一个广泛应用的,从非标准扩展到标准的C语言.它不能被移植,因为它不是标准定义下的C语言,但是,编译器通常在一个不遵循程式标准的模式下允许其通 ...
- JAVA爬虫实践(实践四:webMagic和phantomjs和淘宝爬虫)
webMagic虽然方便,但是也有它不适用的地方,比如定向的某个单页面爬虫,或者存在大量ajax请求,页面的跳转请求全都混淆在js里. 这时可以用webMagic结合phantomjs来真实模拟页面请 ...
- 【JAVA】SWING_ 界面风格
在java中,界面外观的管理是由UIManager类来管理的.不同的系统上安装的外观不一样 ,默认的是java的跨平台外观. 1.获取系统所有外观 import javax.swing.*; impo ...
- chorme浏览器的Access-Control-Allow-Origin拦截限制
今天在公司调试一个项目,这个项目的前后端是分离开的,也就是说前后端是在两个站点上的.我负责的前端页面在请求后端数据的时候数据可以拿到,但是chrome安全级别高,自动拦截跨域和站点的数据请求及交互,出 ...
- javaScript原生定义的函数
1.JavaScript中的算术运算 包括加(+).减(-).乘(*).除(/)和求余(取模)(%)运算,除了这些基本的运算外,JavaScript还支持更加复杂的算术运算,这些复杂算术运算作为Mat ...
- 【Java提高】---枚举的应用
枚举 一.枚举和静态常量区别 讲到枚举我们首先思考,它和public static final String 修饰的常量有什么不同. 我举枚举的两个优点: 1. 保证了 ...
- Sass的四种编译方式
我们都知道Sass其实有两种,一种是Sass,一种是SCSS. Sass 和 SCSS 其实是同一种东西,我们平时都称之为 Sass,两者之间不同之处有以下两点: 文件扩展名不同,Sass 是以“.s ...
- JavaScript语法基础:数组的常用方法详解
本文最初发表于博客园,并在GitHub上持续更新前端的系列文章.欢迎在GitHub上关注我,一起入门和进阶前端. 以下是正文. 数组的定义 之前学习的数据类型,只能存储一个值(字符串为一个值).如果我 ...
- PHP实现伪静态方法汇总
PHP伪静态的使用主要是为了隐藏传递的参数名,下面给大家介绍php实现伪静态的方法,对php实现伪静态相关知识感兴趣的朋友一起学习吧 PHP伪静态的使用主要是为了隐藏传递的参数名,下面给大家介绍php ...
- 解决Sublime Text 3在GBK编码下的中文乱码问题听语音
Sublime Text 3是我最喜欢的代码编辑器,没有之一,因为她的性感高亮代码配色,更因为它的小巧,但是它默认不支持GBK的编码格式,因此打开GBK的代码文件,如果里面有中文的话,就会乱码 工具/ ...