Spark MLib:梯度下降算法实现
声明:本文参考《 大数据:Spark mlib(三) GradientDescent梯度下降算法之Spark实现》
1. 什么是梯度下降?
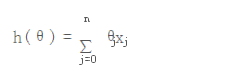

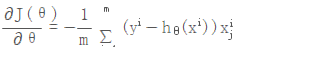
,

2. 梯度下降的几种方式
2.1 批量梯度下降(BGD)

中我们会发现随着计算θ的梯度下降,需要计算所有的采样数据m,计算量会比较大。
2.2 随机梯度下降 (SGD)
在上面2.1的批量梯度下降,采样的是批量数据,那么随机采样一个数据,进行θ梯度下降,就被称为随机梯度下降。
损失函数:
那么单样本的损失函数:m=1 的情况:
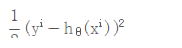
对单样本的损失函数进行求偏导,计算梯度下降
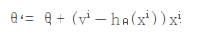
为了控制梯度下降的速度,引入步长

3. Spark 实现的梯度下降
spark实现在mlib库下org.apache.spark.mllib.optimization.GradientDescent类中
3.1 随机梯度?
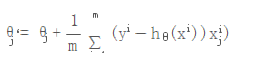
- 计算数据的梯度
- 根据梯度计算新的权重
3.2 计算梯度
- 先随机采样部分数据
data.sample(false, miniBatchFraction, 42 + i)
- 对部分数据样本进行聚合计算
treeAggregate((BDV.zeros[Double](n), 0.0, 0L))(
seqOp = (c, v) => {
// c: (grad, loss, count), v: (label, features)
val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1))
(c._1, c._2 + l, c._3 + 1)
},
combOp = (c1, c2) => {
// c: (grad, loss, count)
(c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3)
})
3.2.1 Spark 提供的计算梯度的方式
- LeastSquaresGradient 梯度,主要用于线型回归
- HingeGradient 梯度,用于SVM分类
- LogisticGradient 梯度,用于逻辑回归
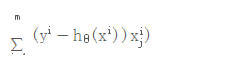
3.3 跟新权重theta θ
在梯度下降计算中,计算新的theta(也叫权重的更新),更新的算法由你采用的模型来决定
val update = updater.compute(
weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble),
stepSize, i, regParam)
- SimpleUpdater
- L1Updater
- SquaredL2Updater
3.3.1 SimpleUpdater
以SimpleUpdater来说:
SimpleUpdater extends Updater {
override def compute(
weightsOld: Vector,
gradient: Vector,
stepSize: Double,
iter: Int,
regParam: Double): (Vector, Double) = {
val thisIterStepSize = stepSize / math.sqrt(iter)
val brzWeights: BV[Double] = weightsOld.asBreeze.toDenseVector
brzAxpy(-thisIterStepSize, gradient.asBreeze, brzWeights)
(Vectors.fromBreeze(brzWeights), 0)
}
}
也就是上面提到的公式:

3.3.2 其它的正则参数化算法
- 和SimpleUpdater一样更新权重
- 将正则化参数乘以迭代步长的到比较参数:shrinkage
- 如果权重大于shrinkage,设置权重-shrinkage
- 如果权重小于-shrinkage,设置权重+shrinkage
- 其它的,设置权重为0
w' = w - thisIterStepSize * (gradient + regParam * w)
和SimpleUpdater比较,补偿了regParam*w ,这也是逻辑回归所采用的梯度下降算法的更新算法
4. 梯度下降收敛条件
- 迭代次数,当达到一定的迭代次数后,权重的值会被收敛到极值点,并且不会受到次数的影响
- 筏值:当两次迭代的权重之间的差小于指定的筏值的时候,就认为已经收敛
private def isConverged(
previousWeights: Vector,
currentWeights: Vector,
convergenceTol: Double): Boolean = {
// To compare with convergence tolerance.
val previousBDV = previousWeights.asBreeze.toDenseVector
val currentBDV = currentWeights.asBreeze.toDenseVector // This represents the difference of updated weights in the iteration.
val solutionVecDiff: Double = norm(previousBDV - currentBDV) solutionVecDiff < convergenceTol * Math.max(norm(currentBDV), 1.0)
}
当前后权重的差的L2,小于筏值*当前权重的L2和1的最大值,就认为下降结束。
5. Spark实现梯度下降的实现示例:
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf}
import org.apache.spark.mllib.linalg.{Vectors}
import org.apache.spark.mllib.optimization._ object SGDExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.set("spark.sql.broadcastTimeout", "10000")
conf.set("fs.defaultFS", "hdfs://abccluster")
val spark = SparkSession.builder().appName("hz_mlib").config(conf).enableHiveSupport().getOrCreate() /**
* 这里以简单的y=3*x+1为例来简单使用一下
* 测试数据就随意
* 1 0 1
* 7 2 1
* 10 3 1
* 4 1 1
* 19 6 1
**/
val list = List[scala.Tuple2[scala.Double, org.apache.spark.mllib.linalg.Vector]](
Tuple2(1d, Vectors.dense(0.0d, 1d)),
Tuple2(7d, Vectors.dense(2.0d, 1d)),
Tuple2(10d, Vectors.dense(3.0d, 1d)),
Tuple2(4d, Vectors.dense(1.0d, 1d)),
Tuple2(19d, Vectors.dense(6.0d, 1d))
) val data: org.apache.spark.rdd.RDD[scala.Tuple2[scala.Double, org.apache.spark.mllib.linalg.Vector]] = spark.sparkContext.parallelize(list) /**
* 而具体的实现梯度有
* LogisticGradient
* LeastSquaresGradient
* HingeGradient
* 对于更新也是三种实现
* SimpleUpdater
* L1Updater
* SquaredL2Updater
**/
var gradient = new LeastSquaresGradient()
var updater = new L1Updater() /**
* GradientDescent parameters default initialize values:
* private var stepSize: Double = 1.0
* private var numIterations: Int = 100
* private var regParam: Double = 0.0
* private var miniBatchFraction: Double = 1.0
* private var convergenceTol: Double = 0.001
*/
var stepSize = 1.0
var numIterations = 100
var regParam: Double = 0.0
var miniBatchFraction = 1.0
var initialWeights: org.apache.spark.mllib.linalg.Vector = Vectors.dense(0d, 0d)
var convergenceTol = 0.001
val (weights, _) = GradientDescent.runMiniBatchSGD(
data: org.apache.spark.rdd.RDD[scala.Tuple2[scala.Double, org.apache.spark.mllib.linalg.Vector]],
gradient: org.apache.spark.mllib.optimization.Gradient,
updater: org.apache.spark.mllib.optimization.Updater,
stepSize: scala.Double,
numIterations: scala.Int,
regParam: scala.Double,
miniBatchFraction: scala.Double,
initialWeights: org.apache.spark.mllib.linalg.Vector,
convergenceTol: scala.Double) println(weights) spark.stop()
}
}
输出测试结果:
scala> import org.apache.spark.mllib.linalg.{Vectors}
import org.apache.spark.mllib.linalg.Vectors
scala> import org.apache.spark.mllib.optimization._
import org.apache.spark.mllib.optimization._
scala> /**
| * 这里以简单的y=3*x+1为例来简单使用一下
| * 测试数据就随意
| * 1 0 1
| * 7 2 1
| * 10 3 1
| * 4 1 1
| * 19 6 1
| **/
| val list = List[scala.Tuple2[scala.Double, org.apache.spark.mllib.linalg.Vector]](
| Tuple2(1d, Vectors.dense(0.0d, 1d)),
| Tuple2(7d, Vectors.dense(2.0d, 1d)),
| Tuple2(10d, Vectors.dense(3.0d, 1d)),
| Tuple2(4d, Vectors.dense(1.0d, 1d)),
| Tuple2(19d, Vectors.dense(6.0d, 1d))
| )
list: List[(Double, org.apache.spark.mllib.linalg.Vector)] = List((1.0,[0.0,1.0]), (7.0,[2.0,1.0]), (10.0,[3.0,1.0]), (4.0,[1.0,1.0]), (19.0,[6.0,1.0]))
scala>
scala> val data: org.apache.spark.rdd.RDD[scala.Tuple2[scala.Double, org.apache.spark.mllib.linalg.Vector]] = spark.sparkContext.parallelize(list)
data: org.apache.spark.rdd.RDD[(Double, org.apache.spark.mllib.linalg.Vector)] = ParallelCollectionRDD[11460] at parallelize at <console>:37
scala>
scala> /**
| * 而具体的实现梯度有
| * LogisticGradient
| * LeastSquaresGradient
| * HingeGradient
| * 对于更新也是三种实现
| * SimpleUpdater
| * L1Updater
| * SquaredL2Updater
| **/
| var gradient = new LeastSquaresGradient()
gradient: org.apache.spark.mllib.optimization.LeastSquaresGradient = org.apache.spark.mllib.optimization.LeastSquaresGradient@7adb7d5b
scala> var updater = new L1Updater()
updater: org.apache.spark.mllib.optimization.L1Updater = org.apache.spark.mllib.optimization.L1Updater@33e6a825
scala>
scala> /**
| * GradientDescent parameters default initialize values:
| * private var stepSize: Double = 1.0
| * private var numIterations: Int = 100
| * private var regParam: Double = 0.0
| * private var miniBatchFraction: Double = 1.0
| * private var convergenceTol: Double = 0.001
| */
| var stepSize = 1.0
stepSize: Double = 1.0
scala> var numIterations = 100
numIterations: Int = 100
scala> var regParam: Double = 0.0
regParam: Double = 0.0
scala> var miniBatchFraction = 1.0
miniBatchFraction: Double = 1.0
scala> var initialWeights: org.apache.spark.mllib.linalg.Vector = Vectors.dense(0d, 0d)
initialWeights: org.apache.spark.mllib.linalg.Vector = [0.0,0.0]
scala> var convergenceTol = 0.001
convergenceTol: Double = 0.001
scala> val (weights, _) = GradientDescent.runMiniBatchSGD(
| data: org.apache.spark.rdd.RDD[scala.Tuple2[scala.Double, org.apache.spark.mllib.linalg.Vector]],
| gradient: org.apache.spark.mllib.optimization.Gradient,
| updater: org.apache.spark.mllib.optimization.Updater,
| stepSize: scala.Double,
| numIterations: scala.Int,
| regParam: scala.Double,
| miniBatchFraction: scala.Double,
| initialWeights: org.apache.spark.mllib.linalg.Vector,
| convergenceTol: scala.Double)
weights: org.apache.spark.mllib.linalg.Vector = [3.000248212261404,0.9997330919125574]
scala>
scala> println(weights)
[3.000248212261404,0.9997330919125574]
样例实现:参考《夜明的孤行灯 -》Spark中的梯度下降 -》 https://www.huangyunkun.com/2015/05/27/spark-gradient-descent/#comment-9317》
Spark MLib:梯度下降算法实现的更多相关文章
- Spark MLib完整基础入门教程
Spark MLib 在Spark下进行机器学习,必然无法离开其提供的MLlib框架,所以接下来我们将以本框架为基础进行实际的讲解.首先我们需要了解其中最基本的结构类型,即转换器.估计器.评估器和流水 ...
- 梯度下降算法的一点认识(Ng第一课)
昨天开始看Ng教授的机器学习课,发现果然是不错的课程,一口气看到第二课. 第一课 没有什么新知识,就是机器学习的概况吧. 第二课 出现了一些听不太懂的概念.其实这堂课主要就讲了一个算法,梯度下降算法. ...
- ng机器学习视频笔记(二) ——梯度下降算法解释以及求解θ
ng机器学习视频笔记(二) --梯度下降算法解释以及求解θ (转载请附上本文链接--linhxx) 一.解释梯度算法 梯度算法公式以及简化的代价函数图,如上图所示. 1)偏导数 由上图可知,在a点 ...
- 监督学习:随机梯度下降算法(sgd)和批梯度下降算法(bgd)
线性回归 首先要明白什么是回归.回归的目的是通过几个已知数据来预测另一个数值型数据的目标值. 假设特征和结果满足线性关系,即满足一个计算公式h(x),这个公式的自变量就是已知的数据x,函数值h(x)就 ...
- [机器学习Lesson3] 梯度下降算法
1. Gradient Descent(梯度下降) 梯度下降算法是很常用的算法,可以将代价函数J最小化.它不仅被用在线性回归上,也被广泛应用于机器学习领域中的众多领域. 1.1 线性回归问题应用 我们 ...
- AI-2.梯度下降算法
上节定义了神经网络中几个重要的常见的函数,最后提到的损失函数的目的就是求得一组合适的w.b 先看下损失函数的曲线图,如下 即目的就是求得最低点对应的一组w.b,而本节要讲的梯度下降算法就是会一步一步地 ...
- Logistic回归Cost函数和J(θ)的推导(二)----梯度下降算法求解最小值
前言 在上一篇随笔里,我们讲了Logistic回归cost函数的推导过程.接下来的算法求解使用如下的cost函数形式: 简单回顾一下几个变量的含义: 表1 cost函数解释 x(i) 每个样本数据点在 ...
- 梯度下降算法对比(批量下降/随机下降/mini-batch)
大规模机器学习: 线性回归的梯度下降算法:Batch gradient descent(每次更新使用全部的训练样本) 批量梯度下降算法(Batch gradient descent): 每计算一次梯度 ...
- tensorflow随机梯度下降算法使用滑动平均模型
在采用随机梯度下降算法训练神经网络时,使用滑动平均模型可以提高最终模型在测试集数据上的表现.在Tensflow中提供了tf.train.ExponentialMovingAverage来实现滑动平均模 ...
随机推荐
- 【BootStrap】 布局组件 II
BootStrap 布局组件 II ■ 分页 BS中通过.pagination的ul元素来实现一个分页集合,一个典型的分页如下: <ul class="pagination" ...
- 大数据 --> 安装Hadoop-单机模式(1)
安装Hadoop-单机模式(1) 一.在Ubuntu下创建hadoop组和hadoop用户 1)创建hadoop用户组 sudo addgroup hadoop //添加用户组 2)创建hadoop用 ...
- c++ --> extern "C" {}详解
extern "C" {}详解 extern "C"的真实目的是实现类C和C++的混合编程.在C++源文件中的语句前面加上extern "C" ...
- [poj2002]Squares_hash
Squares poj-2002 题目大意:在笛卡尔坐标系中给出n个点,求这些点可以构成多少个正方形. 注释:$1\le n\le 10^3$,$-2\cdot 10^3\le x , y\le 2\ ...
- 基于hi-nginx的web开发(python篇)——cookie和会话管理
hi-nginx通过redis管理会话. 要开启管理,需要做三件事. 第一件开启userid: userid on; userid_name SESSIONID; userid_domain loca ...
- 关于VR开发中的穿墙问题随想
在VR开发中,用户将以第一人称的视角进入虚拟世界,即用户同时身处两个坐标系:1. 现实世界坐标系(如房间的坐标系),用户的身体处于这个坐标系 2. VR世界坐标系,用户的感官处于这个坐标系,即用户觉得 ...
- 微信公众号报错 config:invalid signature
官方已经提供了微信 JS 接口签名校验工具(http://mp.weixin.qq.com/debug/cgi-bin/sandbox?t=jsapisign),填入相应的参数就能出来相应的signa ...
- spring框架学习笔记4:SpringAOP实现原理
AOP AOP(Aspect Oriented Programming),即面向切面编程,可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善.OOP引入 ...
- hibernate框架学习笔记6:事务
MySQL的事务.JDBC事务操作: 详细见这篇文章:比较详细 http://www.cnblogs.com/xuyiqing/p/8430214.html 如何在hibernate中配置隔离级别: ...
- 第四次团队作业:社团申请App
概要: 基于上次软件设计本着界面简洁.易于使用的初衷,进行功能的实现,代码位置:https://github.com/LinZezhong/testDemo 第一部分:软件的使用 注册: 登录: 主界 ...