【Python3爬虫】教你怎么利用免费代理搭建代理池
一、写在前面
有时候你的爬虫刚开始的时候可以正常运行,能够正常的爬取数据,但是过了一会,却出现了一个“403 Forbidden",或者是”您的IP访问频率太高“这样的提示,这就意味着你的IP被ban了,好一点的情况是过一段时间你就能继续爬取了,坏一点的情况就是你的IP已经进入别人的黑名单了,然后你的爬虫就GG了。怎么办呢?我们可以通过设置代理来解决,付费代理的效果自然不必多说,但是对于学习阶段的人来说,我觉得爬取网上的免费代理来用是一个更好的选择,而这一篇博客就将教你怎么利用免费代理搭建属于你自己的代理池。
二、目标分析
要搭建一个代理池,需要三个模块:存储模块、爬取模块和测试模块。
存储模块:负责存储我们爬取下来的代理,首先我们需要保证这些代理不能有重复的,然后我们还要对代理是否可用进行标记,这里可以使用Redis数据库的SortedSet(有序集合)进行存储。
爬取模块:负责对一些提供免费代理的网站进行爬取,代理的形式是IP+端口,爬取下来之后保存到数据库里。
测试模块:负责对代理池中的代理的可用性进行测试,由于测试出错不一定就表明代理不可用,可能是因为网络问题或者请求超时等等,所以我们可以设置一个分数标识,100分标识可用,分数越低标识可用性越低,当分数低于一个阈值之后,就从代理池中移除。
三、具体实现
1、存储模块
这里使用的是Redis的有序集合。Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员,不同的是每个元素都会关联一个double类型的分数,Redis正是通过分数来为集合中的成员进行从小到大的排序。这样我们保存到数据库中的元素就是一个代理和一个分数,比如112.17.65.133:8060和100,这就表示112.17.65.133:8060这个代理是可用的。
对于新添加到数据库中的代理,设置的初始分数为10,添加之后会进行一次测试,如果可用就把分数改为100表明可用,如果测试的结果是不可用就把分数减1,当分数减到0后就从代理池中移除。这么做的意义在于一次测试不可用并不能代表这个代理完全不可用,有可能在之后的某次测试中是可用的,这样我们就减小了将一个原本可用的代理从代理池中移除出去的概率。
当我们想要从代理池中获取一个代理的时候,优先从分数为100的代理中随机获取,如果一个100分的代理都没有,则对所有代理进行排序,然后随机获取一个代理。由于我们使用的是随机获取,这样就能保证代理池中的所有代理都有被获取的可能性。
现在我们需要定义一个类来实现这个有序集合,还需要设置一些方法来实现添加代理、修改分数、获取代理等功能。具体代码如下:
"""
Version: Python3.5
Author: OniOn
Site: http://www.cnblogs.com/TM0831/
Time: 2019/2/12 14:54
"""
import redis
import random MAX_SCORE = 100 # 最高分
MIN_SCORE = 0 # 最低分
INITIAL_SCORE = 10 # 初始分数
REDIS_HOST = "localhost"
REDIS_PORT = 6379 class RedisClient:
def __init__(self):
self.db = redis.Redis(host=REDIS_HOST, port=REDIS_PORT, db=0)
self.key = "proxies" def add(self, proxy, score=INITIAL_SCORE):
"""
将代理添加到代理池中
:param proxy: 代理
:param score: 分数
:return:
"""
if not self.is_exist(proxy):
self.db.zadd(self.key, proxy, score) def is_exist(self, proxy):
"""
判断代理池中是否存在该代理
:param proxy: 代理
:return: True or False
"""
if self.db.zscore(self.key, proxy):
return True
else:
return False def random(self):
"""
获取有效代理,先获取最高分代理,如果不存在,则按分数排名然后随机获取
:return: 代理
"""
result = self.db.zrangebyscore(self.key, MAX_SCORE, MAX_SCORE)
if len(result):
return random.choice(result)
else:
result = self.db.zrangebyscore(self.key, MIN_SCORE, MAX_SCORE)
if len(result):
return random.choice(result)
else:
print("代理池已空!") def decrease(self, proxy):
"""
代理分数减1分,若小于最低分,则从代理池中移除
:param proxy:
:return:
"""
if self.is_exist(proxy):
score = self.db.zscore(self.key, proxy)
if score > MIN_SCORE:
score -= 1
self.db.zadd(self.key, proxy, score)
else:
self.delete(proxy) def max(self, proxy):
"""
将代理分数设置为最高分
:param proxy: 代理
:return:
"""
if self.is_exist(proxy):
self.db.zadd(self.key, proxy, MAX_SCORE) def delete(self, proxy):
"""
从代理池中移除该代理
:param proxy: 代理
:return:
"""
if self.is_exist(proxy):
self.db.zrem(self.key, proxy) def all(self):
"""
获取代理池中的所有代理
:return:
"""
if self.count():
return self.db.zrange(self.key, MIN_SCORE, MAX_SCORE) def count(self):
"""
获取代理池中代理数量
:return:
"""
return self.db.zcard(self.key)
2、爬取模块
爬取模块比较简单,就是定义一个Crawler类来对一些提供免费代理的网站进行爬取。具体代码如下:
"""
Version: Python3.5
Author: OniOn
Site: http://www.cnblogs.com/TM0831/
Time: 2019/2/12 15:07
"""
import requests
from lxml import etree
from fake_useragent import UserAgent # 设置元类
class CrawlMetaClass(type):
def __new__(cls, name, bases, attrs):
attrs['__CrawlFuncCount__'] = 0
attrs['__CrawlFunc__'] = []
for k, v in attrs.items():
if 'crawl_' in k:
attrs['__CrawlFunc__'].append(k)
attrs['__CrawlFuncCount__'] += 1
# attrs['__CrawlFuncCount__'] = count
return type.__new__(cls, name, bases, attrs) class Crawler(object, metaclass=CrawlMetaClass):
def __init__(self):
self.proxies = [] # 代理列表
ua = UserAgent() # 使用随机UA
self.headers = {
"UserAgent": ua.random
} def get_proxies(self, callback):
"""
运行各个代理爬虫
:param callback: crawl函数名称
:return:
"""
for proxy in eval("self.{}()".format(callback)):
print("成功获取代理:", proxy)
self.proxies.append(proxy)
return self.proxies def crawl_kdd(self):
"""
快代理爬虫
:return:
"""
urls = ["https://www.kuaidaili.com/free/inha/{}/".format(i) for i in range(1, 4)]
for url in urls:
res = requests.get(url, headers=self.headers)
try:
et = etree.HTML(res.text)
ip_list = et.xpath('//*[@data-title="IP"]/text()')
port_list = et.xpath('//*[@data-title="PORT"]/text()')
for ip, port in zip(ip_list, port_list):
yield ip + ":" + port
except Exception as e:
print(e) def crawl_89ip(self):
"""
89IP爬虫
:return:
"""
urls = ["http://www.89ip.cn/index_{}.html".format(i) for i in range(1, 4)]
for url in urls:
res = requests.get(url, headers=self.headers)
try:
et = etree.HTML(res.text)
ip_list = et.xpath('//*[@class="layui-table"]/tbody/tr/td[1]/text()')
port_list = et.xpath('//*[@class="layui-table"]/tbody/tr/td[2]/text()')
ip_list = [i.strip() for i in ip_list]
port_list = [i.strip() for i in port_list]
for ip, port in zip(ip_list, port_list):
yield ip + ":" + port
except Exception as e:
print(e) def crawl_xc(self):
"""
西刺代理爬虫
:return:
"""
url = "https://www.xicidaili.com/?t=253"
res = requests.get(url, headers=self.headers)
try:
et = etree.HTML(res.text)
ip_list = et.xpath('//*[@id="ip_list"]/tr[3]/td[2]/text()')
port_list = et.xpath('//*[@id="ip_list"]/tr[3]/td[3]/text()')
for ip, port in zip(ip_list, port_list):
yield ip + ":" + port
except Exception as e:
print(e)
可以看到几个爬虫的方法名称都是以crawl开头的,主要是为了方便,如果要添加新的爬虫就只用添加crawl开头的方法即可。
这里我写了爬取快代理、89IP代理和西刺代理的爬虫,都是用xpath进行解析,也都定义了一个生成器,然后用yield返回爬取到的代理。然后定义了一个get_proxies()方法,将所有以crawl开头的方法都调用一遍,获取每个方法返回的结果并生成一个代理列表,最后返回这个代理列表。那么如何获取crawl开头的方法呢?这里借用了元类来实现。首先定义一个类CrawlMetaClass,然后实现了__new__()方法,这个方法的第四个参数attrs里包含了类的一些属性,所以我们可以遍历attrs中包含的信息,就像遍历一个字典一样,如果方法名以crawl开头,就将其添加到__CrawlFunc__中,这样我们就能获取crawl开头的方法了。
我们已经定义好了爬取的方法了,但是还需要定义一个类来执行这些方法,这里可以定义一个GetProxy类来实现爬取代理并保存到代理池中,具体代码如下:
"""
Version: Python3.5
Author: OniOn
Site: http://www.cnblogs.com/TM0831/
Time: 2019/2/14 12:19
"""
from ProxyPool.crawl import Crawler
from ProxyPool.pool import RedisClient class GetProxy:
def __init__(self):
self.crawler = Crawler()
self.redis = RedisClient() def get_proxy(self):
"""
运行爬虫爬取代理
:return:
"""
print("[INFO]Crawl Start...")
count = 0
for callback_label in range(self.crawler.__CrawlFuncCount__):
callback = self.crawler.__CrawlFunc__[callback_label]
# 获取代理
proxies = self.crawler.get_proxies(callback)
for proxy in proxies:
self.redis.add(proxy)
count += len(proxies)
print("此次爬取的代理数量为:{}".format(count))
print("[INFO]Crawl End...\n\n")
3、测试模块
我们已经将代理成功爬取下来并保存到代理池中了,但是我们还需要对代理的可用性进行测试。测试的方法就是使用requests库设置代理并发送请求,如果请求成功并且返回的状态码是200的话,就表明这个代理是可用的,然后我们就要将该代理的分数设置为100,反之如果出现请求失败、请求超时或者返回的状态码不是200的话, 就要将该代理的分数减1,如果分数等于0了,就要从代理池中移除。
这里可以定义一个TestProxy类来实现,具体代码如下:
"""
Version: Python3.5
Author: OniOn
Site: http://www.cnblogs.com/TM0831/
Time: 2019/2/14 14:24
"""
import time
import random
import requests
from fake_useragent import UserAgent
from ProxyPool.crawl import Crawler
from ProxyPool.pool import RedisClient class TestProxy:
def __init__(self):
self.crawler = Crawler()
self.redis = RedisClient()
ua = UserAgent() # 使用随机UA
self.headers = {
"UserAgent": ua.random
} def test(self):
"""
测试函数,测试代理池中的代理
:return:
"""
proxy_list = self.redis.all()
proxy_list = [i.decode('utf-8') for i in proxy_list] # 字节型转字符串型 print("[INFO]Test Start...")
for proxy in proxy_list:
self.request(proxy)
print("[INFO]Test End...\n\n") def request(self, proxy):
"""
测试请求函数
:param proxy:
:return:
"""
print("当前测试代理:{} 该代理分数为:{}".format(proxy, self.redis.db.zscore(self.redis.key, proxy)))
time.sleep(random.randint(1, 4))
try:
url = "https://www.baidu.com/"
proxies = {
"https": "https://" + proxy
}
res = requests.get(url, headers=self.headers, proxies=proxies, timeout=5) if res.status_code == 200:
print("代理可用,分数设置为100")
self.redis.max(proxy)
else:
print("错误的请求状态码,分数减1")
self.redis.decrease(proxy)
except:
print("代理请求失败,分数减1")
self.redis.decrease(proxy)
四、运行程序
这里我定义了一个Main类来实现,过程为先爬取代理,然后对代理池中的代理进行测试,最后从代理池中获取一个可用代理。具体代码如下:
"""
Version: Python3.5
Author: OniOn
Site: http://www.cnblogs.com/TM0831/
Time: 2019/2/14 14:26
"""
from ProxyPool.pool import RedisClient
from ProxyPool.get import GetProxy
from ProxyPool.test import TestProxy class Main:
def __init__(self):
self.gp = GetProxy()
self.tp = TestProxy()
self.db = RedisClient() def run(self):
"""
运行的主函数,先爬取代理,然后测试,最后获取一个有效代理
:return:
"""
self.gp.get_proxy()
self.tp.test()
proxy = self.db.random()
proxy = proxy.decode('utf-8')
print("从代理池中取出的代理为:{}".format(proxy)) if __name__ == '__main__':
m = Main()
m.run()
运行结果截图如下:
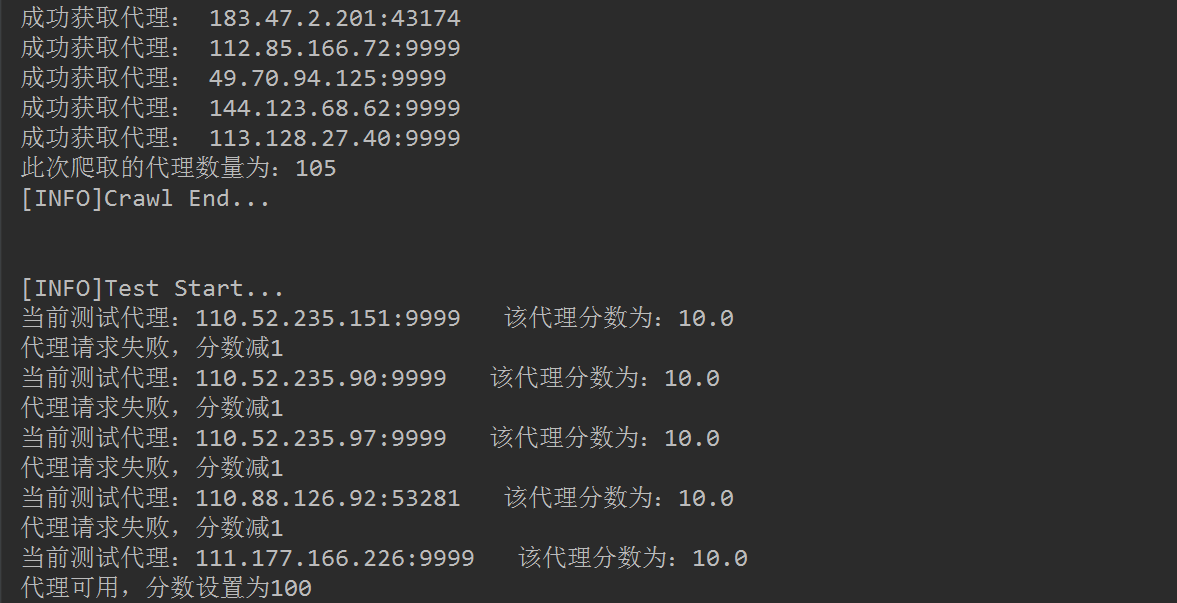
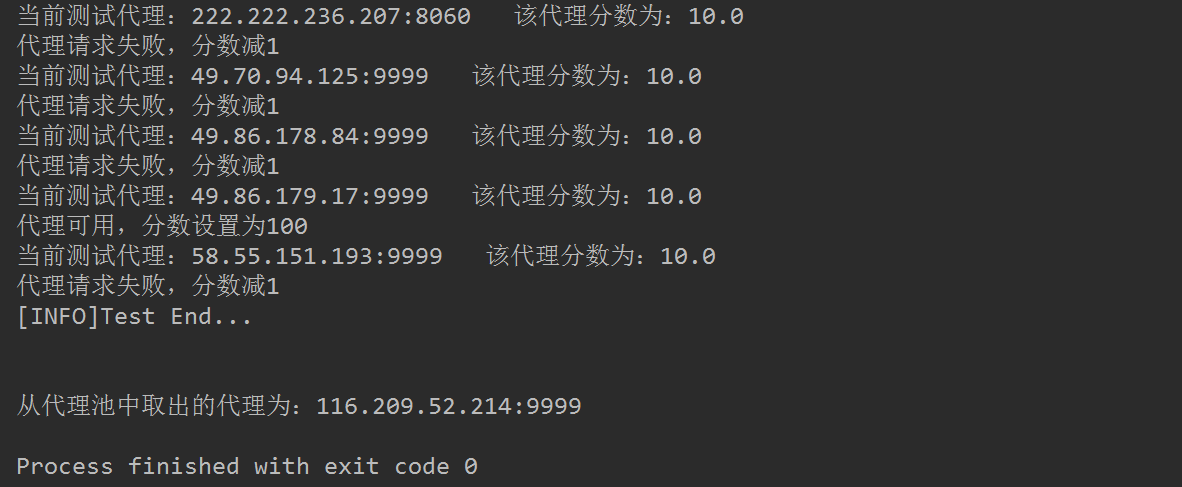
完整代码已上传到GitHub!
【Python3爬虫】教你怎么利用免费代理搭建代理池的更多相关文章
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- Python3爬虫实例 代理的使用
现在爬虫越来越难了,一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会会禁止这个IP的访问. 所以我们需要设置一些代理服 ...
- 记一次企业级爬虫系统升级改造(六):基于Redis实现免费的IP代理池
前言: 首先表示抱歉,春节后一直较忙,未及时更新该系列文章. 近期,由于监控的站源越来越多,就偶有站源做了反爬机制,造成我们的SupportYun系统小爬虫服务时常被封IP,不能进行数据采集. 这时候 ...
- 手把手教你如何利用 HeroKu 免费获取一个 Scrapyd 集群
手把手教你如何利用 HeroKu 免费获取一个 Scrapyd 集群 本文原始地址:https://sitoi.cn/posts/48724.html 准备环境 一个 GitHub 的账号 一个 He ...
- 【Python3爬虫】用Python中的队列来写爬虫
一.写在前面 当你看着你的博客的阅读量慢慢增加的时候,内心不禁有了些小激动,但是不得不吐槽一下--博客园并不会显示你的博客的总阅读量是多少.而这一篇博客就将教你怎么利用队列这种结构来编写爬虫,最终获取 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- Python获取免费的可用代理
Python获取免费的可用代理 在使用爬虫多次爬取同一站点时,常常会被站点的ip反爬虫机制给禁掉,这时就能够通过使用代理来解决.眼下网上有非常多提供最新免费代理列表的站点.这些列表里非常多的代理主机是 ...
- Python爬虫开发【第1篇】【代理】
1.简单的自定义opener() import urllib2 # 构建一个HTTPHandler 处理器对象,支持处理HTTP请求 http_handler = urllib2.HTTPHandle ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
随机推荐
- Spring Boot中使用MyBatis注解配置详解(1)
之前在Spring Boot中整合MyBatis时,采用了注解的配置方式,相信很多人还是比较喜欢这种优雅的方式的,也收到不少读者朋友的反馈和问题,主要集中于针对各种场景下注解如何使用,下面就对几种常见 ...
- [NOIP2002]字串变换 T2 双向BFS
题目描述 已知有两个字串 A,B 及一组字串变换的规则(至多6个规则): A1−>B1 A2−>B2 规则的含义为:在 A$中的子串 A1可以变换为可以变换为B1.A2可以变换为可 ...
- 新手教程:不写JS,在MIP页中实现异步加载数据
从需求谈起:在 MIP 页中异步加载数据 MIP(移动网页加速器) 的 加速原理 除了靠谱的 MIP-Cache CDN 加速外,最值得一提的就是组件系统.所有 JS 交互都需要使用 MIP 组件实现 ...
- 【STM32H7教程】第9章 STM32H7重要知识点数据类型,变量和堆栈
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980 第9章 STM32H7重要知识点数据类型,变量和堆栈 ...
- kubernetes实践之三:深入理解Pod对象
一.Pod定义 最小部署单元 一组容器集合 一个pod中的容器共享网络命名空间 Pod是短暂的 二.Pod容器分类 基础容器 维护整个Pod的网络命名空间 初始化容器 先于业务容器开始执行,在应用启动 ...
- 5.1基于JWT的认证和授权「深入浅出ASP.NET Core系列」
希望给你3-5分钟的碎片化学习,可能是坐地铁.等公交,积少成多,水滴石穿,码字辛苦,如果你吃了蛋觉得味道不错,希望点个赞,谢谢关注. Cookie-Based认证 认证流程 我们先看下传统Web端的认 ...
- 异步多线程 Async
进程:进程是一个程序在电脑运行时,全部资源的合集叫进程 线程:是程序的最小执行单位,包含计算资源,任何一个操作的响应都是线程完成的. 多线程:多个线程并发执行 Thread 是.net框架封装 ...
- mybatis一对一 和 一对多 嵌套查询
实际项目中的,接口对外VO 会出现 一对一 和 一对多的情况,举例:小区 下面有 楼栋 ,楼栋 下面有 房屋 , 房屋里面又房间 小区Vo : districtVo { id: nam ...
- 简述Java变量和强制转换类型
简述Java变量和强制转换类型 java变量 1. java变量 变量:顾名思义,就是在java执行程序过程中可以发生改变的量,就好比方程式中的未知数X一样. 变量的内存分配过程 int a ; // ...
- WordPress怎样设置菜单栏旋转小图标
最近我在浏览别的博客的文章时,无意间发现了一个很好看的小装饰.那就是在WordPress菜单栏上的小图标.于是我研究了研究,弄到了设置方法之后决定把它分享出来. 菜单栏的小图标 设置步骤: 1, 我们 ...