机器学习实战笔记(Python实现)-09-树回归
----------------------------------------------------------------------------------------
本系列文章为《机器学习实战》学习笔记,内容整理自书本,网络以及自己的理解,如有错误欢迎指正。
源码在Python3.5上测试均通过,代码及数据 --> https://github.com/Wellat/MLaction
----------------------------------------------------------------------------------------
1、连续和离散型特征的树的构建
决策树算法主要是不断将数据切分成小数据集,直到所有目标变量完全相同,或者数据不能再切分为止。它是一种贪心算法,并不考虑能否达到全局最优。前面介绍的用ID3构建决策树的算法每次选取当前最佳的特征来分割数据,并按照该特征的所有可能取值来划分,这种切分过于迅速,且不能处理连续性特征。另外一种方法是二元切分法,每次把数据集切成两份,如果数据的某特征等于切分所要求的值,那么这些数据就进入树的左子树,反之右子树。二元切分法可处理连续型特征,节省树的构建时间。
这里依然使用字典来存储树的数据结构,该字典将包含以下4个元素:
- 待切分的特征
- 待切分的特征值
- 右子树,不需切分时,也可是单个值
- 左子树,右子树类似
本章将构建两种树:第一种是第2节的回归树(regression tree),其每个叶节点包含单个值;第二种是第3节的模型树(model tree),其每个叶节点包含一个线性方程。创建这两种树时,我们将尽量使得代码之间可以重用。下面先给出两种树构建算法中的一些共用代码。
- from numpy import *
- def loadDataSet(fileName):
- '''
- 读取一个一tab键为分隔符的文件,然后将每行的内容保存成一组浮点数
- '''
- dataMat = []
- fr = open(fileName)
- for line in fr.readlines():
- curLine = line.strip().split('\t')
- fltLine = map(float,curLine)
- dataMat.append(fltLine)
- return dataMat
- def binSplitDataSet(dataSet, feature, value):
- '''
- 数据集切分函数
- '''
- mat0 = dataSet[nonzero(dataSet[:,feature] > value)[0],:]
- mat1 = dataSet[nonzero(dataSet[:,feature] <= value)[0],:]
- return mat0,mat1
- def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
- '''
- 树构建函数
- leafType:建立叶节点的函数
- errType:误差计算函数
- ops:包含树构建所需其他参数的元组
- '''
- #选择最优的划分特征
- #如果满足停止条件,将返回None和某类模型的值
- #若构建的是回归树,该模型是一个常数;如果是模型树,其模型是一个线性方程
- feat, val = chooseBestSplit(dataSet, leafType, errType, ops)
- if feat == None: return val #
- retTree = {}
- retTree['spInd'] = feat
- retTree['spVal'] = val
- #将数据集分为两份,之后递归调用继续划分
- lSet, rSet = binSplitDataSet(dataSet, feat, val)
- retTree['left'] = createTree(lSet, leafType, errType, ops)
- retTree['right'] = createTree(rSet, leafType, errType, ops)
- return retTree
2、CART回归树
CART(Classification And Regression Trees, 分类回归树)是十分著名的树构建算法,它使用二元切分来处理连续性变量,对其稍作修改就可处理回归问题。
2.1 构建树
①切分数据集并生成叶节点
给定某个误差计算方法,chooseBestSplit()函数会找到数据集上最佳的二元切分方式,此外,该函数还要确定什么时候停止切分,一旦停止切分会生成一个叶节点。该函数伪代码大致如下:

②计算误差
这里采用计算数据的平方误差。
Python代码:
- def regLeaf(dataSet):
- '''负责生成叶节点'''
- #当chooseBestSplit()函数确定不再对数据进行切分时,将调用本函数来得到叶节点的模型。
- #在回归树中,该模型其实就是目标变量的均值。
- return mean(dataSet[:,-1])
- def regErr(dataSet):
- '''
- 误差估计函数,该函数在给定的数据上计算目标变量的平方误差,这里直接调用均方差函数
- '''
- return var(dataSet[:,-1]) * shape(dataSet)[0]#返回总方差
- def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
- '''
- 用最佳方式切分数据集和生成相应的叶节点
- '''
- #ops为用户指定参数,用于控制函数的停止时机
- tolS = ops[0]; tolN = ops[1]
- #如果所有值相等则退出
- if len(set(dataSet[:,-1].T.tolist()[0])) == 1:
- return None, leafType(dataSet)
- m,n = shape(dataSet)
- S = errType(dataSet)
- bestS = inf; bestIndex = 0; bestValue = 0
- #在所有可能的特征及其可能取值上遍历,找到最佳的切分方式
- #最佳切分也就是使得切分后能达到最低误差的切分
- for featIndex in range(n-1):
- for splitVal in set(dataSet[:,featIndex]):
- mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
- if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): continue
- newS = errType(mat0) + errType(mat1)
- if newS < bestS:
- bestIndex = featIndex
- bestValue = splitVal
- bestS = newS
- #如果误差减小不大则退出
- if (S - bestS) < tolS:
- return None, leafType(dataSet)
- mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
- #如果切分出的数据集很小则退出
- if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN):
- return None, leafType(dataSet)
- #提前终止条件都不满足,返回切分特征和特征值
- return bestIndex,bestValue
主要测试命令:
- >>> reload(regTrees)
- >>> myData = regTrees.loadDataSet('ex00.txt')
- >>> myMat = mat(myData)
- >>> regTrees.createTree(myMat)
【注意】本代码在Python3.5环境下测试未通过,错误发生在以上第5行-->return mean(dataSet[:,-1])
错误类型为 TypeError: unsupported operand type(s) for /: 'map' and 'int' 暂未找到解决办法。所以,以下测试结果均来自书本。
2.2 剪枝
一棵树如果节点过多,表明该模型可能对数据进行了“过拟合”。通过降低决策树的复杂度来避免过拟合的过程称为剪枝(pruning) 。
①预剪枝
在函数chooseBestSplit()中的提前终止条件,实际上是在进行一种所谓的预剪枝(prepruning)操作。树构建算法其实对输人的参数tols和tolN非常敏感,如果使用其他值将不太容易达到这么好的效果。
②后剪枝
使用后剪枝方法需要将数据集分成测试集和训练集。首先指定参数,使得构建出的树足够大、足够复杂,便于剪枝。接下来从上而下找到叶节点,用测试集来判断将这些叶节点合并是否能降低测试误差。如果是的话就合并 。
Python实现代码:
- def prune(tree, testData):
- '''回归树剪枝函数'''
- if shape(testData)[0] == 0: return getMean(tree) #无测试数据则返回树的平均值
- if (isTree(tree['right']) or isTree(tree['left'])):#
- lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
- if isTree(tree['left']): tree['left'] = prune(tree['left'], lSet)
- if isTree(tree['right']): tree['right'] = prune(tree['right'], rSet)
- #如果两个分支已经不再是子树,合并它们
- #具体做法是对合并前后的误差进行比较。如果合并后的误差比不合并的误差小就进行合并操作,反之则不合并直接返回
- if not isTree(tree['left']) and not isTree(tree['right']):
- lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
- errorNoMerge = sum(power(lSet[:,-1] - tree['left'],2)) +\
- sum(power(rSet[:,-1] - tree['right'],2))
- treeMean = (tree['left']+tree['right'])/2.0
- errorMerge = sum(power(testData[:,-1] - treeMean,2))
- if errorMerge < errorNoMerge:
- print("merging")
- return treeMean
- else: return tree
- def isTree(obj):
- '''判断输入变量是否是一棵树'''
- return (type(obj).__name__=='dict')
- def getMean(tree):
- '''从上往下遍历树直到叶节点为止,计算它们的平均值'''
- if isTree(tree['right']): tree['right'] = getMean(tree['right'])
- if isTree(tree['left']): tree['left'] = getMean(tree['left'])
- return (tree['left']+tree['right'])/2.0
测试命令:
- reload(regTrees)
- myData2 = regTrees.loadDataSet('ex2.txt')
- myMat2 = mat(myData2)
- from numpy import *
- myMat2 = mat(myData2)
- regTrees.createTree(myMat2)
- myTree = regTrees.createTree(myMat2, ops=(0,1))
- myDataTest = regTrees.loadDataSet('ex2test.txt')
- myMat2Test = mat(myDataTest)
- regTrees.prune(myTree, myMat2Test)
3、模型树
①叶节点
用树建模,除了把叶节点简单地设定为常数值外,还可把叶节点设定为分段线性函数,这里的分段线性是指模型由多个线性片段组成。
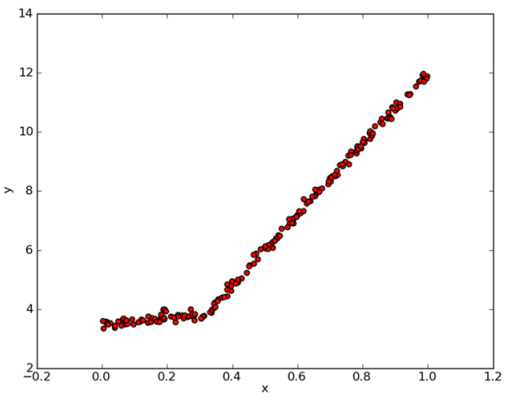
如下图所示数据,如果使用两条直线拟合是否比使用一组常数来建模好呢?答案显而易见。可以设计两条分别从0.0~0.3、从0.3~1.0的直线,于是就可以得到两个线性模型。因为数据集里的一部分数据(0.0~0.3)以某个线性模型建模,而另一部分数据(0.3~1.0)则以另一个线性模型建模,因此我们说采用了所谓的分段线性模型。
②误差计算
前面用于回归树的误差计算方法这里不能再用。稍加变化,对于给定的数据集,先用线性的模型来对它进行拟合,然后计算真实的目标值与模型预测值间的差值。最后将这些差值的平方求和就得到了所需的误差。
与回归树不同,模型树Python代码有以下变化:
- def linearSolve(dataSet):
- '''将数据集格式化成目标变量Y和自变量X,X、Y用于执行简单线性回归'''
- m,n = shape(dataSet)
- X = mat(ones((m,n))); Y = mat(ones((m,1)))
- X[:,1:n] = dataSet[:,0:n-1]; Y = dataSet[:,-1]#默认最后一列为Y
- xTx = X.T*X
- #若矩阵的逆不存在,抛异常
- if linalg.det(xTx) == 0.0:
- raise NameError('This matrix is singular, cannot do inverse,\n\
- try increasing the second value of ops')
- ws = xTx.I * (X.T * Y)#回归系数
- return ws,X,Y
- def modelLeaf(dataSet):
- '''负责生成叶节点模型'''
- ws,X,Y = linearSolve(dataSet)
- return ws
- def modelErr(dataSet):
- '''误差计算函数'''
- ws,X,Y = linearSolve(dataSet)
- yHat = X * ws
- return sum(power(Y - yHat,2))
测试命令:
- >>> regTrees.createTree(myMat,regTrees.modelLeaf,regTrees.modelErr.(1,10))
4、实例:树回归与标准回归的比较
前面介绍了模型树、回归树和一般的回归方法,下面测试一下哪个模型最好。这些模型将在某个数据上进行测试,该数据涉及人的智力水平和自行车的速度的关系。
- def createForeCast(tree, testData, modelEval=regTreeEval):
- # 多次调用treeForeCast()函数,以向量形式返回预测值,在整个测试集进行预测非常有用
- m=len(testData)
- yHat = mat(zeros((m,1)))
- for i in range(m):
- yHat[i,0] = treeForeCast(tree, mat(testData[i]), modelEval)
- return yHat
- def treeForeCast(tree, inData, modelEval=regTreeEval):
- '''
- # 在给定树结构的情况下,对于单个数据点,该函数会给出一个预测值。
- # modeEval是对叶节点进行预测的函数引用,指定树的类型,以便在叶节点上调用合适的模型。
- # 此函数自顶向下遍历整棵树,直到命中叶节点为止,一旦到达叶节点,它就会在输入数据上
- # 调用modelEval()函数,该函数的默认值为regTreeEval()
- '''
- if not isTree(tree): return modelEval(tree, inData)
- if inData[tree['spInd']] > tree['spVal']:
- if isTree(tree['left']): return treeForeCast(tree['left'], inData, modelEval)
- else: return modelEval(tree['left'], inData)
- else:
- if isTree(tree['right']): return treeForeCast(tree['right'], inData, modelEval)
- else: return modelEval(tree['right'], inData)
- def regTreeEval(model, inDat):
- #为了和modeTreeEval()保持一致,保留两个输入参数
- return float(model)
- def modelTreeEval(model, inDat):
- #对输入数据进行格式化处理,在原数据矩阵上增加第0列,元素的值都是1
- n = shape(inDat)[1]
- X = mat(ones((1,n+1)))
- X[:,1:n+1]=inDat
- return float(X*model)
测试命令:
- #回归树
- >>> reload(regTrees)
- >>> trainMat = mat(regTrees.loadDataSet('bikeSpeedVsIq_train.txt'))
- >>> testMat = mat(regTrees.loadDataSet('bikeSpeedVsIq_test.txt'))
- >>> myTree = regTrees.createTree(trainMat, ops=(1,20))
- >>> yHat = regTrees.createForeCast(myTree, testMat[:,0])
- >>> corrcoef(yHat, testMat[:,1], rowvar=0)
- array([[ 1. , 0.96408523],
- [ 0.96408523, 1. ]])
- #模型树
- >>> myTree = regTrees.createTree(trainMat, regTrees.modelLeaf, regTrees.modelErr
- , (1,20))
- >>> yHat = regTrees.createForeCast(myTree, testMat[:,0], regTrees.modelTreeEval)
- >>> corrcoef(yHat, testMat[:,1], rowvar=0)[0,1]
- 0.97604121913806285
- # 标准回归
- >>> ws, X, Y = regTrees.linearSolve(trainMat)
- >>> ws
- matrix([[ 37.58916794],
- [ 6.18978355]])
- >>> for i in range(shape(testMat)[0]) :
- ... yHat[i] = testMat[i,0]*ws[1,0] + ws[0,0]
- ...
- >>> corrcoef(yHat, testMat[:,1], rowvar=0)[0,1]
- 0.94346842356747584
THE END.
机器学习实战笔记(Python实现)-09-树回归的更多相关文章
- 机器学习实战笔记(Python实现)-08-线性回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-04-Logistic回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-02-决策树
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-05-支持向量机(SVM)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-06-AdaBoost
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-03-朴素贝叶斯
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-00-readme
近期学习机器学习,找到一本不错的教材<机器学习实战>.特此做这份学习笔记,以供日后翻阅. 机器学习算法分为有监督学习和无监督学习.这本书前两部分介绍的是有监督学习,第三部分介绍的是无监督学 ...
- 【机器学习实战】第9章 树回归(Tree Regression)
第9章 树回归 <script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/ ...
随机推荐
- aforge 学习-命名空间中文理解
序列 名称 介绍 1 Aforge AForge AForge名称空间的核心名称空间.微软网络框架,其中包含核心类所使用的其他框架的命名空间和类,可以独立用于各种用途. 2 AForge.Cont ...
- hdu 2045 递推
从n>=4开始考虑,只考虑n-1和1的颜色是否相等情况.推出公式F(n)=F(n-1)+2*F(n-2) AC代码: #include<cstdio> const int maxn= ...
- c# 委托(Func、Action)
以前自己写委托都用 delegate, 最近看组里的大佬们都用 Func , 以及 Action 来实现, 代码简洁了不少, 但是看得我晕晕乎乎. 花点时间研究一下,记录一下,以便后期的查阅. 1.F ...
- Win10电脑经常自动掉线、自动断网的解决方法
近期一客户称自己使用电脑上网的时候,过一段时间莫名其妙的出现自动掉线.自动断网的情况,那么遇到这个问题该怎么办?下面装机之家分享一下Win10电脑经常自动掉线.自动断网的解决方法,以Win7系统为例. ...
- R语言学习笔记︱Echarts与R的可视化包——地区地图
笔者寄语:感谢CDA DSC训练营周末上完课,常老师.曾柯老师加了小课,讲了echart与R结合的函数包recharts的一些基本用法.通过对比谢益辉老师GitHub的说明文档,曾柯老师极大地简化了一 ...
- 视频显示格式720p
720p是一种视频显示格式.字母p意为逐行扫描(progressive scan),数字720则表示水平方向有720条扫描线. 通常720p的画面分辨率为1280×720,一般亦可称为高画质(HD). ...
- bootrom的构成
bootrom的构成 在开发阶段,VxWorks 操作系统大多采用bootrom+ VxWorks 方式启动,即下载型方式进行.一方面,由于VxWorks本身调试的需要,另一方面,bootrom相比V ...
- Vxworks驱动程序的结构
驱动程序的结构包括三个部分:初始化部分,函数功能部分和中断服务程序ISR.初始化部分初始化硬件,分配设备所需的资源,完成所有与系统相关的设置.如果是字符设备,首先调用iosDrvlnstall()来安 ...
- [Err] 1136 - Column count doesn't match value count at row 1
1 错误描述 [Err] 1136 - Column count doesn't match value count at row 1 Procedure execution failed 1136 ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...