亿级流量场景下,大型架构设计实现【全文检索高级搜索---ElasticSearch篇】-- 中
1、Elasticsearch的基础分布式架构:
1、Elasticsearch对复杂分布式机制的透明隐藏特性
2、Elasticsearch的垂直扩容与水平扩容
3、增减或减少节点时的数据rebalance
4、master节点
5、节点对等的分布式架构
--------------------------------------------------------------------------------------------------------------------
1、Elasticsearch对复杂分布式机制的透明隐藏特性
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量
隐藏了复杂的分布式机制
分片机制(我们之前随随便便就将一些document插入到es集群中去了,我们有没有care过数据怎么进行分片的,数据到哪个shard中去)
cluster discovery(集群发现机制,我们之前在做那个集群status从yellow转green的实验里,直接启动了第二个es进程,那个进程作为一个node自动就发现了集群,并且加入了进去,还接受了部分数据,replica shard)
shard负载均衡(举例,假设现在有3个节点,总共有25个shard要分配到3个节点上去,es会自动进行均匀分配,以保持每个节点的均衡的读写负载请求)
shard副本,请求路由,集群扩容,shard重分配
--------------------------------------------------------------------------------------------------------------------
2、Elasticsearch的垂直扩容与水平扩容
垂直扩容:采购更强大的服务器,成本非常高昂,而且会有瓶颈,假设世界上最强大的服务器容量就是10T,但是当你的总数据量达到5000T的时候,你要采购多少台最强大的服务器啊
水平扩容:业界经常采用的方案,采购越来越多的普通服务器,性能比较一般,但是很多普通服务器组织在一起,就能构成强大的计算和存储能力
普通服务器:1T,1万,100万
强大服务器:10T,50万,500万
扩容对应用程序的透明性
--------------------------------------------------------------------------------------------------------------------
3、增减或减少节点时的数据rebalance
保持负载均衡
--------------------------------------------------------------------------------------------------------------------
4、master节点
(1)创建或删除索引
(2)增加或删除节点
--------------------------------------------------------------------------------------------------------------------
5、节点平等的分布式架构
(1)节点对等,每个节点都能接收所有的请求
(2)自动请求路由
(3)响应收集
************************************************ 示例图 ******************************************
2、shard&replica机制再次梳理以及单个或者两个node环境中创建index图解
1、shard&replica机制再次梳理
2、图解单node环境下创建index是什么样子的
------------------------------------------------------------------------------------------------
1、shard&replica机制再次梳理
(1)index包含多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
------------------------------------------------------------------------------------------------
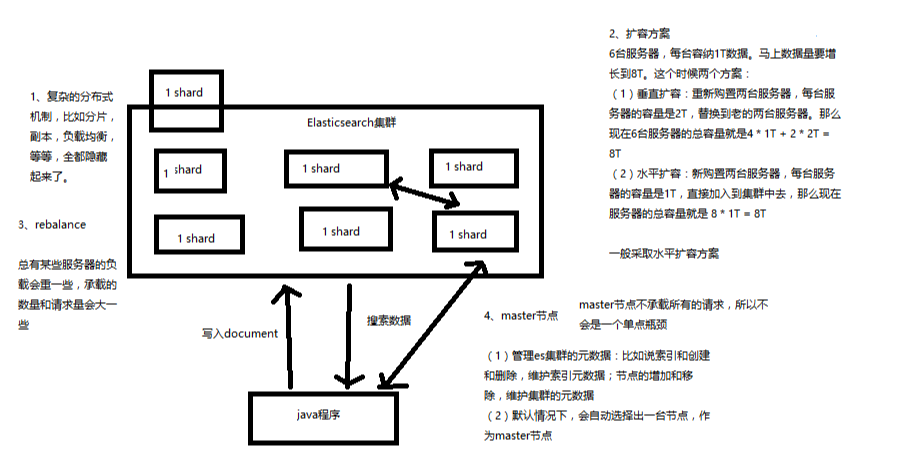
2、图解单node环境下创建index是什么样子的
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
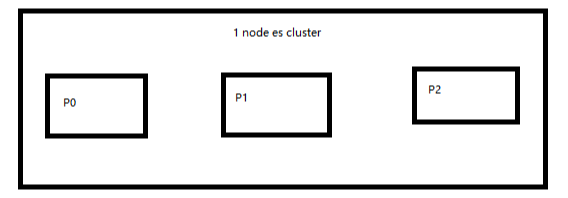
2、图解2个node环境下replica shard是如何分配的
(1)replica shard分配:3个primary shard,3个replica shard,1 node
(2)primary ---> replica同步
(3)读请求:primary/replica
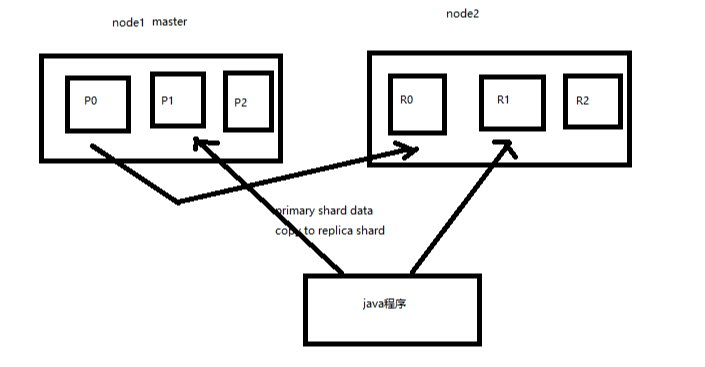
3、图解横向扩容过程,如何超出扩容极限,以及如何提升容错性
(1)primary&replica自动负载均衡,6个shard,3 primary,3 replica
(2)每个node有更少的shard,IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好
(3)扩容的极限,6个shard(3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好
(4)超出扩容极限,动态修改replica数量,9个shard(3primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量
(5)3台机器下,9个shard(3 primary,6 replica),资源更少,但是容错性更好,最多容纳2台机器宕机,6个shard只能容纳0台机器宕机
(6)这里的这些知识点,你综合起来看,就是说,一方面告诉你扩容的原理,怎么扩容,怎么提升系统整体吞吐量;另一方面要考虑到系统的容错性,怎么保证提高容错性,让尽可能多的服务器宕机,保证数据不丢失
*********************************************************** 扩容过程图 --------------> 自动进行负载均衡
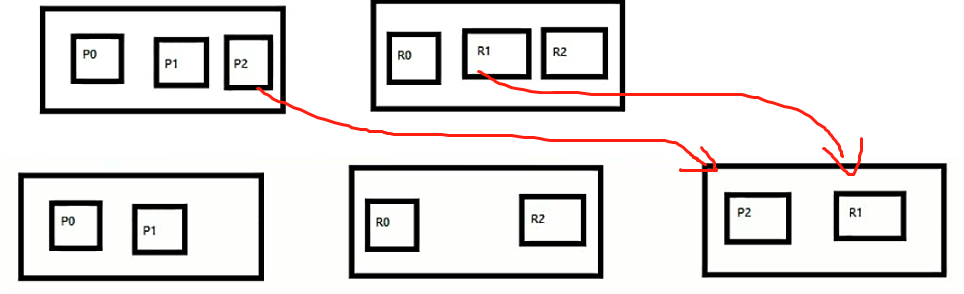
*********************************************************** 容错图 -------------->

**************************************************************** 纠正图 ---->>

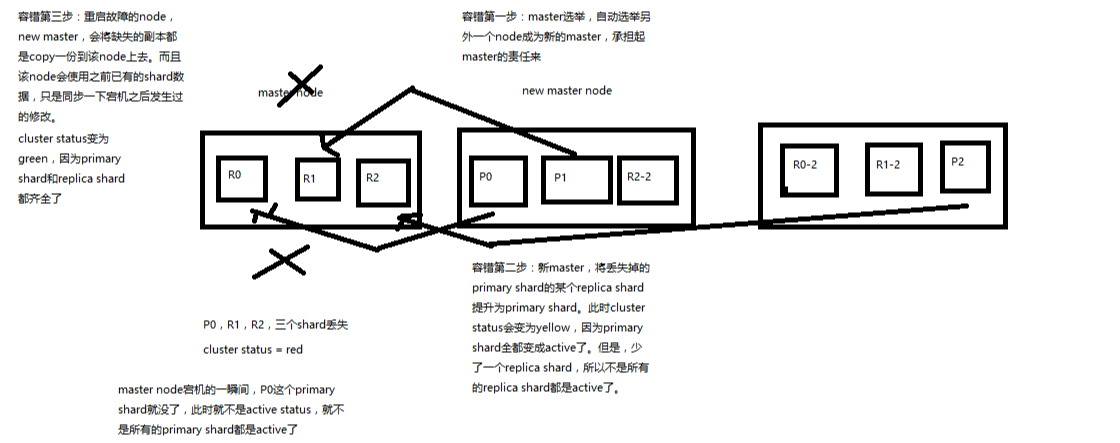
4、图解Elasticsearch容错机制:master选举,replica容错,数据恢复
(1)9 shard,3 node
(2)master node宕机,自动master选举,red
(3)replica容错:新master将replica提升为primary shard,yellow
(4)重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,green
5、 初步解析document的核心元数据以及图解剖析index创建反例
1、_index元数据
2、_type元数据
3、_id元数据
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"test_content": "test test"
}
}
------------------------------------------------------------------------------------------------------------------------------------------
1、_index元数据
(1)代表一个document存放在哪个index中
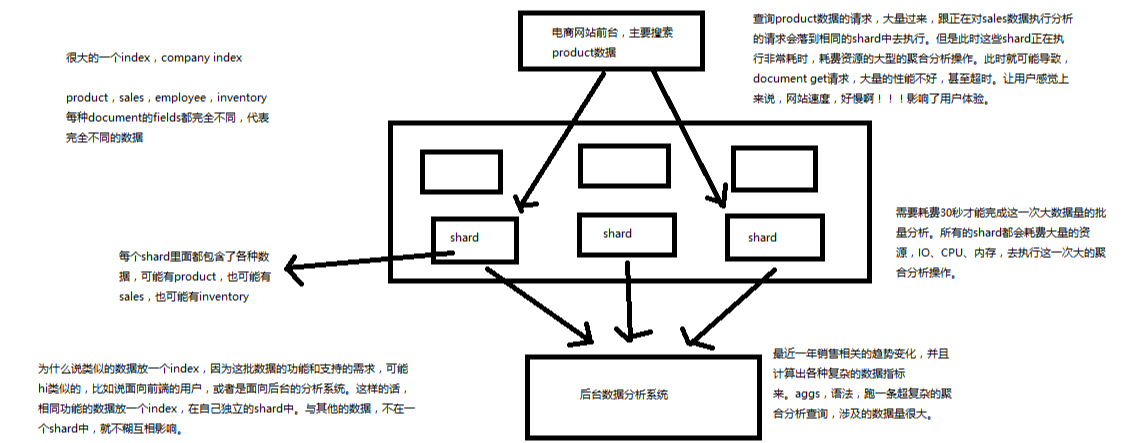
(2)类似的数据放在一个索引,非类似的数据放不同索引:product index(包含了所有的商品),sales index(包含了所有的商品销售数据),inventory index(包含了所有库存相关的数据)。如果你把比如product,sales,human resource(employee),全都放在一个大的index里面,比如说company index,不合适的。
(3)index中包含了很多类似的document:类似是什么意思,其实指的就是说,这些document的fields很大一部分是相同的,你说你放了3个document,每个document的fields都完全不一样,这就不是类似了,就不太适合放到一个index里面去了。
(4)索引名称必须是小写的,不能用下划线开头,不能包含逗号:product,website,blog
2、_type元数据
(1)代表document属于index中的哪个类别(type)
(2)一个索引通常会划分为多个type,逻辑上对index中有些许不同的几类数据进行分类:因为一批相同的数据,可能有很多相同的fields,但是还是可能会有一些轻微的不同,可能会有少数fields是不一样的,举个例子,就比如说,商品,可能划分为电子商品,生鲜商品,日化商品,等等。
(3)type名称可以是大写或者小写,但是同时不能用下划线开头,不能包含逗号
3、_id元数据
(1)代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document
(2)我们可以手动指定document的id(put /index/type/id),也可以不指定,由es自动为我们创建一个id
6、document id的手动指定与自动生成两种方式解析
课程大纲
1、手动指定document id
2、自动生成document id
------------------------------------------------------------------------------------------------------------
1、手动指定document id
(1)根据应用情况来说,是否满足手动指定document id的前提:
一般来说,是从某些其他的系统中,导入一些数据到es时,会采取这种方式,就是使用系统中已有数据的唯一标识,作为es中document的id。举个例子,比如说,我们现在在开发一个电商网站,做搜索功能,或者是OA系统,做员工检索功能。这个时候,数据首先会在网站系统或者IT系统内部的数据库中,会先有一份,此时就肯定会有一个数据库的primary key(自增长,UUID,或者是业务编号)。如果将数据导入到es中,此时就比较适合采用数据在数据库中已有的primary key。
如果说,我们是在做一个系统,这个系统主要的数据存储就是es一种,也就是说,数据产生出来以后,可能就没有id,直接就放es一个存储,那么这个时候,可能就不太适合说手动指定document id的形式了,因为你也不知道id应该是什么,此时可以采取下面要讲解的让es自动生成id的方式。
(2)put /index/type/id
PUT /test_index/test_type/2
{
"test_content": "my test"
}
2、自动生成document id
(1)post /index/type
POST /test_index/test_type
{
"test_content": "my test"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "AVp4RN0bhjxldOOnBxaE",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
(2)自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能会发生冲突
7、document的全量替换、强制创建以及图解lazy delete机制
1、document的全量替换
2、document的强制创建
3、document的删除
------------------------------------------------------------------------------------------------------------------------
1、document的全量替换
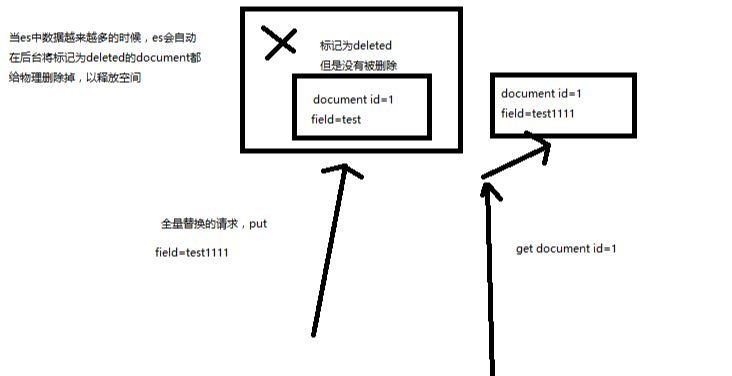
(1)语法与创建文档是一样的,如果document id不存在,那么就是创建;如果document id已经存在,那么就是全量替换操作,替换document的json串内容
(2)document是不可变的,如果要修改document的内容,第一种方式就是全量替换,直接对document重新建立索引,替换里面所有的内容
(3)es会将老的document标记为deleted,然后新增我们给定的一个document,当我们创建越来越多的document的时候,es会在适当的时机在后台自动删除标记为deleted的document
------------------------------------------------------------------------------------------------------------------------
2、document的强制创建
(1)创建文档与全量替换的语法是一样的,有时我们只是想新建文档,不想替换文档,如果强制进行创建呢?
(2)PUT /index/type/id?op_type=create,PUT /index/type/id/_create
------------------------------------------------------------------------------------------------------------------------
3、document的删除
(1)DELETE /index/type/id
(2)不会理解物理删除,只会将其标记为deleted,当数据越来越多的时候,在后台自动删除
8、深度图解剖析Elasticsearch并发冲突问题
9、分布式文档系统-深度图解剖析悲观锁与乐观锁两种并发控制方案

10、图解Elasticsearch内部如何基于_version进行乐观锁并发控制
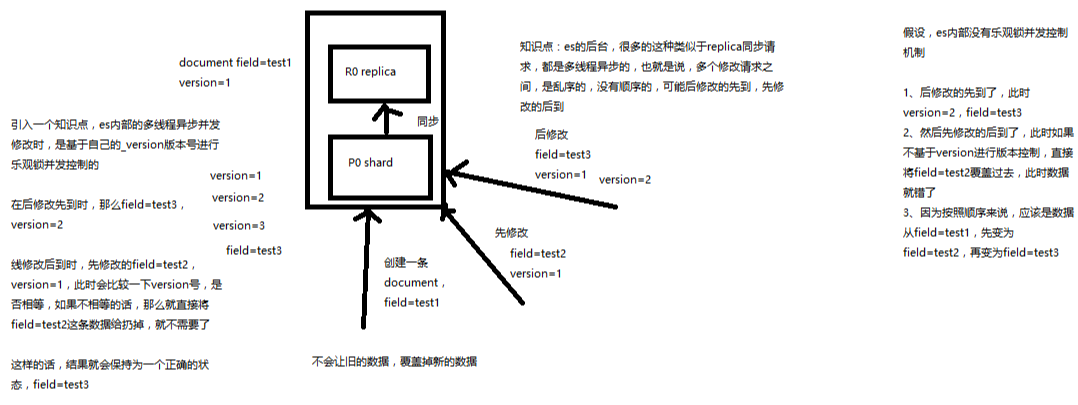
(1)_version元数据
PUT /test_index/test_type/6
{
"test_field": "test test"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
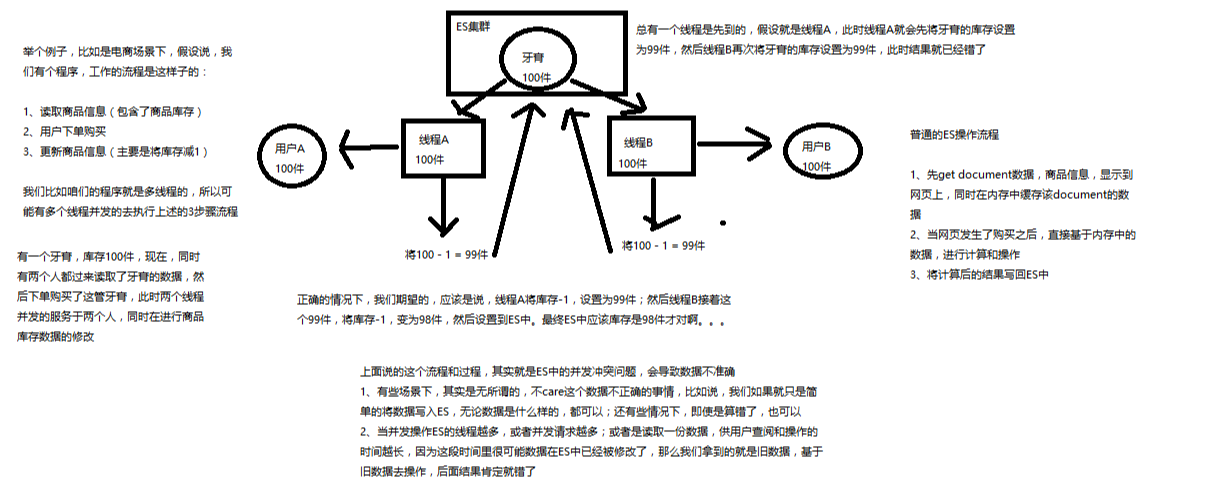
第一次创建一个document的时候,它的_version内部版本号就是1;以后,每次对这个document执行修改或者删除操作,都会对这个_version版本号自动加1;哪怕是删除,也会对这条数据的版本号加1
{
"found": true,
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_version": 4,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
我们会发现,在删除一个document之后,可以从一个侧面证明,它不是立即物理删除掉的,因为它的一些版本号等信息还是保留着的。先删除一条document,再重新创建这条document,其实会在delete version基础之上,再把version号加1
亿级流量场景下,大型架构设计实现【全文检索高级搜索---ElasticSearch篇】-- 中的更多相关文章
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- 亿级流量场景下,大型缓存架构设计实现【1】---redis篇
*****************开篇介绍**************** -------------------------------------------------------------- ...
- 【高并发】亿级流量场景下如何为HTTP接口限流?看完我懂了!!
写在前面 在互联网应用中,高并发系统会面临一个重大的挑战,那就是大量流高并发访问,比如:天猫的双十一.京东618.秒杀.抢购促销等,这些都是典型的大流量高并发场景.关于秒杀,小伙伴们可以参见我的另一篇 ...
- 万级TPS亿级流水-中台账户系统架构设计
万级TPS亿级流水-中台账户系统架构设计 标签:高并发 万级TPS 亿级流水 账户系统 背景 业务模型 应用层设计 数据层设计 日切对账 背景 我们需要给所有前台业务提供统一的账户系统,用来支撑所有前 ...
- Netty Redis 亿级流量 高并发 实战 (长文 修正版)
目录 疯狂创客圈 Java 分布式聊天室[ 亿级流量]实战系列之 -30[ 博客园 总入口 ] 写在前面 1.1. 快速的能力提升,巨大的应用价值 1.1.1. 飞速提升能力,并且满足实际开发要求 1 ...
- java亿级流量电商详情页系统的大型高并发与高可用缓存架构实战视频教程
亿级流量电商详情页系统的大型高并发与高可用缓存架构实战 完整高清含源码,需要课程的联系QQ:2608609000 1[免费观看]课程介绍以及高并发高可用复杂系统中的缓存架构有哪些东西2[免费观看]基于 ...
- SpringCloud 亿级流量 架构演进
疯狂创客圈 Java 高并发[ 亿级流量聊天室实战]实战系列 [博客园总入口 ] 架构师成长+面试必备之 高并发基础书籍 [Netty Zookeeper Redis 高并发实战 ] 前言 Crazy ...
- 【架构师之路】Nginx负载均衡与反向代理—《亿级流量网站架构核心技术》
本篇摘自<亿级流量网站架构核心技术>第二章 Nginx负载均衡与反向代理 部分内容. 当我们的应用单实例不能支撑用户请求时,此时就需要扩容,从一台服务器扩容到两台.几十台.几百台.然而,用 ...
- (亿级流量)分布式防重复提交token设计
大型互联网项目中,很多流量都达到亿级.同一时间很多的人在使用,而每个用户提交表单的时候都可能会出现重复点击的情况,此时如果不做好控制,那么系统将会产生很多的数据重复的问题.怎样去设计一个高可用的防重复 ...
随机推荐
- 工厂模式讲解, 引入Spring IOC
目录 引入 简单工厂 抽象工厂 Spring的bean工厂 模拟Spring工厂实现 模拟IOC 引入 假设有一个司机, 需要到某个城市, 于是我们给他一辆汽车 public class Demo { ...
- Javaoop 遇到的问题
一.java 异常的捕获与处理 (免责声明:本博客里所引用的他人博客链接,只用作我个人的学习,同时非常感谢这些作者!) 1. https://blog.csdn.net/wei_zhi/articl ...
- PostgreSQL:安装及中文显示
一.PostgreSQL PostgreSQL (也称为Post-gress-Q-L)是一个跨平台的功能强大的开源对象关系数据库管理系统,由 PostgreSQL 全球开发集团(全球志愿者团队)开发. ...
- WAF开放规则定义权:专家策略+用户自定义策略=Web安全
在第一期“漫说安全”栏目中,我们用四格漫画的形式介绍了基于深度学习的阿里云WAF到底智能在哪里,能帮客户解决什么问题. 在今天的这期栏目里,我们依然通过漫画这种通俗易懂的方式,与大家分享阿里云WAF的 ...
- C#采用vony.Html.AIO插件批量爬MM网站图片
一.创建项目 1.创建一个.netframework的控制台项目命名为Crawler 2.安装nuget包搜索名称Ivony.Html.AIO,使用该类库什么方便类似jqury的选择器可以根据类名或者 ...
- python 自学之路-Day Two
Day1补充部分 模块初识 模块就是由其他人写好的功能,在程序需要的时候进行导入,直接使用,也叫库. 库有标准库和第三方库,所谓标准库,就是不需要安装就可以直接使用的,自带的:第三方库,就是需要进行下 ...
- JAVA文件的上传与访问
/** * 各种文件上传与判断 * types 文件类型(1图片 2视频 3文件) */@RequestMapping(method = RequestMethod.POST, path = &quo ...
- Demo更新列表
Sdk 对应的demo ESF (1)ESF/ESFramework.EntranceDemo.rar (2)ESF/4.ESFramework.Demos.Ftp.rar (3)ESF/6.ESFr ...
- CSS3D 转换调试
css3d 测试工具 效果如图: 代码如下: <!DOCTYPE html> <html lang="zh-CN"> <head> <me ...
- 腾迅云CDN的使用
一开始,我是想和七牛云一样,将腾迅云的对象存储作为网盘使用,不过在折腾的时间,搞不清楚腾迅云CDN的用法,最后看文档,看博客,大概了解了 这里讲两种用法,一种是结合对象存储,作一个静态网站或下载站,但 ...