用js来实现那些数据结构12(散列表)
上一篇写了如何实现简单的Map结构,因为东西太少了不让上首页。好吧。。。
这一篇文章说一下散列表hashMap的实现。那么为什么要使用hashMap?hashMap又有什么优势呢?hashMap是如何检索数据的?我们一点一点的来解答。
在我们学习一门编程语言的时候,最开始学习的部分就是循环遍历。那么为什么要遍历呢?因为我们需要拿到具体的值,数组中我们要遍历数组获取所有的元素才能定位到我们想要的元素。对象也是一样,我们同样要遍历所有的对象元素来获取我们想要的指定的元素。那么无论是array也好,object也好,栈还是队列还是列表或者集合(我们前面学过的所有数据结构)都需要遍历。不然我们根本拿不到我们想要操作的具体的元素。但是这样就有一个问题,那就是效率。如果我们的数据有成百万上千万的数据。我们每一次循环遍历都会消耗大量的时间,用户体验可以说几乎没有。(当然,前端几乎不会遇到这种情况,因为大数据量的情况都通过分页来转化了)。
那么,有没有一种快速有效的定位我们想要的元素的数据结构呢?答案就是hashMap。当然,应该也有其它更高效的数据处理方式,但是我暂时不知道啊。。。。
那么hashMap是如何存取元素的呢?首先,hashMap在存储元素的时候,会通过lose lose散列函数来设置key,这样我们就无需遍历整个数据结构,就可以快速的定位到该元素的具体位置,从而获取到具体的值。
什么是lose lose散列函数呢?其实lose lose散列函数就是简单的把每个key中的所有字母的ASCII码值相加,生成一个数字,作为散列表的key。当然,这种方法并不是很好,会生成很多相同的散列值。下面会具体的讲解如何解决,以及一种更好的散列函数djb2。
那么我们开始实现我们的hashMap:
// 这里我们没在重复的去写clear,size等其他的方法,因为跟前面实在是没啥区别。
function HashMap() {
// 我们使用数组来存储元素
var list = [];
//转换散列值得loselose散列函数。
var loseloseHashCode = function (key) {
var hash = 0;
// 遍历字符串key的长度,注意,字符串也是可以通过length来获取每一个字节的。
for(var i = 0; i < key.length; i++) {
hash += key.charCodeAt(i)
}
//对hash取余,这是为了得到一个比较小的hash值,
//但是这里取余的对象又不能太大,要注意
return hash % 37;
}
//通过loselose散列函数直接在计算出来的位置放入对应的值。
this.put = function (key,value) {
var position = loseloseHashCode(key);
console.log(position + "-" + key);
list[position] = value;
}
//同样的,我们想要得到一个值,只要通过散列函数计算出位置就可以直接拿到,无需循环
this.get = function (key) {
return list[loseloseHashCode(key)];
}
//这里要注意一下,我们的散列表是松散结构,也就是说散列表内的元素并不是每一个下标index都一定是有值,
//比如我存储两个元素,一个计算出散列值是14,一个是20,那么其余的位置仍旧是存在的,我们不能删除它,因为一旦删除,我们存储元素的位置也会改变。
//所以这里要移除一个元素,只要为其赋值为undefined就可以了。
this.remove = function (key) {
list[loseloseHashCode(key)] = undefined;
} this.print = function () {
for(var i = 0; i < list.length; i++) {
// 大家可以把这里的判断去掉,看看到底是不是松散的数组结构。
if(list[i] !== undefined) {
console.log(i + ":" + list[i]);
}
}
} }
//那么我们来测试一下我们的hashMap
var hash = new HashMap();
hash.put("Gandalf",'www.gandalf.com');
hash.put("John",'www.john.com');
hash.put("Tyrion",'www.tyrion.com');
//因为我们在put代码中加了一个console以便我们更好的理解代码,我们看一下输出
// 19-Gandalf
// 29-John
// 16-Tyrion
console.log(hash.get('John'));//www.john.com
console.log(hash.get("Zaking"));//undefined //那么我们来移除一个元素John
hash.remove("John");
console.log(hash.get("John"));//undefined
那么我们就实现并且简单测试了一下我们自定义的hashMap,发现还不错哦。但是元素太少,没有代表性。我们再多测试几个数据看看会如何?
var conflictHash = new HashMap();
conflictHash.put("Gandalf",'www.Gandalf.com');//19-Gandalf
conflictHash.put("John",'www.John.com');//29-John
conflictHash.put("Tyrion",'www.Tyrion.com');//16-Tyrion
conflictHash.put("Aaron",'www.Aaron.com');//16-Aaron
conflictHash.put("Donnie",'www.Donnie.com');//13-Donnie
conflictHash.put("Ana",'www.Ana.com');//13-Ana
conflictHash.put("Jonathan",'www.Jonathan.com');//5-Jonathan
conflictHash.put("Jamie",'www.Jamie.com');//5-Jamie
conflictHash.put("Sue",'www.Sue.com');//5-Sue
conflictHash.put("Mindy",'www.Mindy.com');//32-Mindy
conflictHash.put("Paul",'www.Paul.com');//32-Paul
conflictHash.put("Nathan",'www.Nathan.com');//10-Nathan conflictHash.print();
/*
5:www.Sue.com
10:www.Nathan.com
13:www.Ana.com
16:www.Aaron.com
19:www.Gandalf.com
29:www.John.com
32:www.Paul.com
*/
我们发现后来的把前面相同散列值得元素给替换了。那么之前的元素也就随之丢失了,这绝不是我们想要看到的样子。这才十几个元素就有这么多相同的,如果数据量极大那还了得。。。这啥用没有啊。。。所以,我们需要解决这样的问题,我们这里介绍两种解决这种冲突的方法。分离链接和线性探查。
1、分离链接
分离链接,其实核心就是为散列表的每一个位置创建一个链表,并将元素存储在里面。它可以说是解决冲突的最简单的方法,但是,它占用了额外的存储空间。之前的例子,如果用分离链接来解决冲突的话,那么看起来就是这个样子。
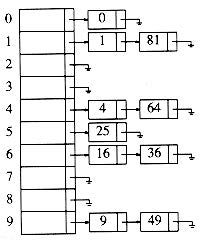
那么我们就需要重写hashMap,我们来看看分离链接下的hashMap是如何实现的。由于我们要重写hashMap类中的方法,所以我们重新构建一个新的类:SeparateHashMap。
function LinkedList() {//...链表方法}
// 创建分离链接法下的hashMap。
function SeparateHashMap () {
var list = [];
//loselose散列函数。
var loseloseHashCode = function (key) {
var hash = 0;
for(var i = 0; i < key.length; i++) {
hash += key.charCodeAt(i)
}
return hash % 37;
}
//这里为什么要创建一个新的用来存储键值对的构造函数?
//首先我们要知道的一点是,在分离链接下,我们元素所存储的位置实际上是在链表里面。
//而一旦在该散列位置下的链表中有多个值,我们仍旧需要通过key去找链表中所对应的元素。
//换句话说,分离链接下的存储方式是,首先通过key来计算散列值,然后把对应的key和value也就是ValuePair存入linkedList。
//这就是valuePair的作用了。
var ValuePair = function (key,value) {
this.key = key;
this.value = value;
this.toString = function () {
return "[" + this.key + "-" + this.value + "]";
}
}
//同样的,我们通过loselose散列函数计算出对应key的散列值。
this.put = function (key,value) {
var position = loseloseHashCode(key);
//这里如果该位置为undefined,说明这个位置没有链表,那么我们就新建一个链表。
if(list[position] == undefined) {
list[position] = new LinkedList();
}
//新建之后呢,我们就通过linkedList类的append方法把valuePair加入进去。
//那么如果上面的判断是false,也就是有了链表,直接跳过上面的判断执行加入操作就好了。
list[position].append(new ValuePair(key,value));
}
this.get = function (key) {
var position = loseloseHashCode(key);
//链表的操作前面相应的链表文章已经写的很清楚了。这里就尽量简单说清
//如果这个位置不是undefined,那么说明存在链表
if(list[position] !== undefined) {
//我们要拿到current,也就是链表中的第一个元素进行链表中的遍历。
var current = list[position].getHead();
//如果current.next不为null说明还有下一个
while(current.next) {
//如果要查找的key是当前链表元素的key,就返回该链表节点的value。
//这里要注意一下。current.element = ValuePair噢!
if(current.element.key === key) {
return current.element.value;
}
current = current.next;
}
//那么这里刚开始让我有些疑惑。为啥还要单独判断一下?
//我们回头看一下,我们while循环的条件是current.next。没current什么事啊...对了。
//所以,这里我们还要单独判断一下是不是current。
//总结一下,这段get方法的代码运行方式是从第一个元素的下一个开始遍历,如果到最后还没找到,就看看是不是第一个,如果第一个也不是,那就返回undefined。没找到想要得到元素。
if(current.element.key === key) {
return current.element.value;
}
}
return undefined;
}
//这个remove方法就不说了。跟get方法一模一样,get方法是在找到对应的值的时候返回该值的value,而remove方法是在找到该值的时候,重新赋值为undefined,从而移除它。
this.remove = function (key) {
var position = loseloseHashCode(key);
if(list[position] !== undefined) {
var current = list[position].getHead();
while(current.next) {
if(current.element.key === key) {
list[position].remove(current.element);
if(list[position].isEmpty()) {
list[position] = undefined;
}
return true;
}
current = current.next;
}
if(current.element.key === key) {
list[position].remove(current.element);
if(list[position].isEmpty()) {
list[position] = undefined;
}
return true;
}
}
return false;
};
this.print = function () {
for(var i = 0; i < list.length; i++) {
// 大家可以把这里的判断去掉,看看到底是不是松散的数组结构。
if(list[i] !== undefined) {
console.log(i + ":" + list[i]);
}
}
}
}
var separateHash = new SeparateHashMap();
separateHash.put("Gandalf",'www.Gandalf.com');//19-Gandalf
separateHash.put("John",'www.John.com');//29-John
separateHash.put("Tyrion",'www.Tyrion.com');//16-Tyrion
separateHash.put("Aaron",'www.Aaron.com');//16-Aaron
separateHash.put("Donnie",'www.Donnie.com');//13-Donnie
separateHash.put("Ana",'www.Ana.com');//13-Ana
separateHash.put("Jonathan",'www.Jonathan.com');//5-Jonathan
separateHash.put("Jamie",'www.Jamie.com');//5-Jamie
separateHash.put("Sue",'www.Sue.com');//5-Sue
separateHash.put("Mindy",'www.Mindy.com');//32-Mindy
separateHash.put("Paul",'www.Paul.com');//32-Paul
separateHash.put("Nathan",'www.Nathan.com');//10-Nathan
separateHash.print();
/*
5:[Jonathan-www.Jonathan.com]n[Jamie-www.Jamie.com]n[Sue-www.Sue.com]
10:[Nathan-www.Nathan.com]
13:[Donnie-www.Donnie.com]n[Ana-www.Ana.com]
16:[Tyrion-www.Tyrion.com]n[Aaron-www.Aaron.com]
19:[Gandalf-www.Gandalf.com]
29:[John-www.John.com]
32:[Mindy-www.Mindy.com]n[Paul-www.Paul.com]
*/
console.log(separateHash.get("Paul"));
/*
www.Paul.com
*/
console.log(separateHash.remove("Jonathan"));//true
separateHash.print();
/*
5:[Jamie-www.Jamie.com]n[Sue-www.Sue.com]
10:[Nathan-www.Nathan.com]
13:[Donnie-www.Donnie.com]n[Ana-www.Ana.com]
16:[Tyrion-www.Tyrion.com]n[Aaron-www.Aaron.com]
19:[Gandalf-www.Gandalf.com]
29:[John-www.John.com]
32:[Mindy-www.Mindy.com]n[Paul-www.Paul.com]
*/
其实,分离链接法,是在每一个散列值对应的位置上新建了一个链表以供重复的值可以存储,我们需要通过key分别在hashMap和linkedList中查找值,而linkedList中的查找仍旧是遍历。如果数据量很大,其实仍旧会耗费一些时间。但是当然,肯定要比数组等这样需要遍历整个数据结构的方式要效率的多。
下面我们来看看线性探查法。
2、线性探查
什么是线性探查呢?其实就是在hashMap中发生冲突的时候,将散列函数计算出的散列值+1,如果+1还是有冲突那么就+2。直到没有冲突为止。
其实分离链接和线性探查两种方法,多少有点时间换空间的味道。
我们还是来看代码。
function LinearHashMap () {
var list = [];
var loseloseHashCode = function (key) {
var hash = 0;
for(var i = 0; i < key.length; i++) {
hash += key.charCodeAt(i)
}
return hash % 37;
}
var ValuePair = function (key,value) {
this.key = key;
this.value = value;
this.toString = function () {
return "[" + this.key + "-" + this.value + "]";
}
}
this.put = function (key,value) {
var position = loseloseHashCode(key);
//同样的,若是没有值。就把该值存入
if(list[position] == undefined) {
list[position] = new ValuePair(key,value);
} else {
// 如果有值,那么久循环到没有值为止。
var index = ++position;
while(list[index] != undefined) {
index++
}
list[index] = new ValuePair(key,value);
}
}
this.get = function (key) {
var position = loseloseHashCode(key);
if(list[position] !== undefined) {
if(list[position].key === key) {
return list[position].value;
} else {
var index = ++position;
while(list[index] === undefined || list[index].key !== key) {
index ++;
}
if(list[index] .key === key) {
return list[index].value
}
}
}
return undefined;
}
this.remove = function (key) {
var position = loseloseHashCode(key);
if(list[position] !== undefined) {
if(list[position].key === key) {
list[index] = undefined;
} else {
var index = ++position;
while(list[index] === undefined || list[index].key !== key) {
index ++;
}
if(list[index] .key === key) {
list[index] = undefined;
}
}
}
return undefined;
};
this.print = function () {
for(var i = 0; i < list.length; i++) {
// 大家可以把这里的判断去掉,看看到底是不是松散的数组结构。
if(list[i] !== undefined) {
console.log(i + ":" + list[i]);
}
}
}
}
var linearHash = new LinearHashMap();
linearHash.put("Gandalf",'www.Gandalf.com');//19-Gandalf
linearHash.put("John",'www.John.com');//29-John
linearHash.put("Tyrion",'www.Tyrion.com');//16-Tyrion
linearHash.put("Aaron",'www.Aaron.com');//16-Aaron
linearHash.put("Donnie",'www.Donnie.com');//13-Donnie
linearHash.put("Ana",'www.Ana.com');//13-Ana
linearHash.put("Jonathan",'www.Jonathan.com');//5-Jonathan
linearHash.put("Jamie",'www.Jamie.com');//5-Jamie
linearHash.put("Sue",'www.Sue.com');//5-Sue
linearHash.put("Mindy",'www.Mindy.com');//32-Mindy
linearHash.put("Paul",'www.Paul.com');//32-Paul
linearHash.put("Nathan",'www.Nathan.com');//10-Nathan
linearHash.print();
console.log(linearHash.get("Paul"));
console.log(linearHash.remove("Mindy"));
linearHash.print();
LinearHashMap与SeparateHashMap在方法上有着相似的实现。这里就不再浪费篇幅的去解释了,但是大家仍旧要注意其中的细节。比如说在位置的判断上的不同之处。
那么HashMap对于冲突的解决方法这里就介绍这两种。其实还有很多方法可以解决冲突,但是我觉得最好的办法就是让冲突的可能性变小。当然,无论是使用什么方法,冲突都是有可能存在的。
那么如何让冲突的可能性变小呢?很简单,就是让计算出的散列值尽可能的不重复。下面介绍一种比loselose散列函数更好一些的散列函数djb2。
var djb2HashCode = function(key) {
var hash = 5831;
for(var i = 0; i < key.length; i++) {
hash = hash * 33 + key.charCodeAt(i);
}
return hash % 1013;
}
大家可以把最开始实现的HashMap的loselose散列函数换成djb2。再去添加元素测试一下是否冲突的可能性变小了。
djb2散列函数中,首先用一个hash变量存储一个质数(只能被1和自身整除的数)。将hash与33相乘并加上当前迭代道德ASCII码值相加。最后对1013取余。就得到了我们想要的散列值。
到这里,hashMap就介绍完了。希望大家可以认真的去阅读查看。
最后,由于本人水平有限,能力与大神仍相差甚远,若有错误或不明之处,还望大家不吝赐教指正。非常感谢!
用js来实现那些数据结构12(散列表)的更多相关文章
- JS中数据结构之散列表
散列是一种常用的数据存储技术,散列后的数据可以快速地插入或取用.散列使用的数据 结构叫做散列表.在散列表上插入.删除和取用数据都非常快. 下面的散列表是基于数组进行设计的,数组的长度是预先设定的,如有 ...
- 【PHP数据结构】散列表查找
上篇文章的查找是不是有意犹未尽的感觉呢?因为我们是真真正正地接触到了时间复杂度的优化.从线性查找的 O(n) 直接优化到了折半查找的 O(logN) ,绝对是一个质的飞跃.但是,我们的折半查找最核心的 ...
- Python与数据结构[4] -> 散列表[2] -> 开放定址法与再散列的 Python 实现
开放定址散列法和再散列 目录 开放定址法 再散列 代码实现 1 开放定址散列法 前面利用分离链接法解决了散列表插入冲突的问题,而除了分离链接法外,还可以使用开放定址法来解决散列表的冲突问题. 开放定 ...
- Python与数据结构[4] -> 散列表[0] -> 散列表与散列函数的 Python 实现
散列表 / Hash Table 散列表与散列函数 散列表是一种将关键字映射到特定数组位置的一种数据结构,而将关键字映射到0至TableSize-1过程的函数,即为散列函数. Hash Table: ...
- jdk1.8HashMap底层数据结构:散列表+链表+红黑树,jdk1.8HashMap数据结构图解+源码说明
一.前言 本文由jdk1.8源码整理而得,附自制jdk1.8底层数据结构图,并截取部分源码加以说明结构关系. 二.jdk1.8 HashMap底层数据结构图 三.源码 1.散列表(Hash table ...
- Nginx数据结构之散列表
1. 散列表(即哈希表概念) 散列表是根据元素的关键码值而直接进行访问的数据结构.也就是说,它通过把关键码值映射到表中一个位置来访问记录, 以加快查找速度.这个映射函数 f 叫做散列方法,存放记录的数 ...
- Python与数据结构[4] -> 散列表[1] -> 分离链接法的 Python 实现
分离链接法 / Separate Chain Hashing 前面完成了一个基本散列表的实现,但是还存在一个问题,当散列表插入元素冲突时,散列表将返回异常,这一问题的解决方式之一为使用链表进行元素的存 ...
- JavaScript数据结构-12.散列碰撞(线性探测法)
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 用js来实现那些数据结构—目录
首先,有一点要声明,下面所有文章的所有内容的代码,都不是我一个人独立完成的,它们来自于一本叫做<学习JavaScript数据结构和算法>(第二版),人民邮电出版社出版的这本书.github ...
随机推荐
- 关于win10系统1709版本安装JDK出现变量配置正确但仍有“java不是内部或外部命令”的解决办法
背景:联想拯救者R720笔记本,系统一键还原了,需要重新安装一部分软件,最基本的就是JDK,但今天在安装时遇到了问题,之前安装的1.8版本,没有仔细配置环境变量,这一次安装的是1.7版本的,仔仔细细配 ...
- Linux后台运行命令 nohup command > myout.file 2>&1
Linux命令后台运行 转自北国的雨,谢谢:http://www.cnblogs.com/lwm-1988/archive/2011/08/20/2147299.html 有两种方式:1. comma ...
- OAuth2.0学习(1-10)新浪开放平台微博认证-手机应用授权和refresh_token刷新access_token
1.当你是使用微博官方移动SDK的移动应用时,授权返回access_token的同时,还会多返回一个refresh_token: JSON 1 2 3 4 5 6 { "access ...
- 消息队列的使用 RabbitMQ (二): Windows 环境下集群的实现
一.RabbitMQ 集群的基本概念 一个 RabbitMQ 中间件(broker) 由一个或多个 erlang 节点组成,节点之间共享 用户名.虚拟目录.队列消息.运行参数 等, 这个 节点的集合被 ...
- Linux:sheel脚本for的用法,及日期参数+1day用法
记录下shell的for的用法,及参数是日期的情况下,该日期+1day的用法: #!/usr/bin/env bash source /app/catt/login.sh p_days="2 ...
- Java:逐行读、写文件、文件目录过滤的用法
import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.I ...
- else语句的搭配
1.else语句搭配if 要么怎样,要么怎样 2.else语句搭配for和while 干完循环之后执行else,干不完或者break就不执行 3.else与异常处理 没有问题的话就执行else吧
- 合并css 合并图片 合并js
1:合并css 如:index.html 中的代码 <!DOCTYPE html><html lang="en"><head> <me ...
- Go VS Code 调式常见问题处理
GO VS Code 调式配置 launch.json{ "version": "0.2.0", "configurations": [ { ...
- OpenGL中glUniform1i使用
在OpenGL中使用glGetUniformLocation和glUniformxxx等函数时,要在之前启用对应的着色器程序,即调用glUseProgram.