希尔排序之C++实现(高级版)
希尔排序之C++实现(高级版)
一、源代码:ShellSortHigh.cpp
/*希尔排序基本思想:
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。
所有距离为d1的倍数的记录放在同一个组中。
先在各组内进行直接插入排序;
然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量 =1(<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
*/
#include<iostream>
using namespace std;
/*定义输出一维数组的函数*/
void print(int array[], int n)
{
for (int i = ; i < n; i++)
{
cout << array[i] << " ";
}
cout << endl;
}
/*
一种查找比较操作和记录移动操作交替地进行的方法。
具体做法:
将待插入记录R[i]的关键字从右向左依次与有序区中记录R[j](j=i-1,i-2,…,1)的关键字进行比较:
① 若R[j]的关键字大于R[i]的关键字,则将R[j]后移一个位置;
②若R[j]的关键字小于或等于R[i]的关键字,则查找过程结束,j+1即为R[i]的插入位置。
关键字比R[i]的关键字大的记录均已后移,所以j+1的位置已经腾空,只要将R[i]直接插入此位置即可完成一趟直接插入排序。 */
int shellSort(int array[], int n)
{
//定义变量,记录交换次数
int count = ;
//定义中间变量,做为临时交换变量
int temp;
//遍历数组(进行排序)
cout << "开始对数组进行排序了..." << endl;
//定义初始增量值
int gap = n;
do{
//初始增量变化规律
gap = gap / + ;
for (int i = gap; i < n; i++)
{
for (int j = i; j >= gap; j-=gap)
{
if (array[j] < array[j - gap])
{
temp = array[j];
array[j] = array[j - gap];
array[j - gap] = temp;
cout << array[j] << "和" << array[j - gap] << "互换了" << endl;
//输出此时数组的顺序
cout << "数组此时的顺序是:";
print(array, );
//每交换一次,记录数加1
count++;
}
else
{
break;
}
}
}
} while (gap>);
cout << "数组排序结束了..." << endl;
return count;
} int main()
{
//定义待排序的一维数组
int array[] = { , , , , , , , , , };
//输出原始数组
cout << "原始数组是:" << endl;
print(array, );
//对数组进行排序
int count = shellSort(array, );
//输出排序后的数组
cout << "排序后的数组是:" << endl;
print(array, );
cout << "共交换" << count << "次" << endl;
return ;
}
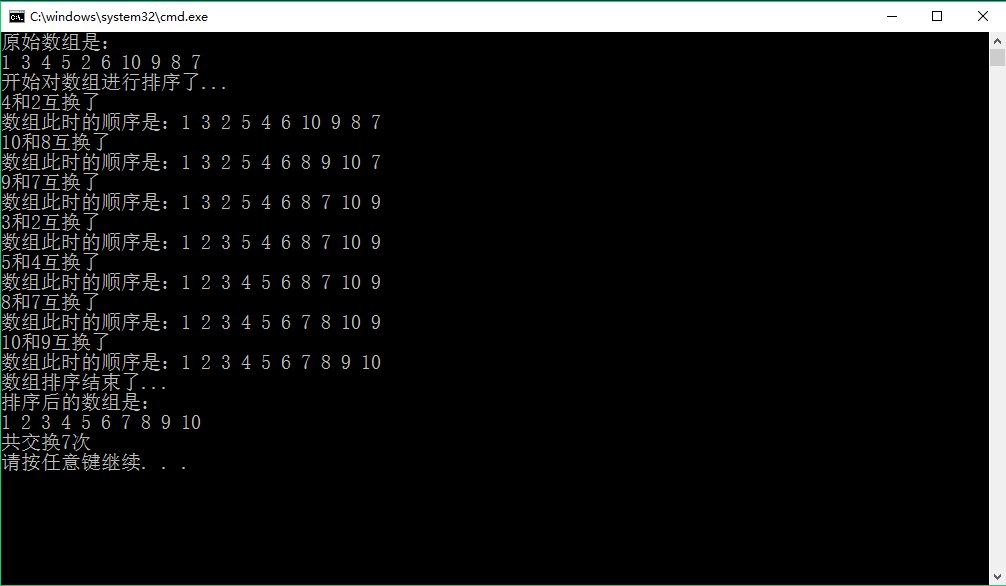
二、运行效果
希尔排序之C++实现(高级版)的更多相关文章
- 处理海量数据的高级排序之——希尔排序(C++)
希尔算法简介 ...
- Hark的数据结构与算法练习之希尔排序
算法说明 希尔排序是插入排序的优化版. 插入排序的最坏时间复杂度是O(n2),但如果要排序的数组是一个几乎有序的数列,那么会降低有效的减低时间复杂度. 希尔排序的目的就是通过一个increment(增 ...
- 深入浅出数据结构C语言版(17)——希尔排序
在上一篇博文中我们提到:要令排序算法的时间复杂度低于O(n2),必须令算法执行"远距离的元素交换",使得平均每次交换减少不止1逆序数. 而希尔排序就是"简单地" ...
- javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法)
javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法) 一.快速排序算法 /* * 这个函数首先检查数组的长度是否为0.如果是,那么这个数组就不需要任何排序,函数直接返回. * ...
- 希尔排序之C++实现(初级版)
希尔排序之C++实现(初级版) 一.源代码:希尔排序之C++实现(初级版) /*希尔排序基本思想: 先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组. 所有距离为d1的倍数的记录放在同一个 ...
- 算法与数据结构(十三) 冒泡排序、插入排序、希尔排序、选择排序(Swift3.0版)
本篇博客中的代码实现依然采用Swift3.0来实现.在前几篇博客连续的介绍了关于查找的相关内容, 大约包括线性数据结构的顺序查找.折半查找.插值查找.Fibonacci查找,还包括数结构的二叉排序树以 ...
- 算法(第四版)学习笔记之java实现希尔排序
希尔排序思想:使数组中随意间隔为h的元素都是有序的. 希尔排序是插入排序的优化.先对数组局部进行排序,最后再使用插入排序将部分有序的数组排序. 代码例如以下: /** * * @author seab ...
- 算法分析中最常用的几种排序算法(插入排序、希尔排序、冒泡排序、选择排序、快速排序,归并排序)C 语言版
每次开始动手写算法,都是先把插入排序,冒泡排序写一遍,十次有九次是重复的,所以这次下定决心,将所有常规的排序算法写了一遍,以便日后熟悉. 以下代码总用一个main函数和一个自定义的CommonFunc ...
- 算法Sedgewick第四版-第1章基础-2.1Elementary Sortss-004希尔排序法(Shell Sort)
一.介绍 1.希尔排序的思路:希尔排序是插入排序的改进.当输入的数据,顺序是很乱时,插入排序会产生大量的交换元素的操作,比如array[n]的最小的元素在最后,则要经过n-1次交换才能排到第一位,因为 ...
随机推荐
- iOS学习笔记(2)— UIView用户事件响应
UIView除了负责展示内容给用户外还负责响应用户事件.本章主要介绍UIView用户交互相关的属性和方法. 1.交互相关的属性 userInteractionEnabled 默认是YES ,如果设置为 ...
- [转]CMake快速入门教程:实战
转自http://blog.csdn.net/ljt20061908/article/details/11736713 0. 前言 一个多月前,由于工程项目的需要,匆匆的学习了一下cmake的使 ...
- 简单对象List自定义属性排序
<body> <div> sort()对数组排序,不开辟新的内存,对原有数组元素进行调换 </div> <div id="showBox" ...
- 【黑客免杀攻防】读书笔记17 - Rootkit基础
1.构建Rootkit基础环境 1.1.构建开发环境 VS2012+WDK8 1.2.构建基于VS2012的调试环境 将目标机.调试机配置在同一个工作组内 sVS2012配置->DRIVER-& ...
- Android Framebuffer介绍及使用【转】
转自:https://www.jianshu.com/p/df1213e5a0ed 来自: Android技术特工队 作者: Aaron 主页: http://www.wxtlife.com/ 原文连 ...
- mysql命令补全工具
需要在linux中下载mysql插件. 安装mysql插件 yum -y install epel-release python-pip python-devel pip install mycli ...
- docker安装(2018-03-14版本)
[安装] 说明一: CENTOS或RHEL自带的docker源不一定是最新的,所以必须到docker.com去找到最新的yum源进行安装 说明二: docker的安装方式有两种: 1. 从指定网站获取 ...
- IIS 启用https
参考:http://www.cnblogs.com/dudu/p/iis_https_ca.html
- Java HashCode详解
一.为什么要有Hash算法 Java中的集合有两类,一类是List,一类是Set.List内的元素是有序的,元素可以重复.Set元素无序,但元素不可重复.要想保证元素不重复,两个元素是否重复应该依据什 ...
- SQL Server日期计算
通常,你需要获得当前日期和计算一些其他的日期,例如,你的程序可能需要判断一个月的第一天或者最后一天.你们大部分人大概都知道怎样把日期进行分割(年.月.日等),然后仅仅用分割出来的年.月.日等放在几个函 ...