堆排序(最大堆)的理解和实现(Java)
堆的定义
堆是具有下列性质的完全二叉树:每个节点的值都大于或等于其左右孩子节点的值,称为大顶堆;或者每个节点的值都小于或等于其左右孩子的值,称为小顶堆。如下图举例:
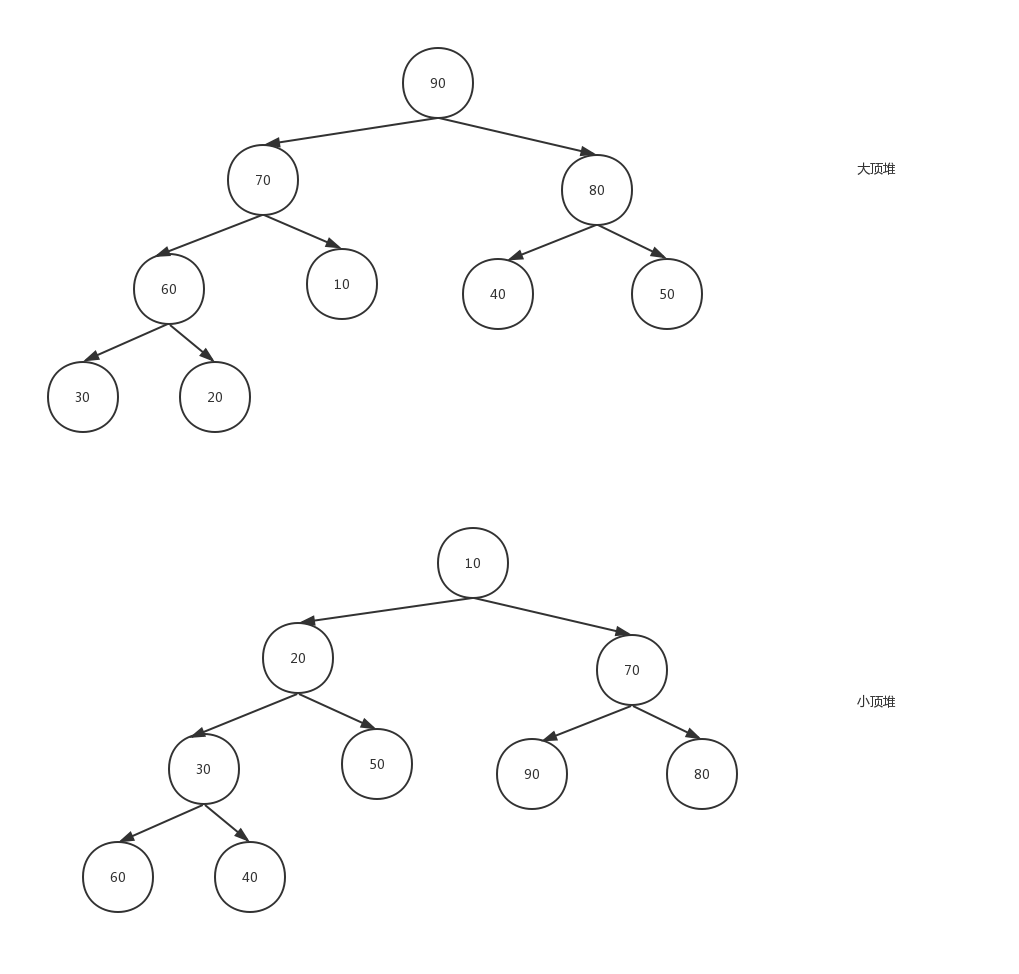
通过堆的定义可知,根节点一定是对中所有节点的最大(小)值。较大(小)的节点靠近根节点(并不绝对,比如上图小顶堆中60, 40均小于70,但它并没有70靠近根节点)
按层序方式给节点从1开始编号,则节点之间满足下列关系:
{ki≥k2iki≥k2i+1
\left \{\begin{array}{cc}
k_i \geq k_{2i}\\
k_i \geq k_{2i+1}
\end{array}\right.
{ki≥k2iki≥k2i+1
或:
{ki≤k2iki≤k2i+1
\left \{\begin{array}{cc}
k_i \leq k_{2i}\\
k_i \leq k_{2i+1}
\end{array}\right.
{ki≤k2iki≤k2i+1
其中i满足:1 ≤\leq≤ i ≤\leq≤ n2\frac{n}{2}2n
这里i为什么小于等于 n2\frac{n}{2}2n呢?
根据完全二叉树的性质,对于一棵完全二叉树,如果某一个节点的下标i=1,则这个节点是二叉树的根,无双亲;如果i > 1,则其双亲是节点i2\frac{i}{2}2i。那么对于有n个节点的二叉树来说,它的i值自然就是小于等于n2\frac{n}{2}2n了。
堆排序算法原理
堆排序(Heap Sort)就是利用堆(这里我们假设利用的最大堆,最小堆类似)进行排序的方法,它的基本思想就是,将待排序的序列构造成一个大顶堆。此时整个序列的最大值就是堆顶的根节点。将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中次大值,如此反复执行,就能得到一个有序序列。
算法流程:
- 将含有n个元素的待排序的序列 (r1r_1r1, r2r_2r2, r3r_3r3, …, rnr_nrn) 初始化成一个大顶堆,此堆为初始的无序区。
- 将堆顶元素r[1]和最后一个元素r[n]进行交换,交换完成后得到新的无序区:(r1r_1r1, r2r_2r2, r3r_3r3, …, rn−1r_{n-1}rn−1),和一个新的有序区 (rnr_nrn)。
- 交换后的新的堆顶元素r[1]可能破坏堆的性质,所以重新将当前无序区调整为一个新堆。然后再将堆顶元素r[1]和无序区最后一个元素进行交换,得到一个新的无序区 (r1r_1r1, r2r_2r2, …, rn−2r_{n-2}rn−2)和一个新的有序区 (rn−1r_{n-1}rn−1, rnr_nrn)。
- 重复上述过程,直到有序区的元素个数为n-1,整个排序过程完成
举例说明:
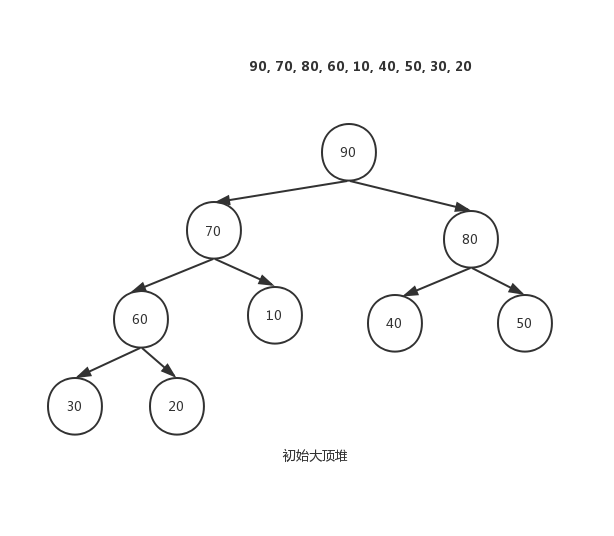
假设我们要排序的序列是{50, 10, 90, 30, 70, 40, 80, 60, 20},长度为9
将待排序序列初始化为一个堆:
则堆排序过程如下:
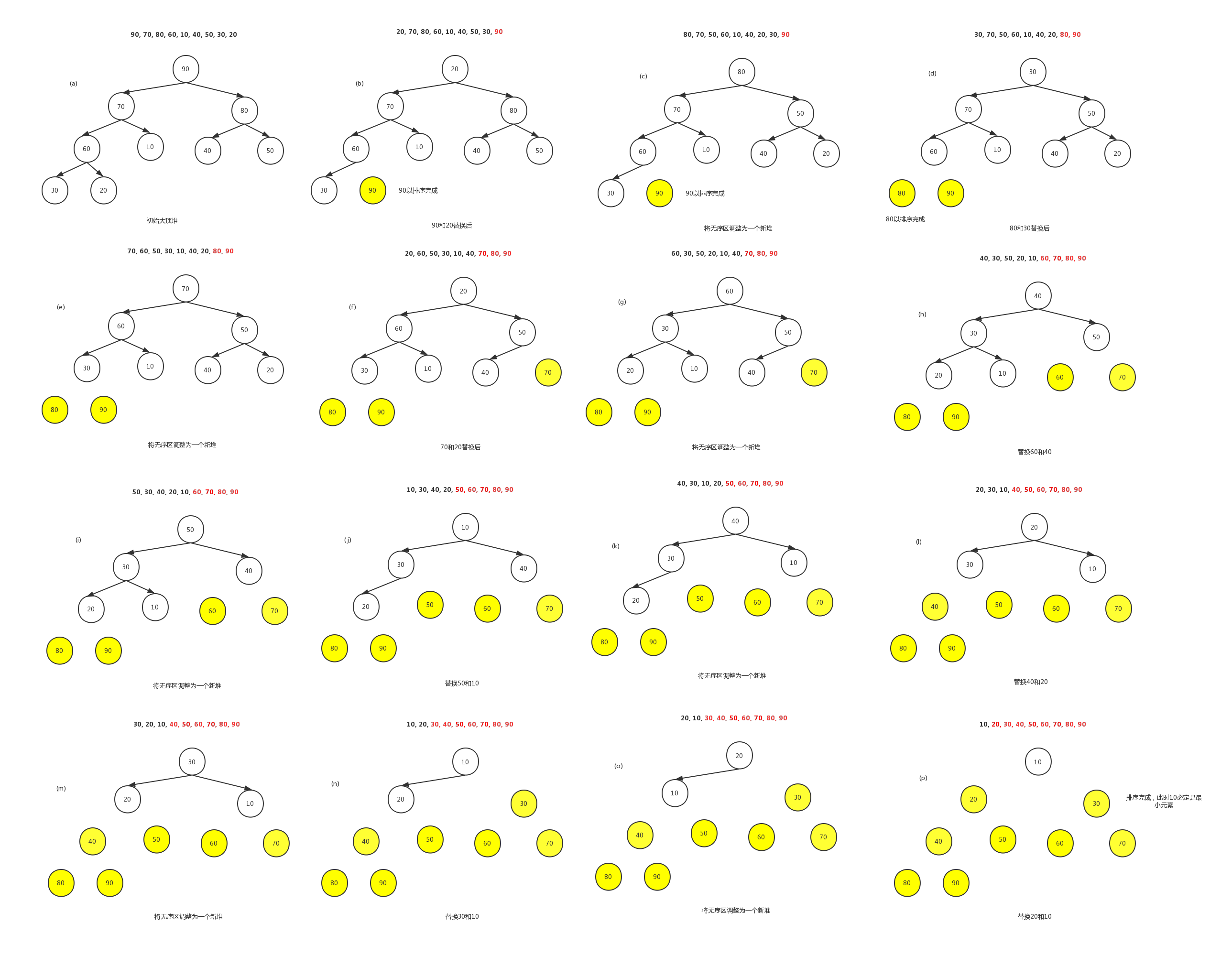
(ps:画图一度画疯…)
现在我们了解了堆排序的过程,但是还有两个问题:
- 如何减肥一个无序序列构建成一个堆?
- 如何在输出堆顶元素后,调整剩余元素成为一个新的堆?
我们所谓的将待排序的序列构造成一个大顶堆,其实就是从下往上、从右到左,将每个非终端(非叶子节点)节点当做根节点,将其和其子树调整成最大堆。
具体看代码:
public class MaxHeapSort {
/**
* 已知elem[s....m]中记录的关键字除elem[s]之外满足堆的定义
* 本函数调整elem[s]的关键字,使elem[s.....m]成为一个大顶堆
* @param elem
* @param s
* @param m
*/
public void maxHeapAdjust(int[] elem, int s ,int m) {
int temp, j;
temp = elem[s];
for (j = 2 * s; j <= m; j *= 2) { //沿关键字较大的孩子节点向下筛选
if(j < m && elem[j] < elem[j + 1]) { //判断左孩子大还是右孩子大
++j; //j为关键字中较大的下标
}
if(temp >= elem[j]) {
break;
}
elem[s] = elem[j];
s = j;
}
elem[s] = temp; //插入
}
public void swap(int[] elem, int i, int j) {
int temp = elem[i];
elem[i] = elem[j];
elem[j] = temp;
}
/**
* 对顺序表elem进行堆排序
* @param elem
*/
public void maxHeapSort(int[] elem) {
int length = elem.length - 1;
for (int i = length / 2; i > 0; i--) { //把elem构建成一个大顶堆
maxHeapAdjust(elem, i, length);
}
for (int i = length; i > 1; i--) {
swap(elem, 1, i); //将堆顶记录和当前未经排序子序列的最后一个记录交换
maxHeapAdjust(elem, 1, i - 1); //将elem[1.....i-1]重新调整为一个大顶堆
}
}
public static void main(String[] args) {
MaxHeapSort m = new MaxHeapSort();
int[] elem = {0, 50, 10, 90, 30, 70, 40, 80, 60, 20};
m.maxHeapSort(elem);
for (int i = 1; i < elem.length; i++) {
System.out.print(elem[i] + ", ");
}
}
}
输出:
10, 20, 30, 40, 50, 60, 70, 80, 90,
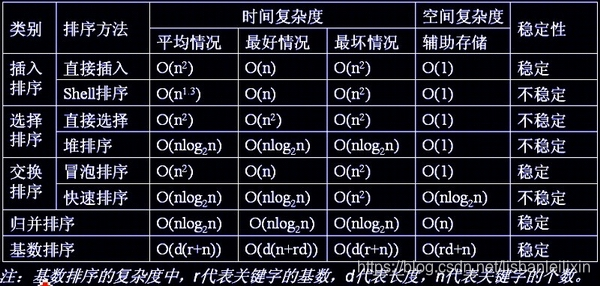
堆排序复杂度分析
堆排序的运行时间主要是消耗在初始构建堆和重建堆时的反复筛选上。
在构建堆的过程中,因为我们是完全二叉树从最下层最右边的非终端节点开始构建,将它和其孩子进行比较和若有必要的交换,对于每个非终端节点来说,其实最多进行两次比较和互换操作,因此真个构建堆的时间复杂度是O(n)。
在正式排序时,第i次取堆顶记录重建堆需要用O(logi)的时间 (完全二叉树的某个节点到根节点的距离是[log2log_2log2i] + 1),并且需要取n-1次堆顶记录,因此重建堆的时间复杂度为O(nlog\loglogn)。
所以堆排序的整体时间复杂度为O(nlog\loglogn)。由于堆排序对原始记录的排序状态并不敏感,因此无论是最好,最坏和平均时间复杂度均为O(nlog\loglogn)。
空间复杂度上,只有一个用来交换的暂存单元,但是由于记录的比较与交换是跳跃式进行的,因此堆排序也是一种不稳定的排序方法
另外,由于初始构建堆所需的比较次数比较多,因此他不适合待排序序列个数较少的情况。
堆排序(最大堆)的理解和实现(Java)的更多相关文章
- Atitit 深入理解命名空间namespace java c# php js
Atitit 深入理解命名空间namespace java c# php js 1.1. Namespace还是package1 1.2. import同时解决了令人头疼的include1 1.3 ...
- 理解和解决Java并发修改异常ConcurrentModificationException(转载)
原文地址:https://www.jianshu.com/p/f3f6b12330c1 理解和解决Java并发修改异常ConcurrentModificationException 不知读者在Java ...
- 深入理解和探究Java类加载机制
深入理解和探究Java类加载机制---- 1.java.lang.ClassLoader类介绍 java.lang.ClassLoader类的基本职责就是根据一个指定的类的名称,找到或者生成其对应的字 ...
- 深入理解什么是Java泛型?泛型怎么使用?【纯转】
本篇文章给大家带来的内容是介绍深入理解什么是Java泛型?泛型怎么使用?有一定的参考价值,有需要的朋友可以参考一下,希望对你们有所助. 一.什么是泛型 “泛型” 意味着编写的代码可以被不同类型的对象所 ...
- 深入理解JVM一java堆分析
上一节介绍了针对JVM的监控工具,包括JPS可以查看当前所有的java进程,jstack查看线程栈可以帮助你分析是否有死锁等情况,jmap可以导出java堆文件在MAT工具上进行分析等等.这些工具都非 ...
- [转载] 深入理解Android之Java虚拟机Dalvik
本文转载自: http://blog.csdn.net/innost/article/details/50377905 一.背景 这个选题很大,但并不是一开始就有这么高大上的追求.最初之时,只是源于对 ...
- 如何理解和使用Java package包
Java中的一个包就是一个类库单元,包内包含有一组类,它们在单一的名称空间之下被组织在了一起.这个名称空间就是包名.可以使用import关键字来导入一个包.例如使用import java.util.* ...
- 深入理解JVM(6)——Java内存模型和线程
Java虚拟机规范中定义了Java内存模型(Java Memory Model,JMM)用来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果(“即Ja ...
- 理解JVM之Java内存区域
Java虚拟机运行时数据区分为以下几个部分: 方法区.虚拟机栈.本地方法栈.堆.程序计数器.如下图所示: 一.程序计数器 程序计数器可看作当前线程所执行的字节码行号指示器,字节码解释器工作时就是通过改 ...
随机推荐
- 关于调用Feign client超时得不到结果的问题
需要在调用方的配置文件加入以下配置 hystrix.command.default.execution.timeout.enabled: false ribbon: ConnectTimeout: R ...
- Yarn application has already exited with state FINISHED
如果在运行spark-sql时遇到如下这样的错误,可能是因为yarn-site.xml中的配置项yarn.nodemanager.vmem-pmem-ratio值偏小,它的默认值为2.1,可以尝试改大 ...
- HDU6029 Happy Necklace 2017-05-07 19:11 45人阅读 评论(0) 收藏
Happy Necklace Time Limit: ...
- KNN和K-Means的区别
KNN和K-Means的区别 KNN K-Means 1.KNN是分类算法 2.监督学习 3.喂给它的数据集是带label的数据,已经是完全正确的数据 1.K-Means是聚类算法 2.非监督学习 3 ...
- Linux 用 sftp scp命令 互传文件
sftp它类似于 ftp, 但它进行加密传输,比FTP有更高的安全性. sftp 是SSH服务的子程序 常用命令 pwd 查看当前工作目录 ls 查看远程当前目录下的所以文件或者目录信息 lls 查看 ...
- [Openwrt 项目开发笔记]:Openwrt必要设置(二)
[Openwrt项目开发笔记]系列文章传送门:http://www.cnblogs.com/double-win/p/3888399.html 正文: 前面的两篇blog中,我将如何搭建Openwrt ...
- HTML/HTML5
HTML/HTML5 一.文档加载顺序. 文档入下,数字编号为加载顺序. <html><!--1--> <head><!--2--> <link ...
- JavaScript正则表达式匹配中英文以及常用标点符号白名单写法
我们在编程中经常会遇到特殊字符过滤的问题,今天我们提供一种白名单方式过滤 直接上代码 function RegEXP(s) { var rs = ""; for (var i = ...
- winform 批量控件取值赋值
以前写winform 最多写几个文本框,最近需要入录一个人员信息,那好几十个字段,一下子干蒙了,这要是一个个取值赋值都写到明天了,于是就自己写了个方法,也不是什么高大上的,就是很简单很普通很low的方 ...
- /bin/sh: cc: 未找到命令
redis 4安装出现 /bin/sh cc: 未找到命令 解决: yum -y install gcc automake autoconf libtool make