Urllib库的基本用法
1、什么是url?
统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。
基本URL包含模式(或称协议)、服务器名称(或IP地址)、路径和文件名,如“协议://授权/路径?查询”。完整的、带有授权部分的普通统一资源标志符语法看上去如下:协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志
2、什么是Urllib库?
Urllib是python内置的处理URL的库,
包括以下模块
urllib.request 打开、读URLs
urllib.error 包含了request出现的异常
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块(spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做robots.txt的纯文本文件。您可以在您的网站中创建一个纯文本文件robots.txt,在文件中声明该网站中不想被robot访问的部分或者指定搜索引擎只收录特定的部分)
3、实例
(1)读一个网页
import urllib.request
with urllib.request.urlopen('http://www.baidu.com') as f:
print(f.read(20).decode('utf8'))
其中,urlopen返回的是一个字节类型的对象,这是由于urlopen不知道从服务器上读的数据该如何解码,需要我们自己对字符串解码。
如上,可以打开百度的界面,
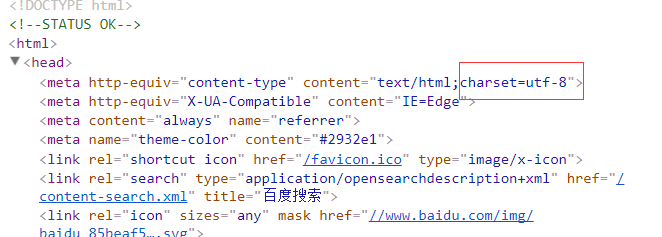
可以看到,此页面用utf-8编码。
当然,你也可以把代码改为:
import urllib.request
req = urllib.request.Request(url = 'http://www.baidu.com')
with urllib.request.urlopen(req) as f:
print(f.read(20).decode('utf8'))
访问请求放置在Request类中,该类包含一些属性,可以传递数据等,此处不过于深究。
(2)登陆动作(使用基础的HTTP身份验证)
Urllib库的基本用法的更多相关文章
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- python爬虫---urllib库的基本用法
urllib是python自带的请求库,各种功能相比较之下也是比较完备的,urllib库包含了一下四个模块: urllib.request 请求模块 urllib.error 异常处理模块 u ...
- Python爬虫入门(3-4):Urllib库的高级用法
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
- Python爬虫 Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 芝麻HTTP: Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 4.Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
随机推荐
- vue、入门
入门vue v-on:click:chang 绑定事件点击 生面周期,整个vue的执行过程,他的应用执行了生面周期,也就是执行过程,这个执行过程如下图表,我们可以参考下图,也可以访问官方网址:ht ...
- 2015.07.15——prime素数
prime素数 1.素数也叫质数,定义是一个数只能被1和它自身整除. 素数从2开始,0,1都不是素数. 2.素数的判断(C++) 3.给定某个数,求小于这个数的所有素数 2.素数的判断(C++) bo ...
- MyBatis 总结记录
1.1MyBatis简介 MyBatis 是一个可以自定义SQL.存储过程和高级映射的持久层框架.MyBatis 摒除了大部分的JDBC代码.手工设置参数和结果集重获.MyBatis 只使用简单的XM ...
- C# 反射获取和设置值
/// <summary> /// 遍历泛型 /// </summary> /// <typeparam name="T"></typep ...
- 高级C#信使(译) - Unity维基百科
高级C#信使 作者:Ilya Suzdalnitski 译自:http://wiki.unity3d.com/index.php/Advanced_CSharp_Messenger 描述 前言 Mis ...
- mysql远程连接数据库
配置mysql允许远程连接的方法. (1)查看3306端口状态 netstat -an | grep 3306 (2)修改mysql配置文件 ubuntu系统:vim /etc/mysql/mysql ...
- 「要买车网」免费获取汽车电商要买车网购车优惠券 - 持续更新(2016-03-12)www.fortunelab.cn
汽车电商要买车网简介 “要买车”(www.yaomaiche.com)网站是上海运图投资有限公司旗下网站,是首家真正打通交易闭环的汽车电商网站,由中国电子商务成功探索者——卜广齐于2014年10月在上 ...
- python configparser配置文件解析器
一.Configparser 此模块提供实现基本配置语言的ConfigParser类,该语言提供类似于Microsoft Windows INI文件中的结构.我们经常会在一些软件安装目录下看到.ini ...
- 六、springcloud之配置中心Config
一.配置中心提供的核心功能 Spring Cloud Config为服务端和客户端提供了分布式系统的外部化配置支持.配置服务器为各应用的所有环境提供了一个中心化的外部配置.它实现了对服务端和客户端对S ...
- 玩玩 Nginx 1----- Nginx + ngx_lua安装测试【CentOs下】
最近打算搞搞nginx,扒着各位先驱的文章自己进行测试下,中间过程也是错误不断,记录一下,以备使用. nginx的安装挺简单的,主要还是研究下一些第三方的模块,首先想试下初始化 ...