8 tensorflow修改tensor张量矩阵的某一列
1.tensorflow的数据流图限制了它的tensor是只读属性,因此对于一个Tensor(张量)形式的矩阵,想修改特定位置的元素,比较困难。
2.我要做的是将所有的操作定义为符号形式的操作。也就是抽象概念的数据流图。当用feed_dict传入具体值以后,就能用sess.run读出具体值。
一、相关内容
https://blog.csdn.net/Cerisier/article/details/79584851
Tensorflow小技巧整理:修改张量特定元素的值
二、修改矩阵的某一列
代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 1 16:53:26 2018 @author: a
"""
import tensorflow as tf
x = tf.placeholder(tf.float32, shape=(2, 2), name="input")
xx=tf.zeros([2,3],tf.float32)
xx2=tf.concat([x,xx],axis=1)
columnTensor=tf.ones([2,1],tf.float32)
print (xx2)
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1),trainable=False)
w2= tf.Variable(xx2,trainable=False)
#编写程序修改Tensor矩阵的某一列
embed_size=300
max_sentence_length=50
max_node_size=max_sentence_length*2-1#训练语料库句子节点的最大长度。注意,是句子节点的最大长度。不是句子单词的最大数目。
#test=tf.Variable(name="test",trainable=False,dtype=tf.float64,shape=[embed_size,max_node_size])
def modify_one_column(tensor,columnTensor,index):#index也是tensor
#tensor为二维矩阵
#columnTensor的维度就是tensor中的一列
numlines=tensor.shape[0].value #行数
numcolunms=tensor.shape[1].value #列数
new_tensor_left=tf.slice(tensor, [0, 0], [numlines, index])
new_tensor_right=tf.slice(tensor, [0, index+1], [numlines, numcolunms-(index+1)])
new_tensor=tf.concat([new_tensor_left,columnTensor,new_tensor_right],1)
return new_tensor_left,new_tensor_right,new_tensor
# def f1():#index为0的情形
# new_tensor_right=tf.slice(tensor, [0, 1], [numlines, numcolunms-1])
# new_tensor=tf.concat([columnTensor,new_tensor_right],1)
# return new_tensor
# if (tf.equal(index,0)):
# new_tensor_right=tf.slice(tensor, [0, 1], [numlines, numcolunms-1])
# new_tensor=tf.concat([columnTensor,new_tensor_right],1)
# return new_tensor sess = tf.Session()
init_op = tf.global_variables_initializer()
#print(sess.run(x, feed_dict={x: [[0.7,0.9]]}))
sess.run(init_op,feed_dict={x: [[0.7,0.9],[80.0,90.0]]})
print (sess.run((w1,w2)))
print (w2)
for index in range(5):
index_tensor=tf.constant(index,tf.int32)
new_tensor_left,new_tensor_right,w22=modify_one_column(w2,columnTensor,index_tensor)
print (sess.run([new_tensor_left,columnTensor,new_tensor_right,w22]))
for index in range(5):
index_tensor=tf.constant(index,tf.int32)
new_tensor_left,new_tensor_right,w2=modify_one_column(w2,columnTensor,index_tensor)
print (sess.run([new_tensor_left,columnTensor,new_tensor_right,w2]))
#print (sess.run(w2,feed_dict={x: [[0.7,0.9]]}))
要注意的是:for循环中传入的是index_tensor而不是index。也就是定义的所有操作都是符号上的操作。这是写tensorflow计算图要遵循的一个重要原则。
上述第二个代码的for循环会在index=1的时候报错。这是因为index=0的时候,w2还是一个固定shape的Tensor矩阵。但是当执行完一次如下代码以后
new_tensor_left,new_tensor_right,w2=modify_one_column(w2,columnTensor,index_tensor)
w2的shape会变成(2,?),这是因为第一次调用modify_one_column中执行的时候,传入的index_tensor是一个Tensor,就会导致函数体内的new_tensor_left和new_tensor_right等的列数都变成了Tensor,即?,也就导致最后返回的new_tensor的列数也是Tensor,即?。
因此,第二次调用modify_one_column执行的时候,计算numcolunms=tensor.shape[1].value时得到的numcolunms是None。因此程序会报出:
ipdb> ValueError: None values not supported.
三、总结
第一,被修改的tensor矩阵用tf.variable保存,并且指定trainable=false,并且是根据tf.place_holder的数据流构建。这样的话,我们执行
init_op = tf.global_variables_initializer()
#print(sess.run(x, feed_dict={x: [[0.7,0.9]]}))
sess.run(init_op,feed_dict={x: [[0.7,0.9],[80.0,90.0]]})
以后就可以将被修改的tensor矩阵与输入之间建立直接的关联。
不用tf.constant的原因是,tf.constant不能根据tf.place_hodler的数据流构建。tf.constant的函数说明如下,可以看到,其不能基于Tensor构建Tensor。
而tf.variable可以基于Tensor构建tensor。也就是接受tensor数据输入,然后variable节点输出tensor数据。(传入的Tensor必须是shape specified。否则不能作为tf.Variable的参数)
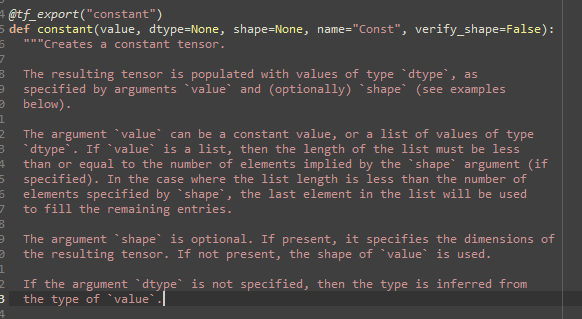
第二,如果反复对一个矩阵的列进行修改,正如上述代码第二个for循环,通过反复运算,能够将矩阵的每一列都变成[1,1]。这个时候,要记住,一定要在第一次将被修改矩阵的行数和列数保存下来,而不是每一次在循环体内进行计算。
因为循环体内对矩阵某一列进行修改,实际上是一个只读的操作,也就是取出被修改列前,被修改列后,然后要修改成的列,拼接而成。这样的话,截取这个矩阵的时候,就会导致列数变成了?,也就是不能确定具体多少列。
如此以来,下一次循环体内如果还想计算列数,就比较困难。
为什么会导致这样。这是因为我传入的index就是一个Tensor。也就是矩阵哪一列被修改,我传入的是Tensor。这就导致了tf.slice切片以后的输出矩阵的列数仍然是一个tensor。
为什么我要传入Tensor,而不是一个具体的值。这是因为我有一个任务需求,是根据实际传入的place_holder的input数据的值,去索引tensor矩阵。但是在构建计算图的时候,这个数据是不知道的,是个tensor。所以,我定义的操作都是在符号上进行的。
上述for循环代码修改如下:
def modify_one_column(tensor,columnTensor,index,numlines,numcolunms):#index也是tensor
#tensor为二维矩阵
#columnTensor的维度就是tensor中的一列
new_tensor_left=tf.slice(tensor, [0, 0], [numlines, index])
new_tensor_right=tf.slice(tensor, [0, index+1], [numlines, numcolunms-(index+1)])
new_tensor=tf.concat([new_tensor_left,columnTensor,new_tensor_right],1)
return new_tensor_left,new_tensor_right,new_tensor sess = tf.Session()
init_op = tf.global_variables_initializer()
#print(sess.run(x, feed_dict={x: [[0.7,0.9]]}))
sess.run(init_op,feed_dict={x: [[0.7,0.9],[80.0,90.0]]})
print (sess.run((w1,w2)))
print (w2) numlines=w2.shape[0].value
numcolunms=w2.shape[1].value
for index in range(5):
index_tensor=tf.constant(index,tf.int32)
new_tensor_left,new_tensor_right,w2=modify_one_column(w2,columnTensor,index_tensor,numlines,numcolunms)
print (sess.run([new_tensor_left,columnTensor,new_tensor_right,w2]))
最后一次for循环结束时的输出如下:

可以看到,每一列都依次被修改了。
我们还可以将numlines等具体值也变为tensor,如下:
numlines_tensor=tf.constant(numlines,tf.int32)
numcolunms_tensor=tf.constant(numcolunms,tf.int32)
8 tensorflow修改tensor张量矩阵的某一列的更多相关文章
- python/numpy/tensorflow中,对矩阵行列操作,下标是怎么回事儿?
Python中的list/tuple,numpy中的ndarrray与tensorflow中的tensor. 用python中list/tuple理解,仅仅是从内存角度理解一个序列数据,而非数学中标量 ...
- 对Tensorflow中tensor的理解
Tensor即张量,在tensorflow中所有的数据都通过张量流来传输,在看代码的时候,对张量的概念很不解,很容易和矩阵弄混,今天晚上查了点资料,并深入了解了一下,简单总结一下什么是张量的阶,以及张 ...
- TensorFlow 中的张量,图,会话
tensor的含义是张量,张量是什么,听起来很高深的样子,其实我们对于张量一点都不陌生,因为像标量,向量,矩阵这些都可以被认为是特殊的张量.如下图所示: 在TensorFlow中,tensor实际上就 ...
- [PyTorch 学习笔记] 1.2 Tensor(张量)介绍
本章代码: https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson1/tensor_introduce1.py https: ...
- TensorFlow计算图,张量,会话基础知识
import tensorflow as tf get_default_graph = "tensorflow_get_default_graph.png" # 当前默认的计算图 ...
- 机器学习-Tensorflow之Tensor和Dataset学习
好了,咱们今天终于进入了现阶段机器学习领域内最流行的一个框架啦——TensorFlow.对的,这款由谷歌开发的机器学习框架非常的简单易用并且得到了几乎所有主流的认可,谷歌为了推广它的这个框架甚至单独开 ...
- pytorch中tensor张量数据基础入门
pytorch张量数据类型入门1.对于pytorch的深度学习框架,其基本的数据类型属于张量数据类型,即Tensor数据类型,对于python里面的int,float,int array,flaot ...
- 高效Tensor张量生成
高效Tensor张量生成 Efficient Tensor Creation 从C++中的Excel数据中创建Tensor张量的方法有很多种,在简单性和性能之间都有不同的折衷.本文讨论了一些方法及其权 ...
- MySQL修改表一次添加多个列(字段)和索引
MySQL修改表一次添加多个列(字段) ALTER TABLE table_name ADD func varchar(50), ADD gene varchar(50), ADD genedetai ...
随机推荐
- Java之集合(二十六)ConcurrentSkipListMap
转载请注明源出处:http://www.cnblogs.com/lighten/p/7542578.html 1.前言 一个可伸缩的并发实现,这个map实现了排序功能,默认使用的是对象自身的compa ...
- Java之集合(二十)LinkedBlockingQueue
转载请注明源出处:http://www.cnblogs.com/lighten/p/7503678.html 1.前言 本章介绍阻塞队列LinkedBlockingQueue,这是一个基于链表的可选长 ...
- Virtualbox下载与安装步骤
不多说,直接上干货! 本主主要介绍一下如何从官方网站下载正版的 虚拟化 Oracle VM VirtualBox ,以及说明一下去官方下载正版软件的重要性. 一.为了系统的稳定以及数据的安全,建议下载 ...
- Linux top命令用法
统计信息区前五行是系统整体的统计信息.第一行是任务队列信息,同 uptime 命令的执行结果.其内容如下: :: 当前时间 up : 系统运行时间,格式为时:分 user 当前登录用户数 load a ...
- mysql保留两位小数
--这个是保留整数位 SELECT CONVERT(4545.1366,DECIMAL); --这个是保留两位小数 ,)); --这个是截取两位,并不会四舍五入保留两位小数 );
- 常用算法2 - 广度优先搜索 & 深度优先搜索 (python实现)
1. 图 定义:图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合. 简单点的说:图由节点和边组成.一 ...
- springboot jpa 多条件查询(多表)
前几天写的,贴上来. 实体类. package com.syl.demo.daomain; import lombok.Data; import javax.persistence.*; /** * ...
- fastjson之JSONObject、JSONArray
JSONObject,JSONArray是JSON的两个子类. 首先我们来看JSONObject源码: 会发现JSONObject是继承Map<String, Object>,并且都是使用 ...
- C# 之String以及浅拷贝与深拷贝
一.String到底是值类型还是引用类型 MSDN 中明确指出 String 是引用类型而不是值类型,但 String 表面上用起来却像是值类型,这又是什么原因呢? 首先从下面这个例子入手: //值 ...
- js new Date() 获取时间
转载:https://www.cnblogs.com/xiaoshujiang/p/5518462.html 一,Date付给初始值,并构造new Date() Date 对象用于处理日期和时间.创建 ...